Design & Implementation of Classification & Clustering
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

LG G3 User Guide
Available applications and services are subject to change at any time. Table of Contents Get Started 1 Your Phone at a Glance 1 Set Up Your Phone 1 Activate Your Phone 4 Complete the Setup Screens 5 Make Your First Call 6 Set Up Your Voicemail 6 Sprint Account Information and Help 7 Sprint Account Passwords 7 Manage Your Account 7 Sprint Support Services 8 Phone Basics 9 Your Phone's Layout 9 Turn Your Phone On and Off 11 Screen On/Off 11 Lock and Unlock Your Phone 12 Unlock Your Screen Using the Knock Code Feature 13 Guest Mode 14 Set Up Guest Mode 14 Use Guest Mode 15 Hardware Key Control Mode 15 Battery and Charger 15 Extend Your Battery Life 17 Phone Function Keys 17 Recent Apps Key 18 Work with Menus 18 Notifications Panel 19 Home Key 20 Back Key 21 Touchscreen Navigation 21 Your Home Screen 22 Home Screen 22 Extended Home Screen 23 i Use the Applications Key 23 Applications: How to View, Open and Switch 23 Applications 25 Customize Your Home Screen 27 Add and Remove Widgets on the Home Screen 28 Change the Phone's Wallpaper 29 Customize Applications Icons on the Home Screen 30 Access Recently-Used Applications 31 Home Screen Clean View 31 Quick Access 32 Change the Screen Orientation 32 Status Bar 32 Enter Text With the On-screen Keyboard 35 Tips for Editing Text 37 Search Your Phone and the Web 42 Phone and Web Search Using Text Entry 42 Phone and Web Search Using Voice Command 44 Using Clip Tray 44 Text Link 44 Phone Calls 46 HD™ Voice 46 Make Phone Calls 46 Call Using the Phone Dialer 46 Dialing Options 47 Missed Call Notification -

2014 BT Compatibility List 20141030
Item Brand Name Model 1 Acer Acer beTouch E210 2 Acer acer E400 3 Acer acer P400 4 Acer DX650 5 Acer E200 6 Acer Liquid E 7 Acer Liquid Mini (E310) 8 Acer M900 9 Acer S110 10 Acer Smart handheld 11 Acer Smart handheld 12 Acer Smart handheld E100 13 Acer Smart handheld E101 14 Adec & Partner AG AG vegas 15 Alcatel Alcatel OneTouch Fierce 2 16 Alcatel MISS SIXTY MSX10 17 Alcatel OT-800/ OT-800A 18 Alcatel OT-802/ OT-802A 19 Alcatel OT-806/ OT-806A/ OT-806D/ OT-807/ OT-807A/ OT-807D 20 Alcatel OT-808/ OT-808A 21 Alcatel OT-880/ OT-880A 22 Alcatel OT-980/ OT-980A 23 Altek Altek A14 24 Amazon Amazon Fire Phone 25 Amgoo Telecom Co LTD AM83 26 Apple Apple iPhone 4S 27 Apple Apple iPhone 5 28 Apple Apple iPhone 6 29 Apple Apple iPhone 6 Plus 30 Apple iPhone 2G 31 Apple iPhone 3G 32 Apple iPhone 3Gs 33 Apple iPhone 4 34 Apple iPhone 5C 35 Apple iPHone 5S 36 Aramasmobile.com ZX021 37 Ascom Sweden AB 3749 38 Asustek 1000846 39 Asustek A10 40 Asustek G60 41 Asustek Galaxy3_L and Galaxy3_S 42 Asustek Garmin-ASUS M10E 43 Asustek P320 44 Asustek P565c 45 BlackBerry BlackBerry Passport 46 BlackBerry BlackBerry Q10 47 Broadcom Corporation BTL-A 48 Casio Hitachi C721 49 Cellnet 7 Inc. DG-805 Cellon Communications 50 C2052, Technology(Shenzhen) Co., Ltd. Cellon Communications 51 C2053, Technology(Shenzhen) Co., Ltd. Cellon Communications 52 C3031 Technology(Shenzhen) Co., Ltd. Cellon Communications 53 C5030, Technology(Shenzhen) Co., Ltd. -
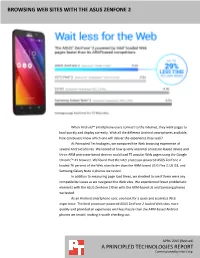
Browsing Web Sites with the Asus Zenfone 2
BROWSING WEB SITES WITH THE ASUS ZENFONE 2 When Android™ smartphone users connect to the Internet, they want pages to load quickly and display correctly. With all the different Android smartphones available, how can buyers know which one will deliver the experience they seek? At Principled Technologies, we compared the Web browsing experience of several Android phones. We looked at how quickly one Intel processor-based device and three ARM processor-based devices could load 75 popular Web pages using the Google Chrome™ 41 browser. We found that the Intel processor-powered ASUS ZenFone 2 loaded 76 percent of the Web sites faster than the ARM-based LG G Flex 2, LG G3, and Samsung Galaxy Note 4 phones we tested. In addition to measuring page load times, we checked to see if there were any compatibility issues as we navigated the Web sites. We experienced fewer problematic elements with the ASUS ZenFone 2 than with the ARM-based LG and Samsung phones we tested. As an Android smartphone user, you look for a quick and seamless Web experience. The Intel processor-powered ASUS ZenFone 2 loaded Web sites more quickly and provided an experience with less hassle than the ARM-based Android phones we tested, making it worth checking out. APRIL 2015 (Revised) A PRINCIPLED TECHNOLOGIES REPORT Commissioned by Intel Corp. A BETTER ANDROID WEB EXPERIENCE WITH ASUS & INTEL Android smartphones are a great way to view Web sites, though they don’t all behave the same way. A mobile device that does a speedy job of loading pages while displaying elements correctly can really improve the user experience. -

Case 5:18-Cv-06739-VKD Document 27 Filed 07/02/18 Page 1 of 11
Case 5:18-cv-06739-VKD Document 27 Filed 07/02/18 Page 1 of 11 IN THE UNITED STATES DISTRICT COURT FOR THE NORTHERN DISTRICT OF TEXAS DALLAS DIVISION § UNILOC USA, INC. and § UNILOC LUXEMBOURG, S.A., § Civil Action No. 3:18-cv-00560-DCG § Plaintiffs, § § v. § PATENT CASE § LG ELECTRONICS U.S.A., INC., § LG ELECTRONICS MOBILECOMM § U.S.A. INC. and § LG ELECTRONICS, INC., § § Defendant. § JURY TRIAL DEMANDED § FIRST AMENDED COMPLAINT FOR PATENT INFRINGEMENT Plaintiffs, Uniloc USA, Inc. (“Uniloc USA”) and Uniloc Luxembourg, S.A. (“Uniloc Luxembourg”) (together, “Uniloc”), for their First Amended Complaint against defendant, LG Electronics U.S.A. (“LGE”), Inc., LG Electronics Mobilecomm U.S.A., Inc., and LG Electronics, Inc., (“LG Korea”) (together “LG”), allege as follows:1 THE PARTIES 1. Uniloc USA is a Texas corporation having a principal place of business at Legacy Town Center I, Suite 380, 7160 Dallas Parkway, Plano Texas 75024. Uniloc USA also maintains a place of business at 102 N. College, Suite 603, Tyler, Texas 75702. 1 An amended complaint supersedes the original complaint and renders it of no legal effect, King v. Dogan, 31 F.3d 344. 346 (5th Cir. 1994), rendering a motion to dismiss the original complaint moot. See, e.g., Mangum v. United Parcel Services, No. 3:09-cv-0385, 2009 WL 2700217 (N.D. Tex. Aug. 26, 2009). 2988606.v1 Case 5:18-cv-06739-VKD Document 27 Filed 07/02/18 Page 2 of 11 2. Uniloc Luxembourg is a Luxembourg public limited liability company having a principal place of business at 15, Rue Edward Steichen, 4th Floor, L-2540, Luxembourg (R.C.S. -

Electronic 3D Models Catalogue (On July 26, 2019)
Electronic 3D models Catalogue (on July 26, 2019) Acer 001 Acer Iconia Tab A510 002 Acer Liquid Z5 003 Acer Liquid S2 Red 004 Acer Liquid S2 Black 005 Acer Iconia Tab A3 White 006 Acer Iconia Tab A1-810 White 007 Acer Iconia W4 008 Acer Liquid E3 Black 009 Acer Liquid E3 Silver 010 Acer Iconia B1-720 Iron Gray 011 Acer Iconia B1-720 Red 012 Acer Iconia B1-720 White 013 Acer Liquid Z3 Rock Black 014 Acer Liquid Z3 Classic White 015 Acer Iconia One 7 B1-730 Black 016 Acer Iconia One 7 B1-730 Red 017 Acer Iconia One 7 B1-730 Yellow 018 Acer Iconia One 7 B1-730 Green 019 Acer Iconia One 7 B1-730 Pink 020 Acer Iconia One 7 B1-730 Orange 021 Acer Iconia One 7 B1-730 Purple 022 Acer Iconia One 7 B1-730 White 023 Acer Iconia One 7 B1-730 Blue 024 Acer Iconia One 7 B1-730 Cyan 025 Acer Aspire Switch 10 026 Acer Iconia Tab A1-810 Red 027 Acer Iconia Tab A1-810 Black 028 Acer Iconia A1-830 White 029 Acer Liquid Z4 White 030 Acer Liquid Z4 Black 031 Acer Liquid Z200 Essential White 032 Acer Liquid Z200 Titanium Black 033 Acer Liquid Z200 Fragrant Pink 034 Acer Liquid Z200 Sky Blue 035 Acer Liquid Z200 Sunshine Yellow 036 Acer Liquid Jade Black 037 Acer Liquid Jade Green 038 Acer Liquid Jade White 039 Acer Liquid Z500 Sandy Silver 040 Acer Liquid Z500 Aquamarine Green 041 Acer Liquid Z500 Titanium Black 042 Acer Iconia Tab 7 (A1-713) 043 Acer Iconia Tab 7 (A1-713HD) 044 Acer Liquid E700 Burgundy Red 045 Acer Liquid E700 Titan Black 046 Acer Iconia Tab 8 047 Acer Liquid X1 Graphite Black 048 Acer Liquid X1 Wine Red 049 Acer Iconia Tab 8 W 050 Acer -

Lg G5 “Friends” Companion Devices Launch in Us
www.LG.com LG G5 “FRIENDS” COMPANION DEVICES LAUNCH IN US Available Now, LG CAM Plus, LG 360 CAM, LG 360 VR, LG TONE via Carriers, Retailers and on LG.COM ENGLEWOOD CLIFFS, N.J., May 24 2016 — Beginning today, LG Electronics’ (LG) customers in the US can get their hands on the highly anticipated LG G5 “Friends” companion devices, including the LG CAM Plus, LG 360 CAM, LG 360 VR and LG TONE Platinum™ on LG.com. The recently launched LG G5 smartphone showcases a new modular design that lets owners easily add LG Friends to transform the G5 into a DSLR-inspired camera, mobile virtual reality viewer and even a 360 video camera. The LG Friends are available now via major US carriers and at retail locations as well as the expanded LG online store – a destination to find great products that help customers get the most out of their favorite LG smartphones. LG.com will also serve as a way to order LG G5 batteries and new charging cradles in the coming weeks – which can be used to charge the G5. In addition, the online store offers batteries and charging cradles for beloved products such as the LG G3, LG G4, and LG V10*. For a limited time only, the store will be rewarding loyal customers with several promotions to celebrate some of LG’s most successful products and innovations. Consumers can take advantage of deep discounts including up to 70 percent off MSRP for, G4 and V10 battery and charger bundles starting for as low as $20.** “The LG ‘Friends’ make the G5 so much more than any other phone on the market. -

Udynamo Compatibility List
uDynamo Compatibility List Reader Manuf. Device Name Alt. Model Info Model Info OS OS Version Carrier Date Added Date Tested Type iDynamo 5 Apple iPad Air 2 Lightning N/A iOS N/A N/A Tablet iDynamo 5 Apple iPad Air* Lightning N/A iOS N/A N/A Tablet iDynamo 5 Apple iPad with Retina Display* Lightning N/A iOS N/A N/A Tablet iDynamo 5 Apple iPad mini 3 Lightning N/A iOS N/A N/A Tablet iDynamo 5 Apple iPad mini 2 Lightning N/A iOS N/A N/A Tablet iDynamo 5 Apple iPad mini* Lightning N/A iOS N/A N/A Tablet iDynamo 5 Apple iPhone 5c* Lightning N/A iOS N/A N/A Phone iDynamo 5 Apple iPhone 5s* Lightning N/A iOS N/A N/A Phone iDynamo 5 Apple iPhone 5* Lightning N/A iOS N/A N/A Phone iDynamo 5 Apple iPod touch (5th* generation) Lightning N/A iOS N/A N/A iPod iDynamo 5 Apple iPhone 6* Lightning N/A iOS N/A N/A Phone iDynamo 5 Apple iPhone 6 Plus* Lightning N/A iOS N/A N/A Phone iDynamo Apple iPad (3rd generation) 30 PIN N/A iOS N/A N/A Tablet iDynamo Apple iPad 2 30 PIN N/A iOS N/A N/A Tablet iDynamo Apple iPad 30 PIN N/A iOS N/A N/A Tablet iDynamo Apple iPhone 4s 30 PIN N/A iOS N/A N/A Phone iDynamo Apple iPhone 4 30 PIN N/A iOS N/A N/A Phone iDynamo Apple iPhone 3GS 30 PIN N/A iOS N/A N/A Phone iDynamo Apple iPod touch (3rd and 4th generation) 30 PIN N/A iOS N/A N/A iPod uDynamo Acer liquid MT liquid MT Android 2.3.6 101.18 1/24/14 1/24/14 uDynamo Alcatel Alcatel OneTouch Fierce 7024W Android 4.2.2 101.18 3/6/14 3/6/14 uDynamo ALCATEL Megane ALCATEL ONE TOUCH 5020T Android 4.1.2 101.18 8/10/15 8/10/15 uDynamo ALCATEL ALCATEL ONE TOUCH IDOL X ALCATEL -

D13.2 "MILS: Business, Legal and Social Acceptance"
D13.2 MILS: Business, Legal and Social Acceptance Project number: 31835 Project acronym: EURO-MILS EURO-MILS: Secure European Virtualisation Project title: for Trustworthy Applications in Critical Domains Start date of the project: 1st October, 2012 Duration: 42 months Programme: FP7/2007-2013 Deliverable type: Report Deliverable reference number: ICT-318353 / D13.2/ 1.0 Activity and Work package Activity A1 / WP 1.3 contributing to the deliverable: Due date: SEPT 2015 – M36 Actual submission date: 30th September 2015 Responsible organisation: JR Editor: Christophe Toulemonde Dissemination level: PU Revision: 1.0 Final report on EURO-MILS Work Package Abstract: 13 Business, Legal and Social Acceptances Virtualisation, MILS, security, safety, Keywords: trustworthiness D13.2 MILS: Business, Legal and Social Acceptance Editor Christophe Toulemonde, JR Contributors Jacques Brygier (SYSF), Holger Blasum, Sergey Tverdyshev (SYSGO), Bertrand Leconte (AOS), Kevin Müller (EADS IW), Axel Söding-Freiherr von Blomberg (OPSYN), Igor Furgel (TSYS), Martina Truskaller (TEC) Disclaimer “This project has received funding from the European Union’s Seventh Framework Programme for research, technological development and demonstration under grant agreement n° 318353”. This document has gone through the consortium’s internal review process and is still subject to the review of the European Commission. Updates to the content may be made at a later stage. EURO-MILS D13.2 I D13.2 MILS: Business, Legal and Social Acceptance Executive Summary This document is the result of EURO-MILS Work Package 1.3. The objective of the WP is to analyse the business impact of trustworthy ICT for networked high-criticality systems. A multistep work has be done to make a quantitative and qualitative analysis of the different markets and understand the potential of exploitation. -

California Proposition 65
AT&T Wireless Handsets, Tablets, Wearables and other Connected Wireless Products California Proposition 65 If you received a Proposition 65 warning on your receipt, packing slip or email confirmation document, please see the following list of products to determine which product you purchased is subject to the warning. Manufacturer SKU Marketing Name and/or model # ASUS 6588A ASUS PadFone X mini Black ASUS 6593A ASUS PadFone X mini Black ASUS 6594A ASUS PadFone X mini Black ASUS R588A ASUS PadFone X mini Black - certified like new ASUS R593A ASUS PadFone X mini Black - certified like new ASUS R594A ASUS PadFone X mini Black - certified like new ASUS S588A ASUS PadFone X mini Black - warranty replacement ASUS S593A ASUS PadFone X mini Black - warranty replacement ASUS S594A ASUS PadFone X mini Black - warranty replacement ASUS 6768A ASUS ZenFone 2E White ASUS 6769A ASUS ZenFone 2E White ASUS 6770A ASUS ZenFone 2E White ASUS R768A ASUS ZenFone 2E White - certified like new ASUS R769A ASUS ZenFone 2E White - certified like new ASUS R770A ASUS ZenFone 2E White - certified like new ASUS S768A ASUS ZenFone 2E White - warranty replacement ASUS S769A ASUS ZenFone 2E White - warranty replacement ASUS S770A ASUS ZenFone 2E White - warranty replacement ASUS 6722A ASUS MeMO Pad 7 LTE (ME375CL) -BLK ASUS 6723A ASUS MeMO Pad 7 LTE (ME375CL) -BLK ASUS 6725A ASUS MeMO Pad 7 LTE (ME375CL) -BLK May 18, 2016 © 2016 AT&T Intellectual Property. All rights reserved. AT&T and the Globe logo are registered trademarks of AT&T Intellectual Property. AT&T Wireless -

Dgipad-4544-Portable Power Max-Ss-V3
www.dreamGEAR.net | www.iSound.net 20001 S. Western Avenue, Torrance, CA 90501 tel: 310.222.5522 :: fax: 310.222.5577 Portable Power Max 16,000 mAh Backup Battery ITEM No. - DGIPAD-4544 UPC - 8 45620 04544 0 1 Inch 5.75 Inches COLOR - Black & Silver PRODUCT FEATURES Flashlight Switch The Portable Power Max is the only back up power supply you will ever Built-in again need while on the road. With its compact design and powerful Flashlight battery, you can squeeze more talk time and photos into multiple devices. The 5 USB ports allow you to charge and power any USB powered device, and the included USB to mini and micro USB cable means you don't have to carry around cables for each device. LED indicators let you know how much power is remaining, and a flashlight is built in to help you LED Charge & Power Status Indicator in the dark. The iSound Portable Power and Portable Power Max batteries use Lithium-ion Polymer, a gel type electrolyte. Unlike 3.25 Inches Lithium-ion batteries, which use a liquid, Lithium-ion Polymer batteries Power have less tendency to leak if cracked or otherwise damaged. Apple only Switch uses Lithium-ion Polymer batteries in the iPhone and iPad. Weight 14.6 oz • Battery with 16000 mAh (60 Wh) • Up to 480 hours of power for 5 USB powered devices simultaneously • Includes 5 USB ports for charging iPods, iPhones, iPads and any other USB powered devices • LED indicator for charging & power status • Power switch and LED status indicator • 100 / 240V AC adapter included Includes 100 / 240V • Built-in flashlight AC Adapter 5 USB Ports 1 USB to Mini USB / Micro USB Includes BlackBerry Adapter Cable included PRODUCT SPECIFICATIONS Portable Power Max Capacity: 16000 mAh Portable Power iPhone 5 iPad Air iPad iPod Touch iPhone 4 TRANSLATIONS Max Number of 4x .75x 1x 9x 5x PACKAGING | COMPLETE FRENCH: Yes | SPANISH: Yes Charges* USER GUIDE | COMPLETE FRENCH: Yes | SPANISH: Yes *Number of times you can charge that single device from a fully charged Portable Power Max. -

Lumo10 RGB Fast Wireless Charger
Lumo10 RGB Fast Wireless Charger #23426 RGB fast wireless charger for smartphones Fast wireless charger with RGB lights and 10W output to charge your Qi-compatible phone Key features • Round wireless charging pad for easy phone placement • Touch-and-charge: simply put your smartphone on the pad and it will charge automatically • With RGB LED lights (rainbow wave) • Works with all Qi-compatible smartphones • Charging works without removing your phone case (supports plastic cases up to 3mm thick) • Supports fast-charging 7.5W output for iPhone and 10W output for Samsung Galaxy phones What's in the box System requirements • Wireless charger • For fast charging: USB charger compatible with Quick Charge 2.0/3.0. Example: • Micro-USB cable • Wall charger: trust.com/21818 • User guide • For normal charging: USB charger with 2A power output • Smartphone compatible with Qi wireless charging Publication date: 12-10-2019 Item number: 23426 © 2019 Trust. All rights reserved. URL: www.trust.com/23426 All brand names are registered trademarks of their respective owners. EAN Code: 8713439234268 Specifications are subject to change without prior notice. High resolution images: www.trust.com/23426/materials Lumo10 RGB Fast Wireless Charger Fuss-Free Wireless Charging There’s no more need to hunt for a cable with the Lumo10 RGB Fast Wireless Charger 10W. Touch-and-charge any Qi-compatible smartphone easily and quickly – and enjoy the charger’s stylish design and RGB light show on the side. Touch-and-Charge Could it be any easier? Just connect the charging pad to a USB charger (not included), place your phone on the charger’s surface and it will begin powering up instantly. -

PD# Brand Model 1 Ipad 4 2 Mini Ipad 3 New Ipad 4 Ipad2 A1395 5 Ipad
PD# Brand Model 1 iPad 4 2 Mini iPad 3 New iPad 4 iPad2 A1395 5 iPad A1219 6 iPad MC349LL/A 7 iPhone5 8 iPhone4s MD239ZP 9 iPhone4 MD128ZP 10 iPhone 4 A1332 11 AT&T iPhone 4 12 AT&T iPhone 3Gs 13 iPhone 3Gs A1241 14 iPhone 3Gs MB489J/A 15 iPod touch 2G 16GB MB531J/A 16 iPod touch 32GB MB376J/A 17 iPod touch 32GB MC544J/A 18 iPod touch 3G 64GB MC011J/A Apple 19 iPod Touch A1288 20 iPod Classic A1238 21 iPod classic 160GB MB150J/A 22 iPod classic 160GB MC297J/A 23 iPod Classic 6.5Gen 120GB (MB565TA/A) 24 iPod nano 16GB MC526J/A 25 iPod nano 4G 16GB MB918J/A 26 iPod nano 8GB MB261J/A 27 iPod nano 5G 16GB MC060J/A 28 iPod shuffle 2G 1GB MB225J/A 29 iPod shuffle 3G 4GB MC164J/A 30 iPod shuffle2GB MC584J/A 31 iPod Nano A1285 32 iPod Nano A1366 33 iPod Shuffle A1271 34 iPod 1204 35 iPod iShuffle A1373 36 Samsung Galaxy Tab 7" 37 Samsung Galaxy Tab 10.1" 38 Samsung Galaxy Tab2 7.0” 39 Samsung Galaxy SIII 40 Samsung Galaxy SII 41 Samsung Galaxy Ace 42 Samsung Evergreen (SGH-A667) 43 Samsung SGH-A777 44 Samsung Solstice II (SGH-A817) 45 Samsung Samsung Rugby II (SGH-A847) 46 Samsung Flight II (SGH-A927) 47 Samsung Jack (SGH-i637) 48 Samsung Captivate (SGH-i897) 49 Samsung Focus (SGH-i917) 50 Samsung Infuse (SGH-i997) 51 Samsung GT-I9000 (Galaxy S I9000 8GB) 52 Samsung YP-P3 53 Samsung OMNIA II i8000 54 Samsung GOOGLE NEXUS S (GT-I9023) 55 Google Nexus 7 56 Kindle Wireless Reading Device (6'') Amazon 57 Kindle Fire HD 58 HTC Freestyle (F5151) 59 HTC HD7S (PD29150) 60 HTC Inspire 4G (PD98120) 61 HTC Tilt (ST7377) 62 HTC Surround (T8788) 63 HTC Desires