Random Drift: Chance and Explanation In
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Timeline of Significant Events in the Development of North American Mammalogy
SpecialSpecial PublicationsPublications MuseumMuseum ofof TexasTexas TechTech UniversityUniversity NumberNumber xx66 21 Novemberxx XXXX 20102017 A Timeline of SignificantTitle Events in the Development of North American Mammalogy Molecular Biology Structural Biology Biochemistry Microbiology Genomics Bioinformatics and Computational Biology Computer Science Statistics Physical Chemistry Information Technology Mathematics David J. Schmidly, Robert D. Bradley, Lisa C. Bradley, and Richard D. Stevens Front cover: This figure depicts a chronological presentation of some of the significant events, technological breakthroughs, and iconic personalities in the history of North American mammalogy. Red lines and arrows depict the chronological flow (i.e., top row – read left to right, middle row – read right to left, and third row – read left to right). See text and tables for expanded interpretation of the importance of each person or event. Top row: The first three panels (from left) are associated with the time period entitled “The Emergence Phase (16th‒18th Centuries)” – Mark Catesby’s 1748 map of Carolina, Florida, and the Bahama Islands, Thomas Jefferson, and Charles Willson Peale; the next two panels represent “The Discovery Phase (19th Century)” – Spencer Fullerton Baird and C. Hart Merriam. Middle row: The first two panels (from right) represent “The Natural History Phase (1901‒1960)” – Joseph Grinnell and E. Raymond Hall; the next three panels (from right) depict “The Theoretical and Technological Phase (1961‒2000)” – illustration of Robert H. MacArthur and Edward O. Wilson’s theory of island biogeography, karyogram depicting g-banded chromosomes, and photograph of electrophoretic mobility of proteins from an allozyme analysis. Bottom row: These four panels (from left) represent the “Big Data Phase (2001‒present)” – chromatogram illustrating a DNA sequence, bioinformatics and computational biology, phylogenetic tree of mammals, and storage banks for a supercomputer. -

Karl Jordan: a Life in Systematics
AN ABSTRACT OF THE DISSERTATION OF Kristin Renee Johnson for the degree of Doctor of Philosophy in History of SciencePresented on July 21, 2003. Title: Karl Jordan: A Life in Systematics Abstract approved: Paul Lawrence Farber Karl Jordan (1861-1959) was an extraordinarily productive entomologist who influenced the development of systematics, entomology, and naturalists' theoretical framework as well as their practice. He has been a figure in existing accounts of the naturalist tradition between 1890 and 1940 that have defended the relative contribution of naturalists to the modem evolutionary synthesis. These accounts, while useful, have primarily examined the natural history of the period in view of how it led to developments in the 193 Os and 40s, removing pre-Synthesis naturalists like Jordan from their research programs, institutional contexts, and disciplinary homes, for the sake of synthesis narratives. This dissertation redresses this picture by examining a naturalist, who, although often cited as important in the synthesis, is more accurately viewed as a man working on the problems of an earlier period. This study examines the specific problems that concerned Jordan, as well as the dynamic institutional, international, theoretical and methodological context of entomology and natural history during his lifetime. It focuses upon how the context in which natural history has been done changed greatly during Jordan's life time, and discusses the role of these changes in both placing naturalists on the defensive among an array of new disciplines and attitudes in science, and providing them with new tools and justifications for doing natural history. One of the primary intents of this study is to demonstrate the many different motives and conditions through which naturalists came to and worked in natural history. -
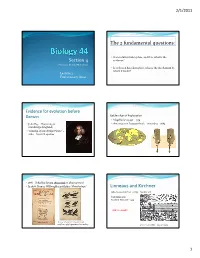
The 2 Fundamental Questions: Linneaus and Kirchner
2/1/2011 The 2 fundamental questions: y Has evolution taken pp,lace, and if so, what is the Section 4 evidence? Professor Donald McFarlane y If evolution has taken place, what is the mechanism by which it works? Lecture 2 Evolutionary Ideas Evidence for evolution before Darwin Golden Age of Exploration y Magellan’s voyage –1519 y John Ray –University of y Antonius von Leeuwenhoek ‐ microbes –1683 Cambridge (England) y “Catalog of Cambridge Plants” – 1660 –lists 626 species y 1686 –John Ray listing thousands of plant species! y In 1678, Francis Willoughby publishes “Ornithology” Linneaus and Kirchner Athenasius Kircher ~ 1675 –Noah’s ark Carl Linneaus – Sistema Naturae ‐ 1735 Ark too small!! Uses a ‘phenetic” classification – implies a phylogenetic relationship! 300 x 50 x 30 cubits ~ 135 x 20 x 13 m 1 2/1/2011 y Georges Cuvier 1769‐ 1832 y “Fixity of Species” Evidence for Evolution –prior to 1830 • Enormous diversity of life –WHY ??? JBS Haldane " The Creator, if He exists, has "an inordinate fondness for beetles" ". Evidence for Evolution –prior to 1830 Evidence for Evolution –prior to 1830 y The discovery of variation. y Comparative Anatomy. Pentadactyl limbs Evidence for Evolution –prior to Evidence for Evolution –prior to 1830 1830 y Fossils – homologies with living species y Vestigal structures Pentadactyl limbs !! 2 2/1/2011 Evidence for Evolution –prior to 1830 Evidence for Evolution –prior to 1830 y Invariance of the fossil sequence y Plant and animal breeding JBS Haldane: “I will give up my belief in evolution if someone finds a fossil rabbit in the Precambrian.” Charles Darwin Jean Baptiste Lamark y 1744‐1829 y 1809 –1882 y Organisms have the ability to adapt to their y Voyage of Beagle 1831 ‐ 1836 environments over the course of their lives. -

VU Research Portal
VU Research Portal Science and Scientism in Popular Science Writing de Ridder, G.J. published in Social Epistemology Review and Reply Collective 2014 document version Publisher's PDF, also known as Version of record Link to publication in VU Research Portal citation for published version (APA) de Ridder, G. J. (2014). Science and Scientism in Popular Science Writing. Social Epistemology Review and Reply Collective, 3(12), 23-39. http://wp.me/p1Bfg0-1KE General rights Copyright and moral rights for the publications made accessible in the public portal are retained by the authors and/or other copyright owners and it is a condition of accessing publications that users recognise and abide by the legal requirements associated with these rights. • Users may download and print one copy of any publication from the public portal for the purpose of private study or research. • You may not further distribute the material or use it for any profit-making activity or commercial gain • You may freely distribute the URL identifying the publication in the public portal ? Take down policy If you believe that this document breaches copyright please contact us providing details, and we will remove access to the work immediately and investigate your claim. E-mail address: [email protected] Download date: 02. Oct. 2021 Social Epistemology Review and Reply Collective, 2014 Vol. 3, No. 12, 23-39. http://wp.me/p1Bfg0-1KE Science and Scientism in Popular Science Writing Jeroen de Ridder, VU University Amsterdam Abstract If one is to believe recent popular scientific accounts of developments in physics, biology, neuroscience, and cognitive science, most of the perennial philosophical questions have been wrested from the hands of philosophers by now, only to be resolved (or sometimes dissolved) by contemporary science. -

Intentional Systems in Cognitive Ethology: the "Panglossian Paradigm" Defended
THE BEHAVIORAL AND BRAIN SCIENCES (1983) 6, 343-390 Printed in the United States of America Intentional systems in cognitive ethology: The "Panglossian paradigm" defended Daniel C. Dennett Department of Philosophy, Tufts University, Medford, Mass. 02155 Abstract: Ethologists and others studying animal behavior in a "cognitive" spirit are in need of a descriptive language and method that are neither anachronistically bound by behaviorist scruples nor prematurely committed to particular "information-processing models. "Just such an interim descriptive method can be found in intentional system theory. The use of intentional system theory is illustrated with the case of the apparently communicative behavior of vervet monkeys. A way of using the theory to generate data - including usable, testable "anecdotal" data - is sketched. The underlying assumptions of this approach can be seen to ally it directly with "adaptationist' theorizing in evolutionary biology, which has recently come under attack from Stephen Gould and Richard Lewontin, who castigate it as the "Panglossian paradigm." Their arguments, which are strongly analogous to B. F. Skinner's arguments against "mentalism," point to certain pitfalls that attend the careless exercise of such "Panglossian" thinking (and rival varieties of thinking as well), but do not constitute a fundamental objection to either adaptationist theorizing or its cousin, intentional system theory. Keywords: adaptation; animal cognition; behaviorism; cognitive ethology; communication; comparative psychology; consciousness; -

The Philosophy of Biology Edited by David L
Cambridge University Press 978-0-521-85128-2 - The Cambridge Companion to the Philosophy of Biology Edited by David L. Hull and Michael Ruse Frontmatter More information the cambridge companion to THE PHILOSOPHY OF BIOLOGY The philosophy of biology is one of the most exciting new areas in the field of philosophy and one that is attracting much attention from working scientists. This Companion, edited by two of the founders of the field, includes newly commissioned essays by senior scholars and by up-and- coming younger scholars who collectively examine the main areas of the subject – the nature of evolutionary theory, classification, teleology and function, ecology, and the prob- lematic relationship between biology and religion, among other topics. Up-to-date and comprehensive in its coverage, this unique volume will be of interest not only to professional philosophers but also to students in the humanities and researchers in the life sciences and related areas of inquiry. David L. Hull is an emeritus professor of philosophy at Northwestern University. The author of numerous books and articles on topics in systematics, evolutionary theory, philosophy of biology, and naturalized epistemology, he is a recipient of a Guggenheim Foundation fellowship and is a Fellow of the American Academy of Arts and Sciences. Michael Ruse is professor of philosophy at Florida State University. He is the author of many books on evolutionary biology, including Can a Darwinian Be a Christian? and Darwinism and Its Discontents, both published by Cam- bridge University Press. A Fellow of the Royal Society of Canada and the American Association for the Advancement of Science, he has appeared on television and radio, and he contributes regularly to popular media such as the New York Times, the Washington Post, and Playboy magazine. -

Information Theory, Evolution, and the Origin of Life
Information theory, evolution, and the origin of life HUBERT P. YOCKEY CAMBRIDGE UNIVERSITY PRESS CA\15RIDG£ \J);IVE;<SITY PRESS Cambridge, New York, Melbourne, Madrid, Cape Town, Singapore, Sao Paulo, Delhi, Dubai, Tokyo, Mexico City Cambridge University Press 32 Avenue of the Americas, New York, NY 10013-2473• USA wv1rw.cambridge.org Information on this tide: www.cambridge.org/978opu69585 © Hubert P. Yockey 2005 This publication is in copyright. Subject to statutory exception and to the provisions of relevant collective licensing agreements, no reproduction of any part may take place without the written permission of Cambridge University Press. First published 2005 Reprinred 2006 First paperback edition 2010 A catalog record for this publication is available from the British Library Library of Congress Cataloging in Publication data Yockey, Hubert P. Information theory, evolution, and the origin of life I Huberr P. Yockey. p. em. Includes bibliographical references (p. ) . ISS� 0·521·80293-8 (hardback: alk. paper) r. Molecular biology. 2. Information theory in biology. 3· Evolution (Biology) 4· Life-Origin. r. Title. QHso6.Y634 2004 572.8 dc22 2004054518 ISBN 978-0·)21-80293-2 Hardback ISBN 978-0-52H6958-5 Paperback Cambridge University Press has no responsibility for rhe persistence or accuracy of URLs for external or third-party internet websites referred to in this publication, and does not guarantee that any content on such websites is, or will remain, accurate or appropriate. Information theory, evolution, and the origin of life Information TheOI)\ Evolution, and the Origin of Life presents a timely introduction to the use of information theory and coding theory in molecular biology. -

Tempo and Mode in Evolution WALTER M
Proc. Nati. Acad. Sci. USA Vol. 91, pp. 6717-6720, July 1994 Colloquium Paper This paper was presented at a colloquium entiled "Tempo and Mode in Evoluton" organized by Walter M. Fitch and Francisco J. Ayala, held Januwy 27-29, 1994, by the National Academy of Sciences, in Irvine, CA. Tempo and mode in evolution WALTER M. FITCH AND FRANCISCO J. AYALA Department of Ecology and Evolutionary Biology, University of California, Irvine, CA 92717 George Gaylord Simpson said in his classic Tempo andMode The conflict between Mendelians and biometricians was in Evolution (1) that paleontologists enjoy special advantages resolved between 1918 and 1931 by the work ofR. A. Fisher over geneticists on two evolutionary topics. One general and J. B. S. Haldane in England, Sewall Wright in the United topic, suggested by the word "tempo," has to do with States, and S. S. Chetverikov in Russia. Independently of "evolutionary rates. ., their acceleration and deceleration, each other, these authors proposed theoretical models of the conditions ofexceptionally slow or rapid evolutions, and evolutionary processes which integrate Mendelian inheri- phenomena suggestive of inertia and momentum." A group tance, natural selection, and biometrical knowledge. of related problems, implied by the word "mode," involves The work of these authors, however, had a limited impact "the study of the way, manner, or pattern of evolution, a on the biology of the time, because it was formulated in study in which tempo is a basic factor, but which embraces difficult mathematical language and because it was largely considerably more than tempo" (pp. xvii-xviii). theoretical with little empirical support. -

Philosophy of the Social Sciences Blackwell Philosophy Guides Series Editor: Steven M
The Blackwell Guide to the Philosophy of the Social Sciences Blackwell Philosophy Guides Series Editor: Steven M. Cahn, City University of New York Graduate School Written by an international assembly of distinguished philosophers, the Blackwell Philosophy Guides create a groundbreaking student resource – a complete critical survey of the central themes and issues of philosophy today. Focusing and advancing key arguments throughout, each essay incorporates essential background material serving to clarify the history and logic of the relevant topic. Accordingly, these volumes will be a valuable resource for a broad range of students and readers, including professional philosophers. 1 The Blackwell Guide to Epistemology Edited by John Greco and Ernest Sosa 2 The Blackwell Guide to Ethical Theory Edited by Hugh LaFollette 3 The Blackwell Guide to the Modern Philosophers Edited by Steven M. Emmanuel 4 The Blackwell Guide to Philosophical Logic Edited by Lou Goble 5 The Blackwell Guide to Social and Political Philosophy Edited by Robert L. Simon 6 The Blackwell Guide to Business Ethics Edited by Norman E. Bowie 7 The Blackwell Guide to the Philosophy of Science Edited by Peter Machamer and Michael Silberstein 8 The Blackwell Guide to Metaphysics Edited by Richard M. Gale 9 The Blackwell Guide to the Philosophy of Education Edited by Nigel Blake, Paul Smeyers, Richard Smith, and Paul Standish 10 The Blackwell Guide to Philosophy of Mind Edited by Stephen P. Stich and Ted A. Warfield 11 The Blackwell Guide to the Philosophy of the Social Sciences Edited by Stephen P. Turner and Paul A. Roth 12 The Blackwell Guide to Continental Philosophy Edited by Robert C. -

The Beginnings of Vertebrate Paleontology in North America Author(S): George Gaylord Simpson Source: Proceedings of the American Philosophical Society, Vol
The Beginnings of Vertebrate Paleontology in North America Author(s): George Gaylord Simpson Source: Proceedings of the American Philosophical Society, Vol. 86, No. 1, Symposium on the Early History of Science and Learning in America (Sep. 25, 1942), pp. 130-188 Published by: American Philosophical Society Stable URL: http://www.jstor.org/stable/985085 . Accessed: 29/09/2013 21:55 Your use of the JSTOR archive indicates your acceptance of the Terms & Conditions of Use, available at . http://www.jstor.org/page/info/about/policies/terms.jsp . JSTOR is a not-for-profit service that helps scholars, researchers, and students discover, use, and build upon a wide range of content in a trusted digital archive. We use information technology and tools to increase productivity and facilitate new forms of scholarship. For more information about JSTOR, please contact [email protected]. American Philosophical Society is collaborating with JSTOR to digitize, preserve and extend access to Proceedings of the American Philosophical Society. http://www.jstor.org This content downloaded from 150.135.114.183 on Sun, 29 Sep 2013 21:55:20 PM All use subject to JSTOR Terms and Conditions THE BEGINNINGS OF VERTEBRATE PALEONTOLOGY IN NORTH AMERICA GEORGE GAYLORD SIMPSON Associate Curator of Vertebrate Paleontology, American Museum of Natural History (Read February14, 1942, in Symposiumon theEarly Historyof Science and Learning in America) CONTENTS siderablevariety of vertebratefossils had been foundin before1846, the accepteddate of that dis- 132 the far West First Glimpses.... ......................... covery. Amongthem were findsby Lewis and Clark in Longueuil,1739, to Croghan,1766 ......... ........ 135 1804-1806,a good mosasaurskeleton from South Dakota, Identifyingthe Vast Mahmot.................... -

To Be a Reductionist in a Complex Universe
How (not) to be a reductionist in a complex universe Karola Stotz Department of Philosophy, University of Sydney, A14, Sydney NSW 2006, Australia. Email: [email protected] Word count: 3000 1. Introduction In the last 10 years the reductionism debate has shifted to the idea of reduction as a relation not between theories, but between explanations. A reductionist explains a system’s phenomenon by the properties and interactions of its components. Through this move Sahotra Sarkar attempted to shift attention from a discussion of the logical form of scientific theories to questions regarding the interpretation of scientific explanations (Sarkar 1998). During this time there has been a spate of publications on what has variously been termed 'causal', 'proximal', or 'experimental' biology, including Sahotra Sarkar’s Molecular Models of Life, Marcel Weber’s Philosophy of Experimental Biology, William Bechtel’s Discovering Cell Mechanisms and Alexander Rosenberg’s Darwinian Reductionism (Sarkar 2005; Weber 2005; Bechtel 2006; Rosenberg 2006). Among the emergent themes in the recent literature on proximal biology are: 1. Does proximal biology discover 'mechanisms' rather than laws or theories? 2. What is the relationship between physicalism and antireductionism? 3. How does proximal biology deal with levels of organization, complexity and non-trivial emergence? In the light of these and other themes this paper discusses to what extent should we expect biological phenomena to be reduced to the molecular level. While most philosophers of biology, and arguably biologists as well, subscribe to some kind of physicalism they also belief that biological phenomena in principle cannot be reduced to physical ones. -

The American Museum of Natural History
THE AMERICAN MUSEUM OF NATURAL HISTORY EIGHTY-FIFTH ANNUAL REPORT JULY, 1953, THROUGH JUNE, 1954 THE AMERICAN MUSEUM OF NATURAL HISTORY EIGHTY-FIFTH ANNUAL REPORT JULY, 1953, THROUGH JUNE, 1954 THE CITY OF NEW YORK 1954 EIGHTY-FIFTH ANNUAL REPORT OF THE PRESIDENT To the Trustees of The American Museum of Natural History and to the Municipal Authorities of the City of New York THE Museum's fiscal year, which ended June 30, 1954, was a good one. As in our previous annual report, I believe we can fairly state that continuing progress is being made on our long-range plan for the Museum. The cooperative attitude of the scientific staff and of our other employees towards the program set forth by management has been largely responsible for what has been accomplished. The record of both the Endowment and Pension Funds during the past twelve months has been notably satisfactory. In a year of wide swings of optimism and pessimism in the security markets, the Finance Committee is pleased to report an increase in the market value of the Endowment Fund of $3,011,800 (87 per cent of which has been due to the over-all rise in prices and 13 per cent to new gifts). Common stocks held by the fund increased in value approximately 30 per cent in the year. The Pension Fund likewise continued to grow, reaching a valuation of $4,498,600, as compared to $4,024,100 at the end of the previous year. Yield at cost for the Endow- ment Fund as of July 1 stood at 4.97 per cent and for the Pension Fund at 3.74 per cent.