Deep Learning on Mobile Devices with Ubiquitous Cognitive Computing
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Technology That Brings Together All Things Mobile
NFC – The Technology That Brings Together All Things Mobile Philippe Benitez Wednesday, June 4th, 2014 NFC enables fast, secure, mobile contactless services… Card Emulation Mode Reader Mode P2P Mode … for both payment and non-payment services Hospitality – Hotel room keys Mass Transit – passes and limited use tickets Education – Student badge Airlines – Frequent flyer card and boarding passes Enterprise & Government– Employee badge Automotive – car sharing / car rental / fleet management Residential - Access Payment – secure mobile payments Events – Access to stadiums and large venues Loyalty and rewards – enhanced consumer experience 3 h h 1996 2001 2003 2005 2007 2014 2014 2007 2005 2003 2001 1996 previous experiences experiences previous We are benefiting from from benefiting are We Barriers to adoption are disappearing ! NFC Handsets have become mainstream ! Terminalization is being driven by ecosystem upgrades ! TSM Provisioning infrastructure has been deployed Barriers to adoption are disappearing ! NFC Handsets have become mainstream ! Terminalization is being driven by ecosystem upgrades ! TSM Provisioning infrastructure has been deployed 256 handset models now in market worldwide Gionee Elife E7 LG G Pro 2 Nokia Lumia 1020 Samsung Galaxy Note Sony Xperia P Acer E320 Liquid Express Google Nexus 10 LG G2 Nokia Lumia 1520 Samsung Galaxy Note 3 Sony Xperia S Acer Liquid Glow Google Nexus 5 LG Mach Nokia Lumia 2520 Samsung Galaxy Note II Sony Xperia Sola Adlink IMX-2000 Google Nexus 7 (2013) LG Optimus 3D Max Nokia Lumia 610 NFC Samsung -

USER MANUAL Welcome!
M351 USER MANUAL Welcome! An Internet phone of a brand new generation, Meizu M351 is designed to bring users countless surprise and joy. users are welcome to visit the official MEIZU website at: http://www.meizu.com On our website, users can browse for software, download firmware upgrades, participate in online discussions, learn more using tips, and much more! Because the constant improvements we made for our products, the features found in the user manual users are currently reading may differ from the actual product. Make sure to always download the latest manual from our official website. This manual was last updated January 18, 2011. This manual was last updated July 22, 2013. Meizu M351 Legal information © 2003-2012 Meizu Inc. All rights reserved. Meizu and the Meizu logo are trademarks belonging to Meizu both in the PRC and overseas. Google, Google logo, Android, Google search, Gmail, Google Mail and Android Market are trademarks of Google, Inc. Street View Images © 2010 Google. Bluetooth and the Bluetooth logo are trademarks of Bluetooth SIG, Inc. Java, J2ME and all other Java-based trademarks are registered trademarks belonging to Sun Microsystems, Inc. in the United States and other countries. Meizu (or Meizu's licensors) own all legal rights to the product, trademarks and interests, including but not limited to any intellectual property rights found in services (whether those rights have been registered, and regardless of where in the world those rights may exist). Meizu company services may include information designated as confidential. Without the prior written consent of Meizu; transcription, replication, reproduction or translation of some or all of said contents are prohibited. -
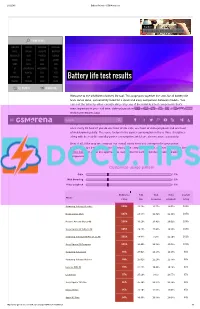
Battery Life Test Results HUAWEI TOSHIBA INTEX PLUM
2/12/2015 Battery life tests GSMArena.com Starborn SAMSUNG GALAXY S6 EDGE+ REVIEW PHONE FINDER SAMSUNG LENOVO VODAFONE VERYKOOL APPLE XIAOMI GIGABYTE MAXWEST MICROSOFT ACER PANTECH CELKON NOKIA ASUS XOLO GIONEE SONY OPPO LAVA VIVO LG BLACKBERRY MICROMAX NIU HTC ALCATEL BLU YEZZ MOTOROLA ZTE SPICE PARLA Battery life test results HUAWEI TOSHIBA INTEX PLUM ALL BRANDS RUMOR MILL Welcome to the GSMArena battery life tool. This page puts together the stats for all battery life tests we've done, conveniently listed for a quick and easy comparison between models. You can sort the table by either overall rating or by any of the individual test components that's most important to you call time, video playback or web browsing.TIP US 828K 100K You can find all about our84K 137K RSS LOG IN SIGN UP testing procedures here. SearchOur overall rating gives you an idea of how much battery backup you can get on a single charge. An overall rating of 40h means that you'll need to fully charge the device in question once every 40 hours if you do one hour of 3G calls, one hour of video playback and one hour of web browsing daily. The score factors in the power consumption in these three disciplines along with the reallife standby power consumption, which we also measure separately. Best of all, if the way we compute our overall rating does not correspond to your usage pattern, you are free to adjust the different usage components to get a closer match. Use the sliders below to adjust the approximate usage time for each of the three battery draining components. -

Test Report on Terminal Compatibility of Huawei's WLAN Products
Huawei WLAN ● Wi-Fi Experience Interoperability Test Reports Test Report on Terminal Compatibility of Huawei's WLAN Products Huawei Technologies Co., Ltd. Test Report on Terminal Compatibility of Huawei's WLAN Products 1 Overview WLAN technology defined in IEEE 802.11 is gaining wide popularity today. WLAN access can replace wired access as the last-mile access solution in scenarios such as public hotspot, home broadband access, and enterprise wireless offices. Compared with other wireless technologies, WLAN is easier to operate and provides higher bandwidth with lower costs, fully meeting user requirements for high-speed wireless broadband services. Wi-Fi terminals are major carriers of WLAN technology and play an essential part in WLAN technology promotion and application. Mature terminal products available on the market cover finance, healthcare, education, transportation, energy, and retail industries. On the basis of WLAN technology, the terminals derive their unique authentication behaviors and implementation methods, for example, using different operating systems. Difference in Wi-Fi chips used by the terminals presents a big challenge to terminal compatibility of Huawei's WLAN products. Figure 1-1 Various WLAN terminals To identify access behaviors and implementation methods of various WLAN terminals and validate Huawei WLAN products' compatibility with the latest mainstream terminals used in various industries, Huawei WLAN product test team carried out a survey on mainstream terminals available on market. Based on the survey result, the team used technologies and methods specific to the WLAN field to test performance indicators of Huawei's WLAN products, including the access capability, authentication and encryption, roaming, protocol, and terminal identification. -

Compatibility Sheet
COMPATIBILITY SHEET SanDisk Ultra Dual USB Drive Transfer Files Easily from Your Smartphone or Tablet Using the SanDisk Ultra Dual USB Drive, you can easily move files from your Android™ smartphone or tablet1 to your computer, freeing up space for music, photos, or HD videos2 Please check for your phone/tablet or mobile device compatiblity below. If your device is not listed, please check with your device manufacturer for OTG compatibility. Acer Acer A3-A10 Acer EE6 Acer W510 tab Alcatel Alcatel_7049D Flash 2 Pop4S(5095K) Archos Diamond S ASUS ASUS FonePad Note 6 ASUS FonePad 7 LTE ASUS Infinity 2 ASUS MeMo Pad (ME172V) * ASUS MeMo Pad 8 ASUS MeMo Pad 10 ASUS ZenFone 2 ASUS ZenFone 3 Laser ASUS ZenFone 5 (LTE/A500KL) ASUS ZenFone 6 BlackBerry Passport Prevro Z30 Blu Vivo 5R Celkon Celkon Q455 Celkon Q500 Celkon Millenia Epic Q550 CoolPad (酷派) CoolPad 8730 * CoolPad 9190L * CoolPad Note 5 CoolPad X7 大神 * Datawind Ubislate 7Ci Dell Venue 8 Venue 10 Pro Gionee (金立) Gionee E7 * Gionee Elife S5.5 Gionee Elife S7 Gionee Elife E8 Gionee Marathon M3 Gionee S5.5 * Gionee P7 Max HTC HTC Butterfly HTC Butterfly 3 HTC Butterfly S HTC Droid DNA (6435LVW) HTC Droid (htc 6435luw) HTC Desire 10 Pro HTC Desire 500 Dual HTC Desire 601 HTC Desire 620h HTC Desire 700 Dual HTC Desire 816 HTC Desire 816W HTC Desire 828 Dual HTC Desire X * HTC J Butterfly (HTL23) HTC J Butterfly (HTV31) HTC Nexus 9 Tab HTC One (6500LVW) HTC One A9 HTC One E8 HTC One M8 HTC One M9 HTC One M9 Plus HTC One M9 (0PJA1) -

Pembuatan Game Fun Boom Countdown Berbasis Mobile Android
PEMBUATAN GAME FUN BOOM COUNTDOWN BERBASIS MOBILE ANDROID NASKAH PUBLIKASI diajukan oleh Adhitya Novebi Rahmawan 11.11.4617 kepada SEKOLAH TINGGI MANAJEMEN INFORMATIKA DAN KOMPUTER AMIKOM YOGYAKARTA YOGYAKARTA 2017 NASKAH PUBLIKASI PEMBUATAN GAME FUN BOOM COUNTDOWN BERBASIS MOBILE ANDROID yang dipersiapkan dan disusun oleh Adhitya Novebi Rahmawan 11.11.4617 Dosen Pembimbing Mei P Kurniawan, M.Kom NIK. 190302187 Tanggal, 10 Februari 2017 Ketua Program Studi Teknik Informatika Bambang Sudarmawan NIK. 190302035 PEMBUATAN GAME FUN BOOM COUNTDOWN BERBASIS MOBILE ANDROID Adhitya Novebi Rahmawan1), Mei P Kurniawan2), 1) Teknik Informatika STMIK AMIKOM Yogyakarta 2)Sistem Informasi STMIK AMIKOM Yogyakarta Jl Ringroad Utara, Condongcatur, Depok, Sleman, Yogyakarta Indonesia 55283 Email : [email protected] 1), [email protected] 2) Abstract - Games, gadgets and smartphones are berisi semua ilmu pengetahuan umum mulai dari pengetahuan sejarah, budaya sampai peristiwa- something inseparable from children’s world peristiwa penting dunia. Tetapi lagi-lagi membaca nowadays. Many children around us have been menjadi kendala utama orang malas mempelajari already carrying a smartphone and rarely carrying pengetahuan umum dari buku. Oleh karena itu dapat books instead of reading it. The curriculums of dikatakan ilmu pengetahuan umum yang diberikan oleh buku kurang diminati oleh khalayak umum. education increase of being difficult each year, but the interest of children to read is declining. It what Masalah terakhir yang muncul adalah materi yang disampaikan oleh buku kurang interaktif. makes Boom Countdown Game is created so that Untuk membangun minat seseorang dalam children can learn while playing. mempelajari ilmu pengetahuan umum diperlukan This game is based on Android because most of the alat yang lebih interaktif dari buku. -

Electronic 3D Models Catalogue (On July 26, 2019)
Electronic 3D models Catalogue (on July 26, 2019) Acer 001 Acer Iconia Tab A510 002 Acer Liquid Z5 003 Acer Liquid S2 Red 004 Acer Liquid S2 Black 005 Acer Iconia Tab A3 White 006 Acer Iconia Tab A1-810 White 007 Acer Iconia W4 008 Acer Liquid E3 Black 009 Acer Liquid E3 Silver 010 Acer Iconia B1-720 Iron Gray 011 Acer Iconia B1-720 Red 012 Acer Iconia B1-720 White 013 Acer Liquid Z3 Rock Black 014 Acer Liquid Z3 Classic White 015 Acer Iconia One 7 B1-730 Black 016 Acer Iconia One 7 B1-730 Red 017 Acer Iconia One 7 B1-730 Yellow 018 Acer Iconia One 7 B1-730 Green 019 Acer Iconia One 7 B1-730 Pink 020 Acer Iconia One 7 B1-730 Orange 021 Acer Iconia One 7 B1-730 Purple 022 Acer Iconia One 7 B1-730 White 023 Acer Iconia One 7 B1-730 Blue 024 Acer Iconia One 7 B1-730 Cyan 025 Acer Aspire Switch 10 026 Acer Iconia Tab A1-810 Red 027 Acer Iconia Tab A1-810 Black 028 Acer Iconia A1-830 White 029 Acer Liquid Z4 White 030 Acer Liquid Z4 Black 031 Acer Liquid Z200 Essential White 032 Acer Liquid Z200 Titanium Black 033 Acer Liquid Z200 Fragrant Pink 034 Acer Liquid Z200 Sky Blue 035 Acer Liquid Z200 Sunshine Yellow 036 Acer Liquid Jade Black 037 Acer Liquid Jade Green 038 Acer Liquid Jade White 039 Acer Liquid Z500 Sandy Silver 040 Acer Liquid Z500 Aquamarine Green 041 Acer Liquid Z500 Titanium Black 042 Acer Iconia Tab 7 (A1-713) 043 Acer Iconia Tab 7 (A1-713HD) 044 Acer Liquid E700 Burgundy Red 045 Acer Liquid E700 Titan Black 046 Acer Iconia Tab 8 047 Acer Liquid X1 Graphite Black 048 Acer Liquid X1 Wine Red 049 Acer Iconia Tab 8 W 050 Acer -

Presentación De Powerpoint
Modelos compatibles de Imóvil No. Marca Modelo Teléfono Versión del sistema operativo 1 360 1501_M02 1501_M02 Android 5.1 2 100+ 100B 100B Android 4.1.2 3 Acer Iconia Tab A500 Android 4.0.3 4 ALPS (Golden Master) MR6012H1C2W1 MR6012H1C2W1 Android 4.2.2 5 ALPS (Golden Master) PMID705GTV PMID705GTV Android 4.2.2 6 Amazon Fire HD 6 Fire HD 6 Fire OS 4.5.2 / Android 4.4.3 7 Amazon Fire Phone 32GB Fire Phone 32GB Fire OS 3.6.8 / Android 4.2.2 8 Amoi A862W A862W Android 4.1.2 9 amzn KFFOWI KFFOWI Android 5.1.1 10 Apple iPad 2 (2nd generation) MC979ZP iOS 7.1 11 Apple iPad 4 MD513ZP/A iOS 7.1 12 Apple iPad 4 MD513ZP/A iOS 8.0 13 Apple iPad Air MD785ZP/A iOS 7.1 14 Apple iPad Air 2 MGLW2J/A iOS 8.1 15 Apple iPad Mini MD531ZP iOS 7.1 16 Apple iPad Mini 2 FE276ZP/A iOS 8.1 17 Apple iPad Mini 3 MGNV2J/A iOS 8.1 18 Apple iPhone 3Gs MC132ZP iOS 6.1.3 19 Apple iPhone 4 MC676LL iOS 7.1.2 20 Apple iPhone 4 MC603ZP iOS 7.1.2 21 Apple iPhone 4 MC604ZP iOS 5.1.1 22 Apple iPhone 4s MD245ZP iOS 8.1 23 Apple iPhone 4s MD245ZP iOS 8.4.1 24 Apple iPhone 4s MD245ZP iOS 6.1.2 25 Apple iPhone 5 MD297ZP iOS 6.0 26 Apple iPhone 5 MD298ZP/A iOS 8.1 27 Apple iPhone 5 MD298ZP/A iOS 7.1.1 28 Apple iPhone 5c MF321ZP/A iOS 7.1.2 29 Apple iPhone 5c MF321ZP/A iOS 8.1 30 Apple iPhone 5s MF353ZP/A iOS 8.0 31 Apple iPhone 5s MF353ZP/A iOS 8.4.1 32 Apple iPhone 5s MF352ZP/A iOS 7.1.1 33 Apple iPhone 6 MG492ZP/A iOS 8.1 34 Apple iPhone 6 MG492ZP/A iOS 9.1 35 Apple iPhone 6 Plus MGA92ZP/A iOS 9.0 36 Apple iPhone 6 Plus MGAK2ZP/A iOS 8.0.2 37 Apple iPhone 6 Plus MGAK2ZP/A iOS 8.1 -

Lista De Compatibilidad Dispositivo Mitpv
Lista de Compatibilidad Dispositivo miTPV MARCA MODELO SISTEMA OPERATIVO 100+ 100B Android 4.1.2 360 1501_M02 Android 5.1 Acer Iconia Tab Android 4.0.3 ALPS (Golden Master) MR6012H1C2W1 Android 4.2.2 ALPS (Golden Master) PMID705GTV Android 4.2.2 Amazon Fire HD 6 Fire OS 4.5.2 / Android 4.4.3 Amazon Fire Phone 32GB Fire OS 3.6.8 / Android 4.2.2 Amoi A862W Android 4.1.2 amzn KFFOWI Android 5.1.1 Apple iPad 2 (2nd generation) iOS 7.1 Apple iPad 4 iOS 7.1 Apple iPad 4 iOS 8.0 Apple iPad Air iOS 7.1 Apple iPad Air 2 iOS 8.1 Apple iPad Mini iOS 7.1 Apple iPad Mini 2 iOS 8.1 Apple iPad Mini 3 iOS 8.1 Apple iPhone 3Gs iOS 6.1.3 Apple iPhone 4 iOS 7.1.2 Apple iPhone 4 iOS 7.1.2 Apple iPhone 4 iOS 5.1.1 Apple iPhone 4s iOS 8.1 Apple iPhone 4s iOS 8.4.1 Apple iPhone 4s iOS 6.1.2 Apple iPhone 5 iOS 6.0 Apple iPhone 5 iOS 8.1 Apple iPhone 5 iOS 7.1.1 Apple iPhone 5c iOS 7.1.2 Apple iPhone 5c iOS 8.1 Apple iPhone 5s iOS 8.0 Apple iPhone 5s iOS 8.4.1 Apple iPhone 5s iOS 7.1.1 Apple iPhone 6 iOS 9.1 Apple iPhone 6 iOS 8.1 Apple iPhone 6 Plus iOS 9.0 Apple iPhone 6 Plus iOS 8.0.2 Apple iPhone 6 Plus iOS 8.1 Apple iPhone 6s iOS 9.1 Apple iPhone 6s Plus iOS 9.1 Apple iPod touch 4th Generation iOS 5.1.1 Apple iPod touch 4th Generation iOS 5.0.1 Apple iPod touch 5th Generation 16GB iOS 8.1 Apple iPod touch 5th Generation 32GB iOS 6.1.3 Aquos IS11SH Android 2.3.3 Aquos IS12SH Android 2.3.3 Lista de Compatibilidad Dispositivo miTPV MARCA MODELO SISTEMA OPERATIVO Aquos IS13SH Android 2.3.5 Aquos SH-12C Android 2.3.3 Aquos SH-13C Android 2.3.4 Arrow Girls' Popteen -

Benutzerhandbuch User Instructions
1 STECKERTYPEN Kompatibilitätsliste, welcher Aufsatz für Ihr 3 KOMPATIBILITÄT 11-Pin-Adapter(-kabel) kompatibel: trockenes Tuch. Verwenden Sie keine Endgerät passend ist. Folgende Modelle sind mit dem SlimPort-Adap- • Samsung Galaxy S3 (i9300, i747, i535, T999, chemischen Zusätze. Adapterkabel: ter(-kabel) kompatibel: R530), Galaxy S4 (i9500), Galaxy S4 Active, • Eine Entsorgung muss über die zuständigen MicroUSB Eingang • Acer Predator 8, Acer Iconia Tab 10, Asus Galaxy S4 Zoom, Galaxy S5 (i9600), Galaxy S5 Sammelstellen erfolgen. 5 Pin 11 Pin (Stromversorgung) Memo Pad 8, PadFone Infinity, PadfoneX, Acer Zoom, Galaxy Note 2 (N7100), Galaxy Note 3 Iconia Tab10, Predator 8, Amazon Fire HD Kids (N9005), Galaxy Note 8, Galaxy Mega 6.3 und 2 BENUTZUNG Edition, Fire HD6, Fire HD7, HDX 8.9, 5.8, Galaxy Tab 3 (8", 10.1"), Galaxy Tab S (8.4", Adapter: Blackberry Passport, Classic, Fujitsu Arrow, 10.5"), Galaxy TabPro (8.4", 10.1"), Galaxy Tab Stylistic QH582, Google LG Nexus 4, LG Nexus S2 (9,7” T815N), Galaxy Express, Galaxy K 5, Nexus 7, HP Chromebook 11, Pro Slate 8, Zoom Pro Slate 12, LG G Flex, G Flex 2, G Pad, G Pro • BITTE ÜBERPRÜFEN SIE AUF DER HERSTEL- 2, G2, G3, G4, GX, GX2, Optimus G Pro, LERSEITE IHRES TABLETS ODER SMARTPHO- HDMI Ausgang MicroUSB Eingang Micro-USB zum Optimus GK, V10, VU 3, YotaPhone 2, ZTE NES, OB IHR GERÄT (Modellnummer beachten!) Benutzerhandbuch (Stromversorgung) Smartphone / Tablet Nubia X6, Nubia Z5S MLH ODER SLIMPORT KOMPATIBEL IST. • ACHTUNG: Samsung Galaxy S6 und S7 MicroUSB zu HDMI - Slimport / Micro-USB zum • Stellen Sie zunächst die Stromverbindung Folgende Modelle sind mit dem MHL 5-Pin- Adapter(-kabel) kompatibel: sowie sämtliche Neo Modelle unterstützen MHL Adapter / Adapterkabel Smartphone / Tablet HDMI Ausgang her. -

Pairing Smartphones in Close Proximity Using Magnetometers
MagPairing: Pairing Smartphones in Close Proximity Using Magnetometers Rong Jin∗, Liu Shiy, Kai Zengz , Amit Pandex, Prasant Mohapatrax ∗School of Electronic Information and Communications, Huazhong University of Science and Technology Email: [email protected] yDepartment of Computer and Information Science, University of Michigan - Dearborn, MI 48128 Email: [email protected] z Department of Electrical and Computer Engineering, George Mason University, VA 22030 Email: [email protected] xDepartment of Computer Science, University of California, Davis, CA, 95616 Email: famit,[email protected] Abstract—With the prevalence of mobile computing, lots of Using auxiliary out-of-band (OOB) channels to facilitate wireless devices need to establish secure communication on the device pairing has been studied as a feasible option involving fly without pre-shared secrets. Device pairing is critical for visual [1, 2, 3, 4, 5, 6, 7, 8], acoustic [9, 10, 11, 12, 13], bootstrapping secure communication between two previously u- nassociated devices over the wireless channel. Using auxiliary out- tactile [14] or vibrational sensors [15, 16]. However, these of-band channels involving visual, acoustic, tactile or vibrational methods are not optimized in terms of usability, which is sensors has been proposed as a feasible option to facilitate device considered of utmost importance in pairing scheme based on pairing. However, these methods usually require users to perform OOB channels [2, 17, 18, 19], and require users to perform additional tasks such as copying, comparing, and shaking. It is additional tasks such as copying, comparing and shaking. It preferable to have a natural and intuitive pairing method with minimal user tasks. -

Alcatel One Touch Go Play 7048 Alcatel One Touch
Acer Liquid Jade S Alcatel Idol 3 4,7" Alcatel Idol 3 5,5" Alcatel One Touch Go Play 7048 Alcatel One Touch Pop C3/C2 Alcatel One Touch POP C7 Alcatel Pixi 4 4” Alcatel Pixi 4 5” (5045x) Alcatel Pixi First Alcatel Pop 3 5” (5065x) Alcatel Pop 4 Lte Alcatel Pop 4 plus Alcatel Pop 4S Alcatel Pop C5 Alcatel Pop C9 Allview C6 Quad Apple Iphone 4 / 4s Apple Iphone 5 / 5s / SE Apple Iphone 5c Apple Iphone 6/6s 4,7" Apple Iphone 6 plus / 6s plus Apple Iphone 7 Apple Iphone 7 plus Apple Iphone 8 Apple Iphone 8 plus Apple Iphone X HTC 8S HTC Desire 320 HTC Desire 620 HTC Desire 626 HTC Desire 650 HTC Desire 820 HTC Desire 825 HTC 10 One M10 HTC One A9 HTC One M7 HTC One M8 HTC One M8s HTC One M9 HTC U11 Huawei Ascend G620s Huawei Ascend G730 Huawei Ascend Mate 7 Huawei Ascend P7 Huawei Ascend Y530 Huawei Ascend Y540 Huawei Ascend Y600 Huawei G8 Huawei Honor 5x Huawei Honor 7 Huawei Honor 8 Huawei Honor 9 Huawei Mate S Huawei Nexus 6p Huawei P10 Lite Huawei P8 Huawei P8 Lite Huawei P9 Huawei P9 Lite Huawei P9 Lite Mini Huawei ShotX Huawei Y3 / Y360 Huawei Y3 II Huawei Y5 / Y541 Huawei Y5 / Y560 Huawei Y5 2017 Huawei Y5 II Huawei Y550 Huawei Y6 Huawei Y6 2017 Huawei Y6 II / 5A Huawei Y6 II Compact Huawei Y6 pro Huawei Y635 Huawei Y7 2017 Lenovo Moto G4 Plus Lenovo Moto Z Lenovo Moto Z Play Lenovo Vibe C2 Lenovo Vibe K5 LG F70 LG G Pro Lite LG G2 LG G2 mini D620 LG G3 LG G3 s LG G4 LG G4c H525 / G4 mini LG G5 / H830 LG K10 / K10 Lte LG K10 2017 / K10 dual 2017 LG K3 LG K4 LG K4 2017 LG K7 LG K8 LG K8 2017 / K8 dual 2017 LG L Fino LG L5 II LG L7 LG