TECHNIQUES for TRANSPARENT PROGRAM SPECIALIZATION in DYNAMIC OPTIMIZERS by S.Subramanya Sastry a Dissertation Submitted in Parti
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Scheme Foreign Function Interface to Javascript Based on an Infix
A Scheme Foreign Function Interface to JavaScript Based on an Infix Extension Marc-André Bélanger Marc Feeley Université de Montréal Université de Montréal Montréal, Québec, Canada Montréal, Québec, Canada [email protected] [email protected] ABSTRACT FFIs are notoriously implementation-dependent and code This paper presents a JavaScript Foreign Function Inter- using a given FFI is usually not portable. Consequently, face for a Scheme implementation hosted on JavaScript and the nature of FFI’s reflects a particular set of choices made supporting threads. In order to be as convenient as possible by the language’s implementers. This makes FFIs usually the foreign code is expressed using infix syntax, the type more difficult to learn than the base language, imposing conversions between Scheme and JavaScript are mostly im- implementation constraints to the programmer. In effect, plicit, and calls can both be done from Scheme to JavaScript proficiency in a particular FFI is often not a transferable and the other way around. Our approach takes advantage of skill. JavaScript’s dynamic nature and its support for asynchronous In general FFIs tightly couple the underlying low level functions. This allows concurrent activities to be expressed data representation to the higher level interface provided to in a direct style in Scheme using threads. The paper goes the programmer. This is especially true of FFIs for statically over the design and implementation of our approach in the typed languages such as C, where to construct the proper Gambit Scheme system. Examples are given to illustrate its interface code the FFI must know the type of all data passed use. -

This Article Appeared in a Journal Published by Elsevier. the Attached Copy Is Furnished to the Author for Internal Non-Commerci
This article appeared in a journal published by Elsevier. The attached copy is furnished to the author for internal non-commercial research and education use, including for instruction at the authors institution and sharing with colleagues. Other uses, including reproduction and distribution, or selling or licensing copies, or posting to personal, institutional or third party websites are prohibited. In most cases authors are permitted to post their version of the article (e.g. in Word or Tex form) to their personal website or institutional repository. Authors requiring further information regarding Elsevier’s archiving and manuscript policies are encouraged to visit: http://www.elsevier.com/copyright Author's personal copy Computer Languages, Systems & Structures 37 (2011) 132–150 Contents lists available at ScienceDirect Computer Languages, Systems & Structures journal homepage: www.elsevier.com/locate/cl Reconciling method overloading and dynamically typed scripting languages Alexandre Bergel à Pleiad Group, Computer Science Department (DCC), University of Chile, Santiago, Chile article info abstract Article history: The Java virtual machine (JVM) has been adopted as the executing platform by a large Received 13 July 2010 number of dynamically typed programming languages. For example, Scheme, Ruby, Received in revised form Javascript, Lisp, and Basic have been successfully implemented on the JVM and each is 28 February 2011 supported by a large community. Interoperability with Java is one important require- Accepted 15 March 2011 ment shared by all these languages. We claim that the lack of type annotation in interpreted dynamic languages makes Keywords: this interoperability either flawed or incomplete in the presence of method overloading. Multi-language system We studied 17 popular dynamically typed languages for JVM and .Net, none of them Interoperability were able to properly handle the complexity of method overloading. -

The Gozer Workflow System
UNIVERSITY OF OKLAHOMA GRADUATE COLLEGE THE GOZER WORKFLOW SYSTEM A THESIS SUBMITTED TO THE GRADUATE FACULTY in partial fulfillment of the requirements for the Degree of MASTER OF SCIENCE By JASON MADDEN Norman, Oklahoma 2010 THE GOZER WORKFLOW SYSTEM A THESIS APPROVED FOR THE SCHOOL OF COMPUTER SCIENCE BY Dr. John Antonio, Chair Dr. Amy McGovern Dr. Rex Page © Copyright by JASON MADDEN 2010 All rights reserved. Acknowledgements I wish to thank my friends and colleagues at RiskMetrics Group, including Nicolas Grounds, Matthew Martin, Jay Sachs, and Joshua Zuech, for their valuable additions to the Gozer Workflow System. It wouldn’t be this complete without them. Thanks also go to the programmers, testers, deployers and operators of Gozer workflows for their patience in dealing with an evolving system, and their feedback and suggestions for improvements. Special thanks go to my manager at RiskMetrics, Jeff Muehring. Without his initial support (following a discussion consuming most of the duration of a late-night flight to New York) and ongoing encouragement, the development and deployment of Gozer could never have happened. Finally, I wish to express my appreciation for my thesis advisor, Dr. John Antonio, for keeping me an the right track and guiding me through the graduate process, and for my committee members, Dr. McGovern and Dr. Page, for their support and for serving on the committee. iv Contents 1 Introduction and Background1 1.1 Before Gozer...............................2 1.2 From XML to Lisp............................4 1.3 Gozer Design Philosophy.........................5 1.4 Gozer Development............................6 1.5 Related Work...............................7 2 The Gozer Language 10 2.1 Syntax.................................. -

Incorporating Scheme-Based Web Programming in Computer Literacy Courses
Incorporating Scheme-based Web Programming in Computer Literacy Courses Timothy J. Hickey ∗ Department of Computer Science Brandeis University Waltham, MA 02254, USA Abstract erful) subset of Jscheme[2] – a Java-based dialect of Scheme. The tight integration of Java with Jscheme allows it to be easily embedded in Java programs and We describe an approach to introducing non-science ma- hence makes it easy for students to implement servlets, jors to computers and computation in part by teach- applets, and other web-deliverable applications. Jscheme ing them to write applets, servlets, and groupware ap- is an implementation of Scheme in Java (meeting almost plications using a dialect of Scheme implemented in all of the requirements of the R4RS [4] Scheme stan- Java. The declarative nature of our approach allows dard). It also includes two simple syntactic extensions: non-science majors with no programming background to develop surprisingly complex web applications in about half a semester. This level of programming provides a • javadot notation: this provides full access to context for a deeper understanding of computation than Java classes, methods, and fields is usually feasible in a Computer Literacy course. • quasi-string notation: this simplifies the pro- cess of generating HTML. 1 Introduction The javadot notation provides a transparent access to Java and the quasi-string notation provides a gentle path from HTML to Scheme for novices. It also pro- There are two general approaches to teaching a Com- vides a convenient syntax for generating complex strings puter Literacy (CS0) class. The most common approach of other sorts (such as SQL queries). -
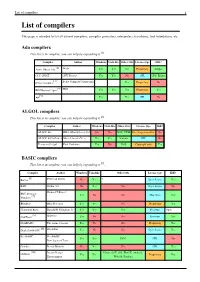
List of Compilers 1 List of Compilers
List of compilers 1 List of compilers This page is intended to list all current compilers, compiler generators, interpreters, translators, tool foundations, etc. Ada compilers This list is incomplete; you can help by expanding it [1]. Compiler Author Windows Unix-like Other OSs License type IDE? [2] Aonix Object Ada Atego Yes Yes Yes Proprietary Eclipse GCC GNAT GNU Project Yes Yes No GPL GPS, Eclipse [3] Irvine Compiler Irvine Compiler Corporation Yes Proprietary No [4] IBM Rational Apex IBM Yes Yes Yes Proprietary Yes [5] A# Yes Yes GPL No ALGOL compilers This list is incomplete; you can help by expanding it [1]. Compiler Author Windows Unix-like Other OSs License type IDE? ALGOL 60 RHA (Minisystems) Ltd No No DOS, CP/M Free for personal use No ALGOL 68G (Genie) Marcel van der Veer Yes Yes Various GPL No Persistent S-algol Paul Cockshott Yes No DOS Copyright only Yes BASIC compilers This list is incomplete; you can help by expanding it [1]. Compiler Author Windows Unix-like Other OSs License type IDE? [6] BaCon Peter van Eerten No Yes ? Open Source Yes BAIL Studio 403 No Yes No Open Source No BBC Basic for Richard T Russel [7] Yes No No Shareware Yes Windows BlitzMax Blitz Research Yes Yes No Proprietary Yes Chipmunk Basic Ronald H. Nicholson, Jr. Yes Yes Yes Freeware Open [8] CoolBasic Spywave Yes No No Freeware Yes DarkBASIC The Game Creators Yes No No Proprietary Yes [9] DoyleSoft BASIC DoyleSoft Yes No No Open Source Yes FreeBASIC FreeBASIC Yes Yes DOS GPL No Development Team Gambas Benoît Minisini No Yes No GPL Yes [10] Dream Design Linux, OSX, iOS, WinCE, Android, GLBasic Yes Yes Proprietary Yes Entertainment WebOS, Pandora List of compilers 2 [11] Just BASIC Shoptalk Systems Yes No No Freeware Yes [12] KBasic KBasic Software Yes Yes No Open source Yes Liberty BASIC Shoptalk Systems Yes No No Proprietary Yes [13] [14] Creative Maximite MMBasic Geoff Graham Yes No Maximite,PIC32 Commons EDIT [15] NBasic SylvaWare Yes No No Freeware No PowerBASIC PowerBASIC, Inc. -

GEOFFREY S. KNAUTH Williamsport, PA — [email protected] Summary
GEOFFREY S. KNAUTH Williamsport, PA | [email protected] Summary: 39 years building applications and systems of every stripe. Over 19 years building web-based systems. Four years college teaching experience. My primary motivation is doing things that matter. Skills: Scala, Java, Python, C/C++, Racket, Lisp, Perl, Ruby, JavaScript, Objective-C, Smalltalk, TEX. Oracle, PostgreSQL, MySQL, XML/JSON, web programming. GNU/Linux, Mac OS X, BSD, Solaris, Windows. Learning: OCaml, Haskell, Clojure, F#, Erlang, JavaScript Plugins, Android/iPhone SDKs, C#, ASP.NET, Squeak, Dart, Go, Rust. PROFESSIONAL EXPERIENCE AccuWeather, State College, PA 03/14{current Senior Software Developer • Collect and process large volumes of real-time worldwide weather data, integrating new sources weekly. Contracting • Calltrunk, London, UK. 03/13{07/13. Django support & Python scripting. • Discovery Machine, Inc., Williamsport, PA. 01/12{05/12. AI R&D in natural language understanding. • Various startups. Android & iOS. 10/10{12/11. Games, social media, search & rescue. Ringleader Digital, New York, NY 06/10{10/10 Senior Software Engineer • Implemented back-end C# parallel scalability performance optimizations working with SQLServer. Coded jQuery front-end enhancements. Mobile advertising platform. Lycoming College, Williamsport, PA 08/06{05/10 Computer Science Instructor • Taught: Introduction to Computer Science, Principles of Advanced Programming, Programming Language Design, Database Systems, Computer Networks, Introduction to Web-based Programming, Web-based Programming, Computer Organization / Machine Language, Introduction to Robotics. Interactive Supercomputing, Waltham, MA 05/06{08/06 Contractor • Optimized GNU Octave performance for parallel supercomputing. SFA, Inc., Virginia Beach, VA 1/04{2/06 Senior Software Engineer • Helped SFA understand legacy military logistics application code I'd written or known, and associated business rules, to help SFA reshape the project using only Java and Oracle. -

SISC: a Complete Scheme Interpreter in Java
SISC: A Complete Scheme Interpreter in Java Scott G. Miller <[email protected]> 20th February 2003 Abstract We will examine the design of SISC, a fully R5RS compliant heap-based inter- preter of the functional language Scheme, with proper tail-recursion and first-class continuations. All noteworthy components of the interpreter will be described, and as well as discussion of some implementation details related to interpretation optimizations and efficient use of the Object-Oriented host language Java. Contents 1 Introduction 2 2 Rationale 3 2.1 Proper tail recursion . 3 2.2 Continuations . 3 3 The Interpreter 4 3.1 Expression compilation . 4 3.2 Environments . 5 3.2.1 Associative Environments . 5 3.2.2 Lexical Environments . 5 3.3 Evaluation . 6 3.3.1 Execution . 7 3.3.2 Expressions . 7 3.4 Procedures . 10 3.4.1 Built-in procedures . 10 3.4.2 Closures . 10 3.4.3 Continuations . 11 3.5 Proper tail recursion . 11 3.6 Continuations . 11 3.7 Error handling . 12 3.7.1 The User’s view . 12 3.7.2 The Implementation . 13 1 4 Datatypes 13 4.1 Symbols . 14 4.2 Numbers . 14 4.3 Multiple values . 14 5 Java: Pros and Cons 15 5.1 Object-Oriented benefits . 15 6 Optimizations 16 6.1 Call-frame recycling . 16 6.2 Expression recycling . 17 6.3 Immediate fast-tracking . 17 7 Extensibility 18 8 Performance comparison 18 9 Conclusion 18 1 Introduction SISC1 is a Java based interpreter of the Scheme. It differs from most Java Scheme interpreters in that it attempts to sacrifice some simplicity in the evaluation model in order to provide a complete interpretation of Scheme. -

Wescheme: the Browser Is Your Programming Environment
WeScheme: The Browser is Your Programming Environment Danny Yoo Emmanuel Schanzer Shriram Krishnamurthi WPI Harvard University Brown University [email protected] [email protected] [email protected] Kathi Fisler WPI kfi[email protected] ABSTRACT • By using Web technologies like the Document Object We present a programming environment called WeScheme Model (DOM) and Cascading Style Sheets (CSS), it that runs in the Web browser and supports interactive de- can reuse the engineering effort of several companies velopment. WeScheme programmers can save programs di- who are competing to add features and performance. rectly on the Web, making them accessible from everywhere. • Giving the students access to the Web’s display tech- As a result, sharing of programs is a central focus that nology offers them an incremental path from Web au- WeScheme supports seamlessly. The environment also lever- thoring to programming, i.e., from statics to dynamics. ages the existing presentation media and program run-time support found in Web browsers, thus making these easily • It can allow for the development of mashups, programs accessible to students and leveraging their rapid engineering composed of several Web applications working together. improvements. WeScheme is being used successfully by stu- It offers the promise of deep interoperability with con- dents, and is especially valuable in schools that have prohi- tent and programs on the Web, like Flickr and Google bitions on installing new software or lack the computational Maps, and makes for interesting and novel program- demands of more intensive programming environments. ming exercises. • It suggests storing programs in the Cloud, which en- Categories and Subject Descriptors ables easy global sharing. -

Comparing Selected Criteria of Programming Languages Java, PHP, C++, Perl, Haskell, Aspectj, Ruby, COBOL, Bash Scripts and Scheme Revision 1.0 Sultan S
Comparing Selected Criteria of Programming Languages Java, PHP, C++, Perl, Haskell, AspectJ, Ruby, COBOL, Bash Scripts and Scheme Revision 1.0 Sultan S. Al-Qahtani Luis F. Guzman Concordia University Concordia University Montreal, Quebec, Canada Montreal, Quebec, Canada [email protected] [email protected] Rafik Arif Adrien Tevoedjre Concordia University Concordia University Montreal, Quebec, Canada Montreal, Quebec, Canada [email protected] [email protected] Pawel Pietrzynski Concordia University Montreal, Quebec, Canada [email protected] Abstract Comparison of programming languages is a common topic of discussion among software engineers. Few languages ever become sufficiently popular that they are used by more than a few people or find their niche in research or education; but professional programmers can easily use dozens of different languages during their career. Multiple programming languages are designed, specified, and implemented every year in order to keep up with the changing programming paradigms, hardware evolution, etc. In this paper we present a comparative study between ten programming languages: Haskell, Java, Perl, C++, AspectJ, COBOL, Ruby, PHP, Bash Scripts, and Scheme; with respect of the following criteria: Secure programming practices, web applications development, web services design and composition, object oriented-based abstraction, reflection, aspect-orientation, functional programming, declarative programming, batch scripting, and user interface prototype design. 1. Introduction The first high-level programming languages were designed during the 1950s. Ever since then, programming languages have been a fascinating and productive area of study [43]. Thousands of different programming languages have been created, mainly in the computer field, with many more being created every year; they are designed, specified, and implemented for the purpose of being up to date with the evolving programming paradigms (e.g. -

Proceedings of the 14Th European Lisp Symposium Online, Everywhere May 3 – 4, 2021 Marco Heisig (Ed.)
Proceedings of the 14th European Lisp Symposium Online, Everywhere May 3 – 4, 2021 Marco Heisig (ed.) ISBN-13: 978-2-9557474-3-8 ISSN: 2677-3465 ii ELS 2021 Preface Message from the Program Chair Welcome to the 14thth European Lisp Symposium! I hope you are as excited for this symposium as I am. For most of you, these are the first minutes of the symposium. But the reason why we have this symposium, the website, the Twitch setup, and all the exciting talks and papers, is because of dozens of other people working hard behind the scenes for months. And I want to use this opening statement to thank these people. The most important person when it comes to ELS is Didier Verna. Year after year, Didier takes care that other people are taking care of ELS. Thank you Didier! Then there is the programme committee — brilliant and supportive people that spend count- less hours reviewing each submission. These people help turn good papers into great papers, and these people are the reason why our conference proceedings are such an interesting read. Thanks everyone on the programme committee! And then there are the local chairs — Georgiy, Mark, and Michał — that spent a large part of the last week refining our technical setup. Without our local chairs, we just couldn’t have this online ELS. Thank you Georgiy, Mark, and Michał! And finally, we have the true stars of the symposium, our presenters. These people spent weeks working on their papers, preparing slides, and recording their talks. And they will also be here live during each talk to answer questions or to discuss ideas. -

Scheme Implementation Techniques
Scheme Implementation Techniques [email protected] Scheme Scheme The language: - A dialect of Lisp - Till R5RS designed by consensus - Wide field of experimentation - Standards intentionally give leeway to implementors Scheme Implemented in everything, embedded everywhere: - Implementations in assembler, C, JavaScript, Java - Runs on Desktops, mobiles, mainframes, microcontrollers, FPGAs - Embedded in games, desktop apps, live-programming tools, audio software, spambots - Used as shell-replacement, kernel module Scheme Advantages: - Small, simple, elegant, general, minimalistic - toolset for implementing every known (and unknown) programming paradigm - provides the basic tools and syntactic abstractions to shape them to your needs - code is data - data is code Scheme Major implementations (totally subjective): - Chez (commercial, very good) - Bigloo (very fast, but restricted) - Racket (comprehensive, educational) - MIT Scheme (old) - Gambit (fast) - Guile (mature, emphasis on embedding) - Gauche (designed to be practical) - CHICKEN (¼) Scheme Other implementations: MIT Scheme LispMe Bee Llava Chibi Kawa Armpit Scheme Luna Tinyscheme Sisc Elk PS3I Miniscm JScheme Heist Scheme->C S9fes SCSH HScheme QScheme Schemix Scheme48 Ikarus Psyche PICOBIT Moshimoshi IronScheme RScheme SHard Stalin Inlab Scheme Rhizome/Pi Dreme EdScheme Jaja SCM Mosh-scheme UMB Scheme Pocket Scheme XLISP Wraith Scheme Ypsilon Scheme Vx-Scheme S7 Sizzle SigScheme SIOD Saggitarius Larceny librep KSI KSM Husk Scheme CPSCM Bus-Scheme BDC Scheme BiT BiwaScheme -

Ola Bini Computational Metalinguist [email protected]
Java as a Platform Ola Bini computational metalinguist [email protected] http://olabini.com/blog torsdag den 12 maj 2011 Your host From Sweden to Chicago through ThoughtWorks Language geek at ThoughtWorks JRuby core developer, Ioke and Seph creator Member of the JSR 292 EG torsdag den 12 maj 2011 Platform torsdag den 12 maj 2011 What you get torsdag den 12 maj 2011 torsdag den 12 maj 2011 torsdag den 12 maj 2011 Code loading torsdag den 12 maj 2011 Platform independence torsdag den 12 maj 2011 torsdag den 12 maj 2011 JIT torsdag den 12 maj 2011 torsdag den 12 maj 2011 Languages torsdag den 12 maj 2011 Aardappel Gosu JudoScript Scala ABCL Groovy Jython SISC AJLogo Hecl Kawa Sixx Anvil Hojo Lili Skij BDC Scheme HotScheme Lisp Sleep BeanShell HotTEA LL SmallWorld Bex Script Ioke Mapyrus StarLogo Bigloo iScript MetaJ Talks2 Bistro Jacl Mini TermWare CAL Jaja NetLogo Thorn Ceylon Janino Nice tuProlog CKI Prolog Jatha Obol Turtle Tracks Clojure javalog PERCobol uts COCOA JBasic PLAN v-language CONVERT Jickle Pnuts W4F Correlate JLog PS3i webLISP Demeter/Java JMatch Quercus WLShell dSelf Join Java Resin XProlog Fan JoyJ Rhino Yassl FScript JRuby rLogo Ync/Javascript Funnel JScheme Sather Yo i x torsdag den 12 maj 2011 Paradigms torsdag den 12 maj 2011 Object Oriented torsdag den 12 maj 2011 Statically typed torsdag den 12 maj 2011 Dynamically typed torsdag den 12 maj 2011 Concatenative torsdag den 12 maj 2011 And many more... torsdag den 12 maj 2011 What’s missing? torsdag den 12 maj 2011 torsdag den 12 maj 2011 Light code loading torsdag den