Continuous Development and Release Automation of Web Applications
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
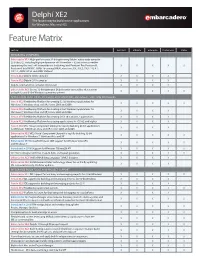
Delphi XE2 Feature Matrix
Delphi® XE2 The fastest way to build native applications for Windows, Mac and iOS Feature Matrix Feature Architect Ultimate Enterprise Professional Starter INTEGRATED COMPILERS Enhanced in XE2! High-performance 32-bit optimizing Delphi® native code compiler 23.0 (dcc32), including High performance x86 Assembler – 32-bit inline assembler supporting the Intel® x86 instruction set (including Intel Pentium® Pro, Pentium III, X X X X X Pentium 4, Intel MMX™, SIMD, Streaming SIMD Extensions, SSE, SSE2, SSE3, SSE 4.1, SSE 4.2, AMD SSE4A and AMD® 3DNow!® New in XE2! Delphi 64-bit compiler X X X X New in XE2! Delphi OS X compiler X X X X Delphi command line compiler (dcc32.exe) X X X X Enhanced in XE2! Create 32-bit optimized Delphi native executables that can run X X X X X on both 32 and 64-bit Windows operating systems APPLICATION PLATFORMS, INTEGRATED FRAMEWORKS, DESIGNERS, SDKS AND INSTALLERS New in XE2! FireMonkey Platform for creating 32-bit Windows applications for X X X X X Windows 7, Windows Vista and XP; Server 2003 and 2008. New in XE2! FireMonkey Platform for creating 64-bit Windows applications for X X X X Windows 7, Windows Vista and XP; Server 2003 and 2008. New in XE2! FireMonkey Platform for creating OS X 10.6 and 10.7 applications X X X X New in XE2! FireMonkey Platform for creating applications for iOS 4.2 and higher X X X X New in XE2! VCL (Visual Component Library) for rapidly building 64-bit applications X X X X for Windows 7,Windows Vista and XP; Server 2003 and 2008. -

Tracking Known Security Vulnerabilities in Third-Party Components
Tracking known security vulnerabilities in third-party components Master’s Thesis Mircea Cadariu Tracking known security vulnerabilities in third-party components THESIS submitted in partial fulfillment of the requirements for the degree of MASTER OF SCIENCE in COMPUTER SCIENCE by Mircea Cadariu born in Brasov, Romania Software Engineering Research Group Software Improvement Group Department of Software Technology Rembrandt Tower, 15th floor Faculty EEMCS, Delft University of Technology Amstelplein 1 - 1096HA Delft, the Netherlands Amsterdam, the Netherlands www.ewi.tudelft.nl www.sig.eu c 2014 Mircea Cadariu. All rights reserved. Tracking known security vulnerabilities in third-party components Author: Mircea Cadariu Student id: 4252373 Email: [email protected] Abstract Known security vulnerabilities are introduced in software systems as a result of de- pending on third-party components. These documented software weaknesses are hiding in plain sight and represent the lowest hanging fruit for attackers. Despite the risk they introduce for software systems, it has been shown that developers consistently download vulnerable components from public repositories. We show that these downloads indeed find their way in many industrial and open-source software systems. In order to improve the status quo, we introduce the Vulnerability Alert Service, a tool-based process to track known vulnerabilities in software projects throughout the development process. Its usefulness has been empirically validated in the context of the external software product quality monitoring service offered by the Software Improvement Group, a software consultancy company based in Amsterdam, the Netherlands. Thesis Committee: Chair: Prof. Dr. A. van Deursen, Faculty EEMCS, TU Delft University supervisor: Prof. Dr. A. -

Return of Organization Exempt from Income
OMB No. 1545-0047 Return of Organization Exempt From Income Tax Form 990 Under section 501(c), 527, or 4947(a)(1) of the Internal Revenue Code (except black lung benefit trust or private foundation) Open to Public Department of the Treasury Internal Revenue Service The organization may have to use a copy of this return to satisfy state reporting requirements. Inspection A For the 2011 calendar year, or tax year beginning 5/1/2011 , and ending 4/30/2012 B Check if applicable: C Name of organization The Apache Software Foundation D Employer identification number Address change Doing Business As 47-0825376 Name change Number and street (or P.O. box if mail is not delivered to street address) Room/suite E Telephone number Initial return 1901 Munsey Drive (909) 374-9776 Terminated City or town, state or country, and ZIP + 4 Amended return Forest Hill MD 21050-2747 G Gross receipts $ 554,439 Application pending F Name and address of principal officer: H(a) Is this a group return for affiliates? Yes X No Jim Jagielski 1901 Munsey Drive, Forest Hill, MD 21050-2747 H(b) Are all affiliates included? Yes No I Tax-exempt status: X 501(c)(3) 501(c) ( ) (insert no.) 4947(a)(1) or 527 If "No," attach a list. (see instructions) J Website: http://www.apache.org/ H(c) Group exemption number K Form of organization: X Corporation Trust Association Other L Year of formation: 1999 M State of legal domicile: MD Part I Summary 1 Briefly describe the organization's mission or most significant activities: to provide open source software to the public that we sponsor free of charge 2 Check this box if the organization discontinued its operations or disposed of more than 25% of its net assets. -

Third Party Licenses for Embarcadero RAD Studio XE, Delphi XE, C++Builder XE
Third Party Licenses for Embarcadero RAD Studio XE, Delphi XE, C++Builder XE This Document contains either required notices for third party software or the third party license documents under which the Separately Licensed Code is licensed. (Please note that in some cases, the license listed may differ from the license under which the latest version of the code can be obtained) Table of Contents Separately Licensed Code ............................................................................................. Microsoft® .NET framework redistributable ............................................................... Microsoft® Visual J# redistributable .......................................................................... Office UI License Agreement ...................................................................................... InstallAware Express .................................................................................................. Rave Reports ............................................................................................................. IP*Works .................................................................................................................... CodeSite .................................................................................................................... FinalBuilder ................................................................................................................ Apache Subversion ................................................................................................... -

Main Brochure2.Indd
Automate your Build Process . Powerful and fl exible user interface . Automate version control, compilers, install builders, deployment, testing, notifi cations, and lots more... Dynamic build process using fl ow control, iterators, loops, and exceptions . Full debugger built in - breakpoints, variable watches, live logging . Script events for every action to customise your build process Hierarchical Logging Error Handling FinalBuilder ActionStudio . The log is presented in the same . Easily detect and handle errors during . Allows development of native FinalBuilder hierarchy as your build process your build process actions . Optionally view live log output . Exception handling actions . Includes property page designer and as the build runs include: TRY, CATCH, FINALLY code editor with syntax highlighting . Builds logs are automatically . Control the fl ow of your build process . Develop actions in VBScript, JScript, COM, archived and recover from errors or any .Net language such as C#, VB.Net or Delphi for .Net . Export the log as XML, HTML, or . Unhandled errors trigger the OnFailure Text action list . Included in all editions of FinalBuilder VSoft Technologies Pty Ltd http://www.fi nalbuilder.com ABN: 82 078 466 092 P.O. Box 126, Erindale Centre, ACT 2903, Australia salesinfo@fi nalbuilder.com Phone: +61 2 6282 7488, Fax +61 2 6282 7588 news://news.fi nalbuilder.com FinalBuilder Integrates with your version control system . Microsoft TeamSystem Use a GUI instead of XML fi les . Microsoft Visual SourceSafe . Perforce Although FinalBuilder uses an XML based fi le format, you . IBM Rational ClearCase don’t need to understand it or even look at it. The FinalBuilder . QSC Team Coherence GUI allows you to quickly and easily create a build process . -

Buyers Guide Product Listings
BUYERS GUIDE PRODUCT LISTINGS Visual Studio Magazine Buyers’ Guide Product Listings The 2009 Visual Studio Magazine Buyers’ Guide listings comprise more than 700 individual products and services, ranging from developer tooling and UI components to Web hosting and instructor-led training. Included for each product is contact and pricing information. Keep in mind that many products come in multiple SKUs and with varied license options, so it’s always a good idea to contact vendors directly for specific pricing. The developer tools arena is a vast and growing space. As such, we’re always on the prowl for new tools and vendors. Know of a product our readers might want to learn more about? E-mail us at [email protected]. BUG & FEATURE TRACKING Gemini—CounterSoft Starts at $1189 • countersoft.com • +44 (0)1753 824000 Rational ClearQuest—IBM Rational Software $1,810 • ibm.com/rational • 888-426-3774 IssueNet Intercept—Elsinore Technologies Call for price • elsitech.com • 866-866-0034 FogBugz 7.0—Fog Creek Software $199 • fogcreek.com • 888-364-2849; 212-279-2076 SilkPerformer—Borland Call for price • borland.com • 800-632-2864; 512-340-2200 OnTime 2009 Professional—Axosoft Starts at $795 for five users • axosoft.com • 800-653-0024; SourceOffSite 4.2—SourceGear 480-362-1900 $239 • sourcegear.com • 217-356-0105 Alexsys Team 2.10—Alexsys Surround SCM 2009—Seapine Software Starts at $145 • alexcorp.com • 888-880-2539; 781-279-0170 Call for price • seapine.com • 888-683-6456; 513-754-1655 AppLife DNA—Kinetic Jump Software TeamInspector—Borland -

Metadefender Core V4.19.0
MetaDefender Core v4.19.0 © 2019 OPSWAT, Inc. All rights reserved. OPSWAT®, MetadefenderTM and the OPSWAT logo are trademarks of OPSWAT, Inc. All other trademarks, trade names, service marks, service names, and images mentioned and/or used herein belong to their respective owners. Table of Contents About This Guide 14 Key Features of MetaDefender Core 15 1. Quick Start with MetaDefender Core 16 1.1. Installation 16 Basic setup 16 1.1.1. Configuration wizard 16 1.2. License Activation 22 1.3. Process Files with MetaDefender Core 22 2. Installing or Upgrading MetaDefender Core 23 2.1. Recommended System Configuration 23 Microsoft Windows Deployments 24 Unix Based Deployments 26 Data Retention 28 Custom Engines 28 Browser Requirements for the Metadefender Core Management Console 28 2.2. Installing MetaDefender 29 Installation 29 Installation notes 29 2.2.1. MetaDefender Core 4.18.0 or older 30 2.2.2. MetaDefender Core 4.19.0 or newer 33 2.3. Upgrading MetaDefender Core 38 Upgrading from MetaDefender Core 3.x to 4.x 38 Upgrading from MetaDefender Core older version to 4.18.0 (SQLite) 38 Upgrading from MetaDefender Core 4.18.0 or older (SQLite) to 4.19.0 or newer (PostgreSQL): 39 Upgrading from MetaDefender Core 4.19.0 to newer (PostgreSQL): 40 2.4. MetaDefender Core Licensing 41 2.4.1. Activating Metadefender Licenses 41 2.4.2. Checking Your Metadefender Core License 46 2.5. Performance and Load Estimation 47 What to know before reading the results: Some factors that affect performance 47 How test results are calculated 48 Test Reports 48 2.5.1. -
1 Finalbuilder Server
FinalBuilder Server © 2012 VSoft Technologies 2 FinalBuilder Server Table of Contents Foreword 0 Part I FinalBuilder Server 5 1 FinalB.u..i.l.d..e..r. .S..e..r.v..e..r. .O...v..e..r.v..i.e..w................................................................................................ 5 2 Installa..t.i.o..n............................................................................................................................. 5 Requirements .......................................................................................................................................................... 6 Installing FinalB..u...i.l.d..e..r.. .S..e...r.v..e...r. ................................................................................................................................ 6 Post Installati.o..n.. .C...o..n...f.i.g..u...r.a..t..i.o..n.. ........................................................................................................................... 10 Configuration. .a..n..d... .M...a..i.n..t..e..n..a..n...c..e.. ......................................................................................................................... 14 3 Gettin..g.. .S..t.a..r.t.e..d..................................................................................................................... 17 Logging In .......................................................................................................................................................... 18 Creating New . .U..s..e...r.s... ............................................................................................................................................ -

Ÿþþ Ÿ F I N a L B U I L D E R a C T I O N S T U D I O M
FinalBuilder ActionStudio Manual Copyright © 2006 VSoft Technologies Pty Ltd I Table of Contents 0 Part I ActionStudio Introduction 1 1 Getting. .S..t.a..r.t.e..d.. .W....i.t.h.. .F..i.n..a..l.B..u..i.l.d..e..r. ......................................................................................... 1 2 What a.r.e.. .F..i.n..a..l.B..u..i.l.d..e..r. .P...l.u..g..-.I.n..s. ............................................................................................. 1 3 Action I.m...p..l.e..m...e..n..t.a..t.i.o..n.. .O...p..t.i.o..n..s. ............................................................................................. 2 4 ActionS..t.u..d..i.o.. .I.D..E.. .O..v..e..r.v..i.e..w... ................................................................................................... 2 Action Package.. .T..r..e..e... .............................................................................................................................................. 3 ActionStudio ID..E.. .H..e..l.p... ............................................................................................................................................. 4 Action Types .......................................................................................................................................................... 5 Standard Ac..t.i.o..n................................................................................................................................................... 5 Execute Pro.g..r.a..m... .A...c..t.io..n...................................................................................................................................... -

Generación, Gestión Y Distribución De Artefactos Java Con Técnicas De Integración Continua Y Software Libre
FACULTAD DE INFORMÁTICA UNIVERSIDAD POLITÉCNICA DE MADRID UNIVERSIDAD POLITÉCNICA DE MADRID FACULTAD DE INFORMÁTICA TRABAJO FIN DE CARRERA GENERACIÓN, GESTIÓN Y DISTRIBUCIÓN DE ARTEFACTOS JAVA CON TÉCNICAS DE INTEGRACIÓN CONTINUA Y SOFTWARE LIBRE AUTOR: Carlos González Sánchez TUTOR: Francisco Gisbert Canto Agradecimientos A la Comunidad de Software Libre, porque sin ella este trabajo difícilmente po- dría haberse llevado a cabo. A Javier Bezos por compartir generosamente su amplio conocimiento acerca de LATEX, y a Ignacio Estirado por su inestimable ayuda en el trabajo de campo. A Susana, a Martín y a mis padres, por todo. Facultad de Informática - UPM. Julio 2008. Carlos González Sánchez I Índice general Agradecimientos I Resumen VII 1. INTRODUCCIÓN1 1.1. Motivación.................................1 1.2. Objetivos..................................2 1.3. Alcance...................................3 2. MATERIAL DE ESTUDIO5 2.1. Ciclo de vida del software........................5 2.2. Control de versiones...........................6 2.3. Gestión de artefactos...........................7 2.4. Gestión de dependencias.........................8 2.5. Gestión de despliegues.......................... 10 2.6. Integración continua........................... 10 2.7. Virtualización............................... 11 2.7.1. Tecnologías de virtualización.................. 12 2.7.2. Ventajas de la virtualización................... 13 2.7.3. Inconvenientes.......................... 14 3. METODOLOGÍA 15 3.1. Arquitectura................................ 15 -

Apache Continuum 1.3.8 V
...................................................................................................................................... Apache Continuum 1.3.8 v. ...................................................................................................................................... The Apache Continuum Project Documentation i Documentation ....................................................................................................................................... 1 Index (category) . 1 2 Getting Started . 2 3 Installation/Upgrade Guides . 3 4 System Requirements . 4 5 Installation . 5 6 Standalone . 6 7 Tomcat . 10 8 Upgrade . 15 9 User's Guides . 17 10 Managing Projects . 18 11 Add a Project . 19 12 Edit a Project . 24 13 Remove a Project . 27 14 Managing Build Definitions . 28 15 Project Build Definition . 29 16 Project Group Build Definition . 31 17 Managing Notification . 33 18 Mail Notification . 35 19 IRC Notification . 36 20 Jabber Notification . 38 21 MSN Notification . 40 22 Wagon Notification . 41 23 Building a project . 43 24 Scheduled Build . 44 25 Forced Build . 45 26 Build Results Management . 46 26 Release Management . 48 26 Prepare Project Release . 50 26 Perform Project Release . 53 26 Release Results Management . 55 26 Administrator's Guides . 56 26 Managing Users and Security . 57 26 Security Configuration . 58 26 LDAP Configuration . 59 26 Managing Project Groups . 60 26 Managing Builders . 63 26 Managing JDKs . 65 26 Managing Build Environments . © 2 0 1 1 , • A L L R I G H T S R E S E R V E D . Documentation ii 26 Managing Schedules . 66 26 Managing General Configuration . 69 26 Managing Local Repositories . 71 26 Managing Purge Configuration . 72 26 Managing Parallel Builds . 74 26 Managing Build Queues . 75 26 Managing Build Agents . 77 26 Managing Build Agent Groups . 78 26 Managing Project Queues . 79 26 External databases . 81 26 Monitoring Continuum . 84 26 Log Files . 87 26 Audit Logs . -

Apache Maven Current Version User Guide
...................................................................................................................................... Apache Maven Current version User Guide ...................................................................................................................................... The Apache Software Foundation 2009-10-16 T a b l e o f C o n t e n t s i Table of Contents ....................................................................................................................................... 1 Table of Contents . i 2 What is Maven? . 1 3 Features . 3 4 FAQ . 4 5 Community Overview . 11 5.1 How to Contribute . 13 5.2 Getting Help . 15 5.3 Issue Tracking . 17 5.4 Source Repository . 18 5.5 Continuous Integration . 20 6 Running Maven . 21 7 Maven Plugins . 23 8 User Centre . 30 8.1 Maven in 5 Minutes . 31 8.2 Getting Started Guide . 35 8.3 POM Reference . 57 8.4 Settings Reference . 91 8.5 Guides . 100 8.5.1 The Build Lifecycle . 103 8.5.2 The POM . 111 8.5.3 Profiles . 123 8.5.4 Repositories . 133 8.5.5 Standard Directory Layout . 136 8.5.6 The Dependency Mechanism . 137 8.5.7 Plugin Development . 153 8.5.8 Configuring Plug-ins . 156 8.5.9 The Plugin Registry . 169 8.5.10 Plugin Prefix Resolution . 172 8.5.11 Developing Ant Plugins . 174 8.5.12 Developing Java Plugins . 188 8.5.13 Creating a Site . 198 8.5.14 Snippet Macro . 203 8.5.15 What is an Archetype . 205 8.5.16 Creating Archetypes . 207 8.5.17 From Maven 1.x to Maven 2.x . 210 8.5.18 Using Maven 1.x repositories with Maven 2.x . 213 8.5.19 Relocation of Artifacts . 214 8.5.20 Installing 3rd party JARs to Local Repository .