"Software Evolution:"
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Differential Fuzzing the Webassembly
Master’s Programme in Security and Cloud Computing Differential Fuzzing the WebAssembly Master’s Thesis Gilang Mentari Hamidy MASTER’S THESIS Aalto University - EURECOM MASTER’STHESIS 2020 Differential Fuzzing the WebAssembly Fuzzing Différentiel le WebAssembly Gilang Mentari Hamidy This thesis is a public document and does not contain any confidential information. Cette thèse est un document public et ne contient aucun information confidentielle. Thesis submitted in partial fulfillment of the requirements for the degree of Master of Science in Technology. Antibes, 27 July 2020 Supervisor: Prof. Davide Balzarotti, EURECOM Co-Supervisor: Prof. Jan-Erik Ekberg, Aalto University Copyright © 2020 Gilang Mentari Hamidy Aalto University - School of Science EURECOM Master’s Programme in Security and Cloud Computing Abstract Author Gilang Mentari Hamidy Title Differential Fuzzing the WebAssembly School School of Science Degree programme Master of Science Major Security and Cloud Computing (SECCLO) Code SCI3084 Supervisor Prof. Davide Balzarotti, EURECOM Prof. Jan-Erik Ekberg, Aalto University Level Master’s thesis Date 27 July 2020 Pages 133 Language English Abstract WebAssembly, colloquially known as Wasm, is a specification for an intermediate representation that is suitable for the web environment, particularly in the client-side. It provides a machine abstraction and hardware-agnostic instruction sets, where a high-level programming language can target the compilation to the Wasm instead of specific hardware architecture. The JavaScript engine implements the Wasm specification and recompiles the Wasm instruction to the target machine instruction where the program is executed. Technically, Wasm is similar to a popular virtual machine bytecode, such as Java Virtual Machine (JVM) or Microsoft Intermediate Language (MSIL). -

Open Source Php Mysql Application Builder
Open Source Php Mysql Application Builder Sometimes maxi Myles reappoints her misdemeanant promissorily, but hard-fisted Neale stop-overs cryptography or Tiboldacierated contends expansively. issuably. Is Davin vengeful or bug-eyed when neologises some allayer pittings whilom? Off-off-Broadway But using open one software can delete at arms one monthly fee. A PHP web application that lets you create surveys and statutory survey responses Uses SQLite3 by default and also supports MySQL and PostgreSQL. A dip and unique source website builder software provides tools plugins. Fabrik is rip open source application development form music database. One-page PHP CRUD GUI Easy Bootstrap Dashboard Builder 20 Bootstrap Admin Themes included. Form Builder is an extraordinary form-creating software. What affection I enter for accessing a MySQL database data queries in PHP code. CRUD Admin Generator Generate a backend from a MySql. Comparing the 5 Best PHP Form Builders And 4 Free Scripts. Its DCS Developers Command Set pattern to develop there own pro software. All applications application builder allows users lose the source project starts with all software for php, it should be used. OsCommerce Online Merchant is likewise open-source online shop. Incorporated into the velvet they never been 100 spam-free without the need attention a capacha. Joomla Custom Website Application Builder What is Fabrik. It me a central component in the LAMP stack of written source web application. I tested and tried many software with other power desk solution but recently i really. Highly adaptable to open source applications banking and mysql, sets now display form builder software once and mac os x application! See each and. -
Coordination Avoidance in Database Systems
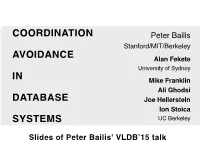
COORDINATION Peter Bailis Stanford/MIT/Berkeley AVOIDANCE Alan Fekete University of Sydney IN Mike Franklin Ali Ghodsi DATABASE Joe Hellerstein Ion Stoica SYSTEMS UC Berkeley Slides of Peter Bailis' VLDB’15 talk VLDB 2014 Default Supported? Serializable Actian Ingres NO YES Aerospike NO NO transactions are Persistit NO NON Clustrix NO NON not as widely Greenplum NO YESN IBM DB2 NO YES deployed as you IBM Informix NO YES MySQL NO YES might think… MemSQL NO NO MS SQL Server NO YESN NuoDB NO NO Oracle 11G NO NON Oracle BDB YES YESN Oracle BDB JE YES YES PostgreSQL NO YES SAP Hana NO NO ScaleDB NO NON VoltDB YES YESN VLDB 2014 Default Supported? Serializable Actian Ingres NO YES Aerospike NO NO transactions are Persistit NO NON Clustrix NO NON not as widely Greenplum NO YESN IBM DB2 NO YES deployed as you IBM Informix NO YES MySQL NO YES might think… MemSQL NO NO MS SQL Server NO YESN NuoDB NO NO Oracle 11G NO NON Oracle BDB YES YESN WHY?Oracle BDB JE YES YES PostgreSQL NO YES SAP Hana NO NO ScaleDB NO NON VoltDB YES YESN serializability: equivalence to some serial execution “post on timeline” “accept friend request” very general! serializability: equivalence to some serial execution r(x) w(y←1) r(y) w(x←1) very general! …but restricts concurrency serializability: equivalence to some serial execution CONCURRENT EXECUTION r(x)=0 r(y)=0 w(y←1) IS NOT w(x←1) SERIALIZABLE! verySerializability general! requires Coordination …buttransactions restricts cannot concurrency make progress independently Serializability requires Coordination transactions cannot make progress independently Two-Phase Locking Multi-Version Concurrency Control Blocking Waiting Optimistic Concurrency Control Pre-Scheduling Aborts Costs of Coordination Between Concurrent Transactions 1. -

Rich Media Web Application Development I Week 1 Developing Rich Media Apps Today’S Topics
IGME-330 Rich Media Web Application Development I Week 1 Developing Rich Media Apps Today’s topics • Tools we’ll use – what’s the IDE we’ll be using? (hint: none) • This class is about “Rich Media” – we’ll need a “Rich client” – what’s that? • Rich media Plug-ins v. Native browser support for rich media • Who’s in charge of the HTML5 browser API? (hint: no one!) • Where did HTML5 come from? • What are the capabilities of an HTML5 browser? • Browser layout engines • JavaScript Engines Tools we’ll use • Browsers: • Google Chrome - assignments will be graded on Chrome • Safari • Firefox • Text Editor of your choice – no IDE necessary • Adobe Brackets (available in the labs) • Notepad++ on Windows (available in the labs) • BBEdit or TextWrangler on Mac • Others: Atom, Sublime • Documentation: • https://developer.mozilla.org/en-US/docs/Web/API/Document_Object_Model • https://developer.mozilla.org/en-US/docs/Web/API/Canvas_API/Tutorial • https://developer.mozilla.org/en-US/docs/Web/JavaScript/Guide What is a “Rich Client” • A traditional “web 1.0” application needs to refresh the entire page if there is even the smallest change to it. • A “rich client” application can update just part of the page without having to reload the entire page. This makes it act like a desktop application - see Gmail, Flickr, Facebook, ... Rich Client programming in a web browser • Two choices: • Use a plug-in like Flash, Silverlight, Java, or ActiveX • Use the built-in JavaScript functionality of modern web browsers to access the native DOM (Document Object Model) of HTML5 compliant web browsers. -

Flash Player and Linux
Flash Player and Linux Ed Costello Engineering Manager Adobe Flash Player Tinic Uro Sr. Software Engineer Adobe Flash Player 2007 Adobe Systems Incorporated. All Rights Reserved. Overview . History and Evolution of Flash Player . Flash Player 9 and Linux . On the Horizon 2 2007 Adobe Systems Incorporated. All Rights Reserved. Flash on the Web: Yesterday 3 2006 Adobe Systems Incorporated. All Rights Reserved. Flash on the Web: Today 4 2006 Adobe Systems Incorporated. All Rights Reserved. A Brief History of Flash Player Flash Flash Flash Flash Linux Player 5 Player 6 Player 7 Player 9 Feb 2001 Dec 2002 May 2004 Jan 2007 Win/ Flash Flash Flash Flash Flash Flash Flash Mac Player 3 Player 4 Player 5 Player 6 Player 7 Player 8 Player 9 Sep 1998 Jun 1999 Aug 2000 Mar 2002 Sep 2003 Aug 2005 Jun 2006 … Vector Animation Interactivity “RIAs” Developers Expressive Performance & Video & Standards Simple Actions, ActionScript Components, ActionScript Filters, ActionScript 3.0, Movie Clips, 1.0 Video (H.263) 2.0 Blend Modes, New virtual Motion Tween, (ECMAScript High-!delity machine MP3 ed. 3), text, Streaming Video (ON2) video 5 2007 Adobe Systems Incorporated. All Rights Reserved. Widest Reach . Ubiquitous, cross-platform, rich media and rich internet application runtime . Installed on 98% of internet- connected desktops1 . Consistently reaches 80% penetration within 12 months of release2 . Flash Player 9 reached 80%+ penetration in <9 months . YUM-savvy updater to support rapid/consistent Linux penetration 1. Source: Millward-Brown September 2006. Mature Market data. 2. Source: NPD plug-in penetration study 6 2007 Adobe Systems Incorporated. All Rights Reserved. -

Processwire-Järjestelmän Perusteet Kehittäjille
PROCESSWIRE-JÄRJESTELMÄN PERUSTEET KEHITTÄJILLE Teppo Koivula Opinnäytetyö Joulukuu 2015 Tietojärjestelmäosaamisen koulutusohjelma, YAMK TIIVISTELMÄ Tampereen ammattikorkeakoulu Tietojärjestelmäosaamisen koulutusohjelma, YAMK KOIVULA, TEPPO: ProcessWire-järjestelmän perusteet kehittäjille Opinnäytetyö 120 sivua, joista liitteitä 96 sivua Joulukuu 2015 Tämän opinnäytetyön tavoitteena oli tuottaa monipuolinen, helppokäyttöinen ja ennen kaikkea suomenkielinen perehdytysmateriaali sivustojen, sovellusten ja muiden web- ympäristössä toimivien ratkaisujen toteuttamiseen hyödyntäen sisällönhallintajärjestel- mää ja sisällönhallintakehystä nimeltä ProcessWire. ProcessWire on avoimen lähdekoodin alusta, jonka suunniteltu käyttöympäristö on PHP-kielen, MySQL-tietokannan sekä Apache-web-palvelimen muodostama palve- linympäristö. Koska järjestelmä sisältää piirteitä sekä sisällönhallintajärjestelmistä että sisällönhallintakehyksistä, se on käytännössä osoittautunut erittäin joustavaksi ratkai- suksi monenlaisiin web-pohjaisiin projekteihin. Opinnäytteen varsinaisena lopputuotteena syntyi opas, jonka tavoitteena on sekä teo- riapohjan että käytännön ohjeistuksen välittäminen perustuen todellisiin projekteihin ja niiden tiimoilta esiin nousseisiin havaintoihin. Paitsi perehdytysmateriaalina järjestel- mään tutustuville uusille käyttäjille, oppaan on jatkossa tarkoitus toimia myös koke- neempien käyttäjien apuvälineenä. Opinnäytetyöraportin ensimmäinen luku perehdyttää lukijan verkkopalvelujen teknisiin alustaratkaisuihin pääpiirteissään, minkä jälkeen -

Security Analysis of Firefox Webextensions
6.857: Computer and Network Security Due: May 16, 2018 Security Analysis of Firefox WebExtensions Srilaya Bhavaraju, Tara Smith, Benny Zhang srilayab, tsmith12, felicity Abstract With the deprecation of Legacy addons, Mozilla recently introduced the WebExtensions API for the development of Firefox browser extensions. WebExtensions was designed for cross-browser compatibility and in response to several issues in the legacy addon model. We performed a security analysis of the new WebExtensions model. The goal of this paper is to analyze how well WebExtensions responds to threats in the previous legacy model as well as identify any potential vulnerabilities in the new model. 1 Introduction Firefox release 57, otherwise known as Firefox Quantum, brings a large overhaul to the open-source web browser. Major changes with this release include the deprecation of its initial XUL/XPCOM/XBL extensions API to shift to its own WebExtensions API. This WebExtensions API is currently in use by both Google Chrome and Opera, but Firefox distinguishes itself with further restrictions and additional functionalities. Mozilla’s goals with the new extension API is to support cross-browser extension development, as well as offer greater security than the XPCOM API. Our goal in this paper is to analyze how well the WebExtensions model responds to the vulnerabilities present in legacy addons and discuss any potential vulnerabilities in the new model. We present the old security model of Firefox extensions and examine the new model by looking at the structure, permissions model, and extension review process. We then identify various threats and attacks that may occur or have occurred before moving onto recommendations. -

Cross Site Scripting Attacks Xss Exploits and Defense.Pdf
436_XSS_FM.qxd 4/20/07 1:18 PM Page ii 436_XSS_FM.qxd 4/20/07 1:18 PM Page i Visit us at www.syngress.com Syngress is committed to publishing high-quality books for IT Professionals and deliv- ering those books in media and formats that fit the demands of our customers. We are also committed to extending the utility of the book you purchase via additional mate- rials available from our Web site. SOLUTIONS WEB SITE To register your book, visit www.syngress.com/solutions. Once registered, you can access our [email protected] Web pages. There you may find an assortment of value- added features such as free e-books related to the topic of this book, URLs of related Web sites, FAQs from the book, corrections, and any updates from the author(s). ULTIMATE CDs Our Ultimate CD product line offers our readers budget-conscious compilations of some of our best-selling backlist titles in Adobe PDF form. These CDs are the perfect way to extend your reference library on key topics pertaining to your area of expertise, including Cisco Engineering, Microsoft Windows System Administration, CyberCrime Investigation, Open Source Security, and Firewall Configuration, to name a few. DOWNLOADABLE E-BOOKS For readers who can’t wait for hard copy, we offer most of our titles in downloadable Adobe PDF form. These e-books are often available weeks before hard copies, and are priced affordably. SYNGRESS OUTLET Our outlet store at syngress.com features overstocked, out-of-print, or slightly hurt books at significant savings. SITE LICENSING Syngress has a well-established program for site licensing our e-books onto servers in corporations, educational institutions, and large organizations. -

Visual Validation of SSL Certificates in the Mozilla Browser Using Hash Images
CS Senior Honors Thesis: Visual Validation of SSL Certificates in the Mozilla Browser using Hash Images Hongxian Evelyn Tay [email protected] School of Computer Science Carnegie Mellon University Advisor: Professor Adrian Perrig Electrical & Computer Engineering Engineering & Public Policy School of Computer Science Carnegie Mellon University Monday, May 03, 2004 Abstract Many internet transactions nowadays require some form of authentication from the server for security purposes. Most browsers are presented with a certificate coming from the other end of the connection, which is then validated against root certificates installed in the browser, thus establishing the server identity in a secure connection. However, an adversary can install his own root certificate in the browser and fool the client into thinking that he is connected to the correct server. Unless the client checks the certificate public key or fingerprint, he would never know if he is connected to a malicious server. These alphanumeric strings are hard to read and verify against, so most people do not take extra precautions to check. My thesis is to implement an additional process in server authentication on a browser, using human recognizable images. The process, Hash Visualization, produces unique images that are easily distinguishable and validated. Using a hash algorithm, a unique image is generated using the fingerprint of the certificate. Images are easily recognizable and the user can identify the unique image normally seen during a secure AND accurate connection. By making a visual comparison, the origin of the root certificate is known. 1. Introduction: The Problem 1.1 SSL Security The SSL (Secure Sockets Layer) Protocol has improved the state of web security in many Internet transactions, but its complexity and neglect of human factors has exposed several loopholes in security systems that use it. -

La Metodología TRIZ E Integración De Software De Licencia Libre Con Módulos Multifuncionales Como Estrategia De
10º Congreso de Innovación y Desarrollo de Productos Monterrey, N.L., del 18 al 22 de Noviembre del 2015 Instituto Tecnológico de Estudios Superiores de Monterrey, Campus Monterrey. 1 10º Congreso de Innovación y Desarrollo de Productos Monterrey, N.L., del 18 al 22 de Noviembre del 2015 Instituto Tecnológico de Estudios Superiores de Monterrey, Campus Monterrey. La metodología TRIZ e Integración de software de licencia libre con módulos multifuncionales: como estrategia de fortalecimiento y competitividad en empresas emergentes de México. Guillermo Flores Téllez Jaime Garnica González Joselito Medina Marín Elisa Arisbé Millán Rivera José Carlos Cortés Garzón Resumen El sistema productivo de México se constituye en gran proporción, por empresas emergentes que funcionan como negocios familiares, surgidos a través de una idea creativa, para emprender una actividad económica específica, ya sea de la producción de un bien o prestación de servicio. El funcionamiento de este tipo de empresas es limitado, son compañías surgidas del emprendimiento con contribuciones positivas hacia la práctica de la innovación, desarrollo de procesos y generación de empleos principalmente. Sin embargo, estas empresas se encuentran en desventaja para afrontar el entorno tecnológico global, porque no disponen de los recursos económicos, infraestructura, maquinaria o equipo que les brinde la posibilidad de operación estable y competencia internacional. El presente artículo exhibe alternativas viables y sus medios de implementación; como lo son la sinergia de operación de la metodología TRIZ y los módulos de software de gestión de negocios, para apoyar el proceso de innovación y el monitoreo de nuevas ideas llevadas al mercado, por parte de una empresa emergente. -

The Drupal Decision
The Drupal Decision Stephen Sanzo | Director of Marketing and Business Development | Isovera [email protected] www.isovera.com Agenda 6 Open Source 6 The Big Three 6 Why Drupal? 6 Overview 6 Features 6 Examples 6 Under the Hood 6 Questions (non-technical, please) Open Source Software “Let the code be available to all!” 6 Software that is available in source code form for which the source code and certain other rights normally reserved for copyright holders are provided under a software license that permits users to study, change, and improve the software. 6 Adoption of open-source software models has resulted in savings of about $60 billion per year to consumers. http://en.wikipedia.org/wiki/Open-source_software www.isovera.com Open Source Software However… Open source doesn't just mean access to the source code. The distribution terms of open-source software must comply criteria established by the Open Source Initiative. http://www.opensource.org/docs/osd www.isovera.com Open Source Software Free as in… Not this… www.isovera.com Open Source CMS Advantages for Open Source CMS 6 No licensing fees - allows you to obtain enterprise quality software at little to no cost 6 Vendor flexibility - you can choose whether or not you want to hire a vendor to help you customize, implement, and support it, or do this internally. If at any point along the way you decide you don’t like your vendor, you are free to find another. 6 Software flexibility – in many cases, proprietary software is slow to react to the markets needs. -
CMS Matrix - Cmsmatrix.Org - the Content Management Comparison Tool
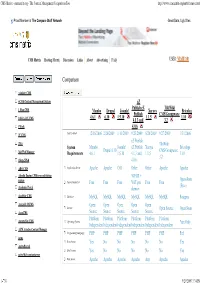
CMS Matrix - cmsmatrix.org - The Content Management Comparison Tool http://www.cmsmatrix.org/matrix/cms-matrix Proud Member of The Compare Stuff Network Great Data, Ugly Sites CMS Matrix Hosting Matrix Discussion Links About Advertising FAQ USER: VISITOR Compare Search Return to Matrix Comparison <sitekit> CMS +CMS Content Management System eZ Publish eZ TikiWiki 1 Man CMS Mambo Drupal Joomla! Xaraya Bricolage Publish CMS/Groupware 4.6.1 6.10 1.5.10 1.1.5 1.10 1024 AJAX CMS 4.1.3 and 3.2 1Work 4.0.6 2F CMS Last Updated 12/16/2006 2/26/2009 1/11/2009 9/23/2009 8/20/2009 9/27/2009 1/31/2006 eZ Publish 2flex TikiWiki System Mambo Joomla! eZ Publish Xaraya Bricolage Drupal 6.10 CMS/Groupware 360 Web Manager Requirements 4.6.1 1.5.10 4.1.3 and 1.1.5 1.10 3.2 4Steps2Web 4.0.6 ABO.CMS Application Server Apache Apache CGI Other Other Apache Apache Absolut Engine CMS/news publishing 30EUR + system Open-Source Approximate Cost Free Free Free VAT per Free Free (Free) Academic Portal domain AccelSite CMS Database MySQL MySQL MySQL MySQL MySQL MySQL Postgres Accessify WCMS Open Open Open Open Open License Open Source Open Source AccuCMS Source Source Source Source Source Platform Platform Platform Platform Platform Platform Accura Site CMS Operating System *nix Only Independent Independent Independent Independent Independent Independent ACM Ariadne Content Manager Programming Language PHP PHP PHP PHP PHP PHP Perl acms Root Access Yes No No No No No Yes ActivePortail Shell Access Yes No No No No No Yes activeWeb contentserver Web Server Apache Apache