Performance Analysis of Optimization Techniques for SQL Multi Query Expressions Over Text Databases in RDBMS
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Evolution of Database Technology
Introduction and Database Technology By EM Bakker September 11, 2012 Databases and Data Mining 1 DBDM Introduction Databases and Data Mining Projects at LIACS Biological and Medical Databases and Data Mining CMSB (Phenotype Genotype), DIAL CGH DB Cyttron: Visualization of the Cell GRID Computing VLe: Virtual Lab e-Science environments DAS3/DAS4 super computer Research on Fundamentals of Databases and Data Mining Database integration Data Mining algorithms Content Based Retrieval September 11, 2012 Databases and Data Mining 2 DBDM Databases (Chapters 1-7): The Evolution of Database Technology Data Preprocessing Data Warehouse (OLAP) & Data Cubes Data Cubes Computation Grand Challenges and State of the Art September 11, 2012 Databases and Data Mining 3 DBDM Data Mining (Chapters 8-11): Introduction and Overview of Data Mining Data Mining Basic Algorithms Mining data streams Mining Sequence Patterns Graph Mining September 11, 2012 Databases and Data Mining 4 DBDM Further Topics Mining object, spatial, multimedia, text and Web data Mining complex data objects Spatial and spatiotemporal data mining Multimedia data mining Text mining Web mining Applications and trends of data mining Mining business & biological data Visual data mining Data mining and society: Privacy-preserving data mining September 11, 2012 Databases and Data Mining 5 [R] Evolution of Database Technology September 11, 2012 Databases and Data Mining 6 Evolution of Database Technology 1960s: (Electronic) Data collection, database creation, IMS -

Query Optimization Techniques - Tips for Writing Efficient and Faster SQL Queries
INTERNATIONAL JOURNAL OF SCIENTIFIC & TECHNOLOGY RESEARCH VOLUME 4, ISSUE 10, OCTOBER 2015 ISSN 2277-8616 Query Optimization Techniques - Tips For Writing Efficient And Faster SQL Queries Jean HABIMANA Abstract: SQL statements can be used to retrieve data from any database. If you've worked with databases for any amount of time retrieving information, it's practically given that you've run into slow running queries. Sometimes the reason for the slow response time is due to the load on the system, and other times it is because the query is not written to perform as efficiently as possible which is the much more common reason. For better performance we need to use best, faster and efficient queries. This paper covers how these SQL queries can be optimized for better performance. Query optimization subject is very wide but we will try to cover the most important points. In this paper I am not focusing on, in- depth analysis of database but simple query tuning tips & tricks which can be applied to gain immediate performance gain. ———————————————————— I. INTRODUCTION Query optimization is an important skill for SQL developers and database administrators (DBAs). In order to improve the performance of SQL queries, developers and DBAs need to understand the query optimizer and the techniques it uses to select an access path and prepare a query execution plan. Query tuning involves knowledge of techniques such as cost-based and heuristic-based optimizers, plus the tools an SQL platform provides for explaining a query execution plan.The best way to tune performance is to try to write your queries in a number of different ways and compare their reads and execution plans. -
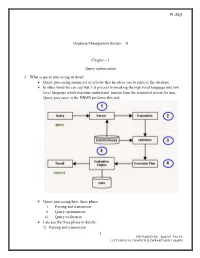
PL/SQL 1 Database Management System
PL/SQL Database Management System – II Chapter – 1 Query optimization 1. What is query processing in detail: Query processing means set of activity that involves you to retrieve the database In other word we can say that it is process to breaking the high level language into low level language which machine understand and perform the requested action for user. Query processor in the DBMS performs this task. Query processing have three phase i. Parsing and transaction ii. Query optimization iii. Query evaluation Lets see the three phase in details : 1) Parsing and transaction : 1 PREPARED BY: RAHUL PATEL LECTURER IN COMPUTER DEPARTMENT (BSPP) PL/SQL . Check syntax and verify relations. Translate the query into an equivalent . relational algebra expression. 2) Query optimization : . Generate an optimal evaluation plan (with lowest cost) for the query plan. 3) Query evaluation : . The query-execution engine takes an (optimal) evaluation plan, executes that plan, and returns the answers to the query Let us discuss the whole process with an example. Let us consider the following two relations as the example tables for our discussion; Employee(Eno, Ename, Phone) Proj_Assigned(Eno, Proj_No, Role, DOP) where, Eno is Employee number, Ename is Employee name, Proj_No is Project Number in which an employee is assigned, Role is the role of an employee in a project, DOP is duration of the project in months. With this information, let us write a query to find the list of all employees who are working in a project which is more than 10 months old. SELECT Ename FROM Employee, Proj_Assigned WHERE Employee.Eno = Proj_Assigned.Eno AND DOP > 10; Input: . -

An Overview of Query Optimization
An Overview of Query Optimization Why? Improving query processing time. Fast response is important in several db applications. Is it possible? Yes, but relative. A query can be evaluated in several ways. We can list all of them and then find the best among them. Sometime, we might not be able to do it because of the number of possible ways to evaluate the query is huge. We need to settle for a compromise: we try to find one that is reasonably good. Typical Query Evaluation Steps in DBMS. The DBMS has the following components for query evaluation: SQL parser, quey optimizer, cost estimator, query plan interpreter. The SQL parser accepts a SQL query and generates a relational algebra expression (sometime, the system catalog is considered in the generation of the expression). This expression is fed into the query optimizer, which works in conjunction with the cost estimator to generate a query execution plan (with hopefully a reasonably cost). This plan is then sent to the plan interpreter for execution. How? The query optimizer uses several heuristics to convert a relational algebra expression to an equivalent expres- sion which (hopefully!) can be computed efficiently. Different heuristics are (see explaination in textbook): (i) transformation between selection and projection; 1. Cascading of selection: σC1∧C2 (R) ≡ σC1 (σC2 (R)) 2. Commutativity of selection: σC1 (σC2 (R)) ≡ σC2 (σC1 (R)) 0 3. Cascading of projection: πAtts(R) = πAtts(πAtts0 (R)) if Atts ⊆ Atts 4. Commutativity of projection: πAtts(σC (R)) = σC (πAtts((R)) if Atts includes all attributes used in C. (ii) transformation between Cartesian product and join; 1. -

CMU 15-445/645 Database Systems (Fall 2018 :: Query Optimization
Query Optimization Lecture #13 Database Systems Andy Pavlo 15-445/15-645 Computer Science Fall 2018 AP Carnegie Mellon Univ. 2 ADMINISTRIVIA Mid-term Exam is on Wednesday October 17th → See mid-term exam guide for more info. Project #2 – Checkpoint #2 is due Friday October 19th @ 11:59pm. CMU 15-445/645 (Fall 2018) 4 QUERY OPTIMIZATION Remember that SQL is declarative. → User tells the DBMS what answer they want, not how to get the answer. There can be a big difference in performance based on plan is used: → See last week: 1.3 hours vs. 0.45 seconds CMU 15-445/645 (Fall 2018) 5 IBM SYSTEM R First implementation of a query optimizer. People argued that the DBMS could never choose a query plan better than what a human could write. A lot of the concepts from System R’s optimizer are still used today. CMU 15-445/645 (Fall 2018) 6 QUERY OPTIMIZATION Heuristics / Rules → Rewrite the query to remove stupid / inefficient things. → Does not require a cost model. Cost-based Search → Use a cost model to evaluate multiple equivalent plans and pick the one with the lowest cost. CMU 15-445/645 (Fall 2018) 7 QUERY PLANNING OVERVIEW System Catalog Cost SQL Query Model Abstract Syntax Annotated Annotated Tree AST AST Parser Binder Rewriter Optimizer (Optional) Name→Internal ID Query Plan CMU 15-445/645 (Fall 2018) 8 TODAY'S AGENDA Relational Algebra Equivalences Plan Cost Estimation Plan Enumeration Nested Sub-queries Mid-Term Review CMU 15-445/645 (Fall 2018) 9 RELATIONAL ALGEBRA EQUIVALENCES Two relational algebra expressions are equivalent if they generate the same set of tuples. -

Evolution of Database Technology 1960S: (Electronic) Data Collection, Database Creation, IMS (Hierarchical Database System by IBM) and Network DBMS
Database Technology Erwin M. Bakker & Stefan Manegold https://homepages.cwi.nl/~manegold/DBDM/ http://liacs.leidenuniv.nl/~bakkerem2/dbdm/ [email protected] [email protected] 9/21/18 Databases and Data Mining 1 Evolution of Database Technology 1960s: (Electronic) Data collection, database creation, IMS (hierarchical database system by IBM) and network DBMS 1970s: Relational data model, relational DBMS implementation 1980s: RDBMS, advanced data models (extended-relational, OO, deductive, etc.) Application-oriented DBMS (spatial, scientific, engineering, etc.) 9/21/18 Databases and Data Mining 2 Evolution of Database Technology 1990s: Data mining, data warehousing, multimedia databases, and Web databases 2000 - Stream data management and mining Data mining and its applications Web technology Data integration, XML Social Networks (Facebook, etc.) Cloud Computing global information systems Emerging in-house solutions In Memory Databases Big Data 9/21/18 Databases and Data Mining 3 1960’s Companies began automating their back-office bookkeeping in the 1960s COBOL and its record-oriented file model were the work-horses of this effort Typical work-cycle: 1. a batch of transactions was applied to the old-tape-master 2. a new-tape-master produced 3. printout for the next business day. COmmon Business-Oriented Language (COBOL 2002 standard) 9/21/18 Databases and Data Mining 4 COBOL A quote by Prof. dr. E.W. Dijkstra (Turing Award 1972) 18 June 1975: “The use of COBOL cripples the mind; its teaching should, therefore, be regarded as a criminal offence.” September 2015: 9/21/18 Databases and Data Mining 5 COBOL Code (just an example!) 01 LOAN-WORK-AREA. -
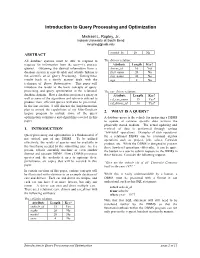
Introduction to Query Processing and Optimization
Introduction to Query Processing and Optimization Michael L. Rupley, Jr. Indiana University at South Bend [email protected] owned_by 10 No ABSTRACT All database systems must be able to respond to The drivers relation: requests for information from the user—i.e. process Attribute Length Key? queries. Obtaining the desired information from a driver_id 10 Yes database system in a predictable and reliable fashion is first_name 20 No the scientific art of Query Processing. Getting these last_name 20 No results back in a timely manner deals with the age 2 No technique of Query Optimization. This paper will introduce the reader to the basic concepts of query processing and query optimization in the relational The car_driver relation: database domain. How a database processes a query as Attribute Length Key? well as some of the algorithms and rule-sets utilized to cd_car_name 15 Yes* produce more efficient queries will also be presented. cd_driver_id 10 Yes* In the last section, I will discuss the implementation plan to extend the capabilities of my Mini-Database Engine program to include some of the query 2. WHAT IS A QUERY? optimization techniques and algorithms covered in this A database query is the vehicle for instructing a DBMS paper. to update or retrieve specific data to/from the physically stored medium. The actual updating and 1. INTRODUCTION retrieval of data is performed through various “low-level” operations. Examples of such operations Query processing and optimization is a fundamental, if for a relational DBMS can be relational algebra not critical, part of any DBMS. To be utilized operations such as project, join, select, Cartesian effectively, the results of queries must be available in product, etc. -

IBM Cloudant: Database As a Service Fundamentals
Front cover IBM Cloudant: Database as a Service Fundamentals Understand the basics of NoSQL document data stores Access and work with the Cloudant API Work programmatically with Cloudant data Christopher Bienko Marina Greenstein Stephen E Holt Richard T Phillips ibm.com/redbooks Redpaper Contents Notices . 5 Trademarks . 6 Preface . 7 Authors. 7 Now you can become a published author, too! . 8 Comments welcome. 8 Stay connected to IBM Redbooks . 9 Chapter 1. Survey of the database landscape . 1 1.1 The fundamentals and evolution of relational databases . 2 1.1.1 The relational model . 2 1.1.2 The CAP Theorem . 4 1.2 The NoSQL paradigm . 5 1.2.1 ACID versus BASE systems . 7 1.2.2 What is NoSQL? . 8 1.2.3 NoSQL database landscape . 9 1.2.4 JSON and schema-less model . 11 Chapter 2. Build more, grow more, and sleep more with IBM Cloudant . 13 2.1 Business value . 15 2.2 Solution overview . 16 2.3 Solution architecture . 18 2.4 Usage scenarios . 20 2.5 Intuitively interact with data using Cloudant Dashboard . 21 2.5.1 Editing JSON documents using Cloudant Dashboard . 22 2.5.2 Configuring access permissions and replication jobs within Cloudant Dashboard. 24 2.6 A continuum of services working together on cloud . 25 2.6.1 Provisioning an analytics warehouse with IBM dashDB . 26 2.6.2 Data refinement services on-premises. 30 2.6.3 Data refinement services on the cloud. 30 2.6.4 Hybrid clouds: Data refinement across on/off–premises. 31 Chapter 3. -

15-445/645 Database Systems (Fall 2020) Carnegie Mellon University Prof
Lecture #02: Intermediate SQL 15-445/645 Database Systems (Fall 2020) https://15445.courses.cs.cmu.edu/fall2020/ Carnegie Mellon University Prof. Andy Pavlo 1 Relational Languages Edgar Codd published a major paper on relational models in the early 1970s. Originally, he only defined the mathematical notation for how a DBMS could execute queries on a relational model DBMS. The user only needs to specify the result that they want using a declarative language (i.e., SQL). The DBMS is responsible for determining the most efficient plan to produce that answer. Relational algebra is based on sets (unordered, no duplicates). SQL is based on bags (unordered, allows duplicates). 2 SQL History Declarative query lanaguage for relational databases. It was originally developed in the 1970s as part of the IBM System R project. IBM originally called it “SEQUEL” (Structured English Query Language). The name changed in the 1980s to just “SQL” (Structured Query Language). The language is comprised of different classes of commands: 1. Data Manipulation Language (DML): SELECT, INSERT, UPDATE, and DELETE statements. 2. Data Definition Language (DDL): Schema definitions for tables, indexes, views, and other objects. 3. Data Control Language (DCL): Security, access controls. SQL is not a dead language. It is being updated with new features every couple of years. SQL-92 is the minimum that a DBMS has to support to claim they support SQL. Each vendor follows the standard to a certain degree but there are many proprietary extensions. 3 Aggregates An aggregation function takes in a bag of tuples as its input and then produces a single scalar value as its output. -

Query Optimization for Dynamic Imputation
Query Optimization for Dynamic Imputation José Cambronero⇤ John K. Feser⇤ Micah J. Smith⇤ Samuel Madden MIT CSAIL MIT CSAIL MIT LIDS MIT CSAIL [email protected] [email protected] [email protected] [email protected] ABSTRACT smaller than the entire database. While traditional imputation Missing values are common in data analysis and present a methods work over the entire data set and replace all missing usability challenge. Users are forced to pick between removing values, running a sophisticated imputation algorithm over a tuples with missing values or creating a cleaned version of their large data set can be very expensive: our experiments show data by applying a relatively expensive imputation strategy. that even a relatively simple decision tree algorithm takes just Our system, ImputeDB, incorporates imputation into a cost- under 6 hours to train and run on a 600K row database. based query optimizer, performing necessary imputations on- Asimplerapproachmightdropallrowswithanymissing the-fly for each query. This allows users to immediately explore values, which can not only introduce bias into the results, but their data, while the system picks the optimal placement of also result in discarding much of the data. In contrast to exist- imputation operations. We evaluate this approach on three ing systems [2, 4], ImputeDB avoids imputing over the entire real-world survey-based datasets. Our experiments show that data set. Specifically,ImputeDB carefully plans the placement our query plans execute between 10 and 140 times faster than of imputation or row-drop operations inside the query plan, first imputing the base tables. Furthermore, we show that resulting in a significant speedup in query execution while the query results from on-the-fly imputation differ from the reducing the number of dropped rows. -

Scalable Query Optimization for Efficient Data Processing Using
1 Scalable Query Optimization for Efficient Data Processing using MapReduce Yi Shan #1, Yi Chen 2 # School of Computing, Informatics, and Decision Systems Engineering, Arizona State University, Tempe, AZ, USA School of Management, New Jersey Institute of Technology, Newark, NJ, USA 1 [email protected] 2 [email protected] 1#*#!2_ Abstract—MapReduce is widely acknowledged by both indus- $0-+ --- try and academia as an effective programming model for query 5�# 0X0,"0X0,"0X0 processing on big data. It is crucial to design an optimizer which finds the most efficient way to execute an SQL query using Fig. 1. Query Q1 MapReduce. However, existing work in parallel query processing either falls short of optimizing an SQL query using MapReduce '8#/ '8#/ or the time complexity of the optimizer it uses is exponential. Also, industry solutions such as HIVE, and YSmart do not '8#/ optimize the join sequence of an SQL query and cannot guarantee '8#/ '8#/ '8#/ an optimal execution plan. In this paper, we propose a scalable '8#/ optimizer for SQL queries using MapReduce, named SOSQL. '8#/ Experiments performed on Google Cloud Platform confirmed '8#/ the scalability and efficiency of SOSQL over existing work. '8#/ '8#/ '8#/ '8#/ '8#/ (a) QP1 (b) QP2 I. INTRODUCTION Fig. 2. Query Plans of Query Q1 It becomes increasingly important to process SQL queries further generates a query execution plan consisting of three on big data. Query processing consists of two parts: query parallel jobs, one for each binary join operation, as illustrated optimization and query execution. The query optimizer first in Figure 3(a). -

Query Optimization
Query Optimization Query Processing: Query processing refers to activities including translation of high level languages (HLL) queries into operations at physical file level, query optimization transformations, and actual evaluation of queries. Steps in Query Processing: Function of query parser is parsing and translation of HLL query into its immediate form relation algebraic expression. A parse tree of the query is constructed and then translated in to relational algebraic expression. Example: consider the following SQL query: SELECT s.name FROM reserves R, sailors S Where R.sid=S.sid AND R.bid=100 And S.rating>5 Its corresponding relational algebraic expression Query Optimization : Query optimization is the process of selecting an efficient execution plan for evaluating the query. After parsing of the query, parsed query is passed to query optimizer, which generates different execution plans to evaluate parsed query and select the plan with least estimated cost. Catalog manager helps optimizer to choose best plan to execute query generating cost of each plan. Query optimization is used for accessing the database in an efficient manner. It is an art of obtaining desired information in a predictable, reliable and timely manner. Formally defines query optimization as a process of transforming a query into an equivalent form which can be evaluated more efficiently. The essence of query optimization is to find an execution plan that minimizes time needed to evaluate a query. To achieve this optimization goal, we need to accomplish two main tasks. First one is to find out the best plan and the second one is to reduce the time involved in executing the query plan.