Pdftk Extract Pages from Pdf
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Coldfusion Server and Performance Management Suite 2018
ColdFusion Server and Performance Management Suite 2018 Third Party Software Notices and/or Additional Terms and Conditions Date Generated: 2018/09/10 LibJPEG ID: 54 Thomas G. Lane This software is based in part on the work of the Independent JPEG Group. _________________________________________________________________________________________________________ Adobe modified Zlib ID: 823 Jean-loup Gailly and Mark Adler Portions include technology used under license from Jean-loup Gailly and Mark Adler, and are copyrighted. _________________________________________________________________________________________________________ Apache Commons Collections ID: 306 Apache Foundation and Contributors This product includes software licensed under the Apache License, Version 2.0 http://www.apache.org/licenses/LICENSE-2.0 _________________________________________________________________________________________________________ Apache Commons Collections ID: 1132 The Apache Software Foundation The Apache Software License, Version 1.1 Copyright (c) 1999-2001, 1999-2003 The Apache Software Foundation. All rights reserved. Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met: 1. Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer. 2. Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other -

Pdftk Server Redistribution Agreement Version
SOFTWARE LICENSE AND DISTRIBUTION AGREEMENT Steward and Lee, LLC PDFtk Server Redistribution License VERSION 2.0 Only by delivering a valid PDFtk Server Redistribution License serial number (ªLicense Serial Numberº) to Licensee does PDF Labs accept the terms and conditions of this Agreement with Licensee. By making the payment in paragraph 2.2.2 or by utilizing a License Serial Number, Licensee acknowledges that Licensee has read, understood and accepted the terms and conditions of this Agreement with PDF Labs. THIS SOFTWARE LICENSE AGREEMENT ("Agreement") is made by and between the individual, company or legal entity that is licensing the Licensed Software ("Licensee"), and Steward and Lee, LLC ("PDF Labs"), a company with primary offices located in McKinney, Texas, USA. 1 DEFINITIONS. 1.1 "PDF Labs Website" shall mean http://www.pdflabs.com. 1.2 "Combined Product" shall mean the product created by Licensee by incorporating or embedding the Licensed Software into third party software. 1.3 "Effective Date" shall mean the date on which this Agreement is accepted by Licensee. 1.4 "Licensed Software" shall mean PDFtk Server in machine executable form and source code, its documentation, and any bug fixes or other changes provided to Licensee as available on the PDF Labs Website. 1.5 "Specifications" shall mean the Licensed Software API specifications and help documentation, available from the PDF Labs Website. 1.6 "Sub-license Agreement" shall mean any agreement entered into by and between Licensee and any other individual or entity under which such individual or entity is granted a sub-license to the Combined Product. -

Sample-Ch01 Lowagie.Pdf
S AMPLE CHAPTER iText in Action by Bruno Lowagie Sample Chapter 1 Copyright 2007 Manning Publications brief contents PART 1 INTRODUCTION ......................................................1 1 ■ iText: when and why 3 2 ■ PDF engine jump-start 30 3 ■ PDF: why and when 73 PART 2 BASIC BUILDING BLOCKS ......................................97 4 ■ Composing text elements 99 5 ■ Inserting images 135 6 ■ Constructing tables 162 7 ■ Constructing columns 193 PART 3 PDF TEXT AND GRAPHICS ..................................221 8 ■ Choosing the right font 223 9 ■ Using fonts 257 10 ■ Constructing and painting paths 283 vii viii BRIEF CONTENTS 11 ■ Adding color and text 325 12 ■ Drawing to Java Graphics2D 356 PART 4 INTERACTIVE PDF .............................................393 13 ■ Browsing a PDF document 395 14 ■ Automating PDF creation 425 15 ■ Creating annotations and fields 464 16 ■ Filling and signing AcroForms 501 17 ■ iText in web applications 533 18 ■ Under the hood 562 iText: when and why This chapter covers ■ History and first use of iText ■ Overview of iText’s PDF functionality ■ Introduction to the examples in this book 3 4 CHAPTER 1 iText: when and why If you want to enhance applications with dynamic PDF generation and/or manipu- lation, you’ve come to the right place. Throughout this book, you’ll learn how to build applications that produce professional, high-quality PDF documents. More specifically, you’ll learn how to do the following: ■ Serve dynamically generated PDF to a web browser ■ Generate documents and reports based on data from an XML file or a database ■ Create maps and ebooks, exploiting numerous interactive features avail- able in PDF ■ Add bookmarks, page numbers, watermarks, and other features to existing PDF documents ■ Split and/or concatenate pages from existing PDF files ■ Fill out forms, add digital signatures, and much more You’ll create these documents on the fly, meaning you aren’t going to use a desk- top application such as Adobe Acrobat. -

Getting Started with Flying Saucer
Getting Started with Flying Saucer Table of Contents What it is and How it Works ......................................................................................... 1 What it is ............................................................................................................1 What it does ........................................................................................................ 2 What you can do with it ........................................................................................ 2 What it does not do .............................................................................................. 2 License and Dependencies ..................................................................................... 3 Requirements for Running and Using Flying Saucer ................................................... 3 Setting your Classpath ...........................................................................................3 Using Flying Saucer ..................................................................................................... 4 Basic Usage .........................................................................................................4 Sample Applications ............................................................................................. 6 Configuration ...............................................................................................................6 The Flying Saucer Configuration File ..................................................................... -
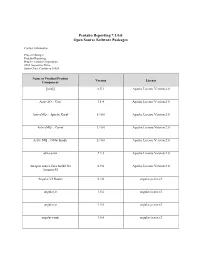
Pentaho Reporting 7.1.0.0 Open Source Software Packages
Pentaho Reporting 7.1.0.0 Open Source Software Packages Contact Information: Project Manager Pentaho Reporting Hitachi Vantara Corporation 2535 Augustine Drive Santa Clara, California 95054 Name of Product/Product Version License Component [ini4j] 0.5.1 Apache License Version 2.0 ActiveIO :: Core 3.1.4 Apache License Version 2.0 ActiveMQ :: Apache Karaf 5.10.0 Apache License Version 2.0 ActiveMQ :: Camel 5.10.0 Apache License Version 2.0 ActiveMQ :: OSGi bundle 5.10.0 Apache License Version 2.0 akka-actor 2.3.3 Apache License Version 2.0 An open source Java toolkit for 0.9.0 Apache License Version 2.0 Amazon S3 Angular UI Router 0.3.0 angular.js.mit.v2 angular.js 1.5.6 angular.js.mit.v2 angular.js 1.5.8 angular.js.mit.v2 angular-route 1.5.6 angular.js.mit.v2 Name of Product/Product Version License Component angular-sanitize-1.5.6 1.5.6 angular.js.mit.v2 angular-translate-2.12.1 2.12.1 angular.js.mit.v2 AngularUI Bootstrap 0.10.0 angular.bootstrap.mit.v2 Annotation 1.0 1.1.1 Apache License Version 2.0 Annotation 1.1 1.0.1 Apache License Version 2.0 ANTLR 3 Complete 3.5.2 ANTLR License Antlr 3.4 Runtime 3.4 ANTLR License ANTLR, ANother Tool for Language 2.7.7 ANTLR License Recognition AOP Alliance (Java/J2EE AOP 1.0 Public Domain standard) Apache ActiveMQ 5.2.0 Apache License Version 2.0 Apache Ant Core 1.9.1 Apache License Version 2.0 Apache Ant Launcher 1.9.1 Apache License Version 2.0 Apache Aries Blueprint API 1.0.1 Apache License Version 2.0 Apache Aries Blueprint CM 1.0.5 Apache License Version 2.0 Name of Product/Product Version -

Creating Accessible Pdfs with MS Office, Acrobat, and Adobe Coldfusion
Slide 1 Creating Accessible PDFs with MS Office, Acrobat, and Adobe ColdFusion By Bouton Jones Adobe ColdFusion Summit October 2, 2018 - 11:45 AM - 12:45 PM (PDT) IT Business Systems Analyst Senior Austin, TX [email protected] [email protected] My pronouns are he, him, and his. Creating Accessible PDFs with MS Office, Acrobat, and Adobe ColdFusion By Bouton Jones Adobe ColdFusion Summit October 2, 2018 - 11:45 AM - 12:45 PM (PDT) IT Business Systems Analyst Senior Austin, TX [email protected] [email protected] My pronouns are he, him, and his. A lot of attention is given to developing accessible web application and web sites but not so much to making accessible PDFs. This session expands on last year's Accessibility session but focuses specifically on creating accessible PDFs. It will cover fillable forms, OCR, redaction, quality assurance, eSignatures/digital signatures, CFDocument, and CFHTMLtoPDF. Slide 2 Life is too short to be spent photographing PowerPoint slides. A handout containing all the slides and speaker notes can be found at http://www.boutonjones.com/pub/a11y.html . #BoutonRocks Life is too short to be spent photographing PowerPoint Slides A handout containing all the slides and speaker notes can be found at http://www.boutonjones.com/pub/a11y.html . #BoutonRocks Slide 3 Three Visually Identical PDFs They have the exact same content, title, headers, font, and colors. So how are they different? Tuesday, October 2, 2018 3 Three Visually Identical PDFs They have the exact same content, title, headers, font, and colors. So how are they different? Slide 4 First PDF Read Text Read Headings Read First List Tuesday, October 2, 2018 4 Tagged PDF with Text Bouton explains (and demonstrates) navigating a PDF with text and navigation (such as headers and lists.) Screen readers (such as Jaws and NVDA) will identify headers and list in a tagged PDF. -
Pdftkbuilder.Pdf)
PDFTK Builder Enhanced User Guide 28 May 2021 PDFTK Builder Enhanced Version: 4.1.6 Date: 28 May 2021 Platform: Windows 32-bit application Developer: David King Compiler: Delphi 10.2 (Tokyo) License: GNU General Public License (GPL), Version 3 Dependencies: PDFtk (v2.02 supplied); installed PDF viewer PDFTK Builder is a free, graphical user interface (GUI) for the Windows version of the popular PDF Toolkit (PDFtk) command line tool, PDFtk Server. The PDFTK Builder Enhanced project forked Version 3 of PDFTK Builder by Angus Johnson to (1) enhance the user interface, (2) add PDF operations, and (3) update the program to be compatible with later versions of PDFtk. The resulting program is PDFTK Builder Version 4. OVERVIEW The following screenshot shows the main form of PDFTK Builder Version 4 with the ‘Join Files’ tab sheet active and the Document Protection panel open. The form contains three sections: (1) 5 different tab sheets each containing an input section for selecting the desired action, input files and options for the PDF functions supported by the tab sheet: Tab Sheet Functions Join Files Merges multiple PDF files or reorders, deletes, duplicates or extracts pages from a single PDF file Split Pages Splits a single PDF file into separate files for each page or into two files containing odd and even pages Mark Pages Stamps, backgrounds or numbers the pages of a single PDF file Rotate Pages Rotates the specified range of pages of a single PDF file by -90, +90 or 180 degrees. Can also extract or delete the range of pages. -

Itext in Action Second Edition
Covers iText 5 SECOND EDITION Bruno Lowagie MANNING Praise for the First Edition Each aspect is explained with numerous examples that can be applied to real-world problems right away. —Ulf Ditmer, JavaRanch Any developer who is making serious use of iText would be a fool not to buy this book. —Dave Gilbert, jfree.org Thorough and complete ... will be a long-running, valuable resource for iText and PDF. —Alan Dennis Software Architect, MyFamily.com One of the best technical books I have ever read! Great work! —Oliver Zeigermann Technical Trainer, CoreMedia AG I wholeheartedly recommend it. —Doug James eReporting Team Lead, Benefitfocus.com, Inc. Impressive! It provides depth without all the noise. —Justin Lee, President, Antwerkz Inc. Valuable to any developer using PDF. —Stuart Caborn, Consultant, Thoughtworks Licensed to Bruno Lowagie <[email protected]> Licensed to Bruno Lowagie <[email protected]> iText in Action Second Edition BRUNO LOWAGIE MANNING Greenwich (74° w. long.) Licensed to Bruno Lowagie <[email protected]> For online information and ordering of this and other Manning books, please visit www.manning.com. The publisher offers discounts on this book when ordered in quantity. For more information, please contact Special Sales Department Manning Publications Co. 180 Broad Street Suite 1323 Stamford, CT 06901 Email: [email protected] ©2011 by Manning Publications Co. All rights reserved. No part of this publication may be reproduced, stored in a retrieval system, or transmitted, in any form or by means electronic, mechanical, photocopying, or otherwise, without prior written permission of the publisher. Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. -

Third Party Software Attributions, Copyrights, Licenses and Disclosure
Third Party Software Attributions, Copyrights, Licenses and Disclosure Qlik Catalog ® October 2020 Release Certain open source or other third-party software and data components are integrated and/or redistributed with various releases of Qlik Catalog. Such third-party components include terms and conditions, such as attribution and liability disclaimers (collectively "Third Party Disclosures") for which disclosure is required by their respective owners. This document sets forth such Third Party Disclosures for the specified version of Qlik Catalog, as of the date set forth above. This disclosure is also available within the Documentation for Qlik Catalog, as well as on the Qlik web page located at http://www.qlik.com/license-terms. NEITHER QLIKTECH INTERNATIONAL AB NOR ANY OF ITS AFFILIATES (COLLECTIVELY, “QLIK”) MAKES ANY REPRESENTATION, WARRANTY OR OTHER COMMITMENT REGARDING SUCH THIRD PARTY COMPONENTS. Component Version License URL abego TreeLayout Core 1.0.1 BSD 3-clause License http://code.google.com/p/treelayout/ http://repo.maven.apache.org/maven2/org/activiti/activiti- Activiti - BPMN Converter 5.22.0 Apache License 2.0 bpmn-converter/ http://repo.maven.apache.org/maven2/org/activiti/activiti- Activiti - BPMN Layout 5.22.0 Apache License 2.0 bpmn-layout/ http://repo.maven.apache.org/maven2/org/activiti/activiti- Activiti - BPMN Model 5.22.0 Apache License 2.0 bpmn-model/ http://repo.maven.apache.org/maven2/org/activiti/activiti- Activiti - Engine 5.22.0 Apache License 2.0 engine/ http://repo.maven.apache.org/maven2/org/activiti/activiti- -

Open Source License Acknowledgements and Third Party Copyrights for CSA 6.0.2
Open Source License Acknowledgements and Third Party Copyrights for CSA 6.0.2 Part number: OL-21169-01 Cisco Security Agent utilizes third party software from various sources. Portions of this software are copyrighted by their respective owners as indicated in the copyright notices below. This document provides regulatory open source licensing information for the Management Center for Cisco Security and Cisco Security Agent, version 6.0.2. The following acknowledgements pertain to this software license. • OpenSSL/Open SSL Project, page 2 • Apache [version 2.0.59], page 3 • TCL license, page 6 • Perl, page 7 • Socket6, page 7 • libpcap, page 8 • CMU-SNMP Libraries, page 8 • Open Market FastCGI, page 8 • CGIC License, page 9 • Mozilla 1.xx (libcurl), page 9 • MICROSOFT SOFTWARE LICENSE TERMS, page 10 • .Net Framework 2.0, page 12 • MarshallSoft Computing SMTP/POP3 Email Engine, page 13 • Jasper Reports V1.2.0 and JFreeChart V1.0.5, page 14 • iText version 1.3.1, page 20 • Java Runtime Environment JRE 1.5.0.06, page 27 • The GNU General Public License (GPL), page 29 Americas Headquarters: Cisco Systems, Inc., 170 West Tasman Drive, San Jose, CA 95134-1706 USA OpenSSL/Open SSL Project OpenSSL/Open SSL Project This product includes software developed by the OpenSSL Project for use in the OpenSSL Toolkit (http://www.openssl.org/). This product includes cryptographic software written by Eric Young ([email protected]). This product includes software written by Tim Hudson ([email protected]). License Issues The OpenSSL toolkit stays under a dual license, i.e. both the conditions of the OpenSSL License and the original SSLeay license apply to the toolkit. -

End User Agreement
END USER AGREEMENT This End User Agreement (“Agreement”) is a legal agreement between you, as purchaser of the Products (“Customer”) and Silver Peak Systems, Inc. (“Company”) regarding your purchase of the Product with these terms and conditions. By using the Product, you agree to be bound by the terms of this Agreement. If you do not agree to the terms of this Agreement, promptly return the Product and accompanying items to the place you obtained them for a full refund. 1. Definitions. “Appliance Product” means the hardware product that accompanies these terms and conditions. “Documentation” means any user instructions, manuals or other materials, and on-line help files regarding the use of the Products that are generally provided by Company in connection with the Products. “Product(s)” means collectively, the Appliance Product and the Software. “Software” means Company’s commercially released machine-executable object code version of software, either for execution on the Appliance Product or as a standalone product, and any updates, upgrades, or new releases of such software that are made available by Company from time to time. “Third Party Software” means third party components, libraries, or modules and relevant documentation delivered with the Software including but not limited to items listed in Exhibit A. 2. Software. Subject to the terms and conditions of this Agreement, Company grants to Customer a personal, non-exclusive, non-sublicenseable and non-transferable license to (a) use the Software, either as installed on the Appliance Product or, if distributed separately as a standalone product, then as distributed, solely in binary form for Customer’s own internal needs; and (b) use the Documentation in connection with the permitted use of the Software. -

The Flying Saucer User's Guide
The Flying Saucer User's Guide Getting Started with Flying Saucer Release R6 May 2006 Table of Contents 1. An Introduction to Flying Saucer 1. What It Is 2. What It Does 3. What It's Good For 4. Where the Saucer Does not Fly (what it can't do) 5. License and Dependencies 6. Requirements for Running and Using Flying Saucer 7. Setting your Classpath 2. Using Flying Saucer 1. Basic Usage 2. Creating PDF Files 3. Rendering to an Image 4. Sample Applications 3. Configuration 1. The Flying Saucer Configuration File 2. Logging Page 2 of 14 An Introduction to Flying Saucer What It Is Flying Saucer is a renderer, which means it takes XML files as input, and generates a rendered representation of that XML as output. The output may go to the screen (in a GUI), to an image, or to a PDF file. Because we believe most people will rely on conventional practices, our main target for content is XHTML, an XML document format that standardizes HTML. However, we accept any well-formed XML for rendering as long as CSS is provided that tells us how to lay it out. In the case of XHTML, default stylesheets are provided out of the box. Internally, Flying Saucer works with an XML document and uses CSS to determine how to lay it out visually. The rules for layout come from the CSS 2.1 Specification, and according to that spec, element nodes and attributes are matched to CSS selectors, where each selector identifies some formatting rules. We can't cover how to use CSS here—it's a long and complex specification—but there are many good books available, and tutorials on the web.