Distributed Reduplication
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Representation of Inflected Nouns in the Internal Lexicon
Memory & Cognition 1980, Vol. 8 (5), 415423 Represeritation of inflected nouns in the internal lexicon G. LUKATELA, B. GLIGORIJEVIC, and A. KOSTIC University ofBelgrade, Belgrade, Yugoslavia and M.T.TURVEY University ofConnecticut, Storrs, Connecticut 06268 and Haskins Laboratories, New Haven, Connecticut 06510 The lexical representation of Serbo-Croatian nouns was investigated in a lexical decision task. Because Serbo-Croatian nouns are declined, a noun may appear in one of several gram matical cases distinguished by the inflectional morpheme affixed to the base form. The gram matical cases occur with different frequencies, although some are visually and phonetically identical. When the frequencies of identical forms are compounded, the ordering of frequencies is not the same for masculine and feminine genders. These two genders are distinguished further by the fact that the base form for masculine nouns is an actual grammatical case, the nominative singular, whereas the base form for feminine nouns is an abstraction in that it cannot stand alone as an independent word. Exploiting these characteristics of the Serbo Croatian language, we contrasted three views of how a noun is represented: (1) the independent entries hypothesis, which assumes an independent representation for each grammatical case, reflecting its frequency of occurrence; (2) the derivational hypothesis, which assumes that only the base morpheme is stored, with the individual cases derived from separately stored inflec tional morphemes and rules for combination; and (3) the satellite-entries hypothesis, which assumes that all cases are individually represented, with the nominative singular functioning as the nucleus and the embodiment of the noun's frequency and around which the other cases cluster uniformly. -

Reduplication in Distributed Morphology
Reduplication in Distributed Morphology Item Type text; Article Authors Haugen, Jason D. Publisher University of Arizona Linguistics Circle (Tucson, Arizona) Journal Coyote Papers: Working Papers in Linguistics, Linguistic Theory at the University of Arizona Rights http://rightsstatements.org/vocab/InC/1.0/ Download date 27/09/2021 03:15:12 Item License Copyright © is held by the author(s). Link to Item http://hdl.handle.net/10150/143067 The Coyote Papers 18 (May 2011), University of Arizona Linguistics Department, Tucson, AZ, U.S.A. Reduplication in Distributed Morphology Jason D. Haugen Oberlin College [email protected] Keywords reduplication, Distributed Morphology, allomorphy, reduplicative allomorphy, base-dependence, Hiaki (Yaqui), Tawala Abstract The two extant approaches to reduplication in Distributed Morphology (DM) are: (i) the read- justment approach, where reduplication is claimed to result from a readjustment operation on some stem triggered by a (typically null) affix; and (ii) the affixation approach, where reduplica- tion is claimed to result from the insertion of a special type of Vocabulary Item (i.e. a reduplica- tive affix–“reduplicant" or \Red") which gets inserted into a syntactic node in order to discharge some morphosyntactic feature(s), but which receives its own phonological content from some other stem (i.e. its \base") in the output. This paper argues from phonologically-conditioned allomorphy pertaining to base-dependence, as in the case of durative reduplication in Tawala, that the latter approach best accounts for a necessary distinction between \reduplicants" and \bases" as different types of morphemes which display different phonological effects, including \the emergence of the unmarked" effects, in many languages. -

University of California Santa Cruz Minimal Reduplication
UNIVERSITY OF CALIFORNIA SANTA CRUZ MINIMAL REDUPLICATION A dissertation submitted in partial satisfaction of the requirements for the degree of DOCTOR OF PHILOSOPHY in LINGUISTICS by Jesse Saba Kirchner June 2010 The Dissertation of Jesse Saba Kirchner is approved: Professor Armin Mester, Chair Professor Jaye Padgett Professor Junko Ito Tyrus Miller Vice Provost and Dean of Graduate Studies Copyright © by Jesse Saba Kirchner 2010 Some rights reserved: see Appendix E. Contents Abstract vi Dedication viii Acknowledgments ix 1 Introduction 1 1.1 Structureofthethesis ...... ....... ....... ....... ........ 2 1.2 Overviewofthetheory...... ....... ....... ....... .. ....... 2 1.2.1 GoalsofMR ..................................... 3 1.2.2 Assumptionsandpredictions. ....... 7 1.3 MorphologicalReduplication . .......... 10 1.3.1 Fixedsize..................................... ... 11 1.3.2 Phonologicalopacity. ...... 17 1.3.3 Prominentmaterialpreferentiallycopied . ............ 22 1.3.4 Localityofreduplication. ........ 24 1.3.5 Iconicity ..................................... ... 24 1.4 Syntacticreduplication. .......... 26 2 Morphological reduplication 30 2.1 Casestudy:Kwak’wala ...... ....... ....... ....... .. ....... 31 2.2 Data............................................ ... 33 2.2.1 Phonology ..................................... .. 33 2.2.2 Morphophonology ............................... ... 40 2.2.3 -mut’ .......................................... 40 2.3 Analysis........................................ ..... 48 2.3.1 Lengtheningandreduplication. -

Greek and Latin Roots, Prefixes, and Suffixes
GREEK AND LATIN ROOTS, PREFIXES, AND SUFFIXES This is a resource pack that I put together for myself to teach roots, prefixes, and suffixes as part of a separate vocabulary class (short weekly sessions). It is a combination of helpful resources that I have found on the web as well as some tips of my own (such as the simple lesson plan). Lesson Plan Ideas ........................................................................................................... 3 Simple Lesson Plan for Word Study: ........................................................................... 3 Lesson Plan Idea 2 ...................................................................................................... 3 Background Information .................................................................................................. 5 Why Study Word Roots, Prefixes, and Suffixes? ......................................................... 6 Latin and Greek Word Elements .............................................................................. 6 Latin Roots, Prefixes, and Suffixes .......................................................................... 6 Root, Prefix, and Suffix Lists ........................................................................................... 8 List 1: MEGA root list ................................................................................................... 9 List 2: Roots, Prefixes, and Suffixes .......................................................................... 32 List 3: Prefix List ...................................................................................................... -

Types and Functions of Reduplication in Palembang
Journal of the Southeast Asian Linguistics Society JSEALS 12.1 (2019): 113-142 ISSN: 1836-6821, DOI: http://hdl.handle.net/10524/52447 University of Hawaiʼi Press TYPES AND FUNCTIONS OF REDUPLICATION IN PALEMBANG Mardheya Alsamadani & Samar Taibah Wayne State University [email protected] & [email protected] Abstract In this paper, we study the morphosemantic aspects of reduplication in Palembang (also known as Musi). In Palembang, both content and function words undergo reduplication, generating a wide variety of semantic functions, such as pluralization, iteration, distribution, and nominalization. Productive reduplication includes full reduplication and reduplication plus affixation, while fossilized reduplication includes partial reduplication and rhyming reduplication. We employed the Distributed Morphology theory (DM) (Halle and Marantz 1993, 1994) to account for these different patterns of reduplication. Moreover, we compared the functions of Palembang reduplication to those of Malay and Indonesian reduplication. Some instances of function word reduplication in Palembang were not found in these languages, such as reduplication of question words and reduplication of negators. In addition, Palembang partial reduplication is fossilized, with only a few examples collected. In contrast, Malay partial reduplication is productive and utilized to create new words, especially words borrowed from English (Ahmad 2005). Keywords: Reduplication, affixation, Palembang/Musi, morphosemantics ISO 639-3 codes: mui 1 Introduction This paper has three purposes. The first is to document the reduplication patterns found in Palembang based on the data collected from three Palembang native speakers. Second, we aim to illustrate some shared features of Palembang reduplication with those found in other Malayic languages such as Indonesian and Malay. The third purpose is to provide a formal analysis of Palembang reduplication based on the Distributed Morphology Theory. -

Morphological Sources of Phonological Length
Morphological Sources of Phonological Length by Anne Pycha B.A. (Brown University) 1993 M.A. (University of California, Berkeley) 2004 A dissertation submitted in partial satisfaction of the requirements for the degree of Doctor of Philosophy in Linguistics in the Graduate Division of the University of California, Berkeley Committee in charge: Professor Sharon Inkelas (chair) Professor Larry Hyman Professor Keith Johnson Professor Johanna Nichols Spring 2008 Abstract Morphological Sources of Phonological Length by Anne Pycha Doctor of Philosophy in Linguistics University of California, Berkeley Professor Sharon Inkelas, Chair This study presents and defends Resizing Theory, whose claim is that the overall size of a morpheme can serve as a basic unit of analysis for phonological alternations. Morphemes can increase their size by any number of strategies -- epenthesizing new segments, for example, or devoicing an existing segment (and thereby increasing its phonetic duration) -- but it is the fact of an increase, and not the particular strategy used to implement it, which is linguistically significant. Resizing Theory has some overlap with theories of fortition and lenition, but differs in that it uses the independently- verifiable parameter of size in place of an ad-hoc concept of “strength” and thereby encompasses a much greater range of phonological alternations. The theory makes three major predictions, each of which is supported with cross-linguistic evidence. First, seemingly disparate phonological alternations can achieve identical morphological effects, but only if they trigger the same direction of change in a morpheme’s size. Second, morpheme interactions can take complete control over phonological outputs, determining surface outputs when traditional features and segments fail to do so. -

Derivational and Inflectional Prefixes and Suffixes in Batusesa Dialect of Balinese: a Descriptive Study
ISSN: 2549-4287 Vol.1, No.1, February 2017 DERIVATIONAL AND INFLECTIONAL PREFIXES AND SUFFIXES IN BATUSESA DIALECT OF BALINESE: A DESCRIPTIVE STUDY Ariani, N.K. English Education Department, Ganesha University of Education e-mail: [email protected] Abstract This study was designed in the form of descriptive qualitative study with the aim at describing the prefixes and suffixes in Batusesa Dialect of Balinese which belong to derivational and inflectional morpheme. The techniques used to collect the data were observation, recording and interview technique. In this study, there were three informants chosen. The results of this study show that there are four kinds of prefixes found in Batusesa Dialect, namely {n-}, {me-}, {pe-}, and {a-} and five kinds of suffixes namely {-ang}, {-nә}, {-in}, {-an} and {-ә}. There are three kinds of prefixes and one kind of suffixes which belong to derivational morpheme, namely {n-}, {me-}, {pe-}, and {-ang}. Moreover there are three kinds of inflectional prefixes namely {n-}, {me-}, and {a-} and four kinds of suffixes which belong to inflectional morpheme, namely {-nә}, {-in}, {-an} and {-ә}. There were some grammatical functions of prefixes and suffixes in Batusesa dialect of Balinese, namely affix forming verbal, affix forming nominal, affix forming numeral, affix forming adjective, and affix forming adverb, activizer and passivizer. Keyword: prefixes, suffixes, derivational, inflectional INTRODUCTION Language is an important aspect in human life. It is a means of communication of a person to the others. The people need language to looking for and give people benefit information. People need language as a means of communication to express their feeling, though and desire. -

Part VI More Affixes
68 Part VI More Affixes PARTICLES Verbs and nouns tend to be complex in Oneida because they can have many internal parts. The particles, however, are simpler in form. They tend to be short - one, two, or three syllables. They perform a number of different functions in the language, some of them are quite straightforward and have easy English translations, while others cover ranges of meaning that are subtle and nearly impossible to translate. Sometimes a sequence of particles has a meaning that is distinct from the meaning of any of the particles in the sequence. The use of particles is part of what distinguishes different styles of speaking. More are used in ceremonial speech, for example. One can begin to learn the particles by grouping some of the more straightforward ones by function. They deal with time, place, extent, grammatical connectives, and conversational interaction. Question Particles náhte÷ what náhohte what (sentence final form) úhka náhte÷ who kánhke when to nikaha=wí= when kátsa÷ nu where (requires a locative or partitive prefix) kátsa÷ ka=y§= which one náhte÷ aolí=wa÷ why, for what reason oh ni=yót how to ni=kú how much to niha=tí how many people to niku=tí how many females Time Particles elhúwa recently o=n§ or n< now, or at that time &wa or n&wa or nu÷ú now, or today oksa÷ right away, soon swatye=l§ sometimes ty%tkut always yotk@=te always yah nuw<=tú never 69 Place Particles @kta nearby @kte somewhere else @tste outside é=nike up, above ehtá=ke down, below k§=tho here k<h nu here k<h nukwá this way ohná=k< back, -

Morphological Well-Formedness As a Derivational Constraint on Syntax: Verbal Inflection in English1
Morphological Well-Formedness as a Derivational Constraint on Syntax: Verbal Inflection in English 1 John Frampton and Sam Gutmann Northeastern University November 1999 ::: the English verb and its auxiliaries are always a source of fascination. Indeed, I think we can say, following Neumeyer (1980), that much of the intellectual success of Chomsky (1957) is due precisely to its strikingly attractive analysis of this inflectional system. (Emonds, 1985, A Unified Theory of Syntactic Categories) The now well-known differences between verb raising in English and French that were first explored by Emonds (1978), and later analyzed in more depth by Pollock (1989), played an important role in the early development of Chomsky's (1995) Min- imalist Program (MP). See Chomsky (1991), in particular, for an analysis in terms of economy of derivation. As the MP developed, the effort to analyze verb raising largely receded. Lasnik (1996), however, took the question up again and showed that fairly broad empirical coverage could be achieved within the MP framework. One important empirical gap (which will be discussed later) remained, and various stipulations about the feature makeup of inserted lexical items were required. In this paper we hope both to remove the empirical gap and to reduce the stipulative aspects of Lasnik's proposal. The larger ambition of this paper is to support the effort, begun in Frampton and Gutmann (1999), to reorient the MP away from economy principles, particularly away from the idea that comparison of derivations is relevant to grammaticality. Here, we will assume certain key ideas from that paper and show how they provide a productive framework for an analysis of verb raising. -

Introduction Introduction
Introduction Introduction -- porke ja7at jch^ayem jolat i ma7ba ya awich^ tal awinam ya xtal sk^anantabat abiluk ja7 yu7unil awil xtal ajok^obe bi7 a xch^ay awu7une kjipat ta karsel xbaht kak^at ta karsel, ha-ha-ha yawich^ awotan7a porke ya xch^ay sjol te sakil winik, ha-ha-ha because you are crazy and you don’t bring your woman (wife).2 You have to take care of your things; and look, it is because of this that you come to ask for what you lost. I will throw you in jail, I will go to leave you in jail! ha-ha-ha This will make you learn! ha-ha-ha The tirade above was launched (mostly in jest) by angry Fransisca, the mother of my host family in Petalcingo, when after a frantic search all over the house for my little desk lamp it turned out that I had hidden it myself in my backpack earlier that day. The quote, which alternatively references me in the second and third person, is replete with references to him and his, and you and yours, which, rather than being realized as pronouns (as in English) are marked by agreement morphemes on the verb and the possessed noun. The morphology and syntax of these agreement morphemes is the topic of the present thesis. Since overt pronouns are quite rare in Tzeltal discourse, the agreement markers usually are the only way of indicating who is doing what to whom, and what is possessed by whom. The fact that the same markers are used to indicate the subject of a transitive verb as well as the possessor of a thing, while not entirely uncommon in the world’s languages, is one of the interesting properties exhibited by Tzeltal. -
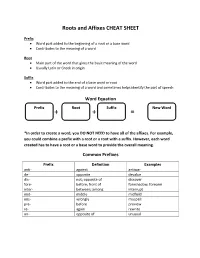
Roots and Affixes CHEAT SHEET
Roots and Affixes CHEAT SHEET Prefix Word part added to the beginning of a root or a base word Contributes to the meaning of a word Root Main part of the word that gives the basic meaning of the word Usually Latin or Greek in origin Suffix Word part added to the end of a base word or root Contributes to the meaning of a word and sometimes helps identify the part of speech Word Equation Prefix Root Suffix New Word + + = *In order to create a word, you DO NOT NEED to have all of the affixes. For example, you could combine a prefix with a root or a root with a suffix. However, each word created has to have a root or a base word to provide the overall meaning. Common Prefixes Prefix Definition Examples anti- against antiwar de- opposite devalue dis- not; opposite of discover fore- before; front of foreshadow, forearm inter- between; among interrupt mid- middle midfield mis- wrongly misspell pre- before preview re- again rewrite un- opposite of unusual Common Roots Roots Definition Examples aqua water aquarium, aquamarine aud to hear audience, audition auto self autobiography, automobile bio life biology, biography cent one hundred century, percent chron time chronological, chronic contra/counter against contradict, encounter hypo below; beneath hypothermia, hypothetical jud judge judicial, prejudice mit to send transmit, admit mono one monologue, monotonous multi many multimedia, multiple port to carry portable, transportation pseudo false pseudonym, pseudoscience voc voice; to call vocalize, advocate Common Suffixes Prefix Definition Examples -able, -ible is; can be affordable, sensible -al, -ial having characteristics of universal, facial -ful full of helpful -ic having characteristics of poetic -ion, -tion, -ation, submission, motion, -tion act; process relation, edition -ity, -ty state of activity, society -less without hopeless -ment state of being; act of contentment -ness state of; condition of openness riotous, courageous, -ous, -eous, -ious having qualities of gracious . -

Re Reduplication Author(S): Alec Marantz Source: Linguistic Inquiry, Vol
Re Reduplication Author(s): Alec Marantz Source: Linguistic Inquiry, Vol. 13, No. 3 (Summer, 1982), pp. 435-482 Published by: The MIT Press Stable URL: http://www.jstor.org/stable/4178287 Accessed: 22/10/2009 18:41 Your use of the JSTOR archive indicates your acceptance of JSTOR's Terms and Conditions of Use, available at http://www.jstor.org/page/info/about/policies/terms.jsp. JSTOR's Terms and Conditions of Use provides, in part, that unless you have obtained prior permission, you may not download an entire issue of a journal or multiple copies of articles, and you may use content in the JSTOR archive only for your personal, non-commercial use. Please contact the publisher regarding any further use of this work. Publisher contact information may be obtained at http://www.jstor.org/action/showPublisher?publisherCode=mitpress. Each copy of any part of a JSTOR transmission must contain the same copyright notice that appears on the screen or printed page of such transmission. JSTOR is a not-for-profit service that helps scholars, researchers, and students discover, use, and build upon a wide range of content in a trusted digital archive. We use information technology and tools to increase productivity and facilitate new forms of scholarship. For more information about JSTOR, please contact [email protected]. The MIT Press is collaborating with JSTOR to digitize, preserve and extend access to Linguistic Inquiry. http://www.jstor.org Alec Marantz Re Reduplication In the recent literature, reduplicationhas been claimed to cause two serious problems for theories of morphologyand phonology.