Alternative Formats If You Require This Document in an Alternative Format, Please Contact: [email protected]
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

To Download the PDF File
Reproductive Anxiety: Reconfiguring the Human in Virtual Culture by John Shiga, B.A., M.A. A thesis submitted to the Faculty of Graduate Studies and Research in partial fulfillment of the requirements for the degree of Doctor of Philosophy School of Journalism & Communication Carleton University Ottawa, Canada © 2009, John P. Shiga Library and Archives Bibliotheque et 1*1 Canada Archives Canada Published Heritage Direction du Branch Patrimoine de I'edition 395 Wellington Street 395, rue Wellington OttawaONK1A0N4 Ottawa ON K1A 0N4 Canada Canada Your file Votre reference ISBN: 978-0-494-60120-4 Our file Notre reference ISBN: 978-0-494-60120-4 NOTICE: AVIS: The author has granted a non L'auteur a accorde une licence non exclusive exclusive license allowing Library and permettant a la Bibliotheque et Archives Archives Canada to reproduce, Canada de reproduire, publier, archiver, publish, archive, preserve, conserve, sauvegarder, conserver, transmettre au public communicate to the public by par telecommunication ou par I'lnternet, preter, telecommunication or on the Internet, distribuer et vendre des theses partout dans le loan, distribute and sell theses monde, a des fins commerciales ou autres, sur worldwide, for commercial or non support microforme, papier, electronique et/ou commercial purposes, in microform, autres formats. paper, electronic and/or any other formats. The author retains copyright L'auteur conserve la propriete du droit d'auteur ownership and moral rights in this et des droits moraux qui protege cette these. Ni thesis. Neither the thesis nor la these ni des extraits substantiels de celle-ci substantial extracts from it may be ne doivent etre imprimes ou autrement printed or otherwise reproduced reproduits sans son autorisation. -
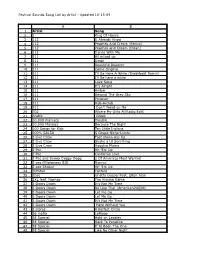
FS Master List-10-15-09.Xlsx
Festival Sounds Song List by Artist - Updated 10-15-09 A B 1 Artist Song 2 1 King Of House 3 112 U Already Know 4 112 Peaches And Cream (Remix) 5 112 Peaches and Cream [Clean] 6 112 Dance With Me 7 311 All mixed up 8 311 Down 9 311 Beautiful Disaster 10 311 Come Original 11 311 I'll Be Here A While (Breakbeat Remix) 12 311 I'll Be here a while 13 311 Love Song 14 311 It's Alright 15 311 Amber 16 311 Beyond The Grey Sky 17 311 Prisoner 18 311 Rub-A-Dub 19 311 Don't Tread on Me 20 702 Where My Girls At(Radio Edit) 21 Arabic Greek 22 10,000 maniacs Trouble 23 10,000 Maniacs Because The Night 24 100 Songs for Kids Ten Little Indians 25 100% SALSA S Grupo Niche-Lluvia 26 2 Live Crew Face Down Ass Up 27 2 Live Crew Shake a Lil Somthing 28 2 Live Crew Hoochie Mama 29 2 Pac Hit 'Em Up 30 2 Pac California Love 31 2 Pac and Snoop Doggy Dogg 2 Of Americas Most Wanted 32 2 pac f/Notorious BIG Runnin' 33 2 pac Shakur Hit 'Em Up 34 20thfox Fanfare 35 2pac Ghetto Gospel Feat. Elton John 36 2XL feat. Nashay The Kissing Game 37 3 Doors Down It's Not My Time 38 3 Doors Down Be Like That (AmericanPieEdit) 39 3 Doors Down Let me Go 40 3 Doors Down Let Me Go 41 3 Doors Down It's Not My Time 42 3 Doors Down Here Without You 43 3 Libras A Perfect Circle 44 36 mafia Lollipop 45 38 Special Hold on Loosley 46 38 Special Back To Paradise 47 38 Special If Id Been The One 48 38 Special Like No Other Night Festival Sounds Song List by Artist - Updated 10-15-09 A B 1 Artist Song 49 38 Special Rockin Into The Night 50 38 Special Saving Grace 51 38 Special Second Chance 52 38 Special Signs Of Love 53 38 Special The Sound Of Your Voice 54 38 Special Fantasy Girl 55 38 Special Caught Up In You 56 38 Special Back Where You Belong 57 3LW No More 58 3OH!3 Don't Trust Me 59 4 Non Blondes What's Up 60 50 Cent Just A Lil' Bit 61 50 Cent Window Shopper (Clean) 62 50 Cent Thug Love (ft. -

Radio 4 Extra Listings for 15 – 21 May 2021 Page 1 of 10 SATURDAY 15 MAY 2021 Producer: Jill Waters Comedy Chat Show About Shame and Guilt
Radio 4 Extra Listings for 15 – 21 May 2021 Page 1 of 10 SATURDAY 15 MAY 2021 Producer: Jill Waters comedy chat show about shame and guilt. First broadcast on BBC Radio 4 in June 1998. Each week Stephen invites a different eminent guest into his SAT 00:00 Planet B (b00j0hqr) SAT 03:00 Mrs Henry Wood - East Lynne (m0006ljw) virtual confessional box to make three 'confessions' are made to Series 1 5. The Yearning of a Broken Heart him. This is a cue for some remarkable storytelling, and 5. The Smart Money No sooner has Lady Isabel been betrayed by the wicked Francis surprising insights. John and Medley are transported to a world of orgies and Levison than she is left unrecognisably disfigured by a terrible We’re used to hearing celebrity interviews where stars are circuses, where the slaves seek a new leader. train crash. persuaded to show off about their achievements and talk about Ten-part series about a mystery virtual world. What is to become of her? their proudest moments. Stephen isn't interested in that. He Written by Paul May. Mrs Henry Wood's novel dramatised by Michael Bakewell. doesn’t want to know what his guests are proud of, he wants to John ...... Gunnar Cauthery Mrs Henry Wood ... Rosemary Leach know what makes them ashamed. That’s surely the way to find Lioba ...... Donnla Hughes Lady Isabel ... Moir Leslie out what really makes a person tick. Stephen and his guest Medley ...... Lizzy Watts Mr Carlyle ... David Collings reflect with empathy and humour on things like why we get Cerberus ..... -

Wv • 1 Music Week GEORGE MICHAEL SONGS from the LAST CENTURY
FOR EVERYONE IN THE BUSINESS OF MUSIC £360 ■ (wv • 1 music week GEORGE MICHAEL SONGS FROM THE LAST CENTURY RELEASE DATE: DEGEMBER 6TH 1999 The Album In 17 years, George Michael can already look back on more than 67 million record sales worldwide. He's notched up 11 no.1 singles and 6 no.1 albums to date in the U.K. George's fourth solo album features songs written by some of the greatest composers of the last 100 years and made famous by an array of world class performers like Sinatra, Nat King Cole, The Police, Bono, Roberta Flack, Nina Simone and Ella Fitzgerald. Co-producedFrank Filipetti. entirely in New York through the late summer by the legendary Phil Ramone and recorded by three time Grammy winner, The Campaign A massive co-op and solus TV advertising campaign of 30" and 10" spots will launch the campaign on Sunday 5th December and continue through to Christmas. Extensive radio advertising will complément the TV campaign, with targeted 30", and 40" and 60" spots. • Fleavyweight nationwide outdoor coverage comprises of prime site 96 sheet, 48 sheet, 6 sheet & 4 sheet sites, commencing November 29th. • Across the board press advertising covering Q, Attitude, OK, Time Out, GQ, Marie Claire, Cosmopolitan, ES Magazine, News Of The World, Mail On Sunday, FT, The Star, The Mirror, The Sun, The Independent & Guardian Guide. • Major retail support has been secured to include substantial in-store presence and will be targeted to andencompass in store adisplays. combination of window displays, album of the week, listening posts, radio advertising Order through Virgin Records Telesales Department 0181 964 6040 Check out www.aegean.net to view an exclusive video of 'Roxanne'. -

Leksykon Polskiej I Światowej Muzyki Elektronicznej
Piotr Mulawka Leksykon polskiej i światowej muzyki elektronicznej „Zrealizowano w ramach programu stypendialnego Ministra Kultury i Dziedzictwa Narodowego-Kultura w sieci” Wydawca: Piotr Mulawka [email protected] © 2020 Wszelkie prawa zastrzeżone ISBN 978-83-943331-4-0 2 Przedmowa Muzyka elektroniczna narodziła się w latach 50-tych XX wieku, a do jej powstania przyczyniły się zdobycze techniki z końca XIX wieku m.in. telefon- pierwsze urządzenie służące do przesyłania dźwięków na odległość (Aleksander Graham Bell), fonograf- pierwsze urządzenie zapisujące dźwięk (Thomas Alv Edison 1877), gramofon (Emile Berliner 1887). Jak podają źródła, w 1948 roku francuski badacz, kompozytor, akustyk Pierre Schaeffer (1910-1995) nagrał za pomocą mikrofonu dźwięki naturalne m.in. (śpiew ptaków, hałas uliczny, rozmowy) i próbował je przekształcać. Tak powstała muzyka nazwana konkretną (fr. musigue concrete). W tym samym roku wyemitował w radiu „Koncert szumów”. Jego najważniejszą kompozycją okazał się utwór pt. „Symphonie pour un homme seul” z 1950 roku. W kolejnych latach muzykę konkretną łączono z muzyką tradycyjną. Oto pionierzy tego eksperymentu: John Cage i Yannis Xenakis. Muzyka konkretna pojawiła się w kompozycji Rogera Watersa. Utwór ten trafił na ścieżkę dźwiękową do filmu „The Body” (1970). Grupa Beaver and Krause wprowadziła muzykę konkretną do utworu „Walking Green Algae Blues” z albumu „In A Wild Sanctuary” (1970), a zespół Pink Floyd w „Animals” (1977). Pierwsze próby tworzenia muzyki elektronicznej miały miejsce w Darmstadt (w Niemczech) na Międzynarodowych Kursach Nowej Muzyki w 1950 roku. W 1951 roku powstało pierwsze studio muzyki elektronicznej przy Rozgłośni Radia Zachodnioniemieckiego w Kolonii (NWDR- Nordwestdeutscher Rundfunk). Tu tworzyli: H. Eimert (Glockenspiel 1953), K. Stockhausen (Elektronische Studie I, II-1951-1954), H. -

Master Thesis Opleiding Media & Journalistiek Faculteit Der Historische
Master Thesis opleiding Media & Journalistiek Faculteit der Historische- en Kunstwetenschappen Erasmus Universiteit Rotterdam Onderwerp : Tiesto (Media) Hype of Mediafenomeen Door : Mw. K. van Eijsden, 282850 Datum : Rotterdam, 25 April 2006 Begeleider : Dr. S.J. Trienekens 2e lezer : Dr. P.E.M. van Dijk Cijfer : 7 (Media)Hype of Mediafenomeen? Er is geen enkele dj op de wereld die zoveel mensen trekt als ik. Het klinkt arrogant, maar dat zijn de feiten. Tiësto, in: Door!: dance in Nederland, 2004, p.218 Student: Kim van Eijsden, 282850 Eerste lezer: Dr. S. Trienekens Tweede lezer: Dr. P.E.M. van Dijk Thesiscode: ND1 Datum: maart 2006 Inhoudsopgave Voorwoord .................................................................................................................................... 2 Inleiding ........................................................................................................................................ 3 1) Tiësto: van plaatjesdraaier tot god ...................................................................................... 8 2) Theoretisch kader ................................................................................................................... 12 3) Onderzoeksopzet .................................................................................................................... 23 4) Resultaten – Het Verloop ........................................................................................................ 30 4.1.) Mediahype – Het Verloop .................................................................................. -

Classic Dance Remake Sounds’ Featuring 128 X Spire Presets Covering a Wide Spectrum of Classic Dance Club Remake Sounds Spanning from the 90S – 2000S
Trance Euphoria are pleased to release ‘Classic Dance Remake Sounds’ featuring 128 x Spire Presets covering a wide spectrum of classic dance club remake sounds spanning from the 90s – 2000s. This classic sound set brings nostalgia back to the current day with remakes from:- Des Mitchell – Welcome To The Dance, Haddaway – What Is Love, Barthezz – On The Move, Alice DJ – The Lonely One, Alice DJ – Better Off Alone, Faithless – Insomnia, Zombie Nation – Kernkarft 400, Darude – Out Of Control, Energy 52 – Cafe Del Mar, William Orbit (Ferry Corsten Remake) – Adagio For Strings, Eiffel 65 – Blue , Corona – Baby Baby, Dahool – Meet Her At The Love Parade, Public Domain – Operation Blade, Ian Van Dahl – Castles In The Sky, Robin S – Show Me Love, Xpansion – Move Your Body, Binary Finary – 1999, Warp Bros – We Will Survive, Capella – U Got 2 Let The Music, 2 Unlimited - No Limit, System F – Out Of The Blue, Sash – Mysterious Times, 4 Strings – Take Me Away, Ron Van Den Bueken – Sunset, Push (SnG Mix) – The Legacy, Push – Strange World, Dee Dee – Forever, Milk Inc – Walk On Water, Gouryella – Gouryella, Veracocha- Carte Blanche, Captain Hollywood – More And More, Scooter – Jiga Jiga. What Is In The Pack? 128 x Spire Presets (Bank) Classic Dance Remake Sounds Presets List – Txt File. Demo MP3. Please Note – Content & Copyright There are no MIDI files or Vocals included in this pack, this pack only includes sounds remade from the classic list above, all melodies used in the demo are protected by copyright and belong to their respective owners and was used for demonstration purposes only. -

Voice of the Broadcasting Industry Volume 23, Issue 3
March 2006 Voice of the Broadcasting Industry Volume 23, Issue 3 $8.00 USA $12.50 Canada-Foreign RADIORADIO NEWS ® NEWS Eddie Fritts honored in DC Will 2005 disappointment Eddie Fritts’ 23 years as President and CEO of the NAB was hon- ored 2/7 at Washington’s Willard Hotel. More than 300 people at- continue for radio? tended, including Senate Commerce Chairman Ted Stevens, Trent The final tally is in from the Radio Advertising Bureau Lott, Thad Cochran, Senate Budget Committee Chairman Judd Gregg and 2005 was a no-growth year for radio. December and Reps. John Dingell. FCC Chairman Kevin Martin and Commis- came in -1%, which brought the full year down to flat. sioner Deborah Taylor Tate also attended. A number of big name But even against the supposed easy comps as Clear broadcasters (Lowry Mays, Dick Ferguson, Bill Stakelin, Bruce Reese, Channel’s Less is More initiative laps itself, 2006 is not Bud Walters, Tribune CEO Dennis FitzSimons, and Gannett’s Craig starting out strong. Rather, weak pacings are continuing. Dubow among them) also attended, along with Jack Valenti. Eddie “Q1 may be further impacted by the Winter Olym- announced at the event that he will be opening a Washington office pics, as TV historically tends to drain some of radio’s called The Fritts Group LLC, with details to come later. ad dollars during this competition. We do, how- ever, hope that easy telecom and national comps as well as political will equate to some growth this year,” Wachovia Securities analysts Marcia Ryvicker said in a note to clients. -

The Stone Roses Music Current Affairs Culture 1980
Chronology: Pre-Stone Roses THE STONE ROSES MUSIC CURRENT AFFAIRS CULTURE 1980 Art created by John 45s: David Bowie, Ashes Cinema: Squire in this year: to Ashes; Joy Division, The Empire Strikes Back; N/K Love Will Tear Us Apart; Raging Bull; Superman II; Michael Jackson, She's Fame; Airplane!; The Out of My Life; Visage, Elephant Man; The Fade to Grey; Bruce Shining; The Blues Springsteen, Hungry Brothers; Dressed to Kill; Heart; AC/DC, You Shook Nine to Five; Flash Me All Night Long; The Gordon; Heaven's Gate; Clash, Bankrobber; The Caddyshack; Friday the Jam, Going Underground; 13th; The Long Good Pink Floyd, Another Brick Friday; Ordinary People. in the Wall (Part II); The d. Alfred Hitchcock (Apr Police, Don't Stand So 29), Peter Sellers (Jul 24), Close To Me; Blondie, Steve McQueen (Nov 7), Atomic & The Tide Is High; Mae West (Nov 22), Madness, Baggy Trousers; George Raft (Nov 24), Kelly Marie, Feels Like I'm Raoul Walsh (Dec 31). In Love; The Specials, Too Much Too Young; Dexy's Fiction: Midnight Runners, Geno; Frederick Forsyth, The The Pretenders, Talk of Devil's Alternative; L. Ron the Town; Bob Marley and Hubbard, Battlefield Earth; the Wailers, Could You Be Umberto Eco, The Name Loved; Tom Petty and the of the Rose; Robert Heartbreakers, Here Ludlum, The Bourne Comes My Girl; Diana Identity. Ross, Upside Down; Pop Musik, M; Roxy Music, Non-fiction: Over You; Paul Carl Sagan, Cosmos. McCartney, Coming Up. d. Jean-Paul Sartre (Apr LPs: Adam and the Ants, 15). Kings of the Wild Frontier; Talking Heads, Remain in TV / Media: Light; Queen, The Game; Millions of viewers tune Genesis, Duke; The into the U.S. -
![714.01 [Cover] Mothernew3](https://docslib.b-cdn.net/cover/5743/714-01-cover-mothernew3-4705743.webp)
714.01 [Cover] Mothernew3
NewMusic CMJ A BAND OF BEES 2525 REVIEWED: SUPERGRASS, Report JULIANA THEORY, ZWAN, PAUL VAN DYK, PRAM, ATOM AND CMJ SPOTLIGHT Issue No. 801 • February 17, 2003 • www.cmj.com HIS PACKAGE... PLUS MORE! LovingLoving CMJ itit LiveLiveAn Introduction to Booking and Promoting Concerts. LOUD ROCK STRAPPING YOUNG MADMAN JAZZ VANDERMARK 5 COMES ALIVE CMJ RETAIL BILLY’S ZWAN SONG NO. 1 CHARTS: NICK CAVE AT NO. 1, MASSIVE ATTACK & DATSUNS MOST ADDED HearHear Tomorrow’sTomorrow’s HitsHits TodayToday!! Volume 129 • March 31, 2003 CMJ CERTAIN DAMAGE INDUSTRY SAMPLER BOOKING NOW Vol.129: Deadline – February 21 / Hits The Street – March 31 * In addition to placing your latest tracks, you can pro * Free interactive ad (including album cover, song- mote your artist with multi-media presentations, EPKs, title, contact information and hyperlink) on the Videos, Micro-Web sites, Screensavers or other inter - Certain Damage splash page and on cmj.com. active elements. * Music appearing on Certain Damage Vol. #129 will * Each audio track includes a free 10-15 second voice also be programmed on Radio CMJ which reaches introduction to plug your artist. a potential audience of 40 million listeners via Spinner.com and AOL Ver.7 * Music appearing on Certain Damage is featured on * Free 1/2 page 4 color ad in CMJ New Music Report. CMJ Music On Hold. Look For Volume 128 With The February 24 Issue. Including Tracks From: CRANKCALLER MASSIVE ATTACKRHIAN BENSON FICTION PLANE essence THE BAD PLUS MORE CHARLES LAW AND JAGGED SUBVERSIVEPLUMB DANIEL JOHNSTON AMPLIFY PRESENCE To give your artist Full Exposure, call Mike Boyle at 917.606.1908 Ext. -

19 February 2010 Page 1 of 12
Radio 4 Listings for 13 – 19 February 2010 Page 1 of 12 SATURDAY 13 FEBRUARY 2010 Real life stories in which listeners talk about the issues that SAT 14:00 Any Answers? (b00qll19) matter to them. Shaun Ley takes listeners' calls and emails in response to this SAT 00:00 Midnight News (b00qlf3c) week's edition of Any Questions? The latest national and international news from BBC Radio 4. Fi Glover is joined by cook and food writer Simon Hopkinson. Followed by Weather. With poetry from Matt Harvey. SAT 14:30 Saturday Drama (b00qny57) Slaughterhouse 5 SAT 00:30 A History of the World in 100 Objects SAT 10:00 Excess Baggage (b00qlgzg) (b00qg5mk) Don McCullin is renowned as a photographer for his stark and Dramatisation by Dave Sheasby of the celebrated anti-war The Beginning of Science and Literature (1500 - 700 BC) telling pictures, often of conflicts and catastrophes. Now in his novel by Kurt Vonnegut. Billy Pilgrim, who hops back and seventies, he has turned to photographing landscapes and forth in time, relives various moments in his real and fantasy Statue of Ramesses Roman ruins across the ancient empire. John McCarthy asks lives, as a prisoner of war, optometrist and time traveller. him about his life of travel, both in combat zones in the remoter A History of the World in 100 Objects has arrived in Egypt parts of the world, and the apparent peace of scenes closer to Narrator ...... John Guerassio around 1250BC. At the heart of this programme is the British home. Billy Pilgrim ...... Andrew Scott Museum's giant statue of the king Ramesses II, an inspiration to Bernard V O'Hare ..... -

A Preferential Introduction to WESTERN MUSIC For
A Preferential Introduction to WESTERN MUSIC for EFL Students VOCABULARY: band, artist, singer, composer, musician, instrument, instrumental, style, (sub)genre, rhythm, beat, melody, acoustic, electric, lyrics, lip-synch, album, Pop Charts /Top40, live music, concert, bootleg, teenybopper, boy band, "one-hit wonder", hit song/album, catchy, (Sth. gets) stuck in Sb.'s head, know Sth. by heart, (Be) into Sth., dig Sth., feel Vs. not feel Sth., record, vinyl, cassette tape, compact disc (CD), streaming service, MP3, playlist, mixtape, remix, round, verse, chorus, music snob, hipster, (music) scene, record label, collection VS. library, pretentious, backup band/singers Classical (Pre-20th Century): Includes subgenres baroque, renaissance, opera, etc. Some call more recent orchestral music "modern classical" or "avant-garde" farther below. Very serious stuff! Examples of composers: Mozart, Beethoven, Brahms, Handel, Bach, Chopin, Mendelsson, Mussorgsky, Ravel, Bizet, Grieg, Rachmaninoff,Coplin, Haydn,Strauss, Wagner, Tchaikovsky, Lizst, etc. A Cappella: The opposite extreme of orchestral music is made using only the human voice as an instrument. A cappella groups are very popular on college campuses and TV singing pageantry shows. The Youtube era has ensured every popular song has an a cappella version. Beatboxing is a percussive variation. Examples: Chanticleer, Hyperpotamus, Rockapella, and various "barbershop" groups. Easy Listening: Includes polkas, waltzes, "show tunes" (from vaudeville acts and musicals), lounge music, as well as some "new age", smooth jazz, and ambient music. Some refer to these styles as "background" music or disparagingly as "elevator" music. It is never loud, but many still find it annoying! Most U.S. cities have one or more radio stations which play these kinds of music, but they are usually on AM radio, not in "stereo" sound, and not listened to by young people.