Wrangling Phosphoproteomic Data to Elucidate Cancer Signaling Pathways
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Human RET Kinase Protein (His Tag)
Human RET Kinase Protein (His Tag) Catalog Number: 11997-H08H1 General Information SDS-PAGE: Gene Name Synonym: CDHF12; CDHR16; HSCR1; MEN2A; MEN2B; MTC1; PTC; RET-ELE1; RET51 Protein Construction: A DNA sequence encoding the extracellular domain of human RET (P07949-1) (Met 1-Arg 635) was fused with a polyhistidine tag at the N- terminus. Source: Human Expression Host: HEK293 Cells QC Testing Purity: > 92 % as determined by SDS-PAGE Protein Description Endotoxin: RET proto-oncogene, also known as RET, is a cell-surface molecule that < 1.0 EU per μg of the protein as determined by the LAL method transduce signals for cell growth and differentiation. It contains 1 cadherin domain and 1 protein kinase domain. RET proto-oncogene belongs to the Stability: protein kinase superfamily, tyr protein kinase family. RET proto-oncogene is involved in numerous cellular mechanisms including cell proliferation, ℃ Samples are stable for up to twelve months from date of receipt at -70 neuronal navigation, cell migration, and cell differentiation upon binding with glial cell derived neurotrophic factor family ligands. It phosphorylates Leu 29 Predicted N terminal: PTK2/FAK1 and regulates both cell death/survival balance and positional Molecular Mass: information. RET is required for the molecular mechanisms orchestration during intestine organogenesis; involved in the development of enteric The recombinant human RET consists of 618 amino acids and has a nervous system and renal organogenesis during embryonic life; promotes calculated molecular mass of 69.1 kDa. The apparent molecular mass of the formation of Peyer's patch-like structures; modulates cell adhesion via the protein is approximately 110-120 kDa in SDS-PAGE under reducing its cleavage; involved in the development of the neural crest. -

Promoter Janus Kinase 3 Proximal Characterization and Analysis Of
The Journal of Immunology Characterization and Analysis of the Proximal Janus Kinase 3 Promoter1 Martin Aringer,2*† Sigrun R. Hofmann,2* David M. Frucht,* Min Chen,* Michael Centola,* Akio Morinobu,* Roberta Visconti,* Daniel L. Kastner,* Josef S. Smolen,† and John J. O’Shea3* Janus kinase 3 (Jak3) is a nonreceptor tyrosine kinase essential for signaling via cytokine receptors that comprise the common ␥-chain (␥c), i.e., the receptors for IL-2, IL-4, IL-7, IL-9, IL-15, and IL-21. Jak3 is preferentially expressed in hemopoietic cells and is up-regulated upon cell differentiation and activation. Despite the importance of Jak3 in lymphoid development and immune function, the mechanisms that govern its expression have not been defined. To gain insight into this issue, we set out to characterize the Jak3 promoter. The 5-untranslated region of the Jak3 gene is interrupted by a 3515-bp intron. Upstream of this intron and the transcription initiation site, we identified an ϳ1-kb segment that exhibited lymphoid-specific promoter activity and was responsive to TCR signals. Truncation of this fragment revealed that core promoter activity resided in a 267-bp fragment that contains putative Sp-1, AP-1, Ets, Stat, and other binding sites. Mutation of the AP-1 sites significantly diminished, whereas mutation of the Ets sites abolished, the inducibility of the promoter construct. Chromatin immunoprecipitation assays showed that histone acetylation correlates with mRNA expression and that Ets-1/2 binds this region. Thus, transcription factors that bind these sites, especially Ets family members, are likely to be important regulators of Jak3 expression. -

Human and Mouse CD Marker Handbook Human and Mouse CD Marker Key Markers - Human Key Markers - Mouse
Welcome to More Choice CD Marker Handbook For more information, please visit: Human bdbiosciences.com/eu/go/humancdmarkers Mouse bdbiosciences.com/eu/go/mousecdmarkers Human and Mouse CD Marker Handbook Human and Mouse CD Marker Key Markers - Human Key Markers - Mouse CD3 CD3 CD (cluster of differentiation) molecules are cell surface markers T Cell CD4 CD4 useful for the identification and characterization of leukocytes. The CD CD8 CD8 nomenclature was developed and is maintained through the HLDA (Human Leukocyte Differentiation Antigens) workshop started in 1982. CD45R/B220 CD19 CD19 The goal is to provide standardization of monoclonal antibodies to B Cell CD20 CD22 (B cell activation marker) human antigens across laboratories. To characterize or “workshop” the antibodies, multiple laboratories carry out blind analyses of antibodies. These results independently validate antibody specificity. CD11c CD11c Dendritic Cell CD123 CD123 While the CD nomenclature has been developed for use with human antigens, it is applied to corresponding mouse antigens as well as antigens from other species. However, the mouse and other species NK Cell CD56 CD335 (NKp46) antibodies are not tested by HLDA. Human CD markers were reviewed by the HLDA. New CD markers Stem Cell/ CD34 CD34 were established at the HLDA9 meeting held in Barcelona in 2010. For Precursor hematopoetic stem cell only hematopoetic stem cell only additional information and CD markers please visit www.hcdm.org. Macrophage/ CD14 CD11b/ Mac-1 Monocyte CD33 Ly-71 (F4/80) CD66b Granulocyte CD66b Gr-1/Ly6G Ly6C CD41 CD41 CD61 (Integrin b3) CD61 Platelet CD9 CD62 CD62P (activated platelets) CD235a CD235a Erythrocyte Ter-119 CD146 MECA-32 CD106 CD146 Endothelial Cell CD31 CD62E (activated endothelial cells) Epithelial Cell CD236 CD326 (EPCAM1) For Research Use Only. -

Inhibition of Src Family Kinases and Receptor Tyrosine Kinases by Dasatinib: Possible Combinations in Solid Tumors
Published OnlineFirst June 13, 2011; DOI: 10.1158/1078-0432.CCR-10-2616 Clinical Cancer Molecular Pathways Research Inhibition of Src Family Kinases and Receptor Tyrosine Kinases by Dasatinib: Possible Combinations in Solid Tumors Juan Carlos Montero1, Samuel Seoane1, Alberto Ocaña2,3, and Atanasio Pandiella1 Abstract Dasatinib is a small molecule tyrosine kinase inhibitor that targets a wide variety of tyrosine kinases implicated in the pathophysiology of several neoplasias. Among the most sensitive dasatinib targets are ABL, the SRC family kinases (SRC, LCK, HCK, FYN, YES, FGR, BLK, LYN, and FRK), and the receptor tyrosine kinases c-KIT, platelet-derived growth factor receptor (PDGFR) a and b, discoidin domain receptor 1 (DDR1), c-FMS, and ephrin receptors. Dasatinib inhibits cell duplication, migration, and invasion, and it triggers apoptosis of tumoral cells. As a consequence, dasatinib reduces tumoral mass and decreases the metastatic dissemination of tumoral cells. Dasatinib also acts on the tumoral microenvironment, which is particularly important in the bone, where dasatinib inhibits osteoclastic activity and favors osteogenesis, exerting a bone-protecting effect. Several preclinical studies have shown that dasatinib potentiates the antitumoral action of various drugs used in the oncology clinic, paving the way for the initiation of clinical trials of dasatinib in combination with standard-of-care treatments for the therapy of various neoplasias. Trials using combinations of dasatinib with ErbB/HER receptor antagonists are being explored in breast, head and neck, and colorectal cancers. In hormone receptor–positive breast cancer, trials using combina- tions of dasatinib with antihormonal therapies are ongoing. Dasatinib combinations with chemother- apeutic agents are also under development in prostate cancer (dasatinib plus docetaxel), melanoma (dasatinib plus dacarbazine), and colorectal cancer (dasatinib plus oxaliplatin plus capecitabine). -

The Regulatory Roles of Phosphatases in Cancer
Oncogene (2014) 33, 939–953 & 2014 Macmillan Publishers Limited All rights reserved 0950-9232/14 www.nature.com/onc REVIEW The regulatory roles of phosphatases in cancer J Stebbing1, LC Lit1, H Zhang, RS Darrington, O Melaiu, B Rudraraju and G Giamas The relevance of potentially reversible post-translational modifications required for controlling cellular processes in cancer is one of the most thriving arenas of cellular and molecular biology. Any alteration in the balanced equilibrium between kinases and phosphatases may result in development and progression of various diseases, including different types of cancer, though phosphatases are relatively under-studied. Loss of phosphatases such as PTEN (phosphatase and tensin homologue deleted on chromosome 10), a known tumour suppressor, across tumour types lends credence to the development of phosphatidylinositol 3--kinase inhibitors alongside the use of phosphatase expression as a biomarker, though phase 3 trial data are lacking. In this review, we give an updated report on phosphatase dysregulation linked to organ-specific malignancies. Oncogene (2014) 33, 939–953; doi:10.1038/onc.2013.80; published online 18 March 2013 Keywords: cancer; phosphatases; solid tumours GASTROINTESTINAL MALIGNANCIES abs in sera were significantly associated with poor survival in Oesophageal cancer advanced ESCC, suggesting that they may have a clinical utility in Loss of PTEN (phosphatase and tensin homologue deleted on ESCC screening and diagnosis.5 chromosome 10) expression in oesophageal cancer is frequent, Cao et al.6 investigated the role of protein tyrosine phosphatase, among other gene alterations characterizing this disease. Zhou non-receptor type 12 (PTPN12) in ESCC and showed that PTPN12 et al.1 found that overexpression of PTEN suppresses growth and protein expression is higher in normal para-cancerous tissues than induces apoptosis in oesophageal cancer cell lines, through in 20 ESCC tissues. -

Role of Focal Adhesion Kinase in Small-Cell Lung Cancer and Its Potential As a Therapeutic Target
cancers Review Role of Focal Adhesion Kinase in Small-Cell Lung Cancer and Its Potential as a Therapeutic Target Frank Aboubakar Nana 1,2 , Marie Vanderputten 1 and Sebahat Ocak 1,3,* 1 Institut de Recherche Expérimentale et Clinique (IREC), Pôle de Pneumologie, ORL et Dermatologie (PNEU), Université catholique de Louvain (UCLouvain), 1200 Brussels, Belgium; [email protected] (F.A.N.); [email protected] (M.V.) 2 Division of Pneumology, Cliniques Universitaires St-Luc, UCL, 1200 Brussels, Belgium 3 Division of Pneumology, CHU UCL Namur (Godinne Site), UCL, 5530 Yvoir, Belgium * Correspondence: [email protected]; Tel.: +32-2-764-9448; Fax: +32-2-764-9440 Received: 15 September 2019; Accepted: 24 October 2019; Published: 29 October 2019 Abstract: Small-cell lung cancer (SCLC) represents 15% of all lung cancers and it is clinically the most aggressive type, being characterized by a tendency for early metastasis, with two-thirds of the patients diagnosed with an extensive stage (ES) disease and a five-year overall survival (OS) as low as 5%. There are still no effective targeted therapies in SCLC despite improved understanding of the molecular steps leading to SCLC development and progression these last years. After four decades, the only modest improvement in OS of patients suffering from ES-SCLC has recently been shown in a trial combining atezolizumab, an anti-PD-L1 immune checkpoint inhibitor, with carboplatin and etoposide, chemotherapy agents. This highlights the need to pursue research efforts in this field. Focal adhesion kinase (FAK) is a non-receptor protein tyrosine kinase that is overexpressed and activated in several cancers, including SCLC, and contributing to cancer progression and metastasis through its important role in cell proliferation, survival, adhesion, spreading, migration, and invasion. -
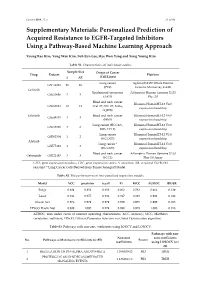
Personalized Prediction of Acquired Resistance to EGFR-Targeted Inhibitors Using a Pathway-Based Machine Learning Approach
Cancers 2019, 11, x S1 of S9 Supplementary Materials: Personalized Prediction of Acquired Resistance to EGFR-Targeted Inhibitors Using a Pathway-Based Machine Learning Approach Young Rae Kim, Yong Wan Kim, Suh Eun Lee, Hye Won Yang and Sung Young Kim Table S1. Characteristics of individual studies. Sample Size Origin of Cancer Drug Dataset Platform S AR (Cell Lines) Lung cancer Agilent-014850 Whole Human GSE34228 26 26 (PC9) Genome Microarray 4x44K Gefitinib Epidermoid carcinoma Affymetrix Human Genome U133 GSE10696 3 3 (A431) Plus 2.0 Head and neck cancer Illumina HumanHT-12 V4.0 GSE62061 12 12 (Cal-27, SSC-25, FaDu, expression beadchip SQ20B) Erlotinib Head and neck cancer Illumina HumanHT-12 V4.0 GSE49135 3 3 (HN5) expression beadchip Lung cancer (HCC827, Illumina HumanHT-12 V3.0 GSE38310 3 6 ER3, T15-2) expression beadchip Lung cancer Illumina HumanHT-12 V3.0 GSE62504 1 2 (HCC827) expression beadchip Afatinib Lung cancer * Illumina HumanHT-12 V4.0 GSE75468 1 3 (HCC827) expression beadchip Head and neck cancer Affymetrix Human Genome U133 Cetuximab GSE21483 3 3 (SCC1) Plus 2.0 Array GEO, gene expression omnibus; GSE, gene expression series; S, sensitive; AR, acquired EGFR-TKI resistant; * Lung Cancer Cells Derived from Tumor Xenograft Model. Table S2. The performances of four penalized regression models. Model ACC precision recall F1 MCC AUROC BRIER Ridge 0.889 0.852 0.958 0.902 0.782 0.964 0.129 Lasso 0.944 0.957 0.938 0.947 0.889 0.991 0.042 Elastic Net 0.978 0.979 0.979 0.979 0.955 0.999 0.023 EPSGO Elastic Net 0.989 1.000 0.979 0.989 0.978 1.000 0.018 AUROC, area under curve of receiver operating characteristic; ACC, accuracy; MCC, Matthews correlation coefficient; EPSGO, Efficient Parameter Selection via Global Optimization algorithm. -

Pdf/Infopackage Kinex.Pdf for a Com- Domain Inhibition (15)
Protein Tyrosine Phosphatase Receptor Type γ Is a JAK Phosphatase and Negatively Regulates Leukocyte Integrin Activation This information is current as Michela Mirenda, Lara Toffali, Alessio Montresor, Giovanni of October 1, 2021. Scardoni, Claudio Sorio and Carlo Laudanna J Immunol 2015; 194:2168-2179; Prepublished online 26 January 2015; doi: 10.4049/jimmunol.1401841 http://www.jimmunol.org/content/194/5/2168 Downloaded from Supplementary http://www.jimmunol.org/content/suppl/2015/01/23/jimmunol.140184 Material 1.DCSupplemental http://www.jimmunol.org/ References This article cites 46 articles, 16 of which you can access for free at: http://www.jimmunol.org/content/194/5/2168.full#ref-list-1 Why The JI? Submit online. • Rapid Reviews! 30 days* from submission to initial decision • No Triage! Every submission reviewed by practicing scientists by guest on October 1, 2021 • Fast Publication! 4 weeks from acceptance to publication *average Subscription Information about subscribing to The Journal of Immunology is online at: http://jimmunol.org/subscription Permissions Submit copyright permission requests at: http://www.aai.org/About/Publications/JI/copyright.html Email Alerts Receive free email-alerts when new articles cite this article. Sign up at: http://jimmunol.org/alerts The Journal of Immunology is published twice each month by The American Association of Immunologists, Inc., 1451 Rockville Pike, Suite 650, Rockville, MD 20852 Copyright © 2015 by The American Association of Immunologists, Inc. All rights reserved. Print ISSN: 0022-1767 Online ISSN: 1550-6606. The Journal of Immunology Protein Tyrosine Phosphatase Receptor Type g Is a JAK Phosphatase and Negatively Regulates Leukocyte Integrin Activation Michela Mirenda,* Lara Toffali,*,† Alessio Montresor,*,† Giovanni Scardoni,† Claudio Sorio,* and Carlo Laudanna*,† Regulation of signal transduction networks depends on protein kinase and phosphatase activities. -

The Extracellular Matrix for Bone Regeneration
This chapter is based on human mesenchymal stromal cells in adhesion to cell-derived 5 extracellular matrix and titanium: a comparative kinome profi le analysis Marta Baroncelli1^, Gwenny M. Fuhler2^, Jeroen van de Peppel1, Willian F. Zambuzzi3, Johannes P.T.M van Leeuwen1, Bram C.J van der Eerden1°, Maikel P. Peppelenbosch2° 1Department of Internal Medicine, Erasmus MC. University Medical Center Rotterdam, Wytemaweg 80, 3015 CN, Rotterdam, The Netherlands 2Department of Gastroenterology and Hepatology, Erasmus MC, University Medical Center Rotterdam, Wytemaweg 80, 3015 CN, Rotterdam, The Netherlands 3Laboratorio de Bioensaios e Dinâmica Celular, Dep.to de Quimica e Bioquimica, Instituto de Biociências, Universidade Estadual Paulista- UNESP, Campus Botucatu, São Paulo, SP Brazil. ^, °: both authors contributed equally to this work Submitted Chapter 5 ABSTRACT The extracellular matrix (ECM) is an essential component of tissue architecture that physically supports cells and actively influences stem cell behaviour, by modulating kinase-mediated signaling cascades that are the key regulators of signal transduc- tion. Cell-derived ECMs have recently emerged in the context of bone regeneration, as they reproduce physiological tissue-architecture and ameliorate the promising properties of mesenchymal stromal cells (MSCs). Titanium scaffolds show good mechanical properties and porosity to facilitate cell adhesion, and thus have been routinely used for bone tissue engineering applications. The aim of this study was to analyze the kinomic signature of human MSCs in adhesion to an osteoblast-derived ECM that we have previously shown to be osteopromotive, and to compare it to MSCs on titanium. PamChip kinase array analysis revealed 63 phosphorylated peptides on ECM and 59 on titanium, with MSCs on ECM exhibiting significant higher levels of kinase activity than those on titanium. -

Protein Tyrosine Kinases: Their Roles and Their Targeting in Leukemia
cancers Review Protein Tyrosine Kinases: Their Roles and Their Targeting in Leukemia Kalpana K. Bhanumathy 1,*, Amrutha Balagopal 1, Frederick S. Vizeacoumar 2 , Franco J. Vizeacoumar 1,3, Andrew Freywald 2 and Vincenzo Giambra 4,* 1 Division of Oncology, College of Medicine, University of Saskatchewan, Saskatoon, SK S7N 5E5, Canada; [email protected] (A.B.); [email protected] (F.J.V.) 2 Department of Pathology and Laboratory Medicine, College of Medicine, University of Saskatchewan, Saskatoon, SK S7N 5E5, Canada; [email protected] (F.S.V.); [email protected] (A.F.) 3 Cancer Research Department, Saskatchewan Cancer Agency, 107 Wiggins Road, Saskatoon, SK S7N 5E5, Canada 4 Institute for Stem Cell Biology, Regenerative Medicine and Innovative Therapies (ISBReMIT), Fondazione IRCCS Casa Sollievo della Sofferenza, 71013 San Giovanni Rotondo, FG, Italy * Correspondence: [email protected] (K.K.B.); [email protected] (V.G.); Tel.: +1-(306)-716-7456 (K.K.B.); +39-0882-416574 (V.G.) Simple Summary: Protein phosphorylation is a key regulatory mechanism that controls a wide variety of cellular responses. This process is catalysed by the members of the protein kinase su- perfamily that are classified into two main families based on their ability to phosphorylate either tyrosine or serine and threonine residues in their substrates. Massive research efforts have been invested in dissecting the functions of tyrosine kinases, revealing their importance in the initiation and progression of human malignancies. Based on these investigations, numerous tyrosine kinase inhibitors have been included in clinical protocols and proved to be effective in targeted therapies for various haematological malignancies. -

Rabbit Anti-Phospho-Ret-SL3384R-FITC
SunLong Biotech Co.,LTD Tel: 0086-571- 56623320 Fax:0086-571- 56623318 E-mail:[email protected] www.sunlongbiotech.com Rabbit Anti-Phospho-Ret SL3384R-FITC Product Name: Anti-Phospho-Ret (Tyr905)/FITC Chinese Name: FITC标记的磷酸化RET原癌基因抗体 Ret(Phospho Y905); Ret Proto-Oncogene; Cadherin-Related Family Member 16; Rearranged During Transfection; RET Receptor Tyrosine Kinase; Cadherin Family Member 12; Proto-Oncogene C-Ret; EC 2.7.10.1; CDHF12; CDHR16; RET51; PTC; Ret Proto-Oncogene (Multiple Endocrine Neoplasia And Medullary Thyroid Carcinoma Alias: 1, Hirschsprung Disease) ; Multiple Endocrine Neoplasia And Medullary Thyroid Carcinoma 1; Proto-Oncogene Tyrosine-Protein Kinase Receptor Ret; Hydroxyaryl- Protein Kinase; RET Transforming Sequence; Receptor Tyrosine Kinase; Hirschsprung Disease 1; Oncogene RET; EC 2.7.10; RET-ELE1; MEN2B; HSCR1; MEN2A; MTC1; RET_HUMAN. Organism Species: Rabbit Clonality: Polyclonal React Species: Human,Mouse,Rat,Chicken,Dog,Cow,Rabbit,Sheep,Guinea Pig, IF=1:50-200 Applications: not yet tested in other applications. optimalwww.sunlongbiotech.com dilutions/concentrations should be determined by the end user. Molecular weight: 34/76/122kDa Form: Lyophilized or Liquid Concentration: 1mg/ml KLH conjugated Synthesised phosphopeptide derived from human Ret around the immunogen: phosphorylation site of Tyr905 Lsotype: IgG Purification: affinity purified by Protein A Storage Buffer: 0.01M TBS(pH7.4) with 1% BSA, 0.03% Proclin300 and 50% Glycerol. Store at -20 ℃ for one year. Avoid repeated freeze/thaw cycles. The lyophilized antibody is stable at room temperature for at least one month and for greater than a year Storage: when kept at -20℃. When reconstituted in sterile pH 7.4 0.01M PBS or diluent of antibody the antibody is stable for at least two weeks at 2-4 ℃. -

PTK2 (Human) Cell-Based ELISA Kit
PTK2 (Human) Cell-Based ELISA Kit Catalog # : KA2852 規格 : [ 1 Kit ] List All Specification Application Image Product PTK2 (Human) Cell-Based ELISA Kit is an indirect enzyme-linked Qualitative Description: immunoassay for qualitative determination of PTK2 expression in cultured cells. Reactivity: Human, Mouse, Rat Storage Store the kit at 4°C. Instruction: Protocol: Protocol Download Suitable Attached Cell, Loosely Attached Cell, Suspension Cell Sample: Label: HRP-conjugated Detection Colorimetric Method: Regulation For research use only (RUO) Status: Applications Qualitative Gene Information Entrez GeneID: 5747 Protein Q05397 Accession#: Gene Name: PTK2 Gene Alias: FADK,FAK,FAK1,pp125FAK Gene PTK2 protein tyrosine kinase 2 Description: Omim ID: 600758 Gene Ontology: Hyperlink Gene Summary: This gene encodes a cytoplasmic protein tyrosine kinase which is found concentrated in the focal adhesions that form between cells growing in the presence of extracellular matrix constituents. The encoded protein is a member of the FAK subfamily of protein tyrosine kinases but lacks significant sequence similarity to kinases from other subfamilies. Activation of this gene may be an important early step in cell growth and intracellular signal transduction pathways triggered in response to certain neural peptides or to cell interactions with the extracellular Page 1 of 2 2017/2/16 matrix. At least four transcript variants encoding four different isoforms have been found for this gene, but the full-length natures of only two of them have been determined.