Rāga Recognition Based on Pitch Distribution Methods
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Music Academy, Madras 115-E, Mowbray’S Road
Tyagaraja Bi-Centenary Volume THE JOURNAL OF THE MUSIC ACADEMY MADRAS A QUARTERLY DEVOTED TO THE ADVANCEMENT OF THE SCIENCE AND ART OF MUSIC Vol. XXXIX 1968 Parts MV srri erarfa i “ I dwell not in Vaikuntha, nor in the hearts of Yogins, nor in the Sun; (but) where my Bhaktas sing, there be I, Narada l ” EDITBD BY V. RAGHAVAN, M.A., p h .d . 1968 THE MUSIC ACADEMY, MADRAS 115-E, MOWBRAY’S ROAD. MADRAS-14 Annual Subscription—Inland Rs. 4. Foreign 8 sh. iI i & ADVERTISEMENT CHARGES ►j COVER PAGES: Full Page Half Page Back (outside) Rs. 25 Rs. 13 Front (inside) 20 11 Back (Do.) „ 30 „ 16 INSIDE PAGES: 1st page (after cover) „ 18 „ io Other pages (each) „ 15 „ 9 Preference will be given to advertisers of musical instruments and books and other artistic wares. Special positions and special rates on application. e iX NOTICE All correspondence should be addressed to Dr. V. Raghavan, Editor, Journal Of the Music Academy, Madras-14. « Articles on subjects of music and dance are accepted for mblication on the understanding that they are contributed solely o the Journal of the Music Academy. All manuscripts should be legibly written or preferably type written (double spaced—on one side of the paper only) and should >e signed by the writer (giving his address in full). The Editor of the Journal is not responsible for the views expressed by individual contributors. All books, advertisement moneys and cheques due to and intended for the Journal should be sent to Dr. V. Raghavan Editor. Pages. -

Towards Automatic Audio Segmentation of Indian Carnatic Music
Friedrich-Alexander-Universit¨at Erlangen-Nurnberg¨ Master Thesis Towards Automatic Audio Segmentation of Indian Carnatic Music submitted by Venkatesh Kulkarni submitted July 29, 2014 Supervisor / Advisor Dr. Balaji Thoshkahna Prof. Dr. Meinard Muller¨ Reviewers Prof. Dr. Meinard Muller¨ International Audio Laboratories Erlangen A Joint Institution of the Friedrich-Alexander-Universit¨at Erlangen-N¨urnberg (FAU) and Fraunhofer Institute for Integrated Circuits IIS ERKLARUNG¨ Erkl¨arung Hiermit versichere ich an Eides statt, dass ich die vorliegende Arbeit selbstst¨andig und ohne Benutzung anderer als der angegebenen Hilfsmittel angefertigt habe. Die aus anderen Quellen oder indirekt ubernommenen¨ Daten und Konzepte sind unter Angabe der Quelle gekennzeichnet. Die Arbeit wurde bisher weder im In- noch im Ausland in gleicher oder ¨ahnlicher Form in einem Verfahren zur Erlangung eines akademischen Grades vorgelegt. Erlangen, July 29, 2014 Venkatesh Kulkarni i Master Thesis, Venkatesh Kulkarni ACKNOWLEDGEMENTS Acknowledgements I would like to express my gratitude to my supervisor, Dr. Balaji Thoshkahna, whose expertise, understanding and patience added considerably to my learning experience. I appreciate his vast knowledge and skill in many areas (e.g., signal processing, Carnatic music, ethics and interaction with participants).He provided me with direction, technical support and became more of a friend, than a supervisor. A very special thanks goes out to my Prof. Dr. Meinard M¨uller,without whose motivation and encouragement, I would not have considered a graduate career in music signal analysis research. Prof. Dr. Meinard M¨ulleris the one professor/teacher who truly made a difference in my life. He was always there to give his valuable and inspiring ideas during my thesis which motivated me to think like a researcher. -

Syllabus for Post Graduate Programme in Music
1 Appendix to U.O.No.Acad/C1/13058/2020, dated 10.12.2020 KANNUR UNIVERSITY SYLLABUS FOR POST GRADUATE PROGRAMME IN MUSIC UNDER CHOICE BASED CREDIT SEMESTER SYSTEM FROM 2020 ADMISSION NAME OF THE DEPARTMENT: DEPARTMENT OF MUSIC NAME OF THE PROGRAMME: MA MUSIC DEPARTMENT OF MUSIC KANNUR UNIVERSITY SWAMI ANANDA THEERTHA CAMPUS EDAT PO, PAYYANUR PIN: 670327 2 SYLLABUS FOR POST GRADUATE PROGRAMME IN MUSIC UNDER CHOICE BASED CREDIT SEMESTER SYSTEM FROM 2020 ADMISSION NAME OF THE DEPARTMENT: DEPARTMENT OF MUSIC NAME OF THE PROGRAMME: M A (MUSIC) ABOUT THE DEPARTMENT. The Department of Music, Kannur University was established in 2002. Department offers MA Music programme and PhD. So far 17 batches of students have passed out from this Department. This Department is the only institution offering PG programme in Music in Malabar area of Kerala. The Department is functioning at Swami Ananda Theertha Campus, Kannur University, Edat, Payyanur. The Department has a well-equipped library with more than 1800 books and subscription to over 10 Journals on Music. We have gooddigital collection of recordings of well-known musicians. The Department also possesses variety of musical instruments such as Tambura, Veena, Violin, Mridangam, Key board, Harmonium etc. The Department is active in the research of various facets of music. So far 7 scholars have been awarded Ph D and two Ph D thesis are under evaluation. Department of Music conducts Seminars, Lecture programmes and Music concerts. Department of Music has conducted seminars and workshops in collaboration with Indira Gandhi National Centre for the Arts-New Delhi, All India Radio, Zonal Cultural Centre under the Ministry of Culture, Government of India, and Folklore Academy, Kannur. -

Fusion Without Confusion Raga Basics Indian
Fusion Without Confusion Raga Basics Indian Rhythm Basics Solkattu, also known as konnakol is the art of performing percussion syllables vocally. It comes from the Carnatic music tradition of South India and is mostly used in conjunction with instrumental music and dance instruction, although it has been widely adopted throughout the world as a modern composition and performance tool. Similarly, the music of North India has its own system of rhythm vocalization that is based on Bols, which are the vocalization of specific sounds that correspond to specific sounds that are made on the drums of North India, most notably the Tabla drums. Like in the south, the bols are used in musical training, as well as composition and performance. In addition, solkattu sounds are often referred to as bols, and the practice of reciting bols in the north is sometimes referred to as solkattu, so the distinction between the two practices is blurred a bit. The exercises and compositions we will discuss contain bols that are found in both North and South India, however they come from the tradition of the North Indian tabla drums. Furthermore, the theoretical aspect of the compositions is distinctly from the Hindustani, (north Indian) tradition. Hence, for the purpose of this presentation, the use of the term Solkattu refers to the broader, more general practice of Indian rhythmic language. South Indian Percussion Mridangam Dolak Kanjira Gattam North Indian Percussion Tabla Baya (a.k.a. Tabla) Pakhawaj Indian Rhythm Terms Tal (also tala, taal, or taala) – The Indian system of rhythm. Tal literally means "clap". -

Applying Natural Language Processing and Deep Learning Techniques for Raga Recognition in Indian Classical Music
Applying Natural Language Processing and Deep Learning Techniques for Raga Recognition in Indian Classical Music Deepthi Peri Dissertation submitted to the Faculty of the Virginia Polytechnic Institute and State University in partial fulfillment of the requirements for the degree of Master of Science in Computer Science and Applications Eli Tilevich, Chair Sang Won Lee Eric Lyon August 6th, 2020 Blacksburg, Virginia Keywords: Raga Recognition, ICM, MIR, Deep Learning Copyright 2020, Deepthi Peri Applying Natural Language Processing and Deep Learning Tech- niques for Raga Recognition in Indian Classical Music Deepthi Peri (ABSTRACT) In Indian Classical Music (ICM), the Raga is a musical piece’s melodic framework. It encom- passes the characteristics of a scale, a mode, and a tune, with none of them fully describing it, rendering the Raga a unique concept in ICM. The Raga provides musicians with a melodic fabric, within which all compositions and improvisations must take place. Identifying and categorizing the Raga is challenging due to its dynamism and complex structure as well as the polyphonic nature of ICM. Hence, Raga recognition—identify the constituent Raga in an audio file—has become an important problem in music informatics with several known prior approaches. Advancing the state of the art in Raga recognition paves the way to improving other Music Information Retrieval tasks in ICM, including transcribing notes automatically, recommending music, and organizing large databases. This thesis presents a novel melodic pattern-based approach to recognizing Ragas by representing this task as a document clas- sification problem, solved by applying a deep learning technique. A digital audio excerpt is hierarchically processed and split into subsequences and gamaka sequences to mimic a textual document structure, so our model can learn the resulting tonal and temporal se- quence patterns using a Recurrent Neural Network. -

Rakti in Raga and Laya
VEDAVALLI SPEAKS Sangita Kalanidhi R. Vedavalli is not only one of the most accomplished of our vocalists, she is also among the foremost thinkers of Carnatic music today with a mind as insightful and uncluttered as her music. Sruti is delighted to share her thoughts on a variety of topics with its readers. Rakti in raga and laya Rakti in raga and laya’ is a swara-oriented as against gamaka- complex theme which covers a oriented raga-s. There is a section variety of aspects. Attempts have of exponents which fears that ‘been made to interpret rakti in the tradition of gamaka-oriented different ways. The origin of the singing is giving way to swara- word ‘rakti’ is hard to trace, but the oriented renditions. term is used commonly to denote a manner of singing that is of a Yo asau Dhwaniviseshastu highly appreciated quality. It swaravamavibhooshitaha carries with it a sense of intense ranjako janachittaanaam involvement or engagement. Rakti Sankarabharanam or Bhairavi? rasa raga udaahritaha is derived from the root word Tyagaraja did not compose these ‘ranj’ – ranjayati iti ragaha, ranjayati kriti-s as a cluster under the There is a reference to ‘dhwani- iti raktihi. That which is pleasing, category of ghana raga-s. Older visesha’ in this sloka from Brihaddcsi. which engages the mind joyfully texts record these five songs merely Scholars have suggested that may be called rakti. The term rakti dhwanivisesha may be taken th as Tyagaraja’ s compositions and is not found in pre-17 century not as the Pancharatna kriti-s. Not to connote sruti and that its texts like Niruktam, Vyjayanti and only are these raga-s unsuitable for integration with music ensures a Amarakosam. -

M.A-Music-Vocal-Syllabus.Pdf
BANGALORE UNIVERSITY NAAC ACCREDITED WITH ‘A’ GRADE P.G. DEPARTMENT OF PERFORMING ARTS JNANABHARATHI, BANGALORE-560056 MUSIC SYLLABUS – M.A KARNATAKA MUSIC VOCAL AND INSTRUMENTAL (VEENA, VIOLIN AND FLUTE) CBCS SYSTEM- 2014 Dr. B.M. Jayashree. Professor of Music Chairperson, BOS (PG) M.A. KARNATAKA MUSIC VOCAL AND INSTRUMENTAL (VEENA, VIOLIN AND FLUTE) Semester scheme syllabus CBCS Scheme of Examination, continuous Evaluation and other Requirements: 1. ELIGIBILITY: A Degree with music vocal/instrumental as one of the optional subject with at least 50% in the concerned optional subject an merit internal among these applicant Of A Graduate with minimum of 50% marks secured in the senior grade examination in music (vocal/instrumental) conducted by secondary education board of Karnataka OR a graduate with a minimum of 50% marks secured in PG Diploma or 2 years diploma or 4 year certificate course in vocal/instrumental music conducted either by any recognized Universities of any state out side Karnataka or central institution/Universities Any degree with: a) Any certificate course in music b) All India Radio/Doordarshan gradation c) Any diploma in music or five years of learning certificate by any veteran musician d) Entrance test (practical) is compulsory for admission. 2. M.A. MUSIC course consists of four semesters. 3. First semester will have three theory paper (core), three practical papers (core) and one practical paper (soft core). 4. Second semester will have three theory papers (core), two practical papers (core), one is project work/Dissertation practical paper and one is practical paper (soft core) 5. Third semester will have two theory papers (core), three practical papers (core) and one is open Elective Practical paper 6. -
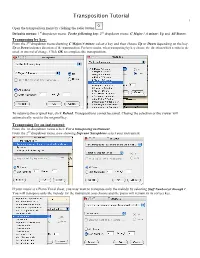
Transposition Tutorial 1
Transposition Tutorial 1 Open the transposition menu by clicking the radio button Defaults menus: 1st dropdown menu: To the following key; 2nd dropdown menu: C Major / A minor; Up and All Staves. Transposing by key: From the 2nd dropdown menu showing C Major/A minor, select a key and then choose Up or Down depending on the key. Up or Down indicates direction of the transposition. For best results, when transposing by key choose the direction which results in the smallest interval of change. Click OK to complete the transposition. To return to the original key, click Reload. Transpositions cannot be saved. Closing the selection or the viewer will automatically reset to the original key. Transposing for an instrument: From the 1st dropdown menu select: For a transposing instrument. From the 2nd dropdown menu, now showing Soprano Saxophone select your instrument. If your music is a Piano Vocal sheet, you may want to transpose only the melody by selecting Staff Number(s)1 through 1. You will transpose only the melody for the instrument you choose and the piano will remain in its correct key. Transposition Tutorial 2 Transposing for an Instrument (continued): Once you have transposed the melody line for a specific instrument you may choose to change the octave of just the melody line. For example, Tenor Saxophone transposes up an octave and a 2nd, and the resulting transposition may be too high for the instrument. From the 1st dropdown menu, select By Interval. From the 2nd dropdown menu now showing Minor Second, select Perfect Octave. Select the Down button and to transpose only the melody line select Staff Number(s) (Staff number 1 though 1 is the melody line). -

CARNATIC MUSIC (CODE – 032) CLASS – X (Melodic Instrument) 2020 – 21 Marking Scheme
CARNATIC MUSIC (CODE – 032) CLASS – X (Melodic Instrument) 2020 – 21 Marking Scheme Time - 2 hrs. Max. Marks : 30 Part A Multiple Choice Questions: Attempts any of 15 Question all are of Equal Marks : 1. Raga Abhogi is Janya of a) Karaharapriya 2. 72 Melakarta Scheme has c) 12 Chakras 3. Identify AbhyasaGhanam form the following d) Gitam 4. Idenfity the VarjyaSwaras in Raga SuddoSaveri b) GhanDharam – NishanDham 5. Raga Harikambhoji is a d) Sampoorna Raga 6. Identify popular vidilist from the following b) M. S. Gopala Krishnan 7. Find out the string instrument which has frets d) Veena 8. Raga Mohanam is an d) Audava – Audava Raga 9. Alankaras are set to d) 7 Talas 10 Mela Number of Raga Maya MalawaGoula d) 15 11. Identify the famous flutist d) T R. Mahalingam 12. RupakaTala has AksharaKals b) 6 13. Indentify composer of Navagrehakritis c) MuthuswaniDikshitan 14. Essential angas of kriti are a) Pallavi-Anuppallavi- Charanam b) Pallavi –multifplecharanma c) Pallavi – MukkyiSwaram d) Pallavi – Charanam 15. Raga SuddaDeven is Janya of a) Sankarabharanam 16. Composer of Famous GhanePanchartnaKritis – identify a) Thyagaraja 17. Find out most important accompanying instrument for a vocal concert b) Mridangam 18. A musical form set to different ragas c) Ragamalika 19. Identify dance from of music b) Tillana 20. Raga Sri Ranjani is Janya of a) Karahara Priya 21. Find out the popular Vena artist d) S. Bala Chander Part B Answer any five questions. All questions carry equal marks 5X3 = 15 1. Gitam : Gitam are the simplest musical form. The term “Gita” means song it is melodic extension of raga in which it is composed. -
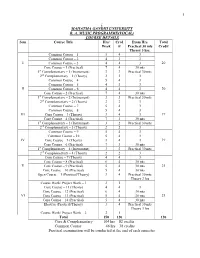
1 ; Mahatma Gandhi University B. A. Music Programme(Vocal
1 ; MAHATMA GANDHI UNIVERSITY B. A. MUSIC PROGRAMME(VOCAL) COURSE DETAILS Sem Course Title Hrs/ Cred Exam Hrs. Total Week it Practical 30 mts Credit Theory 3 hrs. Common Course – 1 5 4 3 Common Course – 2 4 3 3 I Common Course – 3 4 4 3 20 Core Course – 1 (Practical) 7 4 30 mts 1st Complementary – 1 (Instrument) 3 3 Practical 30 mts 2nd Complementary – 1 (Theory) 2 2 3 Common Course – 4 5 4 3 Common Course – 5 4 3 3 II Common Course – 6 4 4 3 20 Core Course – 2 (Practical) 7 4 30 mts 1st Complementary – 2 (Instrument) 3 3 Practical 30 mts 2nd Complementary – 2 (Theory) 2 2 3 Common Course – 7 5 4 3 Common Course – 8 5 4 3 III Core Course – 3 (Theory) 3 4 3 19 Core Course – 4 (Practical) 7 3 30 mts 1st Complementary – 3 (Instrument) 3 2 Practical 30 mts 2nd Complementary – 3 (Theory) 2 2 3 Common Course – 9 5 4 3 Common Course – 10 5 4 3 IV Core Course – 5 (Theory) 3 4 3 19 Core Course – 6 (Practical) 7 3 30 mts 1st Complementary – 4 (Instrument) 3 2 Practical 30 mts 2nd Complementary – 4 (Theory) 2 2 3 Core Course – 7 (Theory) 4 4 3 Core Course – 8 (Practical) 6 4 30 mts V Core Course – 9 (Practical) 5 4 30 mts 21 Core Course – 10 (Practical) 5 4 30 mts Open Course – 1 (Practical/Theory) 3 4 Practical 30 mts Theory 3 hrs Course Work/ Project Work – 1 2 1 Core Course – 11 (Theory) 4 4 3 Core Course – 12 (Practical) 6 4 30 mts VI Core Course – 13 (Practical) 5 4 30 mts 21 Core Course – 14 (Practical) 5 4 30 mts Elective (Practical/Theory) 3 4 Practical 30 mts Theory 3 hrs Course Work/ Project Work – 2 2 1 Total 150 120 120 Core & Complementary 104 hrs 82 credits Common Course 46 hrs 38 credits Practical examination will be conducted at the end of each semester 2 MAHATMA GANDHI UNIVERSITY B. -

Carnatic Music (Melodic Instrumental) (Code No
(B) CARNATIC MUSIC (MELODIC INSTRUMENTAL) (CODE NO. 032) CLASS–XI: (THEORY)(2019-20) One theory paper Total Marks: 100 2 Hours Marks : 30 Theory: A. History and Theory of Indian Music 1. (a) An outline knowledge of the following Lakshana Grandhas Silappadikaram, Natyasastra, Sangita Ratnakara and Chaturdandi Prakasika. (b) Short life sketch and contributions of the following:- Veena Dhanammal, flute Saraba Sastry, Rajamanikkam Pillai, Tirukkodi Kaval Krishna lyer (violin) Rajaratnam Pillai (Nagasvaram), Thyagaraja, Syamasastry, Muthuswamy Deekshitar, Veena Seshanna. (c) Brief study of the musical forms: Geetam and its varieties; Varnam – Padavarnam – Daruvarna Svarajati, Kriti/Kirtana and Padam 2. Definition and explanation of the following terms: Nada, Sruti, Svara, Vadi, Vivadi:, Samvadi, Anuvadi, Amsa & Nyasa, Jaati, Raga, Tala, Jati, Yati, Suladisapta talas, Nadai, Arohana, Avarohana. 3. Candidates should be able to write in notation the Varnam in the prescribed ragas. 4. Lakshanas of the ragas prescribed. 5. Talas Prescribed: Adi, Roopaka, Misra Chapu and Khanda Chapu. A brief study of Suladi Saptatalas. 6. A brief introduction to Manodhama Sangitam CLASS–XI (PRACTICAL) One Practical Paper Marks: 70 B. Practical Activities 1. Ragas Prescribed: Mayamalavagowla, Sankarabharana, Kharaharapriya, Kalyani, Kambhoji, Madhyamavati, Arabhi, Pantuvarali Kedaragaula, Vasanta, Anandabharavi, Kanada, Dhanyasi. 2. Varnams (atleast three) in Aditala in two degree of speed. 3. Kriti/Kirtana in each of the prescribed ragas, covering the main Talas Adi, Rupakam and Chapu. 4. Brief alapana of the ragas prescribed. 5. Technique of playing niraval and kalpana svaras in Adi, and Rupaka talas in two degrees of speed. 6. The candidate should be able to produce all the gamakas pertaining to the chosen instrument. -

Tillana Raaga: Bageshri; Taala: Aadi; Composer
Tillana Raaga: Bageshri; Taala: Aadi; Composer: Lalgudi G. Jayaraman Aarohana: Sa Ga2 Ma1 Dha2 Ni2 Sa Avarohana: Sa Ni2 Dha2 Ma1 Pa Dha2 Ga2 Ma1 Ga2 Ri2 Sa SaNiDhaMa .MaPaDha | Ga. .Ma | RiRiSa . || DhaNiSaGa .SaGaMa | Dha. MaDha| NiRi Sa . || DhaNiSaMa .GaRiSa |Ri. NiDha | NiRi Sa . || SaRiNiDha .MaPaDha |Ga . Ma . | RiNiSa . || Sa ..Ni .Dha Ma . |Sa..Ma .Ga | RiNiSa . || Sa ..Ni .Dha Ma~~ . |Sa..Ma .Ga | RiNiSa . || Pallavi tom dhru dhru dheem tadara | tadheem dheem ta na || dhim . dhira | na dhira na Dhridhru| (dhirana: DhaMaNi .. dhirana.: DhaMaGa .) tom dhru dhru dheem tadara | tadheem dheem ta na || dhim . dhira | na dhira na Dhridhru|| (dhirana: MaDha NiSa.. dhirana:DhaMa Ga..) tom dhru dhru dheem tadara | tadheem dheem ta na || (ta:DhaNi na:NiGaRi) dhim . dhira | na dhira na Dhridhru|| (dhirana:NiGaSaSaNi. Dhirana:DhaSaNiNiDha .) tom dhru dhru dheem tadara | tadheem dheem ta na || dhim . dhira | na dhira na Dhridhru|| (dhira:GaMaDhaNi na:GaGaRiSa dhira:NiDha na:Ga..) tom dhru dhru dheem tadana | tadheem dheem ta na || dhim.... Anupallavi SaMa .Ga MaNi . Dha| NiGa .Ri | NiDhaSa . || GaRi .Sa NiMa .Pa | Dha Ga..Ma | RiNi Sa . || naadhru daani tomdhru dhim | ^ta- ka-jha | Nuta dhim || … naadhru daani tomdhru dhim | (Naadru:MaGa, daani:DhaMa, tomdhru:NiDha, dhim: Sa) ^ta- ka-jha | Nuta dhim || (NiDha SaNi RiSa) taJha-Nu~ta dhim jhaNu | (tajha:SaSa Nu~ta: NiSaRiSa dhim:Ni; jha~Nu:MaDhaNi. tadhim . na | ta dhim ta || (tadhim:Dha Ga..;nata dhimta: MNiDha Sa.Sa) tanadheem .tatana dheemta tanadheem |(tanadheemta: DhaNi Ri ..Sa tanadheem: NiRiSa. .Sa tanadheem: NiDhaNi . ) .dheem dheemta | tom dhru dheem (dheem: Sa deemta:Ga.Ma tomdhrudeem:Ri..Ri Sa) .dheem dheem dheemta ton-| (dheem:Dha.