Analysis of Multiple Single Nucleotide Polymorphisms of Candidate Genes Related to Coronary Heart Disease Susceptibility by Using Support Vector Machines
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Hemoglobin Interaction with Gp1ba Induces Platelet Activation And
ARTICLE Platelet Biology & its Disorders Hemoglobin interaction with GP1bα induces platelet activation and apoptosis: a novel mechanism associated with intravascular hemolysis Rashi Singhal,1,2,* Gowtham K. Annarapu,1,2,* Ankita Pandey,1 Sheetal Chawla,1 Amrita Ojha,1 Avinash Gupta,1 Miguel A. Cruz,3 Tulika Seth4 and Prasenjit Guchhait1 1Disease Biology Laboratory, Regional Centre for Biotechnology, National Capital Region, Biotech Science Cluster, Faridabad, India; 2Biotechnology Department, Manipal University, Manipal, Karnataka, India; 3Thrombosis Research Division, Baylor College of Medicine, Houston, TX, USA, and 4Hematology, All India Institute of Medical Sciences, New Delhi, India *RS and GKA contributed equally to this work. ABSTRACT Intravascular hemolysis increases the risk of hypercoagulation and thrombosis in hemolytic disorders. Our study shows a novel mechanism by which extracellular hemoglobin directly affects platelet activation. The binding of Hb to glycoprotein1bα activates platelets. Lower concentrations of Hb (0.37-3 mM) significantly increase the phos- phorylation of signaling adapter proteins, such as Lyn, PI3K, AKT, and ERK, and promote platelet aggregation in vitro. Higher concentrations of Hb (3-6 mM) activate the pro-apoptotic proteins Bak, Bax, cytochrome c, caspase-9 and caspase-3, and increase platelet clot formation. Increased plasma Hb activates platelets and promotes their apoptosis, and plays a crucial role in the pathogenesis of aggregation and development of the procoagulant state in hemolytic disorders. Furthermore, we show that in patients with paroxysmal nocturnal hemoglobinuria, a chronic hemolytic disease characterized by recurrent events of intravascular thrombosis and thromboembolism, it is the elevated plasma Hb or platelet surface bound Hb that positively correlates with platelet activation. -

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated. -
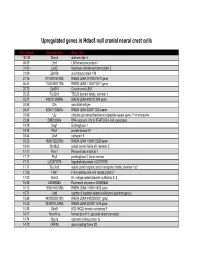
Supp Table 1.Pdf
Upregulated genes in Hdac8 null cranial neural crest cells fold change Gene Symbol Gene Title 134.39 Stmn4 stathmin-like 4 46.05 Lhx1 LIM homeobox protein 1 31.45 Lect2 leukocyte cell-derived chemotaxin 2 31.09 Zfp108 zinc finger protein 108 27.74 0710007G10Rik RIKEN cDNA 0710007G10 gene 26.31 1700019O17Rik RIKEN cDNA 1700019O17 gene 25.72 Cyb561 Cytochrome b-561 25.35 Tsc22d1 TSC22 domain family, member 1 25.27 4921513I08Rik RIKEN cDNA 4921513I08 gene 24.58 Ofa oncofetal antigen 24.47 B230112I24Rik RIKEN cDNA B230112I24 gene 23.86 Uty ubiquitously transcribed tetratricopeptide repeat gene, Y chromosome 22.84 D8Ertd268e DNA segment, Chr 8, ERATO Doi 268, expressed 19.78 Dag1 Dystroglycan 1 19.74 Pkn1 protein kinase N1 18.64 Cts8 cathepsin 8 18.23 1500012D20Rik RIKEN cDNA 1500012D20 gene 18.09 Slc43a2 solute carrier family 43, member 2 17.17 Pcm1 Pericentriolar material 1 17.17 Prg2 proteoglycan 2, bone marrow 17.11 LOC671579 hypothetical protein LOC671579 17.11 Slco1a5 solute carrier organic anion transporter family, member 1a5 17.02 Fbxl7 F-box and leucine-rich repeat protein 7 17.02 Kcns2 K+ voltage-gated channel, subfamily S, 2 16.93 AW493845 Expressed sequence AW493845 16.12 1600014K23Rik RIKEN cDNA 1600014K23 gene 15.71 Cst8 cystatin 8 (cystatin-related epididymal spermatogenic) 15.68 4922502D21Rik RIKEN cDNA 4922502D21 gene 15.32 2810011L19Rik RIKEN cDNA 2810011L19 gene 15.08 Btbd9 BTB (POZ) domain containing 9 14.77 Hoxa11os homeo box A11, opposite strand transcript 14.74 Obp1a odorant binding protein Ia 14.72 ORF28 open reading -

Cellular and Molecular Signatures in the Disease Tissue of Early
Cellular and Molecular Signatures in the Disease Tissue of Early Rheumatoid Arthritis Stratify Clinical Response to csDMARD-Therapy and Predict Radiographic Progression Frances Humby1,* Myles Lewis1,* Nandhini Ramamoorthi2, Jason Hackney3, Michael Barnes1, Michele Bombardieri1, Francesca Setiadi2, Stephen Kelly1, Fabiola Bene1, Maria di Cicco1, Sudeh Riahi1, Vidalba Rocher-Ros1, Nora Ng1, Ilias Lazorou1, Rebecca E. Hands1, Desiree van der Heijde4, Robert Landewé5, Annette van der Helm-van Mil4, Alberto Cauli6, Iain B. McInnes7, Christopher D. Buckley8, Ernest Choy9, Peter Taylor10, Michael J. Townsend2 & Costantino Pitzalis1 1Centre for Experimental Medicine and Rheumatology, William Harvey Research Institute, Barts and The London School of Medicine and Dentistry, Queen Mary University of London, Charterhouse Square, London EC1M 6BQ, UK. Departments of 2Biomarker Discovery OMNI, 3Bioinformatics and Computational Biology, Genentech Research and Early Development, South San Francisco, California 94080 USA 4Department of Rheumatology, Leiden University Medical Center, The Netherlands 5Department of Clinical Immunology & Rheumatology, Amsterdam Rheumatology & Immunology Center, Amsterdam, The Netherlands 6Rheumatology Unit, Department of Medical Sciences, Policlinico of the University of Cagliari, Cagliari, Italy 7Institute of Infection, Immunity and Inflammation, University of Glasgow, Glasgow G12 8TA, UK 8Rheumatology Research Group, Institute of Inflammation and Ageing (IIA), University of Birmingham, Birmingham B15 2WB, UK 9Institute of -

Confirmation of Pathogenic Mechanisms by SARS-Cov-2–Host
Messina et al. Cell Death and Disease (2021) 12:788 https://doi.org/10.1038/s41419-021-03881-8 Cell Death & Disease ARTICLE Open Access Looking for pathways related to COVID-19: confirmation of pathogenic mechanisms by SARS-CoV-2–host interactome Francesco Messina 1, Emanuela Giombini1, Chiara Montaldo1, Ashish Arunkumar Sharma2, Antonio Zoccoli3, Rafick-Pierre Sekaly2, Franco Locatelli4, Alimuddin Zumla5, Markus Maeurer6,7, Maria R. Capobianchi1, Francesco Nicola Lauria1 and Giuseppe Ippolito 1 Abstract In the last months, many studies have clearly described several mechanisms of SARS-CoV-2 infection at cell and tissue level, but the mechanisms of interaction between host and SARS-CoV-2, determining the grade of COVID-19 severity, are still unknown. We provide a network analysis on protein–protein interactions (PPI) between viral and host proteins to better identify host biological responses, induced by both whole proteome of SARS-CoV-2 and specific viral proteins. A host-virus interactome was inferred, applying an explorative algorithm (Random Walk with Restart, RWR) triggered by 28 proteins of SARS-CoV-2. The analysis of PPI allowed to estimate the distribution of SARS-CoV-2 proteins in the host cell. Interactome built around one single viral protein allowed to define a different response, underlining as ORF8 and ORF3a modulated cardiovascular diseases and pro-inflammatory pathways, respectively. Finally, the network-based approach highlighted a possible direct action of ORF3a and NS7b to enhancing Bradykinin Storm. This network-based representation of SARS-CoV-2 infection could be a framework for pathogenic evaluation of specific 1234567890():,; 1234567890():,; 1234567890():,; 1234567890():,; clinical outcomes. -

MALE Protein Name Accession Number Molecular Weight CP1 CP2 H1 H2 PDAC1 PDAC2 CP Mean H Mean PDAC Mean T-Test PDAC Vs. H T-Test
MALE t-test t-test Accession Molecular H PDAC PDAC vs. PDAC vs. Protein Name Number Weight CP1 CP2 H1 H2 PDAC1 PDAC2 CP Mean Mean Mean H CP PDAC/H PDAC/CP - 22 kDa protein IPI00219910 22 kDa 7 5 4 8 1 0 6 6 1 0.1126 0.0456 0.1 0.1 - Cold agglutinin FS-1 L-chain (Fragment) IPI00827773 12 kDa 32 39 34 26 53 57 36 30 55 0.0309 0.0388 1.8 1.5 - HRV Fab 027-VL (Fragment) IPI00827643 12 kDa 4 6 0 0 0 0 5 0 0 - 0.0574 - 0.0 - REV25-2 (Fragment) IPI00816794 15 kDa 8 12 5 7 8 9 10 6 8 0.2225 0.3844 1.3 0.8 A1BG Alpha-1B-glycoprotein precursor IPI00022895 54 kDa 115 109 106 112 111 100 112 109 105 0.6497 0.4138 1.0 0.9 A2M Alpha-2-macroglobulin precursor IPI00478003 163 kDa 62 63 86 72 14 18 63 79 16 0.0120 0.0019 0.2 0.3 ABCB1 Multidrug resistance protein 1 IPI00027481 141 kDa 41 46 23 26 52 64 43 25 58 0.0355 0.1660 2.4 1.3 ABHD14B Isoform 1 of Abhydrolase domain-containing proteinIPI00063827 14B 22 kDa 19 15 19 17 15 9 17 18 12 0.2502 0.3306 0.7 0.7 ABP1 Isoform 1 of Amiloride-sensitive amine oxidase [copper-containing]IPI00020982 precursor85 kDa 1 5 8 8 0 0 3 8 0 0.0001 0.2445 0.0 0.0 ACAN aggrecan isoform 2 precursor IPI00027377 250 kDa 38 30 17 28 34 24 34 22 29 0.4877 0.5109 1.3 0.8 ACE Isoform Somatic-1 of Angiotensin-converting enzyme, somaticIPI00437751 isoform precursor150 kDa 48 34 67 56 28 38 41 61 33 0.0600 0.4301 0.5 0.8 ACE2 Isoform 1 of Angiotensin-converting enzyme 2 precursorIPI00465187 92 kDa 11 16 20 30 4 5 13 25 5 0.0557 0.0847 0.2 0.4 ACO1 Cytoplasmic aconitate hydratase IPI00008485 98 kDa 2 2 0 0 0 0 2 0 0 - 0.0081 - 0.0 -

Exploratory Aspirin Resistance Trial in Healthy Japanese Volunteers (J-ART) Using Platelet Aggregation As a Measure of Thrombogenicity
The Pharmacogenomics Journal (2007) 7, 395–403 & 2007 Nature Publishing Group All rights reserved 1470-269X/07 $30.00 www.nature.com/tpj ORIGINAL ARTICLE Exploratory aspirin resistance trial in healthy Japanese volunteers (J-ART) using platelet aggregation as a measure of thrombogenicity T Fujiwara1, M Ikeda2, K Esumi3, Aspirin prevents the production of thromboxane A2 (TXA2) by irreversibly 4 5 inhibiting platelet cyclooxygenase, exhibiting antiplatelet actions. This agent TD Fujita , M Kono , has been reported to prevent relapse in patients with ischemic heart disease 6 4 H Tokushige , T Hatoyama , or cerebral infarction via this action mechanism. However, there are T Maeda7, T Asai4, T Ogawa6, individual differences in this action, and aspirin is not effective in some T Katsumata4, S Sasaki8, patients, which is referred to as ‘aspirin resistance’. In this study, we analyzed E Suzuki7, M Suzuki5, F Hino9, laboratory aspirin resistance by platelet aggregation in 110 healthy adult 10 10 Japanese males using 24 single-nucleotide polymorphisms (SNPs) of nine TK Fujita , H Zaima , genes involved in platelet aggregation/hemorrhage. Among SNPs involved M Shimada9, T Sugawara8, in platelet aggregation, aspirin was less effective for 924T homozygote of a 10 3 Y Tsuzuki , Y Hashimoto , TXA2 receptor, 924T4C, and 1018C homozygote of a platelet membrane H Hishigaki1, S Horimoto5, glycoprotein GPIba, 1018C4T, suggesting that 924T and 1018C alleles are 2 4 involved in aspirin resistance. N Miyajima , T Yamamoto , The Pharmacogenomics Journal (2007) -

The Human in Vivo Biomolecule Corona Onto Pegylated Liposomes
RevisedView metadata, Manuscript citation and similar papers at core.ac.uk brought to you by CORE provided by Nottingham Trent Institutional Repository (IRep) 1 2 3 4 5 6 The human in vivo biomolecule corona onto PEGylated 7 8 liposomes: a proof-of-concept clinical study 9 10 11 Marilena Hadjidemetriou1, Sarah McAdam2, Grace Garner2, Chelsey Thackeray3, David Knight4, Duncan 12 Smith5, Zahraa Al-Ahmady1, Mariarosa Mazza1, Jane Rogan2, Andrew Clamp3 and Kostas Kostarelos1* 13 14 15 16 17 1Nanomedicine Lab, Faculty of Biology, Medicine & Health, AV Hill Building, The University of Manchester, Manchester, United Kingdom; 2 18 Manchester Cancer Research Centre Biobank, The Christie NHS Foundation Trust, CRUK Manchester Institute, Manchester, United Kingdom 3Institute of Cancer Sciences and The Christie NHS Foundation Trust, Manchester Cancer Research Centre (MCRC), 19 University of Manchester, Manchester, United Kingdom 20 4Bio-MS Facility, Michael Smith Building, The University of Manchester, Manchester, United Kingdom; 21 5xCRUK Manchester Institute, The University of Manchester, Manchester, United Kingdom 22 23 24 25 26 27 28 29 30 31 _______________________________________ 32 * Correspondence should be addressed to: [email protected] 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 1 63 64 65 1 2 3 4 5 Abstract 6 7 The self-assembled layered adsorption of proteins onto nanoparticle (NP) surfaces, once in contact 8 with biological fluids, has been termed the ‘protein corona’ and it is gradually seen as a determinant 9 10 factor for the overall biological behavior of NPs. -

Related Cardiometabolic and Renal Biomarkers in Human Plasma And
www.nature.com/scientificreports OPEN Comparative analysis of obesity- related cardiometabolic and renal biomarkers in human plasma and serum Meenu Rohini Rajan1,2,16, Matus Sotak 1,2,16, Fredrik Barrenäs1,2,3, Tong Shen4, Kamil Borkowski4, Nicholas J. Ashton2,5,6,7, Christina Biörserud9, Tomas L. Lindahl10, Sofa Ramström10,11, Michael Schöll2,5,8, Per Lindahl1, Oliver Fiehn 4, John W. Newman 4,12,13, Rosie Perkins 1, Ville Wallenius9, Stephan Lange 1,14 & Emma Börgeson 1,2,15,17* The search for biomarkers associated with obesity-related diseases is ongoing, but it is not clear whether plasma and serum can be used interchangeably in this process. Here we used high-throughput screening to analyze 358 proteins and 76 lipids, selected because of their relevance to obesity- associated diseases, in plasma and serum from age- and sex-matched lean and obese humans. Most of the proteins/lipids had similar concentrations in plasma and serum, but a subset showed signifcant diferences. Notably, a key marker of cardiovascular disease PAI-1 showed a diference in concentration between the obese and lean groups only in plasma. Furthermore, some biomarkers showed poor correlations between plasma and serum, including PCSK9, an important regulator of cholesterol homeostasis. Collectively, our results show that the choice of biofuid may impact study outcome when screening for obesity-related biomarkers and we identify several markers where this will be the case. Obesity-related illness is an increasingly important global health issue that places a tremendous economic burden on society1. Te negative health efects of prolonged obesity are partly fuelled by chronic low-grade infammation, which contributes to cardiometabolic and kidney pathophysiology2–4. -

Multi-Platforms Approach for Plasma Proteomics: Complementarity of Olink PEA Technology to Mass Spectrometry-Based Protein Profi
bioRxiv preprint doi: https://doi.org/10.1101/2020.08.04.236356; this version posted August 6, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. Multi-platforms approach for plasma proteomics: complementarity of Olink PEA technology to mass spectrometry-based protein profiling Agnese Petrera1, Christine von Toerne1, Jennifer Behler1, Cornelia Huth2, Barbara Thorand2, Anne Hilgendorff3 and Stefanie M. Hauck1* 1 Research Unit Protein Science and Core Facility Proteomics, Helmholtz Zentrum München, German Research Center for Environmental Health (GmbH), Neuherberg, Germany 2 Institute of Epidemiology, Helmholtz Zentrum München, German Research Center for Environmental Health (GmbH), Neuherberg, Germany 3 Institute for Lung Biology and Disease and Comprehensive Pneumology Center with the CPC- M bioArchive, Helmholtz Zentrum München, German Research Center for Environmental Health (GmbH), Neuherberg, Germany *Corresponding author: Stefanie M. Hauck, [email protected] Running title: Complementarity of Olink PEA technology to mass spectrometry bioRxiv preprint doi: https://doi.org/10.1101/2020.08.04.236356; this version posted August 6, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. Complementarity of Olink PEA technology to mass spectrometry Abbreviation PEA: Proximity Extension Assay DDA: Data-dependent acquisition DIA: Data-independent acquisition LC-MS/MS: liquid chromatography mass spectrometry FDR: false discovery rate ID: identification KORA: Cooperative Health Research in the Region of Augsburg Olink panels: C-MET cardiometabolic; CVDII cardiovascular II; CVDIII cardiovascular III; ONCII oncology II; ONCIII oncology III; DEV development; IMM immune response; NEU neurology 2 bioRxiv preprint doi: https://doi.org/10.1101/2020.08.04.236356; this version posted August 6, 2020. -

GP1BA Gene Glycoprotein Ib Platelet Subunit Alpha
GP1BA gene glycoprotein Ib platelet subunit alpha Normal Function The GP1BA gene provides instructions for making a protein called glycoprotein Ib-alpha (GPIba ). This protein is one piece (subunit) of a protein complex called GPIb-IX-V, which plays a role in blood clotting. GPIb-IX-V is found on the surface of small cells called platelets, which circulate in blood and are an essential component of blood clots. The complex can attach (bind) to a protein called von Willebrand factor, fitting together like a lock and its key. Von Willebrand factor is found on the inside surface of blood vessels, particularly when there is an injury. Binding of the GPIb-IX-V complex to von Willebrand factor allows platelets to stick to the blood vessel wall at the site of the injury. These platelets form clots, plugging holes in the blood vessels to help stop bleeding. To form the GPIb-IX-V complex, GPIba interacts with other protein subunits called GPIb- beta, GPIX, and GPV, each of which is produced from a different gene. GPIba is essential for assembly of the complex at the platelet surface. It is the piece of the complex that interacts with von Willebrand factor to trigger blood clotting. GPIba also interacts with other blood clotting proteins to aid in other steps of the clotting process. Health Conditions Related to Genetic Changes Bernard-Soulier syndrome At least 54 GP1BA gene mutations have been found to cause Bernard-Soulier syndrome, a condition characterized by a reduced number of platelets that are larger than normal (macrothrombocytopenia) and excessive bleeding. -

Bleeding Thrombotic and Platelet Disorder TIER1 Genes (V.ISTH 2020.1)
Bleeding Thrombotic and Platelet Disorder TIER1 genes (v.ISTH_2020.1) Gene Category Associated disorder(s) Inheritance Transcript Location symbol Bleeding/coagulation F10 Factor X deficiency AR; AD NM_000504.3 13q34 Bleeding/coagulation F11 Factor XI deficiency AR; AD NM_000128.3 4q35.2 Coagulation Factor XII deficiency AR (coagulation) F12 NM_000505.3 5q35.3 Angioedema Angioedema AD (angioedema) Bleeding/coagulation F13A1 Factor XIII deficiency AR NM_000129.3 6p25.1 Bleeding/coagulation F13B Factor XIII deficiency AR NM_001994.2 1q31.3 Bleeding/coagulation Prothrombin deficiency AR (bleeding/coagulation) Thrombosis F2 Thrombophilia due to AD (thrombosis) NM_000506.4 11p11.2 thrombin defect Bleeding/coagulation Factor V deficiency AR (bleeding/coagulation) Thrombosis F5 Thrombophilia due to AD (thrombosis) NM_000130.4 1q24.2 activated protein C resistance Bleeding/coagulation F7 Factor VII deficiency AR; AD NM_000131.4 13q34 Bleeding/coagulation F8 Haemophilia A XLR NM_000132.3 Xq28 Bleeding/coagulation F9 Haemophilia B XLR NM_000133.3 Xq27.1 AR (afibrinogenemia); Bleeding FGA Fibrinogen deficiency AD NM_000508.3 4q31.3 (hypo/dysfibrinogenemia) AR (afibrinogenemia); Bleeding FGB Fibrinogen deficiency AD NM_005141.4 4q31.3 (hypo/dysfibrinogenemia) AR (afibrinogenemia); Bleeding FGG Fibrinogen deficiency AD NM_021870.2 4q32.1 (hypo/dysfibrinogenemia) Vitamin K-dependent clotting Bleeding/coagulation GGCX AR NM_000821.6 2p11.2 factors deficiency 1 Coagulation KNG1 Kininogen Deficiency AR NM_000893.4 3q27.3 Combined factor V and VIII Bleeding/coagulation