Present-Day English Irregular Verbs Revisited
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Computational Analysis of Affixed Words in Malay Language Bali RANAIVO-MALANÇON School of Computer Sciences Universiti Sains Malaysia [email protected]
Computational analysis of affixed words in Malay language Bali RANAIVO-MALANÇON School of Computer Sciences Universiti Sains Malaysia [email protected] A full-system Malay morphological analyser must contain modules that can analyse affixed words, compound words, and reduplicated words. In this paper, we propose an algorithm to analyse automatically Malay affixed words as they appear in a written text by applying successively segmentation, morphographemic, morphotactic, and interpretation rules. To get an accurate analyser, we have classified Malay affixed words into two groups. The first group contains affixed words that cannot be analysed automatically. They are lexicalised affixed words (e.g. berapa, mengapa), idiosyncrasy (e.g. bekerja, penglipur), and infixed words because infixation is not productive any more in Malay language. Affixed words that belong to the first group will be filtered, treated and take off before the segmentation phase. The second group contain affixed words that can be segmented according to segmentation and morphographemic rules. Affixes are classified following their origin (native vs. borrowed), their position in relation to the base (prefix, suffix, circumfix), and the spelling variations they may create when they are added to a base. At the moment, the analyser can process affixed words containing only native prefixes, suffixes and circumfixes. In Malay language, only five native prefixes (ber-, per-, ter-, me-, pe-) may create some modification (deletion, insertion, assimilation) at the point of contact with the base. Thus the main problem in segmenting prefixed words in Malay is to determine the end of the prefix and the beginning of the base. To solve the problem, we state that each affix in Malay has only one form (i.e. -

USAN Naming Guidelines for Monoclonal Antibodies |
Monoclonal Antibodies In October 2008, the International Nonproprietary Name (INN) Working Group Meeting on Nomenclature for Monoclonal Antibodies (mAb) met to review and streamline the monoclonal antibody nomenclature scheme. Based on the group's recommendations and further discussions, the INN Experts published changes to the monoclonal antibody nomenclature scheme. In 2011, the INN Experts published an updated "International Nonproprietary Names (INN) for Biological and Biotechnological Substances—A Review" (PDF) with revisions to the monoclonal antibody nomenclature scheme language. The USAN Council has modified its own scheme to facilitate international harmonization. This page outlines the updated scheme and supersedes previous schemes. It also explains policies regarding post-translational modifications and the use of 2-word names. The council has no plans to retroactively change names already coined. They believe that changing names of monoclonal antibodies would confuse physicians, other health care professionals and patients. Manufacturers should be aware that nomenclature practices are continually evolving. Consequently, further updates may occur any time the council believes changes are necessary. Changes to the monoclonal antibody nomenclature scheme, however, should be carefully considered and implemented only when necessary. Elements of a Name The suffix "-mab" is used for monoclonal antibodies, antibody fragments and radiolabeled antibodies. For polyclonal mixtures of antibodies, "-pab" is used. The -pab suffix applies to polyclonal pools of recombinant monoclonal antibodies, as opposed to polyclonal antibody preparations isolated from blood. It differentiates polyclonal antibodies from individual monoclonal antibodies named with -mab. Sequence of Stems and Infixes The order for combining the key elements of a monoclonal antibody name is as follows: 1. -

Greek and Latin Roots, Prefixes, and Suffixes
GREEK AND LATIN ROOTS, PREFIXES, AND SUFFIXES This is a resource pack that I put together for myself to teach roots, prefixes, and suffixes as part of a separate vocabulary class (short weekly sessions). It is a combination of helpful resources that I have found on the web as well as some tips of my own (such as the simple lesson plan). Lesson Plan Ideas ........................................................................................................... 3 Simple Lesson Plan for Word Study: ........................................................................... 3 Lesson Plan Idea 2 ...................................................................................................... 3 Background Information .................................................................................................. 5 Why Study Word Roots, Prefixes, and Suffixes? ......................................................... 6 Latin and Greek Word Elements .............................................................................. 6 Latin Roots, Prefixes, and Suffixes .......................................................................... 6 Root, Prefix, and Suffix Lists ........................................................................................... 8 List 1: MEGA root list ................................................................................................... 9 List 2: Roots, Prefixes, and Suffixes .......................................................................... 32 List 3: Prefix List ...................................................................................................... -

Types and Functions of Reduplication in Palembang
Journal of the Southeast Asian Linguistics Society JSEALS 12.1 (2019): 113-142 ISSN: 1836-6821, DOI: http://hdl.handle.net/10524/52447 University of Hawaiʼi Press TYPES AND FUNCTIONS OF REDUPLICATION IN PALEMBANG Mardheya Alsamadani & Samar Taibah Wayne State University [email protected] & [email protected] Abstract In this paper, we study the morphosemantic aspects of reduplication in Palembang (also known as Musi). In Palembang, both content and function words undergo reduplication, generating a wide variety of semantic functions, such as pluralization, iteration, distribution, and nominalization. Productive reduplication includes full reduplication and reduplication plus affixation, while fossilized reduplication includes partial reduplication and rhyming reduplication. We employed the Distributed Morphology theory (DM) (Halle and Marantz 1993, 1994) to account for these different patterns of reduplication. Moreover, we compared the functions of Palembang reduplication to those of Malay and Indonesian reduplication. Some instances of function word reduplication in Palembang were not found in these languages, such as reduplication of question words and reduplication of negators. In addition, Palembang partial reduplication is fossilized, with only a few examples collected. In contrast, Malay partial reduplication is productive and utilized to create new words, especially words borrowed from English (Ahmad 2005). Keywords: Reduplication, affixation, Palembang/Musi, morphosemantics ISO 639-3 codes: mui 1 Introduction This paper has three purposes. The first is to document the reduplication patterns found in Palembang based on the data collected from three Palembang native speakers. Second, we aim to illustrate some shared features of Palembang reduplication with those found in other Malayic languages such as Indonesian and Malay. The third purpose is to provide a formal analysis of Palembang reduplication based on the Distributed Morphology Theory. -

On the Origins of Linguistic Structure : Three Models of Regular and Irregular Past Tense Formation
University of Montana ScholarWorks at University of Montana Graduate Student Theses, Dissertations, & Professional Papers Graduate School 2001 On the origins of linguistic structure : three models of regular and irregular past tense formation Benjamin J. Sienicki The University of Montana Follow this and additional works at: https://scholarworks.umt.edu/etd Let us know how access to this document benefits ou.y Recommended Citation Sienicki, Benjamin J., "On the origins of linguistic structure : three models of regular and irregular past tense formation" (2001). Graduate Student Theses, Dissertations, & Professional Papers. 8129. https://scholarworks.umt.edu/etd/8129 This Thesis is brought to you for free and open access by the Graduate School at ScholarWorks at University of Montana. It has been accepted for inclusion in Graduate Student Theses, Dissertations, & Professional Papers by an authorized administrator of ScholarWorks at University of Montana. For more information, please contact [email protected]. Maureen and Mike MANSFIELD LIBRARY The University of Montana Permission is granted by the author to reproduce this material in its entirety, provided that this material is used for scholarly purposes and is properly cited in published works and reports. **PIease check "Yes" or "No" and provide signature** Yes, I grant permission ______ No, I do not grant permission ___________ Author's Signature: Date: Any copying for commercial purposes or financial gain may be undertaken only with the author's explicit consent. MSThe*i3W»n»ti«ld Library Permission Reproduced with permission of the copyright owner. Further reproduction prohibited without permission. Reproduced with permission of the copyright owner. Further reproduction prohibited without permission. -

Derivational and Inflectional Prefixes and Suffixes in Batusesa Dialect of Balinese: a Descriptive Study
ISSN: 2549-4287 Vol.1, No.1, February 2017 DERIVATIONAL AND INFLECTIONAL PREFIXES AND SUFFIXES IN BATUSESA DIALECT OF BALINESE: A DESCRIPTIVE STUDY Ariani, N.K. English Education Department, Ganesha University of Education e-mail: [email protected] Abstract This study was designed in the form of descriptive qualitative study with the aim at describing the prefixes and suffixes in Batusesa Dialect of Balinese which belong to derivational and inflectional morpheme. The techniques used to collect the data were observation, recording and interview technique. In this study, there were three informants chosen. The results of this study show that there are four kinds of prefixes found in Batusesa Dialect, namely {n-}, {me-}, {pe-}, and {a-} and five kinds of suffixes namely {-ang}, {-nә}, {-in}, {-an} and {-ә}. There are three kinds of prefixes and one kind of suffixes which belong to derivational morpheme, namely {n-}, {me-}, {pe-}, and {-ang}. Moreover there are three kinds of inflectional prefixes namely {n-}, {me-}, and {a-} and four kinds of suffixes which belong to inflectional morpheme, namely {-nә}, {-in}, {-an} and {-ә}. There were some grammatical functions of prefixes and suffixes in Batusesa dialect of Balinese, namely affix forming verbal, affix forming nominal, affix forming numeral, affix forming adjective, and affix forming adverb, activizer and passivizer. Keyword: prefixes, suffixes, derivational, inflectional INTRODUCTION Language is an important aspect in human life. It is a means of communication of a person to the others. The people need language to looking for and give people benefit information. People need language as a means of communication to express their feeling, though and desire. -

Part VI More Affixes
68 Part VI More Affixes PARTICLES Verbs and nouns tend to be complex in Oneida because they can have many internal parts. The particles, however, are simpler in form. They tend to be short - one, two, or three syllables. They perform a number of different functions in the language, some of them are quite straightforward and have easy English translations, while others cover ranges of meaning that are subtle and nearly impossible to translate. Sometimes a sequence of particles has a meaning that is distinct from the meaning of any of the particles in the sequence. The use of particles is part of what distinguishes different styles of speaking. More are used in ceremonial speech, for example. One can begin to learn the particles by grouping some of the more straightforward ones by function. They deal with time, place, extent, grammatical connectives, and conversational interaction. Question Particles náhte÷ what náhohte what (sentence final form) úhka náhte÷ who kánhke when to nikaha=wí= when kátsa÷ nu where (requires a locative or partitive prefix) kátsa÷ ka=y§= which one náhte÷ aolí=wa÷ why, for what reason oh ni=yót how to ni=kú how much to niha=tí how many people to niku=tí how many females Time Particles elhúwa recently o=n§ or n< now, or at that time &wa or n&wa or nu÷ú now, or today oksa÷ right away, soon swatye=l§ sometimes ty%tkut always yotk@=te always yah nuw<=tú never 69 Place Particles @kta nearby @kte somewhere else @tste outside é=nike up, above ehtá=ke down, below k§=tho here k<h nu here k<h nukwá this way ohná=k< back, -

1 Summary 2 Auxiliaries
CAS LX 321 / GRS LX 621 Syntax: Introduction to Sentential Structure November 20ish, 2018 1 Summary While I have you here, I’ll also kind of try to summarize where we are and how we got here, not just introduce new things. In particular, one thing that I want to try to get out of this is a solidification of what we did leading up to homework 8, which has caused some confusion due to a lot of things being very new and densely packed (and not entirely well specified). So, I’ll start by filling in some things from last time’s handout, and take it from there. 2 Auxiliaries We have quite recently added “auxiliaries” to our grammar. We kind of had these before, but they were limited to the modals like should, may, etc. I had intentionally tried to dodge any of the others until we got to this point. 2.1 Modals “Modals” are must, may, might, shall, should, can, could, will, would. And it is possible to put one of these between the subject and the verb. (1) Pat should sleep. What we had done before was to say that these were realizations of category T (for “tense”). The justification for this (which in fact I’m about to co-opt for a different conclusion) is that they “feel” kind of like they have a tense distinction in their morphology. This is an argument that relies a lot on an intuitive feeling and not a lot on much else. But it goes like this: • Modals (except must) seem to come in pairs. -

An Essential Grammar
English An Essential Grammar This is a concise and user-friendly guide to the grammar of modern English, written specifically for native speakers. You do not need to have studied English grammar before: all the essen- tials are explained here clearly and without the use of jargon. Beginning with the basics, the author then introduces more advanced topics. Based on genuine samples of contemporary spoken and written English, the Grammar focuses on both British and American usage, and explores the differences – and similarities – between the two. Features include: • discussion of points which often cause problems • guidance on sentence building and composition • practical spelling rules • explanation of grammatical terms • appendix of irregular verbs. English: An Essential Grammar will help you read, speak and write English with greater confidence. It is ideal for everyone who would like to improve their knowledge of English grammar. Gerald Nelson is Research Assistant Professor in the English Department at The University of Hong Kong, and formerly Senior Research Fellow at the Survey of English Usage, University College London. English An Essential Grammar Gerald Nelson TL E D U G O E R • • T a p y u lo ro r G & Francis London and New York 1111 2 3 4 5 6 7 8 9 1011 1 12111 First published 2001 3 by Routledge 11 New Fetter Lane, London EC4P 4EE 4 5 Simultaneously published in the USA and Canada 6 by Routledge 7 29 West 35th Street, New York, NY 10001 8 Routledge is an imprint of the Taylor & Francis Group 9 20111 This edition published in the Taylor & Francis e-Library, 2002. -

Number Systems in Grammar Position Paper
1 Language and Culture Research Centre: 2018 Workshop Number systems in grammar - position paper Alexandra Y. Aikhenvald I Introduction I 2 The meanings of nominal number 2 3 Special number distinctions in personal pronouns 8 4 Number on verbs 9 5 The realisation of number 12 5.1 The forms 12 5.2 The loci: where number is shown 12 5.3 Optional and obligatory number marking 14 5.4 The limits of number 15 5.4.1 Number and the meanings of nouns 15 5.4.2 'Minor' numbers 16 5.4.3 The limits of number: nouns with defective number values 16 6 Number and noun categorisation 17 7 Markedness 18 8 Split, or mixed, number systems 19 9 Number and social deixis 19 10 Expressing number through other means 20 11 Number systems in language history 20 12 Summary 21 Further readings 22 Abbreviations 23 References 23 1 Introduction Every language has some means of distinguishing reference to one individual from reference to more than one. Number reference can be coded through lexical modifiers (including quantifiers of various sorts or number words etc.), or through a grammatical system. Number is a referential property of an argument of the predicate. A grammatical system of number can be shown either • Overtly, on a noun, a pronoun, a verb, etc., directly referring to how many people or things are involved; or • Covertly, through agreement or other means. Number may be marked: • within an NP • on the head of an NP • by agreement process on a modifier (adjective, article, demonstrative, etc.) • through agreement on verbs, or special suppletive or semi-suppletive verb forms which may code the number of one or more verbal arguments, or additional marker on the verb. -
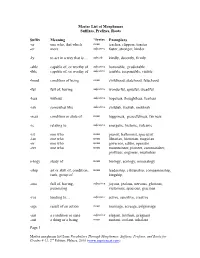
Morpheme Master List
Master List of Morphemes Suffixes, Prefixes, Roots Suffix Meaning *Syntax Exemplars -er one who, that which noun teacher, clippers, toaster -er more adjective faster, stronger, kinder -ly to act in a way that is… adverb kindly, decently, firmly -able capable of, or worthy of adjective honorable, predictable -ible capable of, or worthy of adjective terrible, responsible, visible -hood condition of being noun childhood, statehood, falsehood -ful full of, having adjective wonderful, spiteful, dreadful -less without adjective hopeless, thoughtless, fearless -ish somewhat like adjective childish, foolish, snobbish -ness condition or state of noun happiness, peacefulness, fairness -ic relating to adjective energetic, historic, volcanic -ist one who noun pianist, balloonist, specialist -ian one who noun librarian, historian, magician -or one who noun governor, editor, operator -eer one who noun mountaineer, pioneer, commandeer, profiteer, engineer, musketeer o-logy study of noun biology, ecology, mineralogy -ship art or skill of, condition, noun leadership, citizenship, companionship, rank, group of kingship -ous full of, having, adjective joyous, jealous, nervous, glorious, possessing victorious, spacious, gracious -ive tending to… adjective active, sensitive, creative -age result of an action noun marriage, acreage, pilgrimage -ant a condition or state adjective elegant, brilliant, pregnant -ant a thing or a being noun mutant, coolant, inhalant Page 1 Master morpheme list from Vocabulary Through Morphemes: Suffixes, Prefixes, and Roots for -

Introduction Introduction
Introduction Introduction -- porke ja7at jch^ayem jolat i ma7ba ya awich^ tal awinam ya xtal sk^anantabat abiluk ja7 yu7unil awil xtal ajok^obe bi7 a xch^ay awu7une kjipat ta karsel xbaht kak^at ta karsel, ha-ha-ha yawich^ awotan7a porke ya xch^ay sjol te sakil winik, ha-ha-ha because you are crazy and you don’t bring your woman (wife).2 You have to take care of your things; and look, it is because of this that you come to ask for what you lost. I will throw you in jail, I will go to leave you in jail! ha-ha-ha This will make you learn! ha-ha-ha The tirade above was launched (mostly in jest) by angry Fransisca, the mother of my host family in Petalcingo, when after a frantic search all over the house for my little desk lamp it turned out that I had hidden it myself in my backpack earlier that day. The quote, which alternatively references me in the second and third person, is replete with references to him and his, and you and yours, which, rather than being realized as pronouns (as in English) are marked by agreement morphemes on the verb and the possessed noun. The morphology and syntax of these agreement morphemes is the topic of the present thesis. Since overt pronouns are quite rare in Tzeltal discourse, the agreement markers usually are the only way of indicating who is doing what to whom, and what is possessed by whom. The fact that the same markers are used to indicate the subject of a transitive verb as well as the possessor of a thing, while not entirely uncommon in the world’s languages, is one of the interesting properties exhibited by Tzeltal.