Supporting Information
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Number 2 February 2014
Atlas of Genetics and Cytogenetics in Oncology and Haematology OPEN ACCESS JOURNAL INIST -CNRS Volume 18 - Number 2 February 2014 The PDF version of the Atlas of Genetics and Cytogenetics in Oncology and Haematology is a reissue of the original articles published in collaboration with the Institute for Scientific and Technical Information (INstitut de l’Information Scientifique et Technique - INIST) of the French National Center for Scientific Research (CNRS) on its electronic publishing platform I-Revues. Online and PDF versions of the Atlas of Genetics and Cytogenetics in Oncology and Haematology are hosted by INIST-CNRS. Atlas of Genetics and Cytogenetics in Oncology and Haematology OPEN ACCESS JOURNAL INIST -CNRS Scope The Atlas of Genetics and Cytogenetics in Oncology and Haematology is a peer reviewed on-line journal in open access, devoted to genes, cytogenetics, and clinical entities in cancer, and cancer-prone diseases. It presents structured review articles (“cards”) on genes, leukaemias, solid tumours, cancer-prone diseases, and also more traditional review articles (“deep insights”) on the above subjects and on surrounding topics. It also present case reports in hematology and educational items in the various related topics for students in Medicine and in Sciences. Editorial correspondance Jean-Loup Huret Genetics, Department of Medical Information, University Hospital F-86021 Poitiers, France tel +33 5 49 44 45 46 or +33 5 49 45 47 67 [email protected] or [email protected] Staff Mohammad Ahmad, Mélanie Arsaban, Marie-Christine Jacquemot-Perbal, Vanessa Le Berre, Anne Malo, Carol Moreau, Catherine Morel-Pair, Laurent Rassinoux, Alain Zasadzinski. Philippe Dessen is the Database Director, and Alain Bernheim the Chairman of the on-line version (Gustave Roussy Institute – Villejuif – France). -

List of Genes Associated with Sudden Cardiac Death (Scdgseta) Gene
List of genes associated with sudden cardiac death (SCDgseta) mRNA expression in normal human heart Entrez_I Gene symbol Gene name Uniprot ID Uniprot name fromb D GTEx BioGPS SAGE c d e ATP-binding cassette subfamily B ABCB1 P08183 MDR1_HUMAN 5243 √ √ member 1 ATP-binding cassette subfamily C ABCC9 O60706 ABCC9_HUMAN 10060 √ √ member 9 ACE Angiotensin I–converting enzyme P12821 ACE_HUMAN 1636 √ √ ACE2 Angiotensin I–converting enzyme 2 Q9BYF1 ACE2_HUMAN 59272 √ √ Acetylcholinesterase (Cartwright ACHE P22303 ACES_HUMAN 43 √ √ blood group) ACTC1 Actin, alpha, cardiac muscle 1 P68032 ACTC_HUMAN 70 √ √ ACTN2 Actinin alpha 2 P35609 ACTN2_HUMAN 88 √ √ √ ACTN4 Actinin alpha 4 O43707 ACTN4_HUMAN 81 √ √ √ ADRA2B Adrenoceptor alpha 2B P18089 ADA2B_HUMAN 151 √ √ AGT Angiotensinogen P01019 ANGT_HUMAN 183 √ √ √ AGTR1 Angiotensin II receptor type 1 P30556 AGTR1_HUMAN 185 √ √ AGTR2 Angiotensin II receptor type 2 P50052 AGTR2_HUMAN 186 √ √ AKAP9 A-kinase anchoring protein 9 Q99996 AKAP9_HUMAN 10142 √ √ √ ANK2/ANKB/ANKYRI Ankyrin 2 Q01484 ANK2_HUMAN 287 √ √ √ N B ANKRD1 Ankyrin repeat domain 1 Q15327 ANKR1_HUMAN 27063 √ √ √ ANKRD9 Ankyrin repeat domain 9 Q96BM1 ANKR9_HUMAN 122416 √ √ ARHGAP24 Rho GTPase–activating protein 24 Q8N264 RHG24_HUMAN 83478 √ √ ATPase Na+/K+–transporting ATP1B1 P05026 AT1B1_HUMAN 481 √ √ √ subunit beta 1 ATPase sarcoplasmic/endoplasmic ATP2A2 P16615 AT2A2_HUMAN 488 √ √ √ reticulum Ca2+ transporting 2 AZIN1 Antizyme inhibitor 1 O14977 AZIN1_HUMAN 51582 √ √ √ UDP-GlcNAc: betaGal B3GNT7 beta-1,3-N-acetylglucosaminyltransfe Q8NFL0 -

Investigation of Candidate Genes and Mechanisms Underlying Obesity
Prashanth et al. BMC Endocrine Disorders (2021) 21:80 https://doi.org/10.1186/s12902-021-00718-5 RESEARCH ARTICLE Open Access Investigation of candidate genes and mechanisms underlying obesity associated type 2 diabetes mellitus using bioinformatics analysis and screening of small drug molecules G. Prashanth1 , Basavaraj Vastrad2 , Anandkumar Tengli3 , Chanabasayya Vastrad4* and Iranna Kotturshetti5 Abstract Background: Obesity associated type 2 diabetes mellitus is a metabolic disorder ; however, the etiology of obesity associated type 2 diabetes mellitus remains largely unknown. There is an urgent need to further broaden the understanding of the molecular mechanism associated in obesity associated type 2 diabetes mellitus. Methods: To screen the differentially expressed genes (DEGs) that might play essential roles in obesity associated type 2 diabetes mellitus, the publicly available expression profiling by high throughput sequencing data (GSE143319) was downloaded and screened for DEGs. Then, Gene Ontology (GO) and REACTOME pathway enrichment analysis were performed. The protein - protein interaction network, miRNA - target genes regulatory network and TF-target gene regulatory network were constructed and analyzed for identification of hub and target genes. The hub genes were validated by receiver operating characteristic (ROC) curve analysis and RT- PCR analysis. Finally, a molecular docking study was performed on over expressed proteins to predict the target small drug molecules. Results: A total of 820 DEGs were identified between -

Cellular and Molecular Signatures in the Disease Tissue of Early
Cellular and Molecular Signatures in the Disease Tissue of Early Rheumatoid Arthritis Stratify Clinical Response to csDMARD-Therapy and Predict Radiographic Progression Frances Humby1,* Myles Lewis1,* Nandhini Ramamoorthi2, Jason Hackney3, Michael Barnes1, Michele Bombardieri1, Francesca Setiadi2, Stephen Kelly1, Fabiola Bene1, Maria di Cicco1, Sudeh Riahi1, Vidalba Rocher-Ros1, Nora Ng1, Ilias Lazorou1, Rebecca E. Hands1, Desiree van der Heijde4, Robert Landewé5, Annette van der Helm-van Mil4, Alberto Cauli6, Iain B. McInnes7, Christopher D. Buckley8, Ernest Choy9, Peter Taylor10, Michael J. Townsend2 & Costantino Pitzalis1 1Centre for Experimental Medicine and Rheumatology, William Harvey Research Institute, Barts and The London School of Medicine and Dentistry, Queen Mary University of London, Charterhouse Square, London EC1M 6BQ, UK. Departments of 2Biomarker Discovery OMNI, 3Bioinformatics and Computational Biology, Genentech Research and Early Development, South San Francisco, California 94080 USA 4Department of Rheumatology, Leiden University Medical Center, The Netherlands 5Department of Clinical Immunology & Rheumatology, Amsterdam Rheumatology & Immunology Center, Amsterdam, The Netherlands 6Rheumatology Unit, Department of Medical Sciences, Policlinico of the University of Cagliari, Cagliari, Italy 7Institute of Infection, Immunity and Inflammation, University of Glasgow, Glasgow G12 8TA, UK 8Rheumatology Research Group, Institute of Inflammation and Ageing (IIA), University of Birmingham, Birmingham B15 2WB, UK 9Institute of -

Multi-Ethnic Genome-Wide Association Study for Atrial Fibrillation Carolina Roselli, Broad Institute of MIT and Harvard Mark D
Multi-ethnic genome-wide association study for atrial fibrillation Carolina Roselli, Broad Institute of MIT and Harvard Mark D. Chaffin, Broad Institute of MIT and Harvard Lu-Chen Weng, Broad Institute of MIT and Harvard Stefanie Aeschbacher, University Hospital Basel Gustav Ahlberg, Copenhagen University Hospital Christine M. Albert, Brigham & Womens Hospital Peter Almgren, Lund University Alvaro Alonso, Emory University Christopher D. Anderson, Broad Institute of MIT and Harvard Krishna G. Aragam, Broad Institute of MIT and Harvard Only first 10 authors above; see publication for full author list. Journal Title: Nature Genetics Volume: Volume 50, Number 9 Publisher: Nature Research (part of Springer Nature) | 2018-09-01, Pages 1225-+ Type of Work: Article | Post-print: After Peer Review Publisher DOI: 10.1038/s41588-018-0133-9 Permanent URL: https://pid.emory.edu/ark:/25593/tdhf0 Final published version: http://dx.doi.org/10.1038/s41588-018-0133-9 Copyright information: © 2018 The Author(s) Accessed October 2, 2021 3:10 AM EDT HHS Public Access Author manuscript Author ManuscriptAuthor Manuscript Author Nat Genet Manuscript Author . Author manuscript; Manuscript Author available in PMC 2018 September 13. Published in final edited form as: Nat Genet. 2018 September ; 50(9): 1225–1233. doi:10.1038/s41588-018-0133-9. Multi-Ethnic Genome-wide Association Study for Atrial Fibrillation A full list of authors and affiliations appears at the end of the article. # These authors contributed equally to this work. Abstract Atrial fibrillation (AF) affects over 33 million individuals worldwide1 and has a complex heritability.2 We conducted the largest meta-analysis of genome-wide association studies for AF to Corresponding author: Patrick T. -

Looking for Missing Proteins in the Proteome Of
Looking for Missing Proteins in the Proteome of Human Spermatozoa: An Update Yves Vandenbrouck, Lydie Lane, Christine Carapito, Paula Duek, Karine Rondel, Christophe Bruley, Charlotte Macron, Anne Gonzalez de Peredo, Yohann Coute, Karima Chaoui, et al. To cite this version: Yves Vandenbrouck, Lydie Lane, Christine Carapito, Paula Duek, Karine Rondel, et al.. Looking for Missing Proteins in the Proteome of Human Spermatozoa: An Update. Journal of Proteome Research, American Chemical Society, 2016, 15 (11), pp.3998-4019. 10.1021/acs.jproteome.6b00400. hal-02191502 HAL Id: hal-02191502 https://hal.archives-ouvertes.fr/hal-02191502 Submitted on 19 Mar 2021 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Journal of Proteome Research 1 2 3 Looking for missing proteins in the proteome of human spermatozoa: an 4 update 5 6 Yves Vandenbrouck1,2,3,#,§, Lydie Lane4,5,#, Christine Carapito6, Paula Duek5, Karine Rondel7, 7 Christophe Bruley1,2,3, Charlotte Macron6, Anne Gonzalez de Peredo8, Yohann Couté1,2,3, 8 Karima Chaoui8, Emmanuelle Com7, Alain Gateau5, AnneMarie Hesse1,2,3, Marlene 9 Marcellin8, Loren Méar7, Emmanuelle MoutonBarbosa8, Thibault Robin9, Odile Burlet- 10 Schiltz8, Sarah Cianferani6, Myriam Ferro1,2,3, Thomas Fréour10,11, Cecilia Lindskog12,Jérôme 11 1,2,3 7,§ 12 Garin , Charles Pineau . -

Gene Ontology Functional Annotations and Pleiotropy
Network based analysis of genetic disease associations Sarah Gilman Submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy under the Executive Committee of the Graduate School of Arts and Sciences COLUMBIA UNIVERSITY 2014 © 2013 Sarah Gilman All Rights Reserved ABSTRACT Network based analysis of genetic disease associations Sarah Gilman Despite extensive efforts and many promising early findings, genome-wide association studies have explained only a small fraction of the genetic factors contributing to common human diseases. There are many theories about where this “missing heritability” might lie, but increasingly the prevailing view is that common variants, the target of GWAS, are not solely responsible for susceptibility to common diseases and a substantial portion of human disease risk will be found among rare variants. Relatively new, such variants have not been subject to purifying selection, and therefore may be particularly pertinent for neuropsychiatric disorders and other diseases with greatly reduced fecundity. Recently, several researchers have made great progress towards uncovering the genetics behind autism and schizophrenia. By sequencing families, they have found hundreds of de novo variants occurring only in affected individuals, both large structural copy number variants and single nucleotide variants. Despite studying large cohorts there has been little recurrence among the genes implicated suggesting that many hundreds of genes may underlie these complex phenotypes. The question -

Supp Table 6.Pdf
Supplementary Table 6. Processes associated to the 2037 SCL candidate target genes ID Symbol Entrez Gene Name Process NM_178114 AMIGO2 adhesion molecule with Ig-like domain 2 adhesion NM_033474 ARVCF armadillo repeat gene deletes in velocardiofacial syndrome adhesion NM_027060 BTBD9 BTB (POZ) domain containing 9 adhesion NM_001039149 CD226 CD226 molecule adhesion NM_010581 CD47 CD47 molecule adhesion NM_023370 CDH23 cadherin-like 23 adhesion NM_207298 CERCAM cerebral endothelial cell adhesion molecule adhesion NM_021719 CLDN15 claudin 15 adhesion NM_009902 CLDN3 claudin 3 adhesion NM_008779 CNTN3 contactin 3 (plasmacytoma associated) adhesion NM_015734 COL5A1 collagen, type V, alpha 1 adhesion NM_007803 CTTN cortactin adhesion NM_009142 CX3CL1 chemokine (C-X3-C motif) ligand 1 adhesion NM_031174 DSCAM Down syndrome cell adhesion molecule adhesion NM_145158 EMILIN2 elastin microfibril interfacer 2 adhesion NM_001081286 FAT1 FAT tumor suppressor homolog 1 (Drosophila) adhesion NM_001080814 FAT3 FAT tumor suppressor homolog 3 (Drosophila) adhesion NM_153795 FERMT3 fermitin family homolog 3 (Drosophila) adhesion NM_010494 ICAM2 intercellular adhesion molecule 2 adhesion NM_023892 ICAM4 (includes EG:3386) intercellular adhesion molecule 4 (Landsteiner-Wiener blood group)adhesion NM_001001979 MEGF10 multiple EGF-like-domains 10 adhesion NM_172522 MEGF11 multiple EGF-like-domains 11 adhesion NM_010739 MUC13 mucin 13, cell surface associated adhesion NM_013610 NINJ1 ninjurin 1 adhesion NM_016718 NINJ2 ninjurin 2 adhesion NM_172932 NLGN3 neuroligin -

Mouse Ttc39a Knockout Project (CRISPR/Cas9)
https://www.alphaknockout.com Mouse Ttc39a Knockout Project (CRISPR/Cas9) Objective: To create a Ttc39a knockout Mouse model (C57BL/6J) by CRISPR/Cas-mediated genome engineering. Strategy summary: The Ttc39a gene (NCBI Reference Sequence: NM_153392 ; Ensembl: ENSMUSG00000028555 ) is located on Mouse chromosome 4. 18 exons are identified, with the ATG start codon in exon 1 and the TAG stop codon in exon 18 (Transcript: ENSMUST00000064129). Exon 2~5 will be selected as target site. Cas9 and gRNA will be co-injected into fertilized eggs for KO Mouse production. The pups will be genotyped by PCR followed by sequencing analysis. Note: Exon 2 starts from about 2.26% of the coding region. Exon 2~5 covers 22.11% of the coding region. The size of effective KO region: ~6956 bp. The KO region does not have any other known gene. Page 1 of 9 https://www.alphaknockout.com Overview of the Targeting Strategy Wildtype allele 5' gRNA region gRNA region 3' 1 2 3 4 5 18 Legends Exon of mouse Ttc39a Knockout region Page 2 of 9 https://www.alphaknockout.com Overview of the Dot Plot (up) Window size: 15 bp Forward Reverse Complement Sequence 12 Note: The 2000 bp section upstream of Exon 2 is aligned with itself to determine if there are tandem repeats. Tandem repeats are found in the dot plot matrix. The gRNA site is selected outside of these tandem repeats. Overview of the Dot Plot (down) Window size: 15 bp Forward Reverse Complement Sequence 12 Note: The 2000 bp section downstream of Exon 5 is aligned with itself to determine if there are tandem repeats. -

Mouse Ttc39a Conditional Knockout Project (CRISPR/Cas9)
https://www.alphaknockout.com Mouse Ttc39a Conditional Knockout Project (CRISPR/Cas9) Objective: To create a Ttc39a conditional knockout Mouse model (C57BL/6J) by CRISPR/Cas-mediated genome engineering. Strategy summary: The Ttc39a gene (NCBI Reference Sequence: NM_153392 ; Ensembl: ENSMUSG00000028555 ) is located on Mouse chromosome 4. 18 exons are identified, with the ATG start codon in exon 1 and the TAG stop codon in exon 18 (Transcript: ENSMUST00000064129). Exon 3~5 will be selected as conditional knockout region (cKO region). Deletion of this region should result in the loss of function of the Mouse Ttc39a gene. To engineer the targeting vector, homologous arms and cKO region will be generated by PCR using BAC clone RP23-110F24 as template. Cas9, gRNA and targeting vector will be co-injected into fertilized eggs for cKO Mouse production. The pups will be genotyped by PCR followed by sequencing analysis. Note: Exon 3 starts from about 8.33% of the coding region. The knockout of Exon 3~5 will result in frameshift of the gene. The size of intron 2 for 5'-loxP site insertion: 5201 bp, and the size of intron 5 for 3'-loxP site insertion: 3358 bp. The size of effective cKO region: ~2297 bp. The cKO region does not have any other known gene. Page 1 of 8 https://www.alphaknockout.com Overview of the Targeting Strategy Wildtype allele 5' gRNA region gRNA region 3' 1 3 4 5 18 Targeting vector Targeted allele Constitutive KO allele (After Cre recombination) Legends Exon of mouse Ttc39a Homology arm cKO region loxP site Page 2 of 8 https://www.alphaknockout.com Overview of the Dot Plot Window size: 10 bp Forward Reverse Complement Sequence 12 Note: The sequence of homologous arms and cKO region is aligned with itself to determine if there are tandem repeats. -
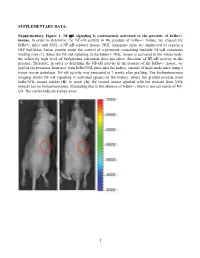
Activation of NF-Κb Signaling Promotes Prostate Cancer Progression in the Mouse and Predicts Poor Progression and Death in Pati
SUPPLEMENTARY DATA: Supplementary Figure 1. NF-B signaling is continuously activated in the prostate of - mouse. In order to determine the NF- '- mouse, we crossed the '- mice with NGL, a NF-B reporter mouse. NGL transgenic mice are engineered to express a GFP/luciferase fusion protein under the control of a promoter containing multiple NF-B consensus binding sites (1). Since the NF-'- NGL mouse is activated in the whole body, the relatively high level of background activation does not allow detection of NF- prostate. Therefore, in order to determine the NF-the '- mouse, we grafted the prostates from 'o the kidney capsule of male nude mice using a tissue rescue technique. NF-B activity was measured at 7 weeks after grafting. The bioluminescence imaging shows NF-B signaling is activated (green) in the kidney, where the grafted prostate from ' use resides (B). In panel (A), the control mouse (grafted with the prostate from NGL mouse) has no bioluminescence, illustrating that in the absence of '-, there is not activation of NF- B. The circles indicate kidney areas. 1 Supplementary Figure 2. NF-B signaling activated in the prostate of Myc/IB bigenic mouse. The prostates from Myc alone (Myc) and bigenic (Myc/IB) mice were harvested at 6 months of age. Activation of NF-B signaling in the prostate was determined by IHC staining of p65-pho antibody. 2 Supplementary Figure 3. Continuous activation of NF-B signaling promotes PCa progression in the Hi-Myc transgenic mouse. The prostates from Myc alone (Myc) and bigeneic (Myc/IB) mice were harvested at 6 months of age. -

Genetic Characterization of Large Parathyroid Adenomas
Endocrine-Related Cancer (2012) 19 389–407 Genetic characterization of large parathyroid adenomas Luqman Sulaiman1,2, Inga-Lena Nilsson3, C Christofer Juhlin1,2,4, Felix Haglund1,2, Anders Ho¨o¨g4, Catharina Larsson1,2 and Jamileh Hashemi1,2 1Medical Genetics Unit, Department of Molecular Medicine and Surgery, Karolinska Institutet, Karolinska University Hospital CMM L8:01, SE-171 76 Stockholm, Sweden 2Center for Molecular Medicine, Karolinska University Hospital, L8:01, SE-171 76 Stockholm, Sweden 3Endocrine Surgery Unit, Department of Molecular Medicine and Surgery, Karolinska Institutet, Karolinska University Hospital P9:03, SE-171 76 Stockholm, Sweden 4Department of Oncology-Pathology, Karolinska Institutet, Karolinska University Hospital P1:02, SE-171 76 Stockholm, Sweden (Correspondence should be addressed to C Larsson at Medical Genetics Unit, Department of Molecular Medicine and Surgery, Karolinska Institutet, Center for Molecular Medicine, Karolinska University Hospital CMM L8:01; Email: [email protected]) Abstract In this study, we genetically characterized parathyroid adenomas with large glandular weights, for which independent observations suggest pronounced clinical manifestations. Large parathyroid adenomas (LPTAs) were defined as the 5% largest sporadic parathyroid adenomas identified among the 590 cases operated in our institution during 2005–2009. The LPTA group showed a higher relative number of male cases and significantly higher levels of total plasma and ionized serum calcium (P!0.001). Further analysis of 21 LPTAs revealed low MIB1 proliferation index (0.1–1.5%), MEN1 mutations in five cases, and one HRPT2 (CDC73) mutation. Total or partial loss of parafibromin expression was observed in ten tumors, two of which also showed loss of APC expression.