5.4.1 Cornparison of Similarity Measure Methods
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Oracle Database Licensing Information, 11G Release 2 (11.2) E10594-26
Oracle® Database Licensing Information 11g Release 2 (11.2) E10594-26 July 2012 Oracle Database Licensing Information, 11g Release 2 (11.2) E10594-26 Copyright © 2004, 2012, Oracle and/or its affiliates. All rights reserved. Contributor: Manmeet Ahluwalia, Penny Avril, Charlie Berger, Michelle Bird, Carolyn Bruse, Rich Buchheim, Sandra Cheevers, Leo Cloutier, Bud Endress, Prabhaker Gongloor, Kevin Jernigan, Anil Khilani, Mughees Minhas, Trish McGonigle, Dennis MacNeil, Paul Narth, Anu Natarajan, Paul Needham, Martin Pena, Jill Robinson, Mark Townsend This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. If this is software or related documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, the following notice is applicable: U.S. GOVERNMENT END USERS: Oracle programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, delivered to U.S. Government end users are "commercial computer software" pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations. -

Third-Party License Acknowledgments
Symantec Privileged Access Manager Third-Party License Acknowledgments Version 3.4.3 Symantec Privileged Access Manager Third-Party License Acknowledgments Broadcom, the pulse logo, Connecting everything, and Symantec are among the trademarks of Broadcom. Copyright © 2021 Broadcom. All Rights Reserved. The term “Broadcom” refers to Broadcom Inc. and/or its subsidiaries. For more information, please visit www.broadcom.com. Broadcom reserves the right to make changes without further notice to any products or data herein to improve reliability, function, or design. Information furnished by Broadcom is believed to be accurate and reliable. However, Broadcom does not assume any liability arising out of the application or use of this information, nor the application or use of any product or circuit described herein, neither does it convey any license under its patent rights nor the rights of others. 2 Symantec Privileged Access Manager Third-Party License Acknowledgments Contents Activation 1.1.1 ..................................................................................................................................... 7 Adal4j 1.1.2 ............................................................................................................................................ 7 AdoptOpenJDK 1.8.0_282-b08 ............................................................................................................ 7 Aespipe 2.4e aespipe ........................................................................................................................ -
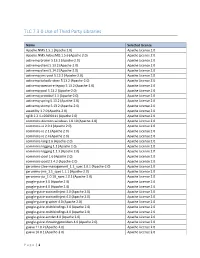
TLC 7.3.0 Use of Third Party Libraries
TLC 7.3.0 Use of Third Party Libraries Name Selected License Apache.NMS 1.5.1 (Apache 2.0) Apache License 2.0 Apache.NMS.ActiveMQ 1.5.6 (Apache 2.0) Apache License 2.0 activemq-broker 5.13.2 (Apache-2.0) Apache License 2.0 activemq-client 5.13.2 (Apache-2.0) Apache License 2.0 activemq-client 5.14.2 (Apache-2.0) Apache License 2.0 activemq-jms-pool 5.13.2 (Apache-2.0) Apache License 2.0 activemq-kahadb-store 5.13.2 (Apache-2.0) Apache License 2.0 activemq-openwire-legacy 5.13.2 (Apache-2.0) Apache License 2.0 activemq-pool 5.13.2 (Apache-2.0) Apache License 2.0 activemq-protobuf 1.1 (Apache-2.0) Apache License 2.0 activemq-spring 5.13.2 (Apache-2.0) Apache License 2.0 activemq-stomp 5.13.2 (Apache-2.0) Apache License 2.0 awaitility 1.7.0 (Apache-2.0) Apache License 2.0 cglib 2.2.1-v20090111 (Apache 2.0) Apache License 2.0 commons-daemon-windows 1.0.10 (Apache-2.0) Apache License 2.0 commons-io 2.0.1 (Apache 2.0) Apache License 2.0 commons-io 2.1 (Apache 2.0) Apache License 2.0 commons-io 2.4 (Apache 2.0) Apache License 2.0 commons-lang 2.6 (Apache-2.0) Apache License 2.0 commons-logging 1.1 (Apache 2.0) Apache License 2.0 commons-logging 1.1.3 (Apache 2.0) Apache License 2.0 commons-pool 1.6 (Apache 2.0) Apache License 2.0 commons-pool2 2.4.2 (Apache-2.0) Apache License 2.0 geronimo-j2ee-management_1.1_spec 1.0.1 (Apache-2.0) Apache License 2.0 geronimo-jms_1.1_spec 1.1.1 (Apache-2.0) Apache License 2.0 geronimo-jta_1.0.1B_spec 1.0.1 (Apache-2.0) Apache License 2.0 google-guice 3.0 (Apache 2.0) Apache License 2.0 google-guice 4.0 (Apache -

MARIMBA PROMOTES SIMON WYNN to CHIEF TECHNOLOGY OFFICER Submitted By: Axicom Monday, 30 April 2001
MARIMBA PROMOTES SIMON WYNN TO CHIEF TECHNOLOGY OFFICER Submitted by: AxiCom Monday, 30 April 2001 Arthur van Hoff to Head Newly-Formed Marimba Advanced Development Laboratory to Promote Technology Innovation Marimba, Inc, a leading provider of systems management solutions built for e-business, today announced the appointment of Simon Wynn to the post of chief technology officer (CTO), reporting directly to Marimba president and CEO, John Olsen. Mr. Wynn assumes the position from Arthur van Hoff, a co-founder of Marimba. Van Hoff, along with senior engineers and fellow co-founders, Sami Shaio and Jonathan Payne, will be part of Marimba's newly-formed Advanced Development Laboratory, and van Hoff will continue to report directly to Olsen. This distinguished team of engineers will focus on technology innovation designed to bring new, leading-edge products to market quickly. Van Hoff, Shaio and Payne are well known as original members of the Sun Microsystems Java team. As CTO, Wynn will be responsible for all technical aspects of Marimba's product vision, including software development, product deployment, strategic planning, new business opportunity assessment, as well as industry standards. "I am pleased to announce the promotion of Simon Wynn to the position of CTO, and we welcome him as a member of our executive team," said Olsen. "This appointment acknowledges Simon's past contributions and reflects his leadership role within the company. Simon has been instrumental in helping to secure Marimba's leadership position in the systems management market." Wynn previously held consecutive positions of director of engineering, engineering manager, and staff software engineer. -

Open Source Used in Cisco UCS Director 5.5
Open Source Used In Cisco UCS Director 5.5 Cisco Systems, Inc. www.cisco.com Cisco has more than 200 offices worldwide. Addresses, phone numbers, and fax numbers are listed on the Cisco website at www.cisco.com/go/offices. Text Part Number: 78EE117C99-116574787 Open Source Used In Cisco UCS Director 5.5 1 This document contains licenses and notices for open source software used in this product. With respect to the free/open source software listed in this document, if you have any questions or wish to receive a copy of any source code to which you may be entitled under the applicable free/open source license(s) (such as the GNU Lesser/General Public License), please contact us at [email protected]. In your requests please include the following reference number 78EE117C99-116574787 The product also uses the Linux operating system, Centos Full 6.7. Information on this distribution is available at http://vault.centos.org/6.7/os/Source/SPackages/. The full source code for this distribution, including copyright and license information, is available on request from [email protected]. Mention that you would like the Linux distribution source archive, and quote the following reference number for this distribution: 118610896-116574787. Contents 1.1 activemq-all 5.2.0 1.1.1 Available under license 1.2 Amazon AWS Java SDK 1.1.1 1.2.1 Available under license 1.3 ant 1.9.3 :2build1 1.3.1 Available under license 1.4 aopalliance version 1.0 repackaged as a module 2.3.0-b10 1.4.1 Available under license 1.5 Apache -

Internal and External Mechanisms for Extending Programming Languages
Internal and External Mechanisms for Extending Programming Languages Keren Lenz Technion - Computer Science Department - Ph.D. Thesis PHD-2013-03 - 2013 Technion - Computer Science Department - Ph.D. Thesis PHD-2013-03 - 2013 Internal and External Mechanisms for Extending Programming Languages Research Thesis Submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy Keren Lenz Submitted to the Senate of the Technion — Israel Institute of Technology Kislev 5773 Haifa November 2012 Technion - Computer Science Department - Ph.D. Thesis PHD-2013-03 - 2013 Technion - Computer Science Department - Ph.D. Thesis PHD-2013-03 - 2013 The research thesis was done under the supervision of Prof. Joseph (Yossi) Gil in the Computer Science Department. First and foremost, I would like to express my gratitude to my advisor, Prof. Yossi Gil. He has patiently guided me in my journey as a new researcher, providing me with valuable insights and practical guidance, as well as encouragement. I would like to thank my parents, Hava and Avishay Golz, for years of dedica- tion and devotion and mainly for bestowing me with education as a key principle since early age. Special thanks go to my brother, Omer, for his incredible support and help in parts of this research. Finally, I am indebted to my beloved husband Oron, for standing beside me every step of the way; and to my Children, Amit, Roy and Ido, for making me happy. The generous financial support of the Technion, the Harbor fund, and IBM’s PhD Fellowship program is gratefully acknowledged. Technion - Computer Science Department - Ph.D. Thesis PHD-2013-03 - 2013 Technion - Computer Science Department - Ph.D. -

What Is Javamail?
WHAT IS JAVAMAIL? TM The World’s Leading Java Resource Java COM Volume:4 Issue:10, October1999 Guaranteed Lowest Prices... From the Editor Holy Wars by Sean Rhody pg. 5 Guest Editorial Presenting Java by Ajit Sagar pg. 7 Straight Talking What an ‘L’ of a Month by Alan Williamson pg. 14 Feature: Ian Moraes E-Java JavaMail Palming Java Framework for developing by Ajit Sagar pg. 28 Internet-based e-mail client applications 8 EJB Home Cover Story: Creating Newsfeeds Using Java Applets John Keogh The Business Make the Internet more relevant, and give Advantage of EJB by Jason Westra pg. 58 your customers better—faster—service 18 CORBA Corner Feature: What Is JavaMail? Rachel Gollub What’s Coming By now you might be asking yourself... 32 in CORBA 3? by Jon Siegel pg. 68 Case History: Enterprise Java at Syracuse University Frank Gates IMHO Distributed applications written in Java using the SIS EJB SIS HTML Web EJB Interface Student Browser Application Interface Server Information Server Calls H Server Manager System T t M le SIS Java OOP Means L or App Interface EJB model to build reliable and scalable systems Server 44 J SIS DB C C Interface alls Server Database OODBMS—Not SIS Server Interface Server by Bruce Scott pg. 94 Widget Factory: A Return to Reflection Jim Crafton RETAILERS PLEASE DISPLAY UNTIL DECEMBER 31, 1999 Adding advanced features to the CodeDocument class à la Borland’s CodeInsight 50 SYS-CON Radio: JavaOne Interviews with Grant Wood & Daniel Berg, and Martin Hardee 64 Product Review: SQL 2000 v7.5 Jim Milbery SYS -CON Pervasive -

Java Bytecode to Native Code Translation: the Caffeine Prototype and Preliminary Results
Java Bytecode to Native Code Translation: The Caffeine Prototype and Preliminary Results Cheng-Hsueh A. Hsieh John C. Gyllenhaal Wen-mei W. Hwu Center for Reliable and High-Performance Computing University of Illinois Urbana-Champaign, IL 61801 ada, gyllen, [email protected] Abstract exists behind efforts to create such a software distribution language. The progress, however, has been very slow due to The Java bytecode language is emerging as a software legal and technical difficulties. distribution standard. With major vendors committed to On the legal side, many software vendors have been porting the Java run-time environment to their platforms, skeptical about the ability of the proposed software distribution programs in Java bytecode are expected to run without languages to protect their intellectual property. In practice, modification on multiple platforms. These first generation run- such concern may have to be addressed empirically after a time environments rely on an interpreter to bridge the gap standard emerges. Although the protection of intellectual between the bytecode instructions and the native hardware. property in software distribution languages is an intriguing This interpreter approach is sufficient for specialized issue, it is not the topic addressed by this paper. For the applications such as Internet browsers where application purpose of our work, we expect Java to be accepted by a performance is often limited by network delays rather than sufficient number of software vendors in the near future to processor speed. It is, however, not sufficient for executing make our work relevant. general applications distributed in Java bytecode. This paper On the technical side, the performance of programs presents our initial prototyping experience with Caffeine, an distributed in a universal software distribution language has optimizing translator from Java bytecode to native machine been a major concern. -

Bab Ii Tinjauan Pustaka
8 BAB II TINJAUAN PUSTAKA 2.1 SEJARAH PT. PELABUHAN INDONESIA CABANG TANJUNG PERAK Dalam lingkup ini akan dijelaskan tentang lokasi, profil PT. PELABUHAN INDONESIA CABANG TANJUNG PERAK dengan menjelaskan Visi dan misi .Sumber : (perakport, 2011 ) 2.1.1 PROFIL PT. PELABUHAN INDONESIA CABANG TANJUNG PERAK Tanjung Perak merupakan salah satu pintu gerbang Indonesia, yang berfungsi sebagai kolektor dan distributor barang dari dan ke Kawasan Timur Indonesia, termasuk propinsi Jawa Timur. Karena letaknya yang strategis dan didukung oleh hinterland yang potensial maka pelabuhan Tanjung Perak juga merupakan Pusat Pelayanan Interinsulair Kawasan Timur Indonesia. Dahulu kapal-kapal samudera membongkar dan memuat barang- barangnya di selat Madura untuk kemudian dengan tongkang dan perahu-perahu dibawa ke Jembatan Merah (pelabuhan pertama waktu itu), yang berada di jantung kota Surabaya melalui sungai Kalimas. Karena perkembangan lalu lintas perdagangan dan peningkatan arus barang serta bertambahnya arus transportasi maka fasilitas dermaga di Jembatan Merah itu akhirnya tidak mencukupi. Kemudian pada tahun 1875 Ir.W.de Jongth menyusun rencana pembangunan Pelabuhan Tanjung Perak agar dapat memberikan pelayanan kepada kapal-kapal samudera membongkar dan memuat 8 Hak Cipta © milik UPN "Veteran" Jatim : Dilarang mengutip sebagian atau seluruh kHak Cipta © milik UPN "Veteran" Jatim : Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan dan menyebutkan sumber.arya tulis ini tanpa mencantumkan dan menyebutkan sumber. 9 secara langsung tanpa melalui tongkang-tongkang dan perahu-perahu. Akan tetapi rencana ini kemudian ditolak karena biayanya sangat tinggi. Selama abad 19 tidak ada pembangunan fasilitas pelabuhan, padahal lalu lintas angkutan barang ke Jembatan Merah terus meningkat. Sementara rencana pembangunan pelabuhan yang disusun Ir.W.de.Jongth dibiarkan terlantar. -

Lenguajes De Programación
LENGUAJES DE PROGRAMACIÓN (Sesión 4) 2. PROGRAMACIÓN ORIENTADA A OBJETOS 2.3. El lenguaje de programación Java 2.4. Otros lenguajes orientados a objetos Objetivo: Comparar la estructura general de JAVA con algunos otros lenguajes de programación también orientados a objetos. Paradigma: Orientado a objetos Apareció en: 1991 Diseñado Sun Microsystems Tipo de dato: Fuerte, Estático Implementacio Numerosas Influido por: Objective-C, C++, Ha influido a: C#, J#, JavaScript,PHP Sistema Multiplataforma Licencia de GNU GPL / Java Java es un lenguaje de programación orientado a objetos desarrollado por Sun Microsystems a principios de los años 90. El lenguaje en sí mismo toma mucha de su sintaxis de C y C++, pero tiene un modelo de objetos más simple y elimina herramientas de bajo nivel, que suelen inducir a muchos errores, como la manipulación directa de punteros o memoria. Las aplicaciones Java están típicamente compiladas en un bytecode, aunque la compilación en código máquina nativo también es posible. En el tiempo de ejecución, el bytecode es normalmente interpretado o compilado a código nativo para la ejecución, aunque la ejecución directa por hardware del bytecode por un procesador Java también es posible. La implementación original y de referencia del compilador, la máquina virtual y las bibliotecas de clases de Java fueron desarrolladas por Sun Microsystems en 1995. Desde entonces, Sun ha controlado las especificaciones, el desarrollo y evolución del lenguaje a través del Java Community Process, si bien otros han desarrollado también implementaciones -

R&S ETC / ETH Open Source Acknowledgment
R&S®ETC / ETH Compact / Handheld TV Analyzer Open Source Acknowledgment This document is valid for the following Rohde & Schwarz instruments: ● R&S®ETC04 ● R&S®ETC08 ● R&S®ETH04 ● R&S®ETH08 ● R&S®ETH14 ● R&S®ETH18 (E@Ýa2) 2116.7949.02 ─ 02 Broadcast and Media Open Source Acknowledgment R&S®ETC / ETH Contents Contents 1 Introduction............................................................................................ 4 1.1 Disclaimer...................................................................................................................... 4 1.2 How to obtain the source code ...................................................................................4 2 Software packages.................................................................................5 3 Verbatim license texts........................................................................... 7 3.1 OpenSSL / SSLeay License..........................................................................................7 3.2 Boost Software License, Version 1.0.......................................................................... 9 3.3 Sun RPC License (Sun RPC)........................................................................................9 3.4 GNU MP Library License............................................................................................ 10 3.5 GNU Lesser General Public License, Version 3 (LGPL 3).......................................12 3.6 GNU General Public License, Version 3 (GPL 3)......................................................14 -

Hooked on Java
A r Hooked on Java Creating Hot Web Sites with Java Applets Arthur van Hoff, Sami Shaio, and Orca Starbuck Sun Microsystems, Inc. Technische Hochschule Darmstadt FACHBEREICH INFORMATIK B1BL1OTHEK Inventar-Nr.: h.%.T...Q.Q.X.iA Sachgebieta: Standort: Fachbereichsbibliothek Informatik TU Darmstadt A •T 8 Addison-Wesley Publishing Company Reading, Massachusetts • Menlo Park, California • New York Don Mills, Ontario • Wokingham, England • Amsterdam Bonn • Sydney • Singapore • Tokyo • Madrid • San Juan Paris • Seoul • Milan • Mexico City • Taipei t Contents List of Figures ix Acknowledgments xiii Introduction xv 1. Introducing Java and Java Applets 1 What IS Java? 1 Plug-n-Play Applets 3 You and Java 4 2. Java and the Internet 5 Java History 5 The Java Programming Language 10 Java and the Internet 16 The Future of Java 18 3. Applets Explained 21 Java Applets 21 Adding an Applet to your Home Page 26 Java Applet Tools 29 Applets Basics 35 vi CONTENTS 4. Cool Applets 41 Overview 41 Sample Applet Description 44 Legend 45 Abacus 46 Animator 47 Audioltem 49 Ballistic Simulator 50 Bar Chart 51 Bar Graph 53 Blinking Text 56 Bouncing Heads 57 Clock 58 Crossword Puzzle 59 Dining Philosophers 60 Escher Paint 61 Graph Layout 62 ImageLoop 64 ImageMap 65 LED Sign 68 Line Graph 70 Link Button 72 Molecule Viewer 73 Neon Sign 75 Nervous Text 76 Nuclear Powerplant 77 Pythagoras' Theorem 78 Scrolling Images 79 Spreadsheet 81 Tic-Tac-Toe 82 TumblingDuke 83 Under Construction 84 Voltage Circuit Simulator 85 What's New! 86 Wire Frame Viewer 87 Zine 89 5. Java in Depth 93 Hello World 93 Overview of Java Syntax 94 Objects and Classes 101 Class Inheritance 105 Interfaces 109 CONTENTS vii Packages 110 Exceptions 111 Threads 114 Monitors and Synchronization 116 Programming with Java 120 6.