On the Opportunities and Risks of Foundation Models Arxiv
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
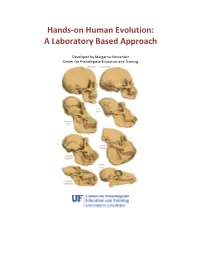
Hands-On Human Evolution: a Laboratory Based Approach
Hands-on Human Evolution: A Laboratory Based Approach Developed by Margarita Hernandez Center for Precollegiate Education and Training Author: Margarita Hernandez Curriculum Team: Julie Bokor, Sven Engling A huge thank you to….. Contents: 4. Author’s note 5. Introduction 6. Tips about the curriculum 8. Lesson Summaries 9. Lesson Sequencing Guide 10. Vocabulary 11. Next Generation Sunshine State Standards- Science 12. Background information 13. Lessons 122. Resources 123. Content Assessment 129. Content Area Expert Evaluation 131. Teacher Feedback Form 134. Student Feedback Form Lesson 1: Hominid Evolution Lab 19. Lesson 1 . Student Lab Pages . Student Lab Key . Human Evolution Phylogeny . Lab Station Numbers . Skeletal Pictures Lesson 2: Chromosomal Comparison Lab 48. Lesson 2 . Student Activity Pages . Student Lab Key Lesson 3: Naledi Jigsaw 77. Lesson 3 Author’s note Introduction Page The validity and importance of the theory of biological evolution runs strong throughout the topic of biology. Evolution serves as a foundation to many biological concepts by tying together the different tenants of biology, like ecology, anatomy, genetics, zoology, and taxonomy. It is for this reason that evolution plays a prominent role in the state and national standards and deserves thorough coverage in a classroom. A prime example of evolution can be seen in our own ancestral history, and this unit provides students with an excellent opportunity to consider the multiple lines of evidence that support hominid evolution. By allowing students the chance to uncover the supporting evidence for evolution themselves, they discover the ways the theory of evolution is supported by multiple sources. It is our hope that the opportunity to handle our ancestors’ bone casts and examine real molecular data, in an inquiry based environment, will pique the interest of students, ultimately leading them to conclude that the evidence they have gathered thoroughly supports the theory of evolution. -

Is Shuma the Chinese Analog of Soma/Haoma? a Study of Early Contacts Between Indo-Iranians and Chinese
SINO-PLATONIC PAPERS Number 216 October, 2011 Is Shuma the Chinese Analog of Soma/Haoma? A Study of Early Contacts between Indo-Iranians and Chinese by ZHANG He Victor H. Mair, Editor Sino-Platonic Papers Department of East Asian Languages and Civilizations University of Pennsylvania Philadelphia, PA 19104-6305 USA [email protected] www.sino-platonic.org SINO-PLATONIC PAPERS FOUNDED 1986 Editor-in-Chief VICTOR H. MAIR Associate Editors PAULA ROBERTS MARK SWOFFORD ISSN 2157-9679 (print) 2157-9687 (online) SINO-PLATONIC PAPERS is an occasional series dedicated to making available to specialists and the interested public the results of research that, because of its unconventional or controversial nature, might otherwise go unpublished. The editor-in-chief actively encourages younger, not yet well established, scholars and independent authors to submit manuscripts for consideration. Contributions in any of the major scholarly languages of the world, including romanized modern standard Mandarin (MSM) and Japanese, are acceptable. In special circumstances, papers written in one of the Sinitic topolects (fangyan) may be considered for publication. Although the chief focus of Sino-Platonic Papers is on the intercultural relations of China with other peoples, challenging and creative studies on a wide variety of philological subjects will be entertained. This series is not the place for safe, sober, and stodgy presentations. Sino- Platonic Papers prefers lively work that, while taking reasonable risks to advance the field, capitalizes on brilliant new insights into the development of civilization. Submissions are regularly sent out to be refereed, and extensive editorial suggestions for revision may be offered. Sino-Platonic Papers emphasizes substance over form. -

Spreading Excellence Report
HIGH PERFORMANCE AND EMBEDDED ARCHITECTURE AND COMPILATION Project Acronym: HiPEAC Project full title: High Performance and Embedded Architecture and Compilation Grant agreement no: ICT-217068 DELIVERABLE 3.1 SPREADING EXCELLENCE REPORT 15/04/2009 Spreading Excellence Report 1 1. Summary on Spreading Excellence ................................................................................ 3 2. Task 3.1: Conference ........................................................................................................ 4 2.1. HiPEAC 2008 Conference, Goteborg ......................................................................... 4 2.2. HiPEAC 2009 Conference, Paphos ........................................................................... 10 2.3. Conference Ranking .................................................................................................. 16 3. Task 3.2: Summer School .............................................................................................. 16 th 3.1. 4 International Summer School – 2008 ................................................................... 16 th 3.2. 5 International Summer School – 2009 ................................................................... 21 4. Task 3.3: HiPEAC Journal ............................................................................................ 22 5. Task 3.4: HiPEAC Roadmap ........................................................................................ 23 6. Task 3.5: HiPEAC Newsletter ...................................................................................... -

In BLACK CLOCK, Alaska Quarterly Review, the Rattling Wall and Trop, and She Is Co-Organizer of the Griffith Park Storytelling Series
BLACK CLOCK no. 20 SPRING/SUMMER 2015 2 EDITOR Steve Erickson SENIOR EDITOR Bruce Bauman MANAGING EDITOR Orli Low ASSISTANT MANAGING EDITOR Joe Milazzo PRODUCTION EDITOR Anne-Marie Kinney POETRY EDITOR Arielle Greenberg SENIOR ASSOCIATE EDITOR Emma Kemp ASSOCIATE EDITORS Lauren Artiles • Anna Cruze • Regine Darius • Mychal Schillaci • T.M. Semrad EDITORIAL ASSISTANTS Quinn Gancedo • Jonathan Goodnick • Lauren Schmidt Jasmine Stein • Daniel Warren • Jacqueline Young COMMUNICATIONS EDITOR Chrysanthe Tan SUBMISSIONS COORDINATOR Adriana Widdoes ROVING GENIUSES AND EDITORS-AT-LARGE Anthony Miller • Dwayne Moser • David L. Ulin ART DIRECTOR Ophelia Chong COVER PHOTO Tom Martinelli AD DIRECTOR Patrick Benjamin GUIDING LIGHT AND VISIONARY Gail Swanlund FOUNDING FATHER Jon Wagner Black Clock © 2015 California Institute of the Arts Black Clock: ISBN: 978-0-9836625-8-7 Black Clock is published semi-annually under cover of night by the MFA Creative Writing Program at the California Institute of the Arts, 24700 McBean Parkway, Valencia CA 91355 THANK YOU TO THE ROSENTHAL FAMILY FOUNDATION FOR ITS GENEROUS SUPPORT Issues can be purchased at blackclock.org Editorial email: [email protected] Distributed through Ingram, Ingram International, Bertrams, Gardners and Trust Media. Printed by Lightning Source 3 Norman Dubie The Doorbell as Fiction Howard Hampton Field Trips to Mars (Psychedelic Flashbacks, With Scones and Jam) Jon Savage The Third Eye Jerry Burgan with Alan Rifkin Wounds to Bind Kyra Simone Photo Album Ann Powers The Sound of Free Love Claire -

A Compiler-Compiler for DSL Embedding
A Compiler-Compiler for DSL Embedding Amir Shaikhha Vojin Jovanovic Christoph Koch EPFL, Switzerland Oracle Labs EPFL, Switzerland {amir.shaikhha}@epfl.ch {vojin.jovanovic}@oracle.com {christoph.koch}@epfl.ch Abstract (EDSLs) [14] in the Scala programming language. DSL devel- In this paper, we present a framework to generate compil- opers define a DSL as a normal library in Scala. This plain ers for embedded domain-specific languages (EDSLs). This Scala implementation can be used for debugging purposes framework provides facilities to automatically generate the without worrying about the performance aspects (handled boilerplate code required for building DSL compilers on top separately by the DSL compiler). of extensible optimizing compilers. We evaluate the practi- Alchemy provides a customizable set of annotations for cality of our framework by demonstrating several use-cases encoding the domain knowledge in the optimizing compila- successfully built with it. tion frameworks. A DSL developer annotates the DSL library, from which Alchemy generates a DSL compiler that is built CCS Concepts • Software and its engineering → Soft- on top of an extensible optimizing compiler. As opposed to ware performance; Compilers; the existing compiler-compilers and language workbenches, Alchemy does not need a new meta-language for defining Keywords Domain-Specific Languages, Compiler-Compiler, a DSL; instead, Alchemy uses the reflection capabilities of Language Embedding Scala to treat the plain Scala code of the DSL library as the language specification. 1 Introduction A compiler expert can customize the behavior of the pre- Everything that happens once can never happen defined set of annotations based on the features provided by again. -

Class 2: Early Hominids
Earliest Hominins CHARLES J VELLA, PHD JULY 25 2018 This is latest theory of how Lucy died! We are Mammals 3 defining mammalian traits: hair, mammary glands, homeothermy Mammalian traits show an adaptation for adaptability Miocene era: 23 to 5 Ma, Warmer global period • Ape grade: Planet of the apes • Over 30 genera and 100 species of ape – compared with 6 today • Location: Africa and Eurasia Proconsul: 25 to 23 Ma, during Miocene; arboreal quadruped Primates • Larger body size • Larger brain • Complete stereoscopic vision • Longer gestation, infancy, life span • More k-selected (tend towards single offspring) • Greater dependency on learned behavior • More social Great Apes Bonobos and Chimps split ~1 Ma Superfamily: Hominoidea Gibbons, Gorillas, Orangutan, Chimpanzee, Human Greater encephalization (brain to body ratio) = smarter larger body, brachiation, social complexity, lack of tail Why did Newt Gingrich recommend this book to all new politicians? Detailed and thoroughly engrossing account of ape rivalries and coalitions. Machiavellianism: political behavior is rooted at a level of development that is below the cognitive and is as much instinctive as it is learned. de Waal 1982 De Waal: Machiavellian IQ Machiavelli's The Prince: Frans de Waal introduced the term 'Machiavellian Intelligence' to describe the social and political behavior of chimpanzees Social behaviors: reconciliation, alliance, and sabotage Tactical deception in primates: Vervet monkeys use false predator alarm calls to get extra food Chimpanzees use deception to mate with females belonging to alpha male Chimpanzee cultures • Chimp Cultures: shared behaviors in different communities: • pounding actions • fishing; • probing; • forcing • comfort behavior • miscellaneous exploitation of vegetation properties • exploitation of leaf properties; • grooming; • attention-getting. -

Final Program of CCC2020
第三十九届中国控制会议 The 39th Chinese Control Conference 程序册 Final Program 主办单位 中国自动化学会控制理论专业委员会 中国自动化学会 中国系统工程学会 承办单位 东北大学 CCC2020 Sponsoring Organizations Technical Committee on Control Theory, Chinese Association of Automation Chinese Association of Automation Systems Engineering Society of China Northeastern University, China 2020 年 7 月 27-29 日,中国·沈阳 July 27-29, 2020, Shenyang, China Proceedings of CCC2020 IEEE Catalog Number: CFP2040A -USB ISBN: 978-988-15639-9-6 CCC2020 Copyright and Reprint Permission: This material is permitted for personal use. For any other copying, reprint, republication or redistribution permission, please contact TCCT Secretariat, No. 55 Zhongguancun East Road, Beijing 100190, P. R. China. All rights reserved. Copyright@2020 by TCCT. 目录 (Contents) 目录 (Contents) ................................................................................................................................................... i 欢迎辞 (Welcome Address) ................................................................................................................................1 组织机构 (Conference Committees) ...................................................................................................................4 重要信息 (Important Information) ....................................................................................................................11 口头报告与张贴报告要求 (Instruction for Oral and Poster Presentations) .....................................................12 大会报告 (Plenary Lectures).............................................................................................................................14 -

A Complete Bibliography of Publications in the Proceedings of the VLDB Endowment
A Complete Bibliography of Publications in the Proceedings of the VLDB Endowment Nelson H. F. Beebe University of Utah Department of Mathematics, 110 LCB 155 S 1400 E RM 233 Salt Lake City, UT 84112-0090 USA Tel: +1 801 581 5254 FAX: +1 801 581 4148 E-mail: [email protected], [email protected], [email protected] (Internet) WWW URL: http://www.math.utah.edu/~beebe/ 13 April 2021 Version 1.59 Title word cross-reference * [2218]. -approximate [1221, 184]. -automorphism [249]. -center [1996]. -clique [2343, 2278]. -cliques [571]. -core [2188, 815, 1712, 1453]. (k;r) [1712]. ++ [624]. 3 [2239, 338, 1997]. + -DB [1088]. -gram [2141]. -grams [1002]. [1838]. 2 [1588]. [2467]. c [1221]. [184]. γ -graph [1647]. -hop [2009]. -means [1088]. K [624, 1691]. -nearest [1493, 1692]. [1453, 1493, 624, 29, 1913, 901, 373, 1692, -Nearest-Neighbor [87]. -partite [2346]. 1996, 1266, 1006, 2440, 1035, 2012, 1490, 21, -path [1081]. -ranks [1070]. -regret 198, 1222, 424, 1340, 959, 1443, 609, 1081, [1035, 1443]. -tree [2350, 596]. -trees [1288]. 1284, 1937, 86, 1691, 968, 2315, 27, 1231, 1800, -uncertainty [432]. 2188, 2343, 1836, 657, 1879, 785, 1819, 1899, 2270, 854, 666, 586, 520, 815, 1387, 2163, 811, 11g [110, 112, 283]. 12c [1780, 1374]. 1791, 2278, 1248, 372, 564, 1501, 87, 417, 1213, 1272, 49, 1036, 1070, 1503, 2170, 249]. 2.0 [126, 2079, 2113, 1158]. 2014 [1187]. 2R k∗ [2346]. k=2 [2009]. l [591]. L [1647]. n 1 [2305]. 2X [1506]. [2141, 1002]. r [571]. ρ [432]. s [2003, 2195]. t [2003, 2195]. 1 2 3X [54, 362]. -

(URMD) Grad Cohort Workshop
MARCH 16-17, 2018 SAN DIEGO GRAD Cohort UnderrepresentedURMD Minorities & Persons with Disabilities 2018 www.cra.org Dear Grad Cohort Participant, We welcome you to the 2018 CRA Grad Cohort Workshop for Underrepresented Minorities + Persons with Disabilities 2018 (URMD)! The next few days are filled with sessions where 25 senior computing researchers and professionals will be sharing their strategies and experiences to help increase GradCohort your graduate school and career success. There will also be plenty of opportunities to meet and network with these successful researchers as well as with graduate students from other universities. We hope that you will take the utmost advantage of this unique experience by actively participating in discussions, developing peer networks, and building mentoring relationships. Since this is the inaugural URMD Grad Cohort Workshop, we are especially interested in hearing your feedback about the program and the experience. Please take time to complete the evaluation form provided after the workshop. We want to learn what you liked and did not like, as well as any suggestions you might have for improving the event in subsequent years. The 2018 CRA-URMD Workshop is made possible through generous contributions by the Computing Research Association, National Science Foundation, AccessComputing, Whova, Google and Association for Computing Machinery. Please join us in thanking them for their kind support. We hope that you take home many new insights and connections from this workshop to help you succeed in -

Entrepreneurship Opportunities & Skills
Entrepreneurship Opportunities & Skills Kunle Olukotun Stanford University 2019 CRA URMD Grad Cohort Workshop Kunle Olukotun • Professor of EE and CS at Stanford since 1992 – Cadence Design endowed chair • Computer architecture and parallel computing • Pioneer in CMP (multicore) processor design – Stanford Hydra project • Parallel programming for all programmers – Director of Pervasive Parallelism Lab (PPL) – High-performance Domain Specific Languages (DSLs) • Data Analytics for What’s Next (DAWN) – Democratizing machine learning Academic Research and Startups • When you can’t find an industrial partner for your ideas make one • Technology transfer by PhD – Understand the initial market for your product (technology) – What is your unfair advantage – More robust technology than research prototypes – Cost of schedule slip is much worse – You don’t have much time for research at a start-up • Pick your team wisely – Technical team (lab partners?) – Management team (who is making decisions) – Cap table • Funding issues – Investors (smart vs. dumb) – Angels vs Venture Capital firms Startup Pros/Cons Pros Cons • Don’t have to convince existing company to change • Have to convince investors course (until exit) (repeatedly) • Have to build a whole company, not just a development team • Finance, sales, marketing, … • Limited resources • Impatient capital Afara WebSystems • Founded in 1999 – Height of internet boom – Large web sites running out of power and space – Goal: Revolutionize internet data centers (multi-B $ market) – Goal: Approach: 10x -

Gavin Selerie – Jumping the Limits
Jumping the Limits: the interaction of art forms at Black Mountain & beyond, including UK practice - Gavin Selerie I Fielding Dawson says Black Mountain “had no sides (literally). It was wide open in the mountain.”1 This is a useful reminder that physical space can influence or determine thought. It was significant that the kinds of exploration associated with the college occurred far from recognized centres of learning. You could call it the permission of outlaws, and Ed Dorn, a son of the Prairie, perhaps brings this to fruition with the cinematic-linguistic slides of Gunslinger. On the other hand, no space is definitive, and a key aspect of the Black Mountain community was its willingness to bring people in to work on projects for a limited period. The corollary of this is that skills or modes of inquiry were susceptible of translation to other spheres. Geographically, the dispersal, both before and after the closure of the college, was significant, allowing Bauhaus and related approaches to be taken up in other parts of North America, and finally circulated back to Europe. New York City had a particular cluster of Black Mountain-affiliated artists and San Francisco also, but the small community or individually focused endeavour could happen anywhere. Charles Olson returned to Gloucester but kept ideas afloat through correspondence, appearances in Berkeley, Vancouver and London, and via his two-year teaching stint at Buffalo. What links figures as disparate as the weaver Anni Albers, the writer Robert Creeley and the designer Buckminster Fuller? Olson, in an unsent letter of 1952, describes Black Mountain as an “assembly point of acts”.2 The key elements are a possibility for intersection and the physical shaping of ideas. -

THANK YOU the Page 2 May 24, 2018
THE TM 911 Franklin Street Weekly Newspaper Michigan City, IN 46360 Volume 34, Number 20 Thursday, May 24, 2018 TO THOSE WHO COURAGEOUSLY GAVE THEIR LIVES… AND THOSE WHO BRAVELY FIGHT TODAY… THANK YOU THE Page 2 May 24, 2018 THE 911 Franklin Street • Michigan City, IN 46360 219/879-0088 • FAX 219/879-8070 %HDFKHU&RPSDQ\'LUHFWRU\ e-mail: News/Articles - [email protected] 'RQDQG7RP0RQWJRPHU\ 2ZQHUV email: Classifieds - [email protected] http://www.thebeacher.com/ $QGUHZ7DOODFNVRQ (GLWRU 'UHZ:KLWH 3ULQW6DOHVPDQ PRINTED WITH Published and Printed by -DQHW%DLQHV ,QVLGH6DOHV&XVWRPHU6HUYLFH TM %HFN\:LUHEDXJK 7\SHVHWWHU'HVLJQHU Trademark of American Soybean Association THE BEACHER BUSINESS PRINTERS 5DQG\.D\VHU 3UHVVPDQ 'RUD.D\VHU %LQGHU\ Delivered weekly, free of charge to Birch Tree Farms, Duneland Beach, Grand Beach, Hidden Shores, Long Beach, Michiana Shores, Michiana MI and Shoreland Hills. The Beacher is also 0LNH%RUDZVNL+RSH&RVWHOOR&KHU\O-RSSHN 3URGXFWLRQ delivered to public places in Michigan City, New Buffalo, LaPorte and Sheridan Beach. -RKQ%DLQHV.DUHQ*HKU&KULV.D\VHU'HQQLV0D\EHUU\ 'HOLYHU\ Rewriting School History by Kayla Weiss “When that final buzzer sounded, and we knew we had won, I let out a breath I hadn’t realized I was keeping in until that moment.” The Lady Blazers, celebrating their state championship. File photo by Bob Wellinski In any year, clinching a berth in Indiana’s state basketball champion- ship is cause for celebration. Katie Collignon achieved something even more remarkable, guiding Marquette Catholic High School’s Lady Blazers to their first state title Feb. 24. They beat Class A No.