Chapter 3: Data Preprocessing
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Moving Average Filters
CHAPTER 15 Moving Average Filters The moving average is the most common filter in DSP, mainly because it is the easiest digital filter to understand and use. In spite of its simplicity, the moving average filter is optimal for a common task: reducing random noise while retaining a sharp step response. This makes it the premier filter for time domain encoded signals. However, the moving average is the worst filter for frequency domain encoded signals, with little ability to separate one band of frequencies from another. Relatives of the moving average filter include the Gaussian, Blackman, and multiple- pass moving average. These have slightly better performance in the frequency domain, at the expense of increased computation time. Implementation by Convolution As the name implies, the moving average filter operates by averaging a number of points from the input signal to produce each point in the output signal. In equation form, this is written: EQUATION 15-1 Equation of the moving average filter. In M &1 this equation, x[ ] is the input signal, y[ ] is ' 1 % y[i] j x [i j ] the output signal, and M is the number of M j'0 points used in the moving average. This equation only uses points on one side of the output sample being calculated. Where x[ ] is the input signal, y[ ] is the output signal, and M is the number of points in the average. For example, in a 5 point moving average filter, point 80 in the output signal is given by: x [80] % x [81] % x [82] % x [83] % x [84] y [80] ' 5 277 278 The Scientist and Engineer's Guide to Digital Signal Processing As an alternative, the group of points from the input signal can be chosen symmetrically around the output point: x[78] % x[79] % x[80] % x[81] % x[82] y[80] ' 5 This corresponds to changing the summation in Eq. -

Informal Data Transformation Considered Harmful
Informal Data Transformation Considered Harmful Eric Daimler, Ryan Wisnesky Conexus AI out the enterprise, so that data and programs that depend on that data need not constantly be re-validated for ev- ery particular use. Computer scientists have been develop- ing techniques for preserving data integrity during trans- formation since the 1970s (Doan, Halevy, and Ives 2012); however, we agree with the authors of (Breiner, Subrah- manian, and Jones 2018) and others that these techniques are insufficient for the practice of AI and modern IT sys- tems integration and we describe a modern mathematical approach based on category theory (Barr and Wells 1990; Awodey 2010), and the categorical query language CQL2, that is sufficient for today’s needs and also subsumes and unifies previous approaches. 1.1 Outline To help motivate our approach, we next briefly summarize an application of CQL to a data science project undertaken jointly with the Chemical Engineering department of Stan- ford University (Brown, Spivak, and Wisnesky 2019). Then, in Section 2 we review data integrity and in Section 3 we re- view category theory. Finally, we describe the mathematics of our approach in Section 4, and conclude in Section 5. We present no new results, instead citing a line of work summa- rized in (Schultz, Spivak, and Wisnesky 2017). Image used under a creative commons license; original 1.2 Motivating Case Study available at http://xkcd.com/1838/. In scientific practice, computer simulation is now a third pri- mary tool, alongside theory and experiment. Within -

Extract, Transformation, and Load(Etl); and Online Analytical Processing(Olap) in Bi
International Journal of Database Management Systems (IJDMS) Vol.12, No.3, June 2020 DESIGN, IMPLEMENTATION, AND ASSESSMENT OF INNOVATIVE DATA WAREHOUSING; EXTRACT, TRANSFORMATION, AND LOAD(ETL); AND ONLINE ANALYTICAL PROCESSING(OLAP) IN BI Ramesh Venkatakrishnan Final Year Doctoral Student, Colorado Technical University, Colorado, USA ABSTRACT The effectiveness of a Business Intelligence System is hugely dependent on these three fundamental components, 1) Data Acquisition (ETL), 2) Data Storage (Data Warehouse), and 3) Data Analytics (OLAP). The predominant challenges with these fundamental components are Data Volume, Data Variety, Data Integration, Complex Analytics, Constant Business changes, Lack of skill sets, Compliance, Security, Data Quality, and Computing requirements. There is no comprehensive documentation that talks about guidelines for ETL, Data Warehouse and OLAP to include the recent trends such as Data Latency (to provide real-time data), BI flexibility (to accommodate changes with the explosion of data) and Self- Service BI. This research paper attempts to fill this gap by analyzing existing scholarly articles in the last three to five years to compile guidelines for effective design, implementation, and assessment of DW, ETL, and OLAP in BI. KEYWORDS Business Intelligence, ETL, DW, OLAP, design implementation and assessment 1. INTRODUCTION “Business intelligence (BI) is an umbrella term that includes the applications, infrastructure and tools, and best practices that enable access to and analysis of information to improve and optimize decisions and performance” [1]. Data Acquisition, Data Storage, and Data Analytics are the primary components of a BI system, and for it to be successful, practical design and implementation of these three components are critical. Source systems such as OLTP records business events. -

Automating the Capture of Data Transformations from Statistical Scripts in Data Documentation Jie Song George Alter H
C2Metadata: Automating the Capture of Data Transformations from Statistical Scripts in Data Documentation Jie Song George Alter H. V. Jagadish University of Michigan University of Michigan University of Michigan Ann Arbor, Michigan Ann Arbor, Michigan Ann Arbor, Michigan [email protected] [email protected] [email protected] ABSTRACT CCS CONCEPTS Datasets are often derived by manipulating raw data with • Information systems → Data provenance; Extraction, statistical software packages. The derivation of a dataset transformation and loading. must be recorded in terms of both the raw input and the ma- nipulations applied to it. Statistics packages typically provide KEYWORDS limited help in documenting provenance for the resulting de- data transformation, data documentation, data provenance rived data. At best, the operations performed by the statistical ACM Reference Format: package are described in a script. Disparate representations Jie Song, George Alter, and H. V. Jagadish. 2019. C2Metadata: Au- make these scripts hard to understand for users. To address tomating the Capture of Data Transformations from Statistical these challenges, we created Continuous Capture of Meta- Scripts in Data Documentation. In 2019 International Conference data (C2Metadata), a system to capture data transformations on Management of Data (SIGMOD ’19), June 30-July 5, 2019, Am- in scripts for statistical packages and represent it as metadata sterdam, Netherlands. ACM, New York, NY, USA, 4 pages. https: in a standard format that is easy to understand. We do so by //doi.org/10.1145/3299869.3320241 devising a Structured Data Transformation Algebra (SDTA), which uses a small set of algebraic operators to express a 1 INTRODUCTION large fraction of data manipulation performed in practice. -

Spatio-Temporal Data Reduction with Deterministic Error Bounds
The VLDB Journal (2006) 15(3): 211–228 DOI 10.1007/s00778-005-0163-7 REGULAR PAPER Hu Cao · Ouri Wolfson · Goce Trajcevski Spatio-temporal data reduction with deterministic error bounds Received: 26 March 2004 / Revised: 22 January 2005 / Accepted: 20 March 2005 / Published online: 28 April 2006 c Springer-Verlag 2006 Abstract A common way of storing spatio-temporal infor- 1 Introduction mation about mobile devices is in the form of a 3D (2D geography + time) trajectory. We argue that when cellular In this paper we consider lossy compression of spatio- phones and Personal Digital Assistants become location- temporal information, particularly trajectories (i.e., motion aware, the size of the spatio-temporal information gener- traces) of moving objects databases. The compression is ated may prohibit efficient processing. We propose to adopt done by approximating each trajectory, but in contrast to a technique studied in computer graphics, namely line- traditional compression methods, we are interested in ap- simplification, as an approximation technique to solve this proximations that guarantee a bound on the error, i.e., in problem. Line simplification will reduce the size of the tra- which the distance between the approximation and the origi- jectories. Line simplification uses a distance function in nal trajectory is bounded. We employ line-simplification for producing the trajectory approximation. We postulate the this type of compression. Next, we consider various types desiderata for such a distance-function: it should be sound, of queries on the approximations database, e.g., range and namely the error of the answers to spatio-temporal queries joins. It turns out that even though the error of each approxi- must be bounded. -

On the Use of Discrete Fourier Transform for Solving Biperiodic Boundary Value Problem of Biharmonic Equation in the Unit Rectangle
On the Use of Discrete Fourier Transform for Solving Biperiodic Boundary Value Problem of Biharmonic Equation in the Unit Rectangle Agah D. Garnadi 31 December 2017 Department of Mathematics, Faculty of Mathematics and Natural Sciences, Bogor Agricultural University Jl. Meranti, Kampus IPB Darmaga, Bogor, 16680 Indonesia Abstract This note is addressed to solving biperiodic boundary value prob- lem of biharmonic equation in the unit rectangle. First, we describe the necessary tools, which is discrete Fourier transform for one di- mensional periodic sequence, and then extended the results to 2- dimensional biperiodic sequence. Next, we use the discrete Fourier transform 2-dimensional biperiodic sequence to solve discretization of the biperiodic boundary value problem of Biharmonic Equation. MSC: 15A09; 35K35; 41A15; 41A29; 94A12. Key words: Biharmonic equation, biperiodic boundary value problem, discrete Fourier transform, Partial differential equations, Interpola- tion. 1 Introduction This note is an extension of a work by Henrici [2] on fast solver for Poisson equation to biperiodic boundary value problem of biharmonic equation. This 1 note is organized as follows, in the first part we address the tools needed to solve the problem, i.e. introducing discrete Fourier transform (DFT) follows Henrici's work [2]. The second part, we apply the tools already described in the first part to solve discretization of biperiodic boundary value problem of biharmonic equation in the unit rectangle. The need to solve discretization of biharmonic equation is motivated by its occurence in some applications such as elasticity and fluid flows [1, 4], and recently in image inpainting [3]. Note that the work of Henrici [2] on fast solver for biperiodic Poisson equation can be seen as solving harmonic inpainting. -

What Is a Data Warehouse?
What is a Data Warehouse? By Susan L. Miertschin “A data warehouse is a subject oriented, integrated, time variant, nonvolatile, collection of data in support of management's decision making process.” https: //www. bus iness.auc. dk/oe kostyr /file /What_ is_a_ Data_ Ware house.pdf 2 What is a Data Warehouse? “A copy of transaction data specifically structured for query and analysis” 3 “Data Warehousing is the coordination, architected, and periodic copying of data from various sources, both inside and outside the enterprise, into an environment optimized for analytical and informational processing” ‐ Alan Simon Data Warehousing for Dummies 4 Business Intelligence (BI) • “…implies thinking abstractly about the organization, reasoning about the business, organizing large quantities of information about the business environment.” p. 6 in Giovinazzo textbook • Purpose of BI is to define and execute a strategy 5 Strategic Thinking • Business strategist – Always looking forward to see how the company can meet the objectives reflected in the mission statement • Successful companies – Do more than just react to the day‐to‐day environment – Understand the past – Are able to predict and adapt to the future 6 Business Intelligence Loop Business Intelligence Figure 1‐1 p. 2 Giovinazzo • Encompasses entire loop shown Business Strategist • Data Storage + ETC = OLAP Data Mining Reports Data Warehouse Data Storage • Data WhWarehouse + Tools (yellow) = Extraction,Transformation, Cleaning DiiDecision Support CRM Accounting Finance HR System 7 The Data Warehouse Decision Support Systems Central Repository Metadata Dependent Data DtData Mar t EtExtrac tion DtData Log Administration Cleansing/Tranformation External Extraction Source Extraction Store Independent Data Mart Operational Environment Figure 1-2 p. -

Data Reduction Techniques for Scientific Visualization and Data Analysis
EuroVis 2017 Volume 36 (2017), Number 3 M. Meyer, S. Takahashi, A. Vilanova STAR – State of The Art Report (Guest Editors) Data Reduction Techniques for Scientific Visualization and Data Analysis Samuel Li1 1Department of Computer and Information Science, University of Oregon 1. Introduction staying in one scenario given that many techniques can operate in different modes. We identify these three dimensions as follows, and The classic paradigm for scientific visualization and data analysis elaborate the ideas behind them in Subsection 1.1. is post-hoc, where simulation codes write results on the file system and visualization routines read them back to operate. This paradigm 1. lossy or lossless data reduction; sees file I/O as an increasing bottleneck, in terms of both transfer 2. reduce on write or reduce on read; and rates and storage capacity. As a result, simulation scientists, as data 3. resulting in original memory footprint or reduced memory foot- producers, often sample available time slices to save on disk. This print. sampling process is not risk-free, since the discarded time slices might contain interesting information. 1.1. Use Case Dimensions Visualization and data analysis scientists, as data consumers, see reasonable turnaround times of processing data a precondi- Lossy or lossless: This dimension is concerned with potential in- tion to successfully perform tasks with exploratory natures. The formation loss after applying data reduction. With lossy reduction, turnaround time is often spent on both reading data from disk, and the reduced form can never recover data identical to the original computations that produce meaningful visualizations and statistics. -

POLITECNICO DI TORINO Repository ISTITUZIONALE
POLITECNICO DI TORINO Repository ISTITUZIONALE Rethinking Software Network Data Planes in the Era of Microservices Original Rethinking Software Network Data Planes in the Era of Microservices / Miano, Sebastiano. - (2020 Jul 13), pp. 1-175. Availability: This version is available at: 11583/2841176 since: 2020-07-22T19:49:25Z Publisher: Politecnico di Torino Published DOI: Terms of use: Altro tipo di accesso This article is made available under terms and conditions as specified in the corresponding bibliographic description in the repository Publisher copyright (Article begins on next page) 08 October 2021 Doctoral Dissertation Doctoral Program in Computer and Control Enginering (32nd cycle) Rethinking Software Network Data Planes in the Era of Microservices Sebastiano Miano ****** Supervisor Prof. Fulvio Risso Doctoral examination committee Prof. Antonio Barbalace, Referee, University of Edinburgh (UK) Prof. Costin Raiciu, Referee, Universitatea Politehnica Bucuresti (RO) Prof. Giuseppe Bianchi, University of Rome “Tor Vergata” (IT) Prof. Marco Chiesa, KTH Royal Institute of Technology (SE) Prof. Riccardo Sisto, Polytechnic University of Turin (IT) Politecnico di Torino 2020 This thesis is licensed under a Creative Commons License, Attribution - Noncommercial- NoDerivative Works 4.0 International: see www.creativecommons.org. The text may be reproduced for non-commercial purposes, provided that credit is given to the original author. I hereby declare that, the contents and organisation of this dissertation constitute my own original work and does not compromise in any way the rights of third parties, including those relating to the security of personal data. ........................................ Sebastiano Miano Turin, 2020 Summary With the advent of Software Defined Networks (SDN) and Network Functions Virtualization (NFV), software started playing a crucial role in the computer net- work architectures, with the end-hosts representing natural enforcement points for core network functionalities that go beyond simple switching and routing. -

Data Warehousing on AWS
Data Warehousing on AWS March 2016 Amazon Web Services – Data Warehousing on AWS March 2016 © 2016, Amazon Web Services, Inc. or its affiliates. All rights reserved. Notices This document is provided for informational purposes only. It represents AWS’s current product offerings and practices as of the date of issue of this document, which are subject to change without notice. Customers are responsible for making their own independent assessment of the information in this document and any use of AWS’s products or services, each of which is provided “as is” without warranty of any kind, whether express or implied. This document does not create any warranties, representations, contractual commitments, conditions or assurances from AWS, its affiliates, suppliers or licensors. The responsibilities and liabilities of AWS to its customers are controlled by AWS agreements, and this document is not part of, nor does it modify, any agreement between AWS and its customers. Page 2 of 26 Amazon Web Services – Data Warehousing on AWS March 2016 Contents Abstract 4 Introduction 4 Modern Analytics and Data Warehousing Architecture 6 Analytics Architecture 6 Data Warehouse Technology Options 12 Row-Oriented Databases 12 Column-Oriented Databases 13 Massively Parallel Processing Architectures 15 Amazon Redshift Deep Dive 15 Performance 15 Durability and Availability 16 Scalability and Elasticity 16 Interfaces 17 Security 17 Cost Model 18 Ideal Usage Patterns 18 Anti-Patterns 19 Migrating to Amazon Redshift 20 One-Step Migration 20 Two-Step Migration 20 Tools for Database Migration 21 Designing Data Warehousing Workflows 21 Conclusion 24 Further Reading 25 Page 3 of 26 Amazon Web Services – Data Warehousing on AWS March 2016 Abstract Data engineers, data analysts, and developers in enterprises across the globe are looking to migrate data warehousing to the cloud to increase performance and lower costs. -

Spatial Domain Low-Pass Filters
Low Pass Filtering Why use Low Pass filtering? • Remove random noise • Remove periodic noise • Reveal a background pattern 1 Effects on images • Remove banding effects on images • Smooth out Img-Img mis-registration • Blurring of image Types of Low Pass Filters • Moving average filter • Median filter • Adaptive filter 2 Moving Ave Filter Example • A single (very short) scan line of an image • {1,8,3,7,8} • Moving Ave using interval of 3 (must be odd) • First number (1+8+3)/3 =4 • Second number (8+3+7)/3=6 • Third number (3+7+8)/3=6 • First and last value set to 0 Two Dimensional Moving Ave 3 Moving Average of Scan Line 2D Moving Average Filter • Spatial domain filter • Places average in center • Edges are set to 0 usually to maintain size 4 Spatial Domain Filter Moving Average Filter Effects • Reduces overall variability of image • Lowers contrast • Noise components reduced • Blurs the overall appearance of image 5 Moving Average images Median Filter The median utilizes the median instead of the mean. The median is the middle positional value. 6 Median Example • Another very short scan line • Data set {2,8,4,6,27} interval of 5 • Ranked {2,4,6,8,27} • Median is 6, central value 4 -> 6 Median Filter • Usually better for filtering • - Less sensitive to errors or extremes • - Median is always a value of the set • - Preserves edges • - But requires more computation 7 Moving Ave vs. Median Filtering Adaptive Filters • Based on mean and variance • Good at Speckle suppression • Sigma filter best known • - Computes mean and std dev for window • - Values outside of +-2 std dev excluded • - If too few values, (<k) uses value to left • - Later versions use weighting 8 Adaptive Filters • Improvements to Sigma filtering - Chi-square testing - Weighting - Local order histogram statistics - Edge preserving smoothing Adaptive Filters 9 Final PowerPoint Numerical Slide Value (The End) 10. -
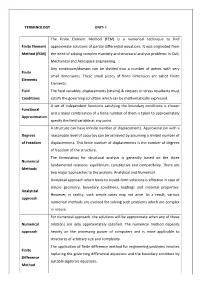
TERMINOLOGY UNIT- I Finite Element Method (FEM)
TERMINOLOGY UNIT- I The Finite Element Method (FEM) is a numerical technique to find Finite Element approximate solutions of partial differential equations. It was originated from Method (FEM) the need of solving complex elasticity and structural analysis problems in Civil, Mechanical and Aerospace engineering. Any continuum/domain can be divided into a number of pieces with very Finite small dimensions. These small pieces of finite dimension are called Finite Elements Elements. Field The field variables, displacements (strains) & stresses or stress resultants must Conditions satisfy the governing condition which can be mathematically expressed. A set of independent functions satisfying the boundary conditions is chosen Functional and a linear combination of a finite number of them is taken to approximately Approximation specify the field variable at any point. A structure can have infinite number of displacements. Approximation with a Degrees reasonable level of accuracy can be achieved by assuming a limited number of of Freedom displacements. This finite number of displacements is the number of degrees of freedom of the structure. The formulation for structural analysis is generally based on the three Numerical fundamental relations: equilibrium, constitutive and compatibility. There are Methods two major approaches to the analysis: Analytical and Numerical. Analytical approach which leads to closed-form solutions is effective in case of simple geometry, boundary conditions, loadings and material properties. Analytical However, in reality, such simple cases may not arise. As a result, various approach numerical methods are evolved for solving such problems which are complex in nature. For numerical approach, the solutions will be approximate when any of these Numerical relations are only approximately satisfied.