Using Python Pandas with NBA Data
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

O Klahoma City
MEDIA GUIDE O M A A H C L I K T Y O T R H U N D E 2 0 1 4 2 0 1 5 THUNDER.NBA.COM TABLE OF CONTENTS GENERAL INFORMATION ALL-TIME RECORDS General Information .....................................................................................4 Year-By-Year Record ..............................................................................116 All-Time Coaching Records .....................................................................117 THUNDER OWNERSHIP GROUP Opening Night ..........................................................................................118 Clayton I. Bennett ........................................................................................6 All-Time Opening-Night Starting Lineups ................................................119 2014-2015 OKLAHOMA CITY THUNDER SEASON SCHEDULE Board of Directors ........................................................................................7 High-Low Scoring Games/Win-Loss Streaks ..........................................120 All-Time Winning-Losing Streaks/Win-Loss Margins ...............................121 All times Central and subject to change. All home games at Chesapeake Energy Arena. PLAYERS Overtime Results .....................................................................................122 Photo Roster ..............................................................................................10 Team Records .........................................................................................124 Roster ........................................................................................................11 -

Team 252 Team 910 Team 919 Team 336 Team 704 Team
TEAM 336 Scouting report: With eight Manning into a mix of big men TEAM 919 n Rodney Rogers, Durham Hillside watch. But it wouldn’t be all perimeter NBA All-Star Game appear- that includes a former NBA MVP, n David West, Garner flash as Rogers and West would bring n Chris Paul, West Forsyth n Pete Maravich, Raleigh Broughton ances among them, Manning and McAdoo, and one of the ACC’s Scouting report: With Maravich and enough muscle to match just about any n Lou Hudson, Dudley n John Wall, Raleigh Word of God Hudson give this team a pair of early stars, Hemric, the Triad Wall in the backcourt and McGrady on front line. n Danny Manning, Page DIALING UP OUR dynamic weapons. Hudson would would have a team that would be n Tracy McGrady, Durham Mount Zion the wing, no team would be as fun to n Dickie Hemric, Jonesville slide nicely into a backcourt on better footing to compete with STATE’S BEST n Bob McAdoo, Smith with Paul. And by throwing some of the state’s other squads. While he is the brightest basketball star on the West Coast, some of NBA MVP Stephen Curry’s shine gets reflected back on his home state. Raised in Charlotte and educated at Davidson, Curry’s triumphs add new chapters to North Carolina’s already impressive hoops tradition. Since picking an all-time starting five of players who played their high school ball in North Carolina might be difficult, Fayetteville Observer staff writer Stephen Schramm has chosen teams based on the state’s six area codes. -

General Assembly of North Carolina Session 2009 Ratified Bill Resolution 2009-31 House Joint Resolution 1517 a Joint Resolution
GENERAL ASSEMBLY OF NORTH CAROLINA SESSION 2009 RATIFIED BILL RESOLUTION 2009-31 HOUSE JOINT RESOLUTION 1517 A JOINT RESOLUTION RECOGNIZING THE UNIVERSITY OF NORTH CAROLINA AT CHAPEL HILL MEN'S BASKETBALL TEAM FOR AN OUTSTANDING SEASON CULMINATING IN THE 2009 NCAA DIVISION I CHAMPIONSHIP. Whereas, on April 6, 2009, the University of North Carolina at Chapel Hill men's basketball team won the 2009 National Collegiate Athletic Association (NCAA) Division I Championship by defeating Michigan State by a score of 89-72, the largest margin in a title game in 17 years; and Whereas, on the road to the final championship game, the Tar Heels defeated each of its opponents by 12 points or more, including the Radford Highlanders (101-58), LSU Tigers (84-70), Gonzaga Bulldogs (98-77), Oklahoma Sooners (72-60), and the Villanova Wildcats (83-69); and Whereas, the 2009 championship marks the fifth Division I NCAA championship title and sixth overall championship title for the men's basketball program at UNC; and Whereas, in NCAA tournament play, UNC has been selected as a No. 1 seed 13 times, appeared in 41 tournaments, and made 18 Final Four appearances, which is a NCAA record; and Whereas, the Tar Heels began their 2008-2009 season as a unanimous No. 1 pick and finished the season with a record of 34-4, adding to the basketball program's record of 20-win seasons 51 times and 30-win seasons 10 times; and Whereas, the Tar Heels were crowned the 2009 Atlantic Coast Conference (ACC) regular season champions, improving the program's ACC record to 27 regular -

Topeka Jayhawk Club Newsletter
Topeka Jayhawk Club Newsletter Topeka Jayhawk Club Home Join Us Cancel Change Current Archive Contact Links Privacy Statement Download PDF File ISSUE 03-04 MAY 2003 To Print A Copy MANGINO & SELF TO ATTEND TJC GOLF TOURNAMENT Both Coach Mangino and Coach Self plan to attend this year's TJC golf tournament on June 16. You should have received a separate mailing to reserve your spot at the tournament. If you did not, please call the TJC phone number at 271-1224. FOOTBALL KICKOFF RECEPTION SCHEDULED JULY 1 Due to scheduling conflicts, TJC's regular summer football picnic will become a reception this year to be held on Tuesday, July 1, from 5:30-8:00 pm at the Holidome. Coach Mangino will be our special guest. You'll receive more info in an upcoming mailing. SELF COMING New coach Bill Self will attend a TJC reception at an as-yet-unspecified date in the near future. Coach Self is busily attending to recruiting duties, and TJC is quite content to let him attend to business before we give him our official welcome. KU FOOTBALL/BASKETBALL PROGRAM AD LISTING TJC will again purchase a full-page ad in the KU football and basketball programs. In addition to promoting the club, we list the names of those members who pay an additional $25 to have their names listed. All money collected from the listings helps defray the $3700 cost of the ad. Please send your money today to the TJC address:P.O. Box 67694, Topeka, Kansas 66667. Mark your check "PROGRAM AD" and be sure to enclose a note telling us how you want your names listed if different than on check. -
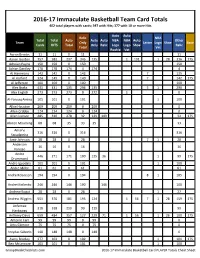
2016-17 Immaculate Basketball Player Checklist;
2016-17 Immaculate Basketball Team Card Totals 402 total players with cards; 397 with Hits; 377 with 10 or more Hits Auto Auto Relic NBA Total Total Auto Auto Auto NBA NBA Auto Other Team Only Letter Logo Shoe Base Cards HITS Total Only Relic Logo Logo Shoe Relic Total Vet Rookie Vet Aaron Brooks 11 11 0 11 11 Aaron Gordon 757 582 237 345 135 1 101 1 28 316 175 Adreian Payne 150 150 0 150 150 Adrian Dantley 178 178 174 4 174 4 AJ Hammons 142 142 0 142 7 135 Al Horford 324 149 0 149 7 142 175 Al Jefferson 100 100 0 100 100 Alec Burks 431 431 135 296 135 5 1 290 Alex English 273 273 273 0 272 1 0 Al-Farouq Aminu 101 101 0 101 1 100 Allan Houston 209 209 209 0 209 0 Allen Crabbe 124 124 124 0 124 0 Allen Iverson 485 310 278 32 129 149 32 175 Alonzo Mourning 68 68 35 33 35 33 Amar'e 316 316 0 316 316 Stoudemire Amir Johnson 28 28 0 28 7 1 20 Anderson 16 16 0 16 16 Varejao Andre 446 271 171 100 135 36 1 99 175 Drummond Andre Iguodala 101 101 0 101 1 100 Andre Miller 61 61 0 61 61 Andre Roberson 194 194 0 194 8 1 185 Andrei Kirilenko 246 246 146 100 146 100 Andrew Bogut 28 28 0 28 1 27 Andrew Wiggins 551 376 181 195 124 1 56 7 1 28 159 175 Anfernee 318 318 219 99 219 99 Hardaway Anthony Davis 659 484 357 127 229 71 1 56 1 26 100 175 Antoine Carr 99 99 99 0 99 0 Artis Gilmore 75 75 75 0 75 0 Arvydas Sabonis 148 148 148 0 148 0 Avery Bradley 277 102 0 102 1 101 175 Ben McLemore 101 101 0 101 1 100 GroupBreakChecklists.com 2016-17 Immaculate Basketball Card PLAYER Totals Cheat Sheet Auto Auto Relic NBA Total Total Auto Auto Auto NBA NBA Auto Other -

2009 NCAA Tournament As the No
2008-09 SEASON REVIEW 1187 2009 NCAA Tournament As the No. 1 overall seed for the first time in First Second Regional Regional school history, the Cardinals blitz in-state rival Round Round Semifinals Finals Morehead State. With the win, No. 1 seeds Ạ improve to 100-0 against No. 16s since the 1 Louisville 74 Tournament expanded in 1985. 16* Morehead State 54 Ạ Louisville 79 Cleveland State jumps out to a 15-4 lead in the Siena 72 8 Ohio State 72 (2OT) first half and stuns the Demon Deacons, who 9 Siena 74 briefly held the No. 1 ranking during the season. Louisville 103 ạ Norris Cole leads the winners with 22, while Arizona 64 5 Utah 71 leading Wake scorer Jeff Teague gets only 10. 12 Arizona 84 Arizona 71 After crushing Arizona, Louisville falls victim to Cleveland State 57 4 Wake Forest 69 Michigan State’s aggressive defense and coach 13 Cleveland State 84 ạ Rick Pitino benches star Terrence Williams Louisville 52 Ả for the last five minutes of the first half. The Indianapolis Michigan State 64 Ả 6 West Virginia 60 Spartans earn their fifth Final Four trip in 10 11 Dayton 68 years, the most of any school in that span. MIDWEST Dayton 43 Kansas 60 Despite losing all five starters from its 2008 3 Kansas 84 championship team, Kansas reaches the Sweet 14 North Dakota State 74 Kansas 62 ả 16 and plays Michigan State tough before losing. Michigan State 67 ả The Jayhawks’ Cole Aldrich has 17 points and 14 7 Boston College 55 rebounds for his third straight double-double. -

Open Andrew Bryant SHC Thesis.Pdf
THE PENNSYLVANIA STATE UNIVERSITY SCHREYER HONORS COLLEGE DEPARTMENT OF ECONOMICS REVISITING THE SUPERSTAR EXTERNALITY: LEBRON’S ‘DECISION’ AND THE EFFECT OF HOME MARKET SIZE ON EXTERNAL VALUE ANDREW DAVID BRYANT SPRING 2013 A thesis submitted in partial fulfillment of the requirements for baccalaureate degrees in Mathematics and Economics with honors in Economics Reviewed and approved* by the following: Edward Coulson Professor of Economics Thesis Supervisor David Shapiro Professor of Economics Honors Adviser * Signatures are on file in the Schreyer Honors College. i ABSTRACT The movement of superstar players in the National Basketball Association from small- market teams to big-market teams has become a prominent issue. This was evident during the recent lockout, which resulted in new league policies designed to hinder this flow of talent. The most notable example of this superstar migration was LeBron James’ move from the Cleveland Cavaliers to the Miami Heat. There has been much discussion about the impact on the two franchises directly involved in this transaction. However, the indirect impact on the other 28 teams in the league has not been discussed much. This paper attempts to examine this impact by analyzing the effect that home market size has on the superstar externality that Hausman & Leonard discovered in their 1997 paper. A road attendance model is constructed for the 2008-09 to 2011-12 seasons to compare LeBron’s “superstar effect” in Cleveland versus his effect in Miami. An increase of almost 15 percent was discovered in the LeBron superstar variable, suggesting that the move to a bigger market positively affected LeBron’s fan appeal. -

By Joe Kaiser ESPN It Took Danny Ferry Exactly Seven Days in His
By Joe Kaiser ESPN Smith had a great 2011 -12, but he is an unrestricted free agent after this season. It took Danny Ferry exactly seven days in his new role as the Atlanta Hawks' president of basketball operations and general manager to completely change the face of the franchise. His ability to swiftly orchestrate separate deals to part with high-priced veterans Joe Johnson and Marvin Williams signaled a commitment to rebuilding and shed as much as $77 million still owed to the two veterans beyond next season. Fast-forward two-and-a-half months to today, and Ferry's rebuilt roster has only a handful of contracts that go beyond the 2012-13 season: • Al Horford : Signed through 2015-16. • Lou Williams : Signed through 2013-14. • John Jenkins : 2012 first-round pick. • Mike Scott : 2012 second-round pick. • Jeff Teague : Due to become a restricted free agent at season's end, barring an extension. Notice one big name we didn't mention: Josh Smith . The tantalizingly talented, yet often frustrating, forward is among the many Hawks entering the final year of their deals, and he represents arguably the biggest challenge for Ferry to date: what to do with Smith. If handled correctly, this could be the next step toward eventually turning the Hawks into a perennial playoff contender. Mishandled, and this could undo everything good that came out of the trades of Johnson and Williams. So the question is, what's the smarter move for Ferry and the Hawks? a) Negotiate an extension that will keep Smith in Atlanta for the long term. -

NBA Players Word Search
Name: Date: Class: Teacher: NBA Players Word Search CRMONT A ELLISIS A I A HTHOM A S XTGQDWIGHTHOW A RDIBZWLMVG VKEVINDUR A NTBL A KEGRIFFIN YQMJVURVDE A NDREJORD A NNTX CEQBMRRGBHPK A WHILEON A RDB TFJGOUTO A I A SDIRKNOWITZKI IGPOUSBIIYUDPKEVINLOVEXC MKHVSSTDOKL A YTHOMPSONXJF DMDDEESWLEMMP A ULGEORGEEK U A E A MLBYEMIISTEPHENCURRY NNRVJLW A BYL A ODLVIWJVHLER CUOI A WLNRKLNO A LHORFORDMI A GNDMEWEOESLVUBPZK A LSUYE NIWWESNWNG A IKTIMDUNC A NLI KNIESTR A JEPLU A QZPHESRJIR GOLSHBQD A K A LFKYLELOWRYNV HBLT A RDEMWR A ZSERGEIB A K A I DIIYROGDEM A RDEROZ A NGSJBN ZL A HDOKUSLGDCHRISP A ULUXG OIMSEKL A M A RCUS A LDRIDGEDZ VKSWNQXIDR A YMONDGREENYFZ TONYP A RKER A LECHRISBOSH A P AL HORFORD DWYANE WADE ISAIAH THOMAS DEMAR DEROZAN RUSSELL WESTBROOK TIM DUNCAN DAMIAN LILLARD PAUL GEORGE DRAYMOND GREEN LEBRON JAMES KLAY THOMPSON BLAKE GRIFFIN KYLE LOWRY LAMARCUS ALDRIDGE SERGE IBAKA KYRIE IRVING STEPHEN CURRY KEVIN LOVE DWIGHT HOWARD CHRIS BOSH TONY PARKER DEANDRE JORDAN DERON WILLIAMS JOSE BAREA MONTA ELLIS TIM DUNCAN KEVIN DURANT JAMES HARDEN JEREMY LIN KAWHI LEONARD DAVID WEST CHRIS PAUL MANU GINOBILI PAUL MILLSAP DIRK NOWITZKI Free Printable Word Seach www.AllFreePrintable.com Name: Date: Class: Teacher: NBA Players Word Search CRMONT A ELLISIS A I A HTHOM A S XTGQDWIGHTHOW A RDIBZWLMVG VKEVINDUR A NTBL A KEGRIFFIN YQMJVURVDE A NDREJORD A NNTX CEQBMRRGBHPK A WHILEON A RDB TFJGOUTO A I A SDIRKNOWITZKI IGPOUSBIIYUDPKEVINLOVEXC MKHVSSTDOKL A YTHOMPSONXJF DMDDEESWLEMMP A ULGEORGEEK U A E A MLBYEMIISTEPHENCURRY NNRVJLW A BYL A ODLVIWJVHLER -

National Basketball Association Official
NATIONAL BASKETBALL ASSOCIATION OFFICIAL SCORER'S REPORT FINAL BOX 10/8/2012 ORACLE Arena, Oakland, CA Officials: #22 Bill Spooner, #40 Leon Wood, #72 JT Orr Time of Game: 2:03 Attendance: 14,571 VISITOR: Utah Jazz (0-1) NO PLAYER MIN FG FGA 3P 3PA FT FTA OR DR TOT A PF ST TO BS PTS 2 Marvin Williams F 22:24 4 6 0 0 5 6 0 3 3 1 0 1 1 0 13 24 Paul Millsap F 20:36 4 7 1 1 4 7 2 4 6 1 3 1 2 0 13 25 Al Jefferson C 20:36 1 8 0 0 0 0 1 2 3 1 1 0 0 2 2 20 Gordon Hayward G 17:01 2 10 0 1 1 2 3 3 6 0 2 2 1 0 5 5 Mo Williams G 22:24 3 9 2 2 3 3 0 3 3 6 1 0 4 0 11 8 Randy Foye 16:21 0 6 0 2 0 0 0 1 1 3 1 0 0 2 0 0 Enes Kanter 24:19 5 12 0 0 2 2 3 8 11 1 1 0 0 2 12 15 Derrick Favors 22:28 4 7 0 0 0 0 1 1 2 0 0 0 4 0 8 6 Jamaal Tinsley 25:36 1 3 0 2 0 0 0 3 3 6 1 2 1 0 2 3 DeMarre Carroll 23:13 4 6 1 3 0 0 1 2 3 0 2 0 2 0 9 33 Darnell Jackson 4:56 0 1 0 0 0 0 0 1 1 0 2 0 2 0 0 10 Alec Burks 17:01 2 5 1 1 0 0 0 0 0 1 3 0 1 0 5 40 Jeremy Evans 3:05 0 0 0 0 0 0 0 1 1 0 0 0 0 0 0 19 Raja Bell DNP - Coach's Decision 31 Brian Butch DNP - Coach's Decision 23 Trey Gilder DNP - Coach's Decision 55 Kevin Murphy DNP - Coach's Decision 22 Chris Quinn DNP - Coach's Decision 11 Earl Watson NWT - Right Knee Rehab TOTALS: 30 80 5 12 15 20 11 32 43 20 17 6 18 6 80 PERCENTAGES: 37.5% 41.7% 75.0% TM REB: 13 TOT TO: 18 (17 PTS) HOME: GOLDEN STATE WARRIORS (2-0) NO PLAYER MIN FG FGA 3P 3PA FT FTA OR DR TOT A PF ST TO BS PTS 4 Brandon Rush F 28:09 6 12 2 6 0 0 1 1 2 1 1 0 2 2 14 10 David Lee F 36:21 9 14 0 1 1 2 1 13 14 5 3 4 3 0 19 31 Festus Ezeli C 24:31 2 3 0 0 2 2 1 -

Communications
MARCH 23, 2019 | NCAA TOURNAMENT - SECOND ROUND | GAME NOTES KANSAS COMMUNICATIONS # # # # 26-9 12-6 17 / 17 27-9 11-7 14 / 18 TIGERS OVERALL BIG 12 RANKING (AP/COACHES) OVERALL SEC RANKING (AP/COACHES) -VS- Bill Self 473-105 (.818) Bruce Pearl 97-71 (.577) JAYHAWKS HEAD COACH RECORD AT KU, 16TH SEASON HEAD COACH RECORD AT AU, FIFTH SEASON SCHEDULE (H: 17-0; A: 3-8; N: 6-1) GAME (4) KANSAS VS (5) AUBURN KU IN THE NCAA TOURNEY (More on pg. 49) KU OPP NCAA Championship • Second Round OVERALL (under Bill Self) 108-46 (38-14) Rnk Rnk Opponent TV Time/Result Salt Lake City, Utah • Vivint Smart Home Arena (18,284) as No. 4 seed 8-4 NOVEMBER (5-0) 36 In Round of 32 (Since 1981) 23-10 6 1/1 10/10 vs. Michigan State! ESPN W, 92-87 Saturday, March 23, 2019 • 8:40 p.m. (CT) 12 2/1 -/- VERMONT~ ESPN2 W, 84-68 16 2/1 -/- LOUISIANA JTV/ESPN+ W, 89-76 TBS JAYHAWK RADIO 21 2/2 rv/rv vs. Marquette# ESPN2 W, 77-68 NETWORK Play-by-Play: Andrew Catalon Radio: IMG Jayhawk Radio Network 23 2/2 5/5 vs. Tennessee# ESPN2 W, 87-82 ot Analysts: Steve Lappas Webcast: KUAthletics.com/Radio DECEMBER (6-1) Reporter: Lisa Byington Play-by-Play: Brian Hanni POINTS 1 2/2 -/- STANFORD ESPN W, 90-84 ot Producer: Johnathan Segal Analyst: Greg Gurley 75.7 PER GAME ›› 79.5 4 2/2 -/- WOFFORD JTV/ESPN+ W, 72-47 Director: Andy Goldberg Producer/Engineer: Steve Kincaid 8 2/2 -/- NEW MEXICO STATE^ ESPN2 W, 63-60 TIP-OFF 46.5 ‹‹ FG% 44.8 15 1/1 17/16 VILLANOVA ESPN W, 74-71 • Kansas is making its 48th NCAA Tournament appearance and has a 18 1/1 -/- SOUTH DAKOTA JTV/ESPN+ W, 89-53 108-46 record in the event. -

Administration of Barack Obama, 2015 Remarks Honoring the 2014
Administration of Barack Obama, 2015 Remarks Honoring the 2014 National Basketball Association Champion San Antonio Spurs January 12, 2015 The President. Well, hello, everybody! Welcome to the White House. Everybody, please have a seat. In case you didn't know, these are the NBA Champion San Antonio Spurs. I was considering having the Vice President cover these remarks so I could stay fresh for the State of the Union. [Laughter] Taking an example off Pop, who sits his stars sometimes—[laughter]— but I decided I actually wanted to meet them. So I know we've got a lot of Spurs fans in the house—no doubt—including a guy I stole from San Antonio, our Secretary of Housing and Urban Development, former Mayor Julián Castro. [Applause] Hey! And of course we want to welcome General Manager R.C. Buford and, of course, Coach Popovich. I want the coach to know that he is not contractually obligated to take questions after the first quarter of my remarks. [Laughter] Now, look, I admit it, I'm a Bulls fan. It's never easy celebrating a non-Bulls team in the White House. [Laughter] That's all I've been able to do—[laughter]—so far. But even I have to admit that the Spurs are hard to dislike. First of all, they're old. [Laughter] And for an old guy, it makes me feel good to see—where's Tim? [Laughter] Tim's got some gray. There's a few others with a little sprinkles around here. There's a reason why the uniform is black and silver.