An Algorithm for Controlled Text Analysis on Wikipedia
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Viking Voicejan2014.Pub
Volume 2 February 2014 Viking Voice PENN DELCO SCHOOL DISTRICT Welcome 2014 Northley students have been busy this school year. They have been playing sports, performing in con- certs, writing essays, doing homework and projects, and enjoying life. Many new and exciting events are planned for the 2014 year. Many of us will be watching the Winter Olympics, going to plays and con- certs, volunteering in the community, participating in Reading Across America for Dr. Seuss Night, and welcoming spring. The staff of the Viking Voice wishes everyone a Happy New Year. Northley’s Students are watching Guys and Dolls the 2014 Winter Olympics Northley’s 2014 Musical ARTICLES IN By Vivian Long and Alexis Bingeman THE VIKING V O I C E This year’s winter Olympics will take place in Sochi Russia. This is the This year’s school musical is Guy and • Olympic Events first time in Russia’s history that they Dolls Jr. Guys and Dolls is a funny musical • Guys and Dolls will host the Winter Olympic Games. set in New York in the 40’s centering on Sochi is located in Krasnodar, which is gambling guys and their dolls (their girl • Frozen: a review, a the third largest region of Russia, with friends). Sixth grader, Billy Fisher, is playing survey and excerpt a population of about 400,000. This is Nathan Detroit, a gambling guy who is always • New Words of the located in the south western corner of trying to find a place to run his crap game. Year Russia. The events will be held in two Emma Robinson is playing Adelaide, Na- • Scrambled PSSA different locations. -

ISU Communication 1788
INTERNATIONAL SKATING UNION Communication No. 1788 Results of the 2013 ISU Championships A. Speed Skating European Speed Skating Championships, Heerenveen, Netherlands January 11 - 13, 2013 Organizing Member: Koninklijke Nederlandsche Schaatsenrijders Bond Ladies 500 m 3000 m 1500 m 5000 m points 1. Ireen Wüst, Netherlands 39:69 4:01.25 1:56.39 7:01.95 160.889 2013 Lady European Speed Skating Champion 2. Linda de Vries, Netherlands 39.98 4:05.33 1:57.57 7:02.77 162.335 3. Diane Valkenburg, Netherlands 39.93 4:05.84 1:57.76 7:05.56 162.712 Winners of the distances: Karolina Erbanová, Czech Republic 38.72 Ireen Wüst, Netherlands 4:01.25 1:56.39 Martina Sábliková, Czech Republic 6:57.16 Men 500 m 5000 m 1500 m 10000 m points 1. Sven Kramer, Netherlands 36.70 6:12.55 1:47.49 12:55.98 148.584 2013 European Speed Skating Champion 2. Jan Blokhuijsen, Netherlands 36.40 6:18.16 1:47.89 13:01.60 149.259 3. Håvard Bøkko, Norway 36.14 6:23.38 1:46.78 13:08.16 149.479 Winners of the distances: Konrad Niedzwiedzki, Poland 35, 93 1:46.32 Sven Kramer, Netherlands 6:12.55 12:55.98 1 World Sprint Speed Skating Championships, Salt Lake City, USA January 26 - 27, 2013 Organizing Member: U.S. Speedskating Ladies 500 m 1000 m 500 m 1000 m points 1. Heather Richardson, USA 37.31 1:13.74 37.24 1:13.19 148.015 2013 Lady World Sprint Speed Skating Champion 2. -

Yard Bulletin September 7, 2018 You May View the Yard Bulletin on the FYE Website (Bit.Ly/Yardbulletin)
First-Year Experience Office Volume 2022 Issue III Yard Bulletin September 7, 2018 You may view the Yard Bulletin on the FYE website (bit.ly/yardbulletin). Upcoming Events Course Offerings • Saturday, September 8, 6-8 PM—Laser The Mindich Program in Engaged Scholarship. Tag–You’re It! Come channel your inner This exciting Initiative at Harvard College brings kid and play laser tag with the Harvard community engagement into the curriculum. College Dance Marathon (HCDM) Board. Through community engagement that connects Join HCDM for their welcome back kick-off event. Come learning and action, Engaged Scholarship ready to have the time of your life and learn more about courses take learning beyond the classroom to link your how to get involved with this new group on campus. All academic work to questions, problems, and opportunities in participants will leave with some cool HCDM swag! Sever the real world. Please contact Flavia C. Peréa Quad, Harvard Yard. ([email protected]), Director, Mindich Program for Engaged Scholarship, with any questions, or visit: • Saturday, September 8, 7:30-10PM— engagedscholarship.fas.harvard.edu. Fall courses are: A Cappella Jam. Join the audience for a series of performances as an introduction to the vibrant • SPANSH 59: Spanish and the Community. María Parra- and active a cappella community on campus! Velasco. Tuesdays & Thursdays, 1:30-2:45PM. With all officially recognized a cappella groups • HEB 1200: Neanderthals and Other Extinct Humans. performing in this joint extravaganza, this show promises Bridget Alex. Tuesdays & Thursdays, 10:30-11:45AM. to deliver a night of music and performances for all to enjoy! Doors open at 7PM; free tickets available at the • SOC-STD 68UH: Urban Health and Community door. -

Evaluation of Ice Skaters' Technical Skills
Evaluation of ice skaters’ technical skills Minkyu Kim [email protected] Motivation During a skater’s performance in an ice link, due to his or her fast and intricate movements, audiences hardly recognize how well the player’s performance is done from the perspective of technical skills. If a program can count the number of spins he or she does or detect the position and angle of foot before and after jump, which is important to judge the quality of jumps and finally give us a score for the technical skills, it will be very useful. Goal In this study, a skater’s motion is recognized through image processing in MATLAB to evaluate her technical skills. For example, to judge how well a play is done, the number of spinning a skater does is counted and the angles and relative positions of her feet when she jumps from and lands on the ground are tracked and quantified in MATLAB where a database for the judging criteria is saved beforehand. Therefore, before referees’ announcement for the final score the skater gets, we are able to calculate the score. Design A skater’s performance is recorded as a wmv file and saved in MATLAB. The skater’s motion is then read frame by frame in MATLAB. By using intensity threshold and edge detection combined with image processing techniques such as Particle Swarm Optimization (PSO), mean shift model, and so on [1-3], only her motion is highlighted frame by frame and anything else becomes dark or vice versa. By observing and analyzing each frame, the number of spinning or other technical movements is recognized. -

The Inside Edge: Sisterhood of the Traveling Earring | Icenetwork.Com: Your Home for figure Skating and Speed Skating
6/29/2018 The Inside Edge: Sisterhood of the traveling earring | icenetwork.com: Your home for figure skating and speed skating. Subscribe Login Register HOME SCHEDULE + RESULTS SKATERS NEWS PHOTOS FANS The Inside Edge: Sisterhood of the traveling earring Andrews gets earring from Babilonia, who originally gave it to Yamaguchi Posted 1/23/14 by Sarah S. Brannen and Drew Meekins, special to icenetwork Starr Andrews dons the earring that Olympic champ Kristi Yamaguchi once wore. Sarah S. Brannen An earring's journey When we talked to Starr Andrews after the juvenile ladies event, we noticed a pretty earring in her left ear, a small gold hoop with a crystal heart dangling from it. We didn't realize we had seen it before: Kristi Yamaguchi wore it as she won her Olympic gold medal in Albertville. It turns out that Tai Babilonia gave the earring to Yamaguchi back in 1992, and she wore it for the entire Olympic competition and for years afterward. "I really wanted to give her something special, something really cool," Babilonia told us. "And I saw her wearing it on the cover of Sports Illustrated." http://web.icenetwork.com/news/2014/01/23/67027190 1/5 6/29/2018 The Inside Edge: Sisterhood of the traveling earring | icenetwork.com: Your home for figure skating and speed skating. "I got it from Tai during a trying time when I competed," Yamaguchi said. "I wore it for good luck, and it symbolized strength and hope for me." Yamaguchi eventually gave the earring to Katia Gordeeva after the death of Gordeeva's husband, Sergei Grinkov, and eventually Gordeeva gave it back to Babilonia. -

Gutsy Performance in Sochi
Recitation E Gutsy Performance in Sochi One of Japan’s most popular athletes should have known she couldn’t leave quietly. Mao Asada’s press conference Wednesday to officially announce her retirement from figure skating attracted some 350 journalists and was telecast live across Japan. Asada had led the country’s figure skating scene since her teens with her trademark triple axel. She started skating at the age of five and won world championships in 2008, 2010 and 2014 . Her illustrious career also included a silver medal at the 2010 Vancouver Olympics. Asada, who announced her retirement from her 21-year career on her blog two days ago, occupied a special place in the Japanese sports landscape. Her popularity far exceeded that of other figure skaters, even those with more gold medals. At Wednesday’s press conference, Asada called her performance in the free skating event at the 2014 Sochi Olympics her most memorable. “It’s difficult to pick just one,” Asada said. “But the free skating in Sochi definitely stands out.” She placed 16th in the short program in Sochi after falling on her triple Axel, under-rotating a triple flip, and doubling a triple loop. But in a stirring free skate Asada rebounded, earning a personal best score of 142.71. This made her the third woman to score above the 140 mark after Yuna Kim’s 2010 Olympics score and Yulia Lipnitskaya’s 2014 Olympics team event score. It placed Asada third in the free skating and sixth overall. Even though she didn’t win a medal, it was a performance that many will never forget. -

ISU WORLD FIGURE SKATING CHAMPIONSHIPS 2013 March 11
ISU WORLD FIGURE SKATING CHAMPIONSHIPS® 2013 March 11 – 17, 2013, London ON / Canada MEN - Music Rotation Men Monday Tuesday 11-Mar-13 12-Mar-13 Group 1 07:30 - 08:10 15:00 - 15:40 14:40 - 15:20 22:10 - 22:50 Nation PR MR MR PR SP or FS SP or FS SP or FS SP or FS Jorik HENDRICKX BEL 1 2 3 4 Justus STRID DEN 2 3 4 5 Jin Seo KIM KOR 3 4 5 6 Javier FERNANDEZ ESP 4 5 6 1 Alexander MAJOROV SWE 5 6 1 2 Yakov GODOROZHA UKR 6 1 2 3 Men Monday Tuesday 11-Mar-13 12-Mar-13 Group 2 08:10 - 08:50 15:40 - 16:20 11:00 - 11:40 18:30 - 19:10 Nation PR MR MR PR SP or FS SP or FS SP or FS SP or FS Patrick CHAN CAN 1 2 3 4 Kevin REYNOLDS CAN 2 3 4 5 Andrei ROGOZINE CAN 3 4 5 1 Max AARON USA 4 5 1 2 Ross MINER USA 5 1 2 3 Men Monday Tuesday 11-Mar-13 12-Mar-13 Group 3 09:00 - 09:40 16:30 - 17:10 11:40 - 12:20 19:10 - 19:50 Nation PR MR MR PR SP or FS SP or FS SP or FS SP or FS Pavel IGNATENKO BLR 1 2 3 4 Florent AMODIO FRA 2 3 4 5 Brian JOUBERT FRA 3 4 5 6 Alexei BYCHENKO ISR 4 5 6 1 Maciej CIEPLUCHA POL 5 6 1 2 Zoltan KELEMEN ROU 6 1 2 3 Men Monday Tuesday 11-Mar-13 12-Mar-13 Group 4 09:40 - 10:20 17:10 - 17:50 12:30 - 13:10 20:00 - 20:40 Nation PR MR MR PR SP or FS SP or FS SP or FS SP or FS Nan SONG CHN 1 2 3 4 Yuzuru HANYU JPN 2 3 4 5 Takahito MURA JPN 3 4 5 6 Daisuke TAKAHASHI JPN 4 5 6 1 Maxim KOVTUN RUS 5 6 1 2 Misha GE UZB 6 1 2 3 Official ISU Sponsors ISU WORLD FIGURE SKATING CHAMPIONSHIPS® 2013 March 11 – 17, 2013, London ON / Canada MEN - Music Rotation Men Monday Tuesday 11-Mar-13 12-Mar-13 Group 5 10:30 - 11:10 18:00 - 18:40 13:10 - 13:50 20:40 -

SCRIPT: the Undisputed Queen of Figure Skating Yuna Kim Became A
SCRIPT: The undisputed queen of figure skating Yuna Kim became a Lillehammer 2016 Winter Youth Olympic Games Ambassador and spoke of the Olympic values during a skating work shop with the Norwegian national team and local youngsters in the YOG host city. Better know as ‘Queen Yuna’ the South Korean legend of figure skating also previewed the first Grand Prix event of the coming season Skate America in Milwaukee, USA this October where her fellow South Korean athlete and a medalist of Innsbruck 2012 Winter Youth Olympic Games, Park So-youn, the National Champion, will be going for gold against Russia’s Yuila Lipnitskaya and Evgenia Medvedeva. Yuna Kim retired from figure skating having never finished a major ladies singles event off the podium, a remarkable achievement that most notably saw her claim Olympic gold at the Olympic Winter Games Vancouver 2010 and a silver medal at the Olympic Winter Games Sochi 2014. The Sochi gold medal was awarded to Russia’s Adelina Sotnikova, a graduate of the first Winter Youth Olympic Games in Innsbruck in 2012. One thousand, one hundred athletes aged 15 to 18 from 70 nations will compete in 70 medal events. The seven sports on the Olympic program will feature plus a few new additions, including team ski-snowboard cross and monobob. The Winter YOG will take place in existing venues from the legacy of the Lillehammer 1994 Olympic Winter Games. The IOC chooses Ambassadors for each edition of the Youth Olympic Games. Sporting legends such as Usain Bolt, Michael Phelps, Yao Ming and Yelena Isinbayeva have supported the YOG. -
The Journey Begins: Brown Blogs from South Korea | Icenetwork.Com: Your Home for figure Skating and Speed Skating
6/29/2018 The Journey Begins: Brown blogs from South Korea | icenetwork.com: Your home for figure skating and speed skating. Subscribe Login Register HOME SCHEDULE + RESULTS SKATERS NEWS PHOTOS FANS The Journey Begins: Brown blogs from South Korea U.S. bronze medalist takes readers behind the scenes at Four Continents Posted 2/13/17 by Jason Brown, special to icenetwork Team USA members Jason Brown and Mirai Nagasu pose with a PyeongChang 2018 Winter Olympics mascot at the airport in Seoul. courtesy of Jason Brown U.S. bronze medalist Jason Brown is competing at the 2017 Four Continents Championships in Gangneung, South Korea, this week. He is keeping a blog for icenetwork. Saturday, Feb. 18Sunday, Feb. 19 Saturday night marked the conclusion of the pairs and ladies events. Brandon [Frazier] and Haven [Denney], and Ashley [Cain] and Tim [LeDuc] finished eighth and ninth, respectively, while Chris [Knierim] and Alexa [Scimeca Knierim] finished sixth. Each pair looked so beautiful and said they were pleased with their performances. http://web.icenetwork.com/news/2017/02/13/215863584/the-journey-begins-brown-blogs-from-south-korea 1/6 6/29/2018 The Journey Begins: Brown blogs from South Korea | icenetwork.com: Your home for figure skating and speed skating. In the ladies competition, Karen [Chen] and Mariah [Bell] finished 12th and sixth, while Mirai [Nagasu] took home the bronze medal after delivering a beautiful free skate. The men's event saw Grant [Hochstein] and I land ninth and sixth, respectively, while Nathan [Chen] killed it by landing five quads in his free skate to win the overall event. -

The Effect of School Closure On
Teasing Out the Compressed Education Debates in Contemporary South Korea: Media Portrayal of Figure Skater Yuna Kim by Hye Jin Kim B.A., Simon Fraser University, 2010 Thesis Submitted in Partial Fulfillment of the Requirements for the Degree of Master of Arts in the Department of Sociology and Anthropology Faculty of Arts and Social Sciences Hye Jin Kim 2013 SIMON FRASER UNIVERSITY Summer 2013 Approval Name: Hye Jin Kim Degree: Master of Arts (Sociology) Title of Thesis: Teasing Out the Compressed Education Debates in Contemporary South Korea: Media Portrayal of Figure Skater Yuna Kim Examining Committee: Chair: Dr. Barbara Mitchelle Professor Dr. Cindy Patton Senior Supervisor Professor Dr. Jie Yang Committee member Assistant Professor Dr. Helen Leung External Examiner Associate Professor Gender, Sexuality, and Women’s Studies Date Defended/Approved: July 30, 2013 ii Partial Copyright Licence iii Abstract In this thesis, I argue that the heated debates about South Korea’s education policy consist of problems that arise from different genres of discourses that in turn belong to different historical moments and education values. I engage in a media discourse analysis of the reportage on South Korean international sport celebrity Yuna Kim that highlight the key education debates currently taking place in South Korea. First, I deal with the neologism umchinttal (my mom’s friend’s daughter) as an ideal student type. The use of the neologism suggests that students without familial cultural or economic capital do not have as much social mobility through education compared to the previous generation of students. Second, I look at the changing student-parent-teacher relationship through the controversy about Kim’s decision to part ways with her former coach Brian Orser. -
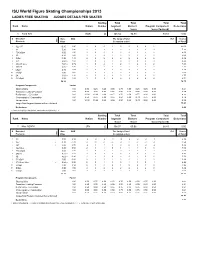
ISU World Figure Skating Championships 2013 LADIES FREE SKATING JUDGES DETAILS PER SKATER
ISU World Figure Skating Championships 2013 LADIES FREE SKATING JUDGES DETAILS PER SKATER Starting Total Total Total Total Rank Name Nation Number Segment Element Program Component Deductions Score Score Score (factored) 1 Yuna KIM KOR 24 148.34 74.73 73.61 0.00 # Executed Base GOE The Judges Panel Ref Scores Elements Info Value (in random order) of Panel 1 3Lz+3T 10.10 1.90 2 3 3 2 3 3 3 3 2 12.00 2 3F 5.30 1.90 2 3 3 2 3 2 3 3 3 7.20 3 FCCoSp4 3.50 1.00 2 3 2 2 2 2 2 2 2 4.50 4 3S 4.20 1.40 2 2 3 1 2 2 2 2 2 5.60 5 StSq4 3.90 1.40 2 3 2 2 2 2 2 2 2 5.30 6 3Lz 6.60 x 1.80 2 3 3 2 3 2 3 2 3 8.40 7 2A+2T+2Lo 7.04 x 0.79 1 3 2 1 2 1 2 1 2 7.83 8 3S+2T 6.05 x 1.30 2 2 2 1 2 1 2 2 2 7.35 9 LSp3 2.40 1.07 2 2 3 2 2 3 2 2 2 3.47 10 ChSq1 2.00 1.60 2 3 3 2 2 3 2 2 2 3.60 11 2A 3.63 x 1.14 2 3 3 2 2 3 2 2 2 4.77 12 CCoSp4 3.50 1.21 3 3 3 2 2 3 2 2 2 4.71 58.22 74.73 Program Components Factor Skating Skills 1.60 9.50 9.25 9.25 9.00 8.75 9.50 9.25 9.25 9.00 9.21 Transition / Linking Footwork 1.60 9.00 9.25 8.75 8.75 8.50 9.25 9.00 8.75 8.75 8.89 Performance / Execution 1.60 10.00 10.00 9.00 9.25 8.50 9.50 9.75 9.00 9.00 9.36 Choreography / Composition 1.60 9.50 9.75 9.00 9.25 8.50 9.00 10.00 8.75 9.00 9.18 Interpretation 1.60 10.00 10.00 9.25 9.00 8.50 9.25 10.00 9.00 9.00 9.36 Judges Total Program Component Score (factored) 73.61 Deductions: 0.00 x Credit for highlight distribution, base value multiplied by 1.1 Starting Total Total Total Total Rank Name Nation Number Segment Element Program Component Deductions Score Score Score (factored) 2 Mao -

U.S. Figure Skating Style Guidelines U.S
U.S. FIGURE SKATING STYLE GUIDELINES U.S. FIGURE SKATING STYLE GUIDE This style guide is specifically intended for writing purposes to create consistency throughout the organization to better streamline the message U.S. Figure Skating conveys to the public. U.S. Figure Skating’s websites and its contributing writers should use this guide in order to adhere to the organization’s writing style. Not all skating terms/events are listed here. We adhere to Associated Press style (exceptions are noted). If you have questions about a particular style, please contact Michael Terry ([email protected]). THE TOP 11 Here are the top 11 most common style references. U.S. Figure Skating Abbreviate United States with periods and no space between the letters. The legal name of the organization is the U.S. Figure Skating Associa- tion, but in text it should always be referred to as U.S. Figure Skating. USFSA and USFS are not acceptable. U.S. Figure Skating Championships, U.S. Synchronized Skating Championships, U.S. Collegiate Figure Skating Championships, U.S. Adult Figure Skating Championships These events are commonly referred to as “nationals,” “synchro nationals,” “collegiate nationals” and “adult nationals,” but the official names of the events are the U.S. Figure Skating Championships (second reference: U.S. Championships), the U.S. Synchronized Skat- ing Championships (second reference: U.S. Synchronized Championships), the U.S. Collegiate Figure Skating Championships (second reference: U.S. Collegiate Championships) and the U.S. Adult Figure Skating Championships (second reference: U.S. Adult Championships). one space after periods “...better than it was before,” Chen said.