A Switching Dynamic Generalized Linear Model to Detect Abnormal Performances in Major League Baseball
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Fair Ball! Why Adjustments Are Needed
© Copyright, Princeton University Press. No part of this book may be distributed, posted, or reproduced in any form by digital or mechanical means without prior written permission of the publisher. CHAPTER 1 Fair Ball! Why Adjustments Are Needed King Arthur’s quest for it in the Middle Ages became a large part of his legend. Monty Python and Indiana Jones launched their searches in popular 1974 and 1989 movies. The mythic quest for the Holy Grail, the name given in Western tradition to the chal- ice used by Jesus Christ at his Passover meal the night before his death, is now often a metaphor for a quintessential search. In the illustrious history of baseball, the “holy grail” is a ranking of each player’s overall value on the baseball diamond. Because player skills are multifaceted, it is not clear that such a ranking is possible. In comparing two players, you see that one hits home runs much better, whereas the other gets on base more often, is faster on the base paths, and is a better fielder. So which player should rank higher? In Baseball’s All-Time Best Hitters, I identified which players were best at getting a hit in a given at-bat, calling them the best hitters. Many reviewers either disapproved of or failed to note my definition of “best hitter.” Although frequently used in base- ball writings, the terms “good hitter” or best hitter are rarely defined. In a July 1997 Sports Illustrated article, Tom Verducci called Tony Gwynn “the best hitter since Ted Williams” while considering only batting average. -

Insert Text Here
TROUT AT 1,000 CAREER GAMES On June 21st, Angels outfielder Mike Trout played in his 1,000th career game. Since making his debut July 8, 2011, the Millville, NJ native amassed a .308 (1,126/3,658) average with 216 doubles, 43 triples, 224 home runs, 617 RBI, 178 stolen bases and 754 runs scored during his first 1,000 games. Below you will find a summary of some of Trout’s accomplishments: His 224 career home runs were tied with Joe DiMaggio for 17th most all- MLB ALL-TIME LEADERS & THEIR time by an American Leaguer in their first 1,000 career games…MLB TOTALS AT 1,000 GAMES* home run leader, Barry Bonds, had 172 career home runs after his LEADER TROUT 1,000th career game. H PETE ROSE, 1,231 1,126 HR BARRY BONDS, 172 224 R RICKEY HENDERSON, 795 754 754 runs are the 20th most in Major League history by a player in their BB BARRY BONDS, 603 638 th TB HANK AARON, 2,221 2,100 first 1,000 career games and 14 in A.L. history…Trout scored more runs WAR BARRY BONDS, 50 60.8 in his first 1,000 career games than Stan Musial (746), Jackie Robinson * COURTESY OF ESPN (743), Willie Mays (719) and Frank Robinson (706), among others…Rickey Henderson, who has scored the most runs in Major League history, had 795 career runs at the time of his 1,000th career game. Trout has amassed 2,100 total bases, ranking 17th all-time by an PLAYERS WITH 480+ EXTRA-BASE HITS American Leaguer in their first 1,000 career games, ahead of Ken Griffey & 600 WALKS IN FIRST 1,000 G Jr. -

Baseball Math (Cont.)
Student Activity Sheet Baseball Math (cont.) Name:___________________________ Date:____________Per:_____________ If you have ever watched or played in a baseball game, you have probably noticed that there are a lot of numbers involved. Think for a moment about what it would be like to play without using numbers. It would seem pretty strange, wouldn’t it? For instance, how would you know how many outs there are, or how many runs were scored, or even who won? Baseball is packed full of numbers. Explore how numbers are used by completing the investigation that follows. Extra Bases The distance from home plate to first base and between all the bases on a major league baseball field is equal to 90 feet. 1. When you hit a double, how far do you have to run? _______________________________________________________________________________ _______________________________________________________________________________ 2. How much further is a triple than a single? _______________________________________________________________________________ _______________________________________________________________________________ 3. When you hit a home run, how many times longer is that than a single? _______________________________________________________________________________ _______________________________________________________________________________ 4. Write a number sentence showing that a double is 1/2 the distance of a home run. _______________________________________________________________________________ _______________________________________________________________________________ -
Using Mathematics and Statistics to Analyze Who Are the Great Sluggers in Baseball
ICOTS-7, 2006: Taylor and Krevisky USING MATHEMATICS AND STATISTICS TO ANALYZE WHO ARE THE GREAT SLUGGERS IN BASEBALL Randy Taylor Las Positas College, United States Steve Krevisky Middlesex Community College, United States [email protected] In this presentation, we share the results of statistical work that we have done over several years, in order to determine who are the best sluggers in the game of baseball in the US. Using z scores, we examined yearly home run and slugging average figures, so as to analyze which batters were the most SD’s above the mean. We used cutoffs of 200 at bats or 250 plate appearances before expansion, and increased this by about 5%, to account for the increased number of games played after the expansion in the early 1960s. Since real data are involved, we feel that this would be a very good application for students in a basic statistics class, and we will present various charts in the following discussion, and summarize our findings. This is a shortened version of what we have presented at numerous conferences in the US. Please let us know if you wish to see the full version of our paper! INDIVIDUAL YEAR HOME RUN RESULTS Gathering the statistics was much more time consuming than imagined. Data was obtained for all years 1920-2003 from The Sports Encyclopedia: Baseball 2004 by David S. Neft, Richard M. Cohen, and Michael L. Neft. This book contained all the information required, but the print was very small. It also used numbers to indicate players who were traded, which was important in counting players totals in both leagues if they played in both leagues. -

Sports Figures Price Guide
SPORTS FIGURES PRICE GUIDE All values listed are for Mint (white jersey) .......... 16.00- David Ortiz (white jersey). 22.00- Ching-Ming Wang ........ 15 Tracy McGrady (white jrsy) 12.00- Lamar Odom (purple jersey) 16.00 Patrick Ewing .......... $12 (blue jersey) .......... 110.00 figures still in the packaging. The Jim Thome (Phillies jersey) 12.00 (gray jersey). 40.00+ Kevin Youkilis (white jersey) 22 (blue jersey) ........... 22.00- (yellow jersey) ......... 25.00 (Blue Uniform) ......... $25 (blue jersey, snow). 350.00 package must have four perfect (Indians jersey) ........ 25.00 Scott Rolen (white jersey) .. 12.00 (grey jersey) ............ 20 Dirk Nowitzki (blue jersey) 15.00- Shaquille O’Neal (red jersey) 12.00 Spud Webb ............ $12 Stephen Davis (white jersey) 20.00 corners and the blister bubble 2003 SERIES 7 (gray jersey). 18.00 Barry Zito (white jersey) ..... .10 (white jersey) .......... 25.00- (black jersey) .......... 22.00 Larry Bird ............. $15 (70th Anniversary jersey) 75.00 cannot be creased, dented, or Jim Edmonds (Angels jersey) 20.00 2005 SERIES 13 (grey jersey ............... .12 Shaquille O’Neal (yellow jrsy) 15.00 2005 SERIES 9 Julius Erving ........... $15 Jeff Garcia damaged in any way. Troy Glaus (white sleeves) . 10.00 Moises Alou (Giants jersey) 15.00 MCFARLANE MLB 21 (purple jersey) ......... 25.00 Kobe Bryant (yellow jersey) 14.00 Elgin Baylor ............ $15 (white jsy/no stripe shoes) 15.00 (red sleeves) .......... 80.00+ Randy Johnson (Yankees jsy) 17.00 Jorge Posada NY Yankees $15.00 John Stockton (white jersey) 12.00 (purple jersey) ......... 30.00 George Gervin .......... $15 (whte jsy/ed stripe shoes) 22.00 Randy Johnson (white jersey) 10.00 Pedro Martinez (Mets jersey) 12.00 Daisuke Matsuzaka .... -
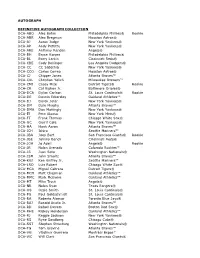
2021 Topps Definitive Collection BB Checklist.Xls
AUTOGRAPH DEFINITIVE AUTOGRAPH COLLECTION DCA-ABO Alec Bohm Philadelphia Phillies® Rookie DCA-ABR Alex Bregman Houston Astros® DCA-AJ Aaron Judge New York Yankees® DCA-AP Andy Pettitte New York Yankees® DCA-ARE Anthony Rendon Angels® DCA-BH Bryce Harper Philadelphia Phillies® DCA-BL Barry Larkin Cincinnati Reds® DCA-CBE Cody Bellinger Los Angeles Dodgers® DCA-CC CC Sabathia New York Yankees® DCA-CCO Carlos Correa Houston Astros® DCA-CJ Chipper Jones Atlanta Braves™ DCA-CKL Christian Yelich Milwaukee Brewers™ DCA-CMI Casey Mize Detroit Tigers® Rookie DCA-CR Cal Ripken Jr. Baltimore Orioles® DCA-DCA Dylan Carlson St. Louis Cardinals® Rookie DCA-DE Dennis Eckersley Oakland Athletics™ DCA-DJ Derek Jeter New York Yankees® DCA-DM Dale Murphy Atlanta Braves™ DCA-DMA Don Mattingly New York Yankees® DCA-EJ Pete Alonso New York Mets® DCA-FT Frank Thomas Chicago White Sox® DCA-GC Gerrit Cole New York Yankees® DCA-HA Hank Aaron Atlanta Braves™ DCA-ICH Ichiro Seattle Mariners™ DCA-JBA Joey Bart San Francisco Giants® Rookie DCA-JBE Johnny Bench Cincinnati Reds® DCA-JOA Jo Adell Angels® Rookie DCA-JR Nolan Arenado Colorado Rockies™ DCA-JS Juan Soto Washington Nationals® DCA-JSM John Smoltz Atlanta Braves™ DCA-KGJ Ken Griffey Jr. Seattle Mariners™ DCA-LRO Luis Robert Chicago White Sox® DCA-MCA Miguel Cabrera Detroit Tigers® DCA-MCH Matt Chapman Oakland Athletics™ DCA-MMC Mark McGwire Oakland Athletics™ DCA-MT Mike Trout Angels® DCA-NR Nolan Ryan Texas Rangers® DCA-OS Ozzie Smith St. Louis Cardinals® DCA-PG Paul Goldschmidt St. Louis Cardinals® DCA-RA Roberto Alomar Toronto Blue Jays® DCA-RAJ Ronald Acuña Jr. -

Socal Vs. Nocal? No Contest the Best Rivalry in Sports Heats Up
SoCal vs. NoCal? No Contest The Best Rivalry in Sports Heats Up By Chris Brown and Casey Shearer It s the latter half of September, which means the fall breezes are blowing and the leaves are changing. The smell of hot-dogs and stale beer is in the air; everybody wants peanuts and Crackerjacks; children run home from school and head to the sandlot. All of which are symptoms of pennant fever. Or at least they should be. But as we look around, nobody seems to care about baseball at all. In what is usually the most exciting time of the year for baseball fans, that special excitement is somehow absent. Even as Mark McGwire and Ken Griffey Jr. chase Babe Ruth and Roger Maris, and Larry Walker chases the triple crown, something is missing: What's missing, kosher hot-dogs? A players? strike? Roy Hobbs? Steve Howe and his crack? The Cubbies? Has baseball become so unpopular so as to lose the interest of all its fans? Is it just that baseball lacks that type of hype, flashy color and big-money that basketball purports or the bone crushing thrills of football? No, what's missing are those heated races that lead to a bad case of pennant fever. With less than two weeks remaining in the season, the playoff picture is all but set in stone. In the American League, Baltimore owns the East, Cleveland looks to have the Central wrapped up, Seattle should win the West barring a major collapse, and the Bronx Bombers have sewn up the wild card. -

Baseball Statistics in the Steroids Era
BASEBALL STATISTICS IN THE STEROIDS ERA _________________________ By John Dechant _________________________ A THESIS Submitted to the faculty of the Graduate School of the Creighton University in Partial Fulfillment of the Requirements for the degree of Master of the Arts in the Department of Liberal Studies. _________________________ OMAHA, NEBRASKA JUNE 27, 2008 iii Abstract This thesis examines the presence of steroids and performance enhancing substances in Major League Baseball from approximately 1988 to 2008. This period, informally known as the “steroids era,” has been the source of great controversy in recent years as more and more information on the matter has been disclosed to the public. In particular, this discussion focuses on the records and statistics of this era. In addition to the players who achieved these statistics, these numbers should be under great scrutiny as their validity is questioned. CONTENTS PREFACE………………………………………………………………………………iv INTRODUCTION……………………………………………………………………….1 Chapter ONE HISTORICAL PATTERNS OF STEROID USE IN BASEBALL………5 The Nature of Performance Enhancing Substances………………5 Early Signs of Steroid Use in Major League Baseball…………....8 Early Major League Baseball Steroid Policy…………………….12 Contemporary Steroid Use in Major League Baseball and the Evolution of Testing Policy……………………………..14 Congressional Intervention and the Mitchell Report…………….23 TWO ETHICAL CONSIDERATIONS OF STEROIDS IN BASEBALL……32 The Prohibition Debate………………………………………….32 Records and Statistics……………………………………………46 THREE *ASTERISKS AND DISTINGUISHING MARKS……………………..54 Problems of the Steroids Era…......................................................54 Precedents………………………………………………………..60 Asterisk…………………………………………………………..62 Era Divide………………………………………………………..65 Status Quo………………………………………………………..66 Assessment……………………………………………………….67 CONCLUSION…………………………………………………………………………..70 BIBLIOGRAPHY………………………………………………………………………..71 iv Preface My opinion of steroids and performance enhancing substances in baseball changed on February 13, 2008. -

A's News Clips, Friday, October 16, 2009 One of the Best Teams Ever
A’s News Clips, Friday, October 16, 2009 One of the best teams ever Bruce Jenkins, Chronicle Staff Writer Spring training brought its usual spirit of renewal in 1990, but it wasn't the same around the A's camp. In a sense, the ground was still trembling. Oakland had just won a World Series interrupted by earthquake, rendering more trivial matters insignificant against the burden of recovery. At the sight of Dave Stewart, you pictured him helping victims amid the rubble of the Nimitz Freeway. A glimpse of Terry Steinbach and you were back at Candlestick as he held his wife, Mary, so tightly on the field. Even the most notable game details seemed vague, to the point where the first two games (in Oakland) were - and remain - a virtual blank. This became the forgotten World Series, never to gain its proper recognition. Combine the fateful Oct. 17 with the latter-day stigma of steroids, and you have an A's team struggling for a place in history - although it's hardly a mystery in this corner. Without hesitation, I rank the '89 A's among the five greatest teams in history. Funny thing about those "top five" lists. They tend to expand, uncontrollably. Can a surfer really isolate his five best waves? Would a jazz aficionado be able to stop after naming five great sax solos? How about your five favorite songs, or movies? It's the top five, and it's 38-deep. In baseball, any such examination begins with the 1927 Yankees of Babe Ruth, Lou Gehrig and so many more. -

One for the Books: on Rhetoric, Community, and Memory
One for the Books: On Rhetoric, Community, and Memory ________________ Todd F. McDorman _______________ The 34th LaFollette Lecture October 10, 2013 _____________ www.wabash.edu/lafollette The Charles D. LaFollette Lecture Series One for the Books: On Rhetoric, Community, and Memory1 Todd F. McDorman PREFERRED CITATION McDorman, Todd F., “One for the Books: On Rhetoric, Community, and Memory.” The Charles D. LaFollette Lectures Series (2009): < http://www.wabash.edu/lafollette/mcdorman2013/> EXCERPT Classical liberal arts teaching and learning at its best is potent in helping us engage and interrogate the economies and ecologies of life-with-the-dead precisely because it serves as one of those few educational refuges, or haunts if you will, from the insistent pressures to reduce prudential teaching and learning to myopic, present-day utility, which in my mind equates with living alone and with no past. From classics to chemistry, music to mathematics, English to economics, the liberal arts bear witness to the enormous landscape of human experience and the potential for those who have passed on to continue to address vital present-day questions and truths, and, oh yes, to call us to account. __________ The LaFollette Lecture Series was established by the Wabash College Board of Trustees to honor Charles D. LaFollette, their longtime colleague on the Board. The lecture is given each year by a Wabash College Faculty member who is charged to address the relation of his or her special discipline to the humanities broadly conceived. For more information, contact Dwight Watson, LaFollette Professor of Humanities, Professor of Theater, Wabash College, Crawfordsville, IN 47933. -

First Day Covers
Name Postmark and Theme Rarity 500 Home Run Club-Mantle, Williams & More 500 HR Club with 13 Signatures-Stamped Twice-2/14/89 RARE Tom Seaver First No-Hitter 6/16/78 100 MADE! RARE Ryne Sandberg/Pete Rose Managerial Debut 8/17/84 RARE Joseph W. Sewell 1920 World Series 10/12/85 RARE Elmer Smith 1920 World Series 10/12/85 RARE George Uhle 1920 World Series 10/12/85 RARE Bill Wambsganss 1920 World Series 10/12/85 RARE Joe Wood 1920 World Series 10/12/85 RARE Florida Marlins Opening Day 9 Signatures from Team Members-4/5/93 Cal Ripken Jr. 2,131 GAMES 651/2131 (With Gehrig Stamp)-9/6/95 RARE Magic Johnson Coaching Debut-3/27/94 Nolan Ryan Last Game-9/22/93 RARE Nolan Ryan 5,714 Strikeouts-9/17/93 Mark Whiten Four Home Runs-9/8/93 Magic Johnson All-Star MVP 2/9/92 Ted Williams 50th Anniversary of Batting .400 9/28/91 RARE Bob Cousy & Bill Sharman Backcourt Duo 8/28/91 Larry Bird 100TH Anniversary 8/28/91 Bob Forsch RARE! No-Hitter 4/16/78 (Inlcudes No-Hitter Ticket Stub!!) EXTREMELY RARE 101 MADE Bert Blyleven 3,000 Strikeouts 8/1/86 Wally Joyner Rookie Selection 7/15/86 Rusty Staub "THANKS RUSTY" Day 7/13/86 Rusty Staub REFLECTIONS 7/13/86 Bob Horner 4 HOME RUNS 7/6/86 Don Sutton and Phil Niekro Pitching Duel 6/28/86 Don Sutton 300 WINS 6/18/86 Roger Clemens 20 STRIKEOUTS Clemens adds "20K" 4/29/86 Bret Saberhagen GAME 7 1985 WORLD SERIES 10/27/85 Charlie Leibrandt GAME 6 1985 WORLD SERIES 10/26/85 RARE Willie Wilson GAME 5 1985 WORLD SERIES 10/24/85 Reggie Jackson Mr. -
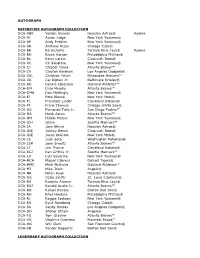
2020 Topps Definitive Collection Baseball Checklist
AUTOGRAPH DEFINITIVE AUTOGRAPH COLLECTION DCA-ABR Yordan Alvarez Houston Astros® Rookie DCA-AJ Aaron Judge New York Yankees® DCA-AP Andy Pettitte New York Yankees® DCA-AR Anthony Rizzo Chicago Cubs® DCA-BB Bo Bichette Toronto Blue Jays® Rookie DCA-BH Bryce Harper Philadelphia Phillies® DCA-BL Barry Larkin Cincinnati Reds® DCA-CC CC Sabathia New York Yankees® DCA-CJ Chipper Jones Atlanta Braves™ DCA-CK Clayton Kershaw Los Angeles Dodgers® DCA-CKL Christian Yelich Milwaukee Brewers™ DCA-CR Cal Ripken Jr. Baltimore Orioles® DCA-DE Dennis Eckersley Oakland Athletics™ DCA-DM Dale Murphy Atlanta Braves™ DCA-DMA Don Mattingly New York Yankees® DCA-EJ Pete Alonso New York Mets® DCA-FL Francisco Lindor Cleveland Indians® DCA-FT Frank Thomas Chicago White Sox® DCA-GS Fernando Tatis Jr. San Diego Padres™ DCA-HA Hank Aaron Atlanta Braves™ DCA-HM Hideki Matsui New York Yankees® DCA-ICH Ichiro Seattle Mariners™ DCA-JA Jose Altuve Houston Astros® DCA-JBE Johnny Bench Cincinnati Reds® DCA-JDE Jacob deGrom New York Mets® DCA-JS Juan Soto Washington Nationals® DCA-JSM John Smoltz Atlanta Braves™ DCA-JT Jim Thome Cleveland Indians® DCA-KGJ Ken Griffey Jr. Seattle Mariners™ DCA-LS Luis Severino New York Yankees® DCA-MCA Miguel Cabrera Detroit Tigers® DCA-MMC Mark McGwire Oakland Athletics™ DCA-MT Mike Trout Angels® DCA-NR Nolan Ryan Houston Astros® DCA-OS Ozzie Smith St. Louis Cardinals® DCA-RA Roberto Alomar Toronto Blue Jays® DCA-RAJ Ronald Acuña Jr. Atlanta Braves™ DCA-RD Rafael Devers Boston Red Sox® DCA-RH Rhys Hoskins Philadelphia Phillies® DCA-RJ Reggie