Confidence As a Priority Signal 2 Authors: David Aguilar-Lleyda1*, Maxime Lemarchand1, Vincent De Gardelle2
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

8 Easy Games for English Olympics
8 Easy Games for English Olympics Figure 1 Photo of Flags Table 1 Guess the Flag Description: This game is a perfect way to learn about other countries in the world. Many students will already be familiar with countries and their flags, especially with the Olympic Games. But they may not know the English names for the countries. This game allows students to apply their background knowledge to English and have fun! Level: Beginner – Intermediate Materials: Cards with flags of countries (optional: write the names of the countries on the back of the cards) Directions: 1. Group students according to their country (teams of 4 students). 2. For each question, one student from each group will stand up. 3. The teacher will show a picture of a flag. The first standing student to raise their hand gets the chance to say the name of the flag’s country. If they are incorrect, a different student can answer. 4. If no standing students know the answer, the teacher can allow them to ask their group for help. 5. The team of the student who answers the question gets one point. 6. A different student must respond to each question. The same student cannot answer more than once until the entire group has participated. 7. The 3 teams with the most correct answers win a medal for their team (gold, silver, or bronze, respectively). 8 Easy Games for English Olympics Figure 2 Photo of Out of Order Sign Table 2 Out of Order! Description: This game tests students’ ability to take words and place them in the correct order to create a sentence. -

The Neural Bases of Argument Structure Processing Revealed by Primed Lexical Decision
cortex 57 (2014) 198e211 Available online at www.sciencedirect.com ScienceDirect Journal homepage: www.elsevier.com/locate/cortex Research report The neural bases of argument structure processing 5 revealed by primed lexical decision Donghoon Lee a, Benjamin Pruce b and Sharlene D. Newman b,* a Department of Psychology, Pusan National University, Busan, South Korea b Department of Psychological and Brain Sciences, Indiana University, Bloomington, IN, USA article info abstract Article history: Previous studies have reported anticipatory effects during sentence processing. However, Received 30 May 2013 the source of these effects has not been clearly characterized. This study investigated the Reviewed 22 July 2013 hypothesis that one source of anticipatory effects, particularly during verb processing, is Revised 8 January 2014 the automatic triggering of argument structure processes. If argument structure processes Accepted 21 April 2014 are automatically triggered it was hypothesized that the task need not require the initia- Action editor Stefano Cappa tion of the process, as such a primed lexical decision task was used that examined the Published online 9 May 2014 neural priming of cross-grammatical class prime pairs (e.g., verb-noun priming). While previous studies, as does the current study, have revealed behavioral priming for cross- Keywords: grammatical class and within-class (nounenoun and verbeverb) prime/target pairs, the Priming current results revealed significant activation differences. Enhancement effects were fMRI observed for cross-grammatical class priming in the language network, particularly the Argument structure inferior frontal gyrus (BA 47), and the posterior temporal cortex. Both regions have been linked to argument structure processing previously. Within-class priming resulted in neural suppression of the inferior temporal/occipital regions. -

Nouns Denoting More Than One Species : a Comparative Approach (English/French) Célia Hoffstetter
Nouns denoting more than one species : A comparative approach (English/French) Célia Hoffstetter To cite this version: Célia Hoffstetter. Nouns denoting more than one species : A comparative approach (English/French). Humanities and Social Sciences. 2013. dumas-02047901 HAL Id: dumas-02047901 https://dumas.ccsd.cnrs.fr/dumas-02047901 Submitted on 25 Feb 2019 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Ecole Normale Supérieure de Lyon NOUNS DENOTING MORE THAN ONE SPECIES : A COMPARATIVE APPROACH (E NGLISH /F RENCH ) Célia Hoffstetter Supervised by Laure Gardelle Table of contents Introduction ................................................................................................................................ 9 Chapter 1 .................................................................................................................................. 11 I. The classical approach to categorization ...................................................................... 11 1. Theoretical tenets .................................................................................................. -
View Unit 4: Cultural and Social Structures (PDF)
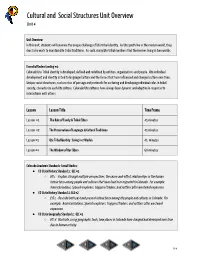
Cultural and Social Structures Unit Overview Unit 4 Unit Overview In this unit, students will examine the unique challenge of Ute tribal identity. As Ute youth live in the modern world, they must also work to maintain Ute tribal traditions. As such, many Ute tribal members find themselves living in two worlds. Essential Understanding #4: Colorado Ute Tribal identity is developed, defined and redefined by entities, organizations and people. Ute individual development and identity is tied to language/culture and the forces that have influenced and changed culture over time. Unique social structures, such as rites of passage and protocols for nurturing and developing individual roles in tribal society, characterize each Ute culture. Colorado Ute cultures have always been dynamic and adaptive in response to interactions with others. Lesson Lesson Title Time Frame Lesson #1 The Role of Family & Tribal Elders 45 minutes Lesson #2 The Preservation of Language & Cultural Traditions 45 minutes Lesson #3 Ute Tribal Identity : Living in 2 Worlds 45 minutes Lesson #4 The Wisdom of Our Elders 60 minutes Colorado Academic Standards-Social Studies: ● CO State History Standard 1: GLE #1 ○ EO.c. - Explain, through multiple perspectives, the cause-and-effect relationships in the human interactions among people and cultures that have lived in or migrated to Colorado. For example: American Indians, Spanish explorers, trappers/traders, and settlers after westward expansion. ● CO State History Standard 1: GLE #2 ○ E.O.c.- Describe both past and present interactions among the people and cultures in Colorado. For example: American Indians, Spanish explorers, trappers/traders, and settlers after westward expansion. -

Reading Foundations Skills Block
Language Arts Grades K–2: Reading Foundations Skills Block Resource Manual _ELED.00.SKILLS RESOURCE.indb 1 1/23/19 6:30 PM EL Education Language Arts Curriculum K–2 Reading Foundations Skills Block: Resource Manual EL Education Language Arts Curriculum is published by: EL Education 247 W. 35th Street, 8th Floor New York, NY 10001 www.ELeducation.org ISBN 978-1683625131 FIRST EDITION © 2016 EL Education Inc. Except where otherwise noted, EL Education’s Language Arts Curriculum is published under a Creative Commons Attribution 4.0 International (CC BY 4.0) License. To view a copy of this license, visit https://creativecommons.org/licenses/by/4.0/. Licensed third-party content noted as such in this curriculum is the property of the respective copyright owner, and not subject to the CC BY 4.0 License. Responsibility for securing any necessary permissions as to such third- party content rests with parties desiring to use such content. For example, certain third-party content may not be reproduced or distributed (outside the scope of fair use) without additional permissions from the content owner and it is the responsibility of the person seeking to reproduce or distribute this curriculum to either secure those permissions or remove the applicable content before reproduction or distribution. Common Core State Standards © Copyright 2010. National Governors Association Center for Best Practices and Council of Chief State School Officers. All rights reserved. Common Core State Standards are subject to the public license located at http://www.corestandards.org/public-license/. Cover art from “First Come the Eggs,” a project by third grade students at Genesee Community Charter School. -

Direct Pen Input and Hand Occlusion
Direct Pen Input and Hand Occlusion by Daniel Vogel A thesis submitted in conformity with the requirements for the degree of Doctor of Philosophy Department of Computer Science University of Toronto © Copyright 2010 Daniel Vogel Direct Pen Input and Hand Occlusion Daniel Vogel Doctor of Philosophy Department of Computer Science, University of Toronto 2010 Abstract We investigate, model, and design interaction techniques for hand occlusion with direct pen input. Our focus on occlusion follows from a qualitative and quantitative study of direct pen usability with a conventional graphical user interface (GUI). This study reveals overarching problems relating to poor precision, ergonomics, cognitive differences, limited input, and problems resulting from occlusion. To investigate occlusion more closely, we conduct three formal experiments to examine its area and shape, its affect on performance, and compensatory postures. We find that the shape of the occluded area varies across participants with some common characteristics. Our results provide evidence that occlusion affects target selection performance: especially for continuous tasks or when the goal is initially hidden. We observe how users contort their wrist posture during a simultaneous monitoring task, and show this can increase task time. Based on these investigations, we develop a five parameter geometric model to represent the shape of the occluded area and extend this to a user configurable, real-time version. To evaluate our model, we introduce a novel analytic testing methodology using optimization for geometric fitting and precision- recall statistics for comparison; as well as conducting a user study. To address problems with occlusion, we introduce the notion of occlusion-aware interfaces: techniques which can use ii our configurable model to track currently occluded regions and then counteract potential problems and/or utilize the occluded area. -

About Plural Morphology and Game Animals: from Old English to Present-Day English
Lexis Journal in English Lexicology 9 | 2015 Utterer-Centered Studies on Lexical Issues About Plural Morphology and Game Animals: from Old English to Present-Day English Fabienne Toupin Electronic version URL: http://journals.openedition.org/lexis/964 DOI: 10.4000/lexis.964 ISSN: 1951-6215 Publisher Université Jean Moulin - Lyon 3 Electronic reference Fabienne Toupin, « About Plural Morphology and Game Animals: from Old English to Present-Day English », Lexis [Online], 9 | 2015, Online since 13 May 2015, connection on 10 December 2020. URL : http://journals.openedition.org/lexis/964 ; DOI : https://doi.org/10.4000/lexis.964 Lexis is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License. Lexis 9: “Utterer‐centered studies on lexical issues” 95 About Plural Morphology and Game Animals: from Old English to Present‐Day English Fabienne Toupin1 Abstract My focus here will be on those animal names which never (e.G. deer) or occasionally (e.G. herring) take the ‐s suffix in the plural in Present‐Day English. After a detailed presentation of these names (§1), I will try to show (§2) that they form a lexical category in Guiraud’s sense, that is, a non‐arbitrary set of nouns with common features at the level both of the siGnified and of the siGnifier, and constituting, from a diachronic perspective, a matrix having enabled membership of the category to develop until today. I will then try to explain why this cateGory resisted analoGical extension of the ‐s plural marker, by bringing in the culture of AnGlo‐Saxon EnGland and the very special status of a Group of animals in the culture in question (§3). -

Writing Challenges
WRITING CHALLENGES Farm Animals Weekly Overview This week, we are learning about farm animals and will using our writing skills to help us. We are focussing a lot on sentence writing this week. When writing full sentences there is a lot to remember! You have to think of your idea, remember your sentence, listen to the sounds in words and remember to have a finger space after each word! WOW! This week we mainly want you to think about remembering your finger spaces, your adults can help out with all the other parts of the sentence. A finger space comes after each word. We need the space so that we can see where each word begins and ends- it makes reading your sentence so much easier. So warm up your finger space fingers- before writing your sentences give them a wiggle and stretch them out. To help you remember where to put them, it helps to count the words in your sentence- you can either count the words on an adults fingers or use something like a piece of pasta for each word and lay it out in a line. Every time you have written a word, get rid of the finger or pasta. Each time you do that, remember to use a finger space! Here are some exciting writing challenges WRITING CHALLENGES Lesson 1 - Who lives on the farm? Watch this video (click the picture) Can you draw a picture of a farm and draw some animals you might find there? Make sure you label the animals by listening to all the sounds you can hear. -

A Preliminary List of Animal Names in the Chuuk District, Micronesia with Some Notes on Plant Names
Micronesica 31(1):1-245, 1999 A Preliminary List of Animal Names in the Chuuk District, Micronesia with some notes on plant names Alan E. Davis1 1 Current Address: AAA196, Box 10001, Saipan, MP 96950, CNMI This list is dedicated to my children, Forrest LeRoy Eugene Davis, Timothy Davis, and Thomas Gotthelf Fischer Davis, Tian Taky Davis, and Dianne Eclipse Davis and to all other little boys and girls in Chuuk whose mothers and fathers do not understand one another very well. Revised from a technical report printed by the College of Mi- cronesia and the Micronesian Language Institute (UOG). °c 1996, 1999 Alan Eugene Davis °c 1996, 1999 College of Micronesia, Chuuk °c 1996, 1999 Micronesian Language Institute, University of Guam This document may be freely copied, on the condition that a copy of this notice is provided or else, for excerpts, that full acknowledgement is given of this source. Abstract—This is an unfinished list of animal names, including many unverified names, from dialects / languages commonly heard in Chuuk Lagoon, the Mortlock Islands, Hall Islands, Western Islands (Pattiw) and Nominweit´e,constituting the Eastern end of a chain of related dialects and cultures extending from Sonsorol and Tobi to Chuuk Lagoon. This list may emphasize a relatively small number of dialects; names are listed, however, from throughout the district. Animal names are ordered phylogenetically, divided into chapters according to broad classification. Chapters on sponges, coelenterates, worms, molluscs, crus- taceans, and insects and allies are divided into sections by category. Fishes are the subject of one large chapter, divided into sections by family. -

Hank's Handy Hammer
BB PoemAA of theWeekCC By Ellen Booth Church and Jerry Levine NEW YORK • TORONTO • LONDON • AUCKLAND • SYDNEY MEXICO CITY • NEW DELHI • HONG KONG • BUENOS AIRES ABC Poem of the Week © Ellen Booth Church, Scholastic Teaching Resources To our mothers, Francesca Church and Sarah Levine, whose love of words, books, and playful rhymes introduced us to the lifelong joy of reading. Thank you Mom. —Ellen Booth Church and Jerry Levine Scholastic Inc. grants teachers permission to photocopy the pages from this book for classroom use. No other part of this publication may be reproduced in whole or in part, or stored in a retrieval system, or transmitted in any form or by any means, electronic, mechanical, photocopying, recording, or otherwise, without permission of the publisher. For information regarding permission, write to Scholastic Inc., 557 Broadway, New York, NY 10012-3999 Front cover design by Norma Ortiz Interior design by Sydney Wright Cover and interior art by James Graham Hale ISBN 0-439-43115-8 Copyright © 2003 by Ellen Booth Church and Jerry Levine Published by Scholastic Inc. All rights reserved. Printed in the U.S.A. 1 2 3 4 5 6 7 8 9 10 40 09 08 07 06 05 04 03 ABC Poem of the Week © Ellen Booth Church, Scholastic Teaching Resources Contents Introduction . .4 The Letter Poems Amazing Active Astronauts . .7 Ball-Batting Baboons . .8 Cozy Carefree Camels . .9 Deep Diving Ducks . .10 Eggplants to Eat and Enjoy . .11 Four Feathery Falcons . .12 Gorgeous Galloping Gazelles . .13 Hank’s Handy Hammer . .14 Into Invisible Igloos . .15 Jiggly Jolly Jellyfish . -

Hualapai Reference Grammar
DOCUMENT RESUME ED 250 132 RC 015 014 AUTHOR Watahomigie, Lucille J.; And Others TITLE Hualapai Reference Grammar. INSTITUTION California Univ., Los Angeles. American Indian Studies Center.; Peach Springs School District #8, AZ. SPONS AGENCY American Philosophical Society, Philadelphia, Pa.; National Endowment for the Humanities (NFAH), Washington, D.C.; Office of Bilingual Education and Minority Languages Affairs (ED), Washington, D.C. REPORT NO ISBN-0-935626-07-7 PUB DATE 82 NOTE 599p. PUB TYPE Guides - Classroom Use Materials (For Learner) (051) -- Reference Materials - General (130) EDRS PRICE MF03/PC24 Plus Postage. , DESCRIPTORS *American Indian Languages; Function Words;*GriCmar; Morphemes; Nouns; Reference Materials; Resource Materials; *Sentence Structure; *Structural Grammar; Written Language ,- IDENTIFIERS *Hualapai; Yuman Languages ABSTRACT A first and modest beginning toward a grammar of the Hualapai language, a Pai branch of the Yuman language family, this reference book is intended for use by: the Hualapai people to reaffirm the vitality of their language; the Hualapai teachers in their preparation of language materials for teaching; younger Haulapais to find the regularity and complexity of the language; and the linguists and general public to see the richness of the Hualapai language. Consisting of six parts, the reference book: reviews how a writing system was selected for the Hualapai language; explains the alphabet used and how each letter is pronounced; discusses the basic structure of Hualapai sentences with attention to noun and verb usage; explains how different types of sentences are formed and what they mean; and presents a discussion on nouns and pronouns. Other information provided includes an analysis of verbs in detail, a discussion of verbal expressions, and an explanation of sound symbolism; types and formation of useful expressions (modal, habit and repetition, and degree) are discussed and ways in which sentences can be expanded into longer and more complex ones areexplained. -

Fly Times Issue 49, October 2012
FLY TIMES ISSUE 49, October, 2012 Stephen D. Gaimari, editor Plant Pest Diagnostics Branch California Department of Food & Agriculture 3294 Meadowview Road Sacramento, California 95832, USA Tel: (916) 262-1131 FAX: (916) 262-1190 Email: [email protected] Welcome to the latest issue of Fly Times! I thank everyone for sending in such interesting articles – I hope you all enjoy reading it as much as I enjoyed putting it together! Please let me encourage all of you to consider contributing articles that may be of interest to the Diptera community for the next Fly Times. We all greatly appreciate your contributions! Fly Times offers a great forum to report on your research activities and to make requests for taxa being studied, as well as to report interesting observations about flies, to discuss new and improved methods, to advertise opportunities for dipterists (one of which – a biggie – is the first article!), and to report on or announce meetings relevant to the community. This is also a great place to report on your interesting (and hopefully fruitful) collecting activities! Really anything fly-related is considered. I also want to thank Chris Borkent for putting together the list of Diptera citations since the last Fly Times – good job! The electronic version of the Fly Times continues to be hosted on the North American Dipterists Society website at http://www.nadsdiptera.org/News/FlyTimes/Flyhome.htm. The Diptera community would greatly appreciate your independent contributions to this newsletter. For this issue, I want to again thank all the contributors for sending me so many great articles! That said, we need even more reports on trips, collections, methods, updates, etc., with all the associated digital images you wish to provide.