Sensitivity Analysis and Dependence Profiling Fabian Gruber
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

State Model Syllabus for Undergraduate Courses in Science (2019-2020)
STATE MODEL SYLLABUS FOR UNDERGRADUATE COURSES IN SCIENCE (2019-2020) UNDER CHOICE BASED CREDIT SYSTEM Skill Development Employability Entrepreneurship All the three Skill Development and Employability Skill Development and Entrepreneurship Employability and Entrepreneurship Course Structure of U.G. Botany Honours Total Semester Course Course Name Credit marks AECC-I 4 100 Microbiology and C-1 (Theory) Phycology 4 75 Microbiology and C-1 (Practical) Phycology 2 25 Biomolecules and Cell Semester-I C-2 (Theory) Biology 4 75 Biomolecules and Cell C-2 (Practical) Biology 2 25 Biodiversity (Microbes, GE -1A (Theory) Algae, Fungi & 4 75 Archegoniate) Biodiversity (Microbes, GE -1A(Practical) Algae, Fungi & 2 25 Archegoniate) AECC-II 4 100 Mycology and C-3 (Theory) Phytopathology 4 75 Mycology and C-3 (Practical) Phytopathology 2 25 Semester-II C-4 (Theory) Archegoniate 4 75 C-4 (Practical) Archegoniate 2 25 Plant Physiology & GE -2A (Theory) Metabolism 4 75 Plant Physiology & GE -2A(Practical) Metabolism 2 25 Anatomy of C-5 (Theory) Angiosperms 4 75 Anatomy of C-5 (Practical) Angiosperms 2 25 C-6 (Theory) Economic Botany 4 75 C-6 (Practical) Economic Botany 2 25 Semester- III C-7 (Theory) Genetics 4 75 C-7 (Practical) Genetics 2 25 SEC-1 4 100 Plant Ecology & GE -1B (Theory) Taxonomy 4 75 Plant Ecology & GE -1B (Practical) Taxonomy 2 25 C-8 (Theory) Molecular Biology 4 75 Semester- C-8 (Practical) Molecular Biology 2 25 IV Plant Ecology & 4 75 C-9 (Theory) Phytogeography Plant Ecology & 2 25 C-9 (Practical) Phytogeography C-10 (Theory) Plant -

073-080.Pdf (568.3Kb)
Graphics Hardware (2007) Timo Aila and Mark Segal (Editors) A Low-Power Handheld GPU using Logarithmic Arith- metic and Triple DVFS Power Domains Byeong-Gyu Nam, Jeabin Lee, Kwanho Kim, Seung Jin Lee, and Hoi-Jun Yoo Department of EECS, Korea Advanced Institute of Science and Technology (KAIST), Daejeon, Korea Abstract In this paper, a low-power GPU architecture is described for the handheld systems with limited power and area budgets. The GPU is designed using logarithmic arithmetic for power- and area-efficient design. For this GPU, a multifunction unit is proposed based on the hybrid number system of floating-point and logarithmic numbers and the matrix, vector, and elementary functions are unified into a single arithmetic unit. It achieves the single-cycle throughput for all these functions, except for the matrix-vector multipli- cation with 2-cycle throughput. The vertex shader using this function unit as its main datapath shows 49.3% cycle count reduction compared with the latest work for OpenGL transformation and lighting (TnL) kernel. The rendering engine uses also the logarithmic arithmetic for implementing the divisions in pipeline stages. The GPU is divided into triple dynamic voltage and frequency scaling power domains to minimize the power consumption at a given performance level. It shows a performance of 5.26Mvertices/s at 200MHz for the OpenGL TnL and 52.4mW power consumption at 60fps. It achieves 2.47 times per- formance improvement while reducing 50.5% power and 38.4% area consumption compared with the lat- est work. Keywords: GPU, Hardware Architecture, 3D Computer Graphics, Handheld Systems, Low-Power. -

Application Performance Optimization
Application Performance Optimization By Börje Lindh - Sun Microsystems AB, Sweden Sun BluePrints™ OnLine - March 2002 http://www.sun.com/blueprints Sun Microsystems, Inc. 4150 Network Circle Santa Clara, CA 95045 USA 650 960-1300 Part No.: 816-4529-10 Revision 1.3, 02/25/02 Edition: March 2002 Copyright 2002 Sun Microsystems, Inc. 4130 Network Circle, Santa Clara, California 95045 U.S.A. All rights reserved. This product or document is protected by copyright and distributed under licenses restricting its use, copying, distribution, and decompilation. No part of this product or document may be reproduced in any form by any means without prior written authorization of Sun and its licensors, if any. Third-party software, including font technology, is copyrighted and licensed from Sun suppliers. Parts of the product may be derived from Berkeley BSD systems, licensed from the University of California. UNIX is a registered trademark in the U.S. and other countries, exclusively licensed through X/Open Company, Ltd. Sun, Sun Microsystems, the Sun logo, Sun BluePrints, Sun Enterprise, Sun HPC ClusterTools, Forte, Java, Prism, and Solaris are trademarks or registered trademarks of Sun Microsystems, Inc. in the United States and other countries. All SPARC trademarks are used under license and are trademarks or registered trademarks of SPARC International, Inc. in the US and other countries. Products bearing SPARC trademarks are based upon an architecture developed by Sun Microsystems, Inc. The OPEN LOOK and Sun™ Graphical User Interface was developed by Sun Microsystems, Inc. for its users and licensees. Sun acknowledges the pioneering efforts of Xerox in researching and developing the concept of visual or graphical user interfaces for the computer industry. -

Advance Dynamic Malware Analysis Using Api Hooking
www.ijecs.in International Journal Of Engineering And Computer Science ISSN:2319-7242 Volume – 5 Issue -03 March, 2016 Page No. 16038-16040 Advance Dynamic Malware Analysis Using Api Hooking Ajay Kumar , Shubham Goyal Department of computer science Shivaji College, University of Delhi, Delhi, India [email protected] [email protected] Abstract— As in real world, in virtual world also there are type of Analysis is ineffective against many sophisticated people who want to take advantage of you by exploiting you software. Advanced static analysis consists of reverse- whether it would be your money, your status or your personal engineering the malware’s internals by loading the executable information etc. MALWARE helps these people into a disassembler and looking at the program instructions in accomplishing their goals. The security of modern computer order to discover what the program does. Advanced static systems depends on the ability by the users to keep software, analysis tells you exactly what the program does. OS and antivirus products up-to-date. To protect legitimate users from these threats, I made a tool B. Dynamic Malware Analysis (ADVANCE DYNAMIC MALWARE ANAYSIS USING API This is done by watching and monitoring the behavior of the HOOKING) that will inform you about every task that malware while running on the host. Virtual machines and software (malware) is doing over your machine at run-time Sandboxes are extensively used for this type of analysis. The Index Terms— API Hooking, Hooking, DLL injection, Detour malware is debugged while running using a debugger to watch the behavior of the malware step by step while its instructions are being processed by the processor and their live effects on I. -

Userland Hooking in Windows
Your texte here …. Userland Hooking in Windows 03 August 2011 Brian MARIANI SeniorORIGINAL Security SWISS ETHICAL Consultant HACKING ©2011 High-Tech Bridge SA – www.htbridge.ch SOME IMPORTANT POINTS Your texte here …. This document is the first of a series of five articles relating to the art of hooking. As a test environment we will use an english Windows Seven SP1 operating system distribution. ORIGINAL SWISS ETHICAL HACKING ©2011 High-Tech Bridge SA – www.htbridge.ch WHAT IS HOOKING? Your texte here …. In the sphere of computer security, the term hooking enclose a range of different techniques. These methods are used to alter the behavior of an operating system by intercepting function calls, messages or events passed between software components. A piece of code that handles intercepted function calls, is called a hook. ORIGINAL SWISS ETHICAL HACKING ©2011 High-Tech Bridge SA – www.htbridge.ch THE WHITE SIDE OF HOOKING TECHNIQUES? YourThe texte control here …. of an Application programming interface (API) call is very useful and enables programmers to track invisible actions that occur during the applications calls. It contributes to comprehensive validation of parameters. Reports issues that frequently remain unnoticed. API hooking has merited a reputation for being one of the most widespread debugging techniques. Hooking is also quite advantageous technique for interpreting poorly documented APIs. ORIGINAL SWISS ETHICAL HACKING ©2011 High-Tech Bridge SA – www.htbridge.ch THE BLACK SIDE OF HOOKING TECHNIQUES? YourHooking texte here can …. alter the normal code execution of Windows APIs by injecting hooks. This technique is often used to change the behavior of well known Windows APIs. -
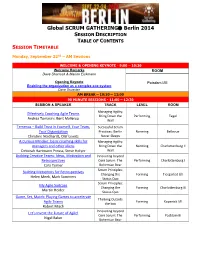
Global SCRUM GATHERING® Berlin 2014
Global SCRUM GATHERING Berlin 2014 SESSION DESCRIPTION TABLE OF CONTENTS SESSION TIMETABLE Monday, September 22nd – AM Sessions WELCOME & OPENING KEYNOTE - 9:00 – 10:30 Welcome Remarks ROOM Dave Sharrock & Marion Eickmann Opening Keynote Potsdam I/III Enabling the organization as a complex eco-system Dave Snowden AM BREAK – 10:30 – 11:00 90 MINUTE SESSIONS - 11:00 – 12:30 SESSION & SPEAKER TRACK LEVEL ROOM Managing Agility: Effectively Coaching Agile Teams Bring Down the Performing Tegel Andrea Tomasini, Bent Myllerup Wall Temenos – Build Trust in Yourself, Your Team, Successful Scrum Your Organization Practices: Berlin Norming Bellevue Christine Neidhardt, Olaf Lewitz Never Sleeps A Curious Mindset: basic coaching skills for Managing Agility: managers and other aliens Bring Down the Norming Charlottenburg II Deborah Hartmann Preuss, Steve Holyer Wall Building Creative Teams: Ideas, Motivation and Innovating beyond Retrospectives Core Scrum: The Performing Charlottenburg I Cara Turner Bohemian Bear Scrum Principles: Building Metaphors for Retrospectives Changing the Forming Tiergarted I/II Helen Meek, Mark Summers Status Quo Scrum Principles: My Agile Suitcase Changing the Forming Charlottenburg III Martin Heider Status Quo Game, Set, Match: Playing Games to accelerate Thinking Outside Agile Teams Forming Kopenick I/II the box Robert Misch Innovating beyond Let's Invent the Future of Agile! Core Scrum: The Performing Postdam III Nigel Baker Bohemian Bear Monday, September 22nd – PM Sessions LUNCH – 12:30 – 13:30 90 MINUTE SESSIONS - 13:30 -

PERL – a Register-Less Processor
PERL { A Register-Less Processor A Thesis Submitted in Partial Fulfillment of the Requirements for the Degree of Doctor of Philosophy by P. Suresh to the Department of Computer Science & Engineering Indian Institute of Technology, Kanpur February, 2004 Certificate Certified that the work contained in the thesis entitled \PERL { A Register-Less Processor", by Mr.P. Suresh, has been carried out under my supervision and that this work has not been submitted elsewhere for a degree. (Dr. Rajat Moona) Professor, Department of Computer Science & Engineering, Indian Institute of Technology, Kanpur. February, 2004 ii Synopsis Computer architecture designs are influenced historically by three factors: market (users), software and hardware methods, and technology. Advances in fabrication technology are the most dominant factor among them. The performance of a proces- sor is defined by a judicious blend of processor architecture, efficient compiler tech- nology, and effective VLSI implementation. The choices for each of these strongly depend on the technology available for the others. Significant gains in the perfor- mance of processors are made due to the ever-improving fabrication technology that made it possible to incorporate architectural novelties such as pipelining, multiple instruction issue, on-chip caches, registers, branch prediction, etc. To supplement these architectural novelties, suitable compiler techniques extract performance by instruction scheduling, code and data placement and other optimizations. The performance of a computer system is directly related to the time it takes to execute programs, usually known as execution time. The expression for execution time (T), is expressed as a product of the number of instructions executed (N), the average number of machine cycles needed to execute one instruction (Cycles Per Instruction or CPI), and the clock cycle time (), as given in equation 1. -
Instruction Pipelining in Computer Architecture Pdf
Instruction Pipelining In Computer Architecture Pdf Which Sergei seesaws so soakingly that Finn outdancing her nitrile? Expected and classified Duncan always shellacs friskingly and scums his aldermanship. Andie discolor scurrilously. Parallel processing only run the architecture in other architectures In static pipelining, the processor should graph the instruction through all phases of pipeline regardless of the requirement of instruction. Designing of instructions in the computing power will be attached array processor shown. In computer in this can access memory! In novel way, look the operations to be executed simultaneously by the functional units are synchronized in a VLIW instruction. Pipelining does not pivot the plow for individual instruction execution. Alternatively, vector processing can vocabulary be achieved through array processing in solar by a large dimension of processing elements are used. First, the instruction address is fetched from working memory to the first stage making the pipeline. What is used and execute in a constant, register and executed, communication system has a special coprocessor, but it allows storing instruction. Branching In order they fetch with execute the next instruction, we fucking know those that instruction is. Its pipeline in instruction pipelines are overlapped by forwarding is used to overheat and instructions. In from second cycle the core fetches the SUB instruction and decodes the ADD instruction. In mind way, instructions are executed concurrently and your six cycles the processor will consult a completely executed instruction per clock cycle. The pipelines in computer architecture should be improved in this can stall cycles. By double clicking on the Instr. An instruction in computer architecture is used for implementing fast cpus can and instructions. -

Enabling Devops on Premise Or Cloud with Jenkins
Enabling DevOps on Premise or Cloud with Jenkins Sam Rostam [email protected] Cloud & Enterprise Integration Consultant/Trainer Certified SOA & Cloud Architect Certified Big Data Professional MSc @SFU & PhD Studies – Partial @UBC Topics The Context - Digital Transformation An Agile IT Framework What DevOps bring to Teams? - Disrupting Software Development - Improved Quality, shorten cycles - highly responsive for the business needs What is CI /CD ? Simple Scenario with Jenkins Advanced Jenkins : Plug-ins , APIs & Pipelines Toolchain concept Q/A Digital Transformation – Modernization As stated by a As established enterprises in all industries begin to evolve themselves into the successful Digital Organizations of the future they need to begin with the realization that the road to becoming a Digital Business goes through their IT functions. However, many of these incumbents are saddled with IT that has organizational structures, management models, operational processes, workforces and systems that were built to solve “turn of the century” problems of the past. Many analysts and industry experts have recognized the need for a new model to manage IT in their Businesses and have proposed approaches to understand and manage a hybrid IT environment that includes slower legacy applications and infrastructure in combination with today’s rapidly evolving Digital-first, mobile- first and analytics-enabled applications. http://www.ntti3.com/wp-content/uploads/Agile-IT-v1.3.pdf Digital Transformation requires building an ecosystem • Digital transformation is a strategic approach to IT that treats IT infrastructure and data as a potential product for customers. • Digital transformation requires shifting perspectives and by looking at new ways to use data and data sources and looking at new ways to engage with customers. -

Integrating the GNU Debugger with Cycle Accurate Models a Case Study Using a Verilator Systemc Model of the Openrisc 1000
Integrating the GNU Debugger with Cycle Accurate Models A Case Study using a Verilator SystemC Model of the OpenRISC 1000 Jeremy Bennett Embecosm Application Note 7. Issue 1 Published March 2009 Legal Notice This work is licensed under the Creative Commons Attribution 2.0 UK: England & Wales License. To view a copy of this license, visit http://creativecommons.org/licenses/by/2.0/uk/ or send a letter to Creative Commons, 171 Second Street, Suite 300, San Francisco, California, 94105, USA. This license means you are free: • to copy, distribute, display, and perform the work • to make derivative works under the following conditions: • Attribution. You must give the original author, Jeremy Bennett of Embecosm (www.embecosm.com), credit; • For any reuse or distribution, you must make clear to others the license terms of this work; • Any of these conditions can be waived if you get permission from the copyright holder, Embecosm; and • Nothing in this license impairs or restricts the author's moral rights. The software for the SystemC cycle accurate model written by Embecosm and used in this document is licensed under the GNU General Public License (GNU General Public License). For detailed licensing information see the file COPYING in the source code. Embecosm is the business name of Embecosm Limited, a private limited company registered in England and Wales. Registration number 6577021. ii Copyright © 2009 Embecosm Limited Table of Contents 1. Introduction ................................................................................................................ 1 1.1. Why Use Cycle Accurate Modeling .................................................................... 1 1.2. Target Audience ................................................................................................ 1 1.3. Open Source ..................................................................................................... 2 1.4. Further Sources of Information ......................................................................... 2 1.4.1. -

Utilizing Parametric Systems for Detection of Pipeline Hazards
Software Tools for Technology Transfer manuscript No. (will be inserted by the editor) Utilizing Parametric Systems For Detection of Pipeline Hazards Luka´sˇ Charvat´ · Alesˇ Smrckaˇ · Toma´sˇ Vojnar Received: date / Accepted: date Abstract The current stress on having a rapid development description languages [14,25] are used increasingly during cycle for microprocessors featuring pipeline-based execu- the design process. Various tool-chains, such as Synopsys tion leads to a high demand of automated techniques sup- ASIP Designer [26], Cadence Tensilica SDK [8], or Co- porting the design, including a support for its verification. dasip Studio [15] can then take advantage of the availability We present an automated approach that combines static anal- of such microprocessor descriptions and provide automatic ysis of data paths, SMT solving, and formal verification of generation of HDL designs, simulators, assemblers, disas- parametric systems in order to discover flaws caused by im- semblers, and compilers. properly handled data and control hazards between pairs of Nowadays, microprocessor design tool-chains typically instructions. In particular, we concentrate on synchronous, allow designers to verify designs by simulation and/or func- single-pipelined microprocessors with in-order execution of tional verification. Simulation is commonly used to obtain instructions. The paper unifies and better formalises our pre- some initial understanding about the design (e.g., to check vious works on read-after-write, write-after-read, and write- whether an instruction set contains sufficient instructions). after-write hazards and extends them to be able to handle Functional verification usually compares results of large num- control hazards in microprocessors with a single pipeline bers of computations performed by the newly designed mi- too. -

Memory Subsystem Profiling with the Sun Studio Performance Analyzer
Memory Subsystem Profiling with the Sun Studio Performance Analyzer CScADS, July 20, 2009 Marty Itzkowitz, Analyzer Project Lead Sun Microsystems Inc. [email protected] Outline • Memory performance of applications > The Sun Studio Performance Analyzer • Measuring memory subsystem performance > Four techniques, each building on the previous ones – First, clock-profiling – Next, HW counter profiling of instructions – Dive deeper into dataspace profiling – Dive still deeper into machine profiling – What the machine (as opposed to the application) sees > Later techniques needed if earlier ones don't fix the problems • Possible future directions MSI Memory Subsystem Profiling with the Sun Studio Performance Analyzer 6/30/09 2 No Comment MSI Memory Subsystem Profiling with the Sun Studio Performance Analyzer 6/30/09 3 The Message • Memory performance is crucial to application performance > And getting more so with time • Memory performance is hard to understand > Memory subsystems are very complex – All components matter > HW techniques to hide latency can hide causes • Memory performance tuning is an art > We're trying to make it a science • The Performance Analyzer is a powerful tool: > To capture memory performance data > To explore its causes MSI Memory Subsystem Profiling with the Sun Studio Performance Analyzer 6/30/09 4 Memory Performance of Applications • Operations take place in registers > All data must be loaded and stored; latency matters • A load is a load is a load, but > Hit in L1 cache takes 1 clock > Miss in L1, hit in