Data-Driven Pose Estimation for Virtual Realiity
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Order 1886 Full Game Pc Download the Order: 1886
the order 1886 full game pc download The Order: 1886. While Killzone: Shadow Fall and inFAMOUS: Second Son have given us a glimpse of how Sony's popular franchises can be enhanced and expanded on the PlayStation 4, The Order: 1886 is exciting for a completely different reason. This isn't something familiar given a facelift-- this is a totally new project, one whose core ideas and gameplay were born on next-generation hardware. It's interesting, then, that this also serves as the first original game for developer Ready at Dawn. Ideas for The Order originally began forming in 2006 as a project that crafted fiction from real-life history and legends. Indeed, one of the game's more intriguing elements is that mix of fantasy and reality. This alternate-timeline Victorian London is covered in a layer of grit and grime true to that era, contrasted by dirigibles flying through the sky and fantastical weapons used by the game's protagonists, four members of a high-tech (for the times) incarnation of the Knights of the Round Table. That idea of blending different aspects together may be what's most compelling about The Order: 1886 beyond just its premise. The first thing you notice is the game's visual style. There's a cinematic, film-like look to everything, and not only are the overall graphical qualities and camera angles tweaked to reflect that, but The Order also runs in widescreen the entire time--not just during cutscenes like in other games. It's a decision that some have bemoaned, since those top and bottom areas of the screen are now "missing" during game-play. -

Recommendations for Integrating a P300-Based Brain–Computer Interface in Virtual Reality Environments for Gaming: an Update
computers Review Recommendations for Integrating a P300-Based Brain–Computer Interface in Virtual Reality Environments for Gaming: An Update Grégoire Cattan 1,* , Anton Andreev 2 and Etienne Visinoni 3 1 IBM, Cloud and Cognitive Software, Department of SaferPayment, 30-150 Krakow, Poland 2 GIPSA-lab, CNRS, Department of Platforms and Project, 38402 Saint Martin d’Hères, France; [email protected] 3 SputySoft, 75004 Paris, France; [email protected] * Correspondence: [email protected] Received: 19 September 2020; Accepted: 12 November 2020; Published: 14 November 2020 Abstract: The integration of a P300-based brain–computer interface (BCI) into virtual reality (VR) environments is promising for the video games industry. However, it faces several limitations, mainly due to hardware constraints and limitations engendered by the stimulation needed by the BCI. The main restriction is still the low transfer rate that can be achieved by current BCI technology, preventing movement while using VR. The goal of this paper is to review current limitations and to provide application creators with design recommendations to overcome them, thus significantly reducing the development time and making the domain of BCI more accessible to developers. We review the design of video games from the perspective of BCI and VR with the objective of enhancing the user experience. An essential recommendation is to use the BCI only for non-complex and non-critical tasks in the game. Also, the BCI should be used to control actions that are naturally integrated into the virtual world. Finally, adventure and simulation games, especially if cooperative (multi-user), appear to be the best candidates for designing an effective VR game enriched by BCI technology. -

Activate Technology & Media Outlook 2021
October 2020 ACTIVATE TECHNOLOGY & MEDIA OUTLOOK 2021 www.activate.com 12 Takeaways from the Activate Technology & Media Outlook 2021 Time and Attention: The entire growth curve for consumer time spent with technology and media has shifted upwards and will be sustained at a higher level than ever before, opening up new opportunities. Video Games: Gaming is the new technology paradigm as most digital activities (e.g. search, social, shopping, live events) will increasingly take place inside of gaming. All of the major technology platforms will expand their presence in the gaming stack, leading to a new wave of mergers and technology investments. AR/VR: Augmented reality and virtual reality are on the verge of widespread adoption as headset sales take off and use cases expand beyond gaming into other consumer digital activities and enterprise functionality. Video: By 2024, nearly all American households will have a Connected TV. The average paid video streaming subscriber will own 5.7 subscriptions, while also watching other services for free (e.g. sharing passwords, using advertising-supported services, viewing social video). eCommerce: The growth curve of eCommerce has accelerated by 5 years in 5 months. Consumers will expand their digital shopping destinations beyond the retailers that they bought from before shelter-in-place. Marketplace platforms and the shift to online grocery buying will level the eCommerce playing field for large traditional retailers and brands. Esports: During shelter-in-place, esports were sports for many consumers; going forward, esports will be a major global catalyst for interest in interactive gaming, technology, and entertainment experiences. www.activate.com Continued ➔ 2 12 Takeaways from the Activate Technology & Media Outlook 2021 Sports Tech and Sports: New technologies will reshape every aspect of sports, including data, athlete performance, and viewing experiences. -

Work Experience Aaa Projects Education Social
SKILLS - Adobe Creative Suite - Team Leadership - Illustrator - Department Management - Photoshop - Creative Direction - After Effects - Visual Design - Maya - Wireframing/Prototyping - HTML/CSS - Implementation - Motion Graphics - Perforce/JIRA/Confluence CONTACT WORK EXPERIENCE [email protected] UI Artist/Designer Ready At Dawn Studios | Irvine, CA | June 2016 - Present TEL. 210.249.1983 General Responsibilities: www.justbuck.it - Work within a UI Team (Design, Art, and Programming) on all UI tasks - Production pipeline creation and overall department maintenance for the UI Team Long Beach, CA - Create wireframes, concepts, mockups, animations, and in-game assets across all games - Work on multiple projects simultaneously while still meeting deadlines Born and raised in San Antonio, Texas, I knew at a young age that art was my passion. With a BFA in Communication Graphic Designer Design from Texas State University and Fortify Design | Austin, TX | September 2014 - 2016 years of professional experience, I’m adept General Responsibilities: with the Adobe Creative Suite (Photoshop, - Design graphics for various clients across the professional spectrum Illustrator, After Effects, etc), Maya, HTML, as - Work alongside the Lead Graphic Designer on all projects well as the fine arts. With professional - Tackle dozens of projects from trademarks to websites to packaging to printing experience in the field of Graphic Design - Contact clients and correspond via phone and email and the games industry as a UI Artist/De- signer, I recognize the importance of meeting deadlines and delivering high quality work to clients or publishers. I am driven by design and thrive in high-pressure AAA PROJECTS environments. I handle challenges with creativity, proficiency, and positivity and UI Artist would be an asset to any design team. -

Game Design Workshop
Game Design Workshop USC School of Cinematic Arts, CTIN 488 Instructors: Chris Swain, Dan Arey, and Vincent Diamante Contact Info: Chris Swain Dan Arey Vincent Diamante (310) 403 0798 (310) 663 0949 (213) 840 0645 [email protected] [email protected] [email protected] Course Description: CTIN 488 is the foundation course for game design education at USC. It is a required course for all students majoring and minoring in interactive entertainment and games from the School of Cinematic Arts and Viterbi School of Engineering. The foundation mentioned is constructed from a codified language for games and set of design methodologies that collectively we call “playcentric design”. Think of playcentric design as a USC school of thought for games. It is intended to provide flexible skills and knowledge that will enable you to create playable systems more efficiently and collaborate with others more effectively. Playcentric design strives to enable the student to: 1) Understand Fundamental Theory – You will learn about the Formal, Dramatic, and Dynamic elements of games and how the three interrelate 2) Learn core development process – This process is independent of software tools (which change over time). It includes understanding iterative design, prototyping, playtesting, presentation, and collaboration 3) Practice, Practice, Practice – Everyone will design many games hands-on regardless of technical skills. Class assignments are designed to make good additions to a student’s demo reel. In addition everyone will get lots of experience critiquing and analyzing games as playable systems. CTIN 488 is designed to provide the foundation of knowledge for succeeding throughout the game program at USC and becoming a professional game designer. -
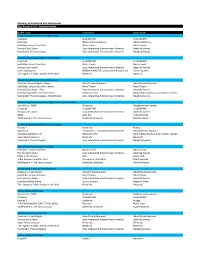
21St Annual DICE Awards Finalists.Xlsx
Academy of Interactive Arts and Sciences 21st Annual D.I.C.E. Awards Finalists GAME TITLE PUBLISHER DEVELOPER Outstanding Achievement in Animation Cuphead StudioMDHR StudioMDHR For Honor Ubisoft Entertainment Ubisoft Montreal Hellblade: Senua's Sacrifice Ninja Theory Ninja Theory Horizon Zero Dawn Sony Interactive Entertainment America Guerrilla Games Uncharted: The Lost Legacy Sony Interactive Entertainment America Naughty Dog LLC Outstanding Achievement in Art Direction Cuphead StudioMDHR StudioMDHR Hellblade: Senua's Sacrifice Ninja Theory Ninja Theory Horizon Zero Dawn Sony Interactive Entertainment America Guerrilla Games Little Nightmares BANDAI NAMCO Entertainment America Inc. Tarsier Studios The Legend of Zelda: Breath of the Wild Nintendo Nintendo Outstanding Achievement in Character Assassin's Creed Origins ‐ Bayek Ubisoft Entertainment Ubisoft Entertainment Hellblade: Senua's Sacrifice ‐ Senua Ninja Theory Ninja Theory Horizon Zero Dawn ‐ Aloy Sony Interactive Entertainment America Guerrilla Games Star Wars Battlefront II ‐ Iden Versio Electronic Arts DICE, Motive Studios, and Criterion Games Uncharted: The Lost Legacy ‐ Chloe Fraiser Sony Interactive Entertainment America Naughty Dog LLC Outstanding Achievement in Original Music Composition Call of Duty: WWII Activision Sledgehammer Games Cuphead StudioMDHR StudioMDHR Horizon Zero Dawn Sony Interactive Entertainment America Guerrilla Games RiME Grey Box Tequila Works Wolfenstein II: The New Colossus Bethesda Softworks MachineGames Outstanding Achievement in Sound Design Destiny -

Lone Echo and the Magic of Vr
ARTISTRY IN A NEW MEDIUM: LONE ECHO AND THE MAGIC OF VR NATHAN PHAIL-LIFF | ART DIRECTOR | READY AT DAWN Topics Covered . Magic (and challenges) of the Medium • Immersion, presence, and storytelling • Social interactions and multiplayer • Content challenges of the medium . Environmental design considerations for VR • New artistic considerations for VR • Balancing style for aesthetics and comfort . Avatar design for presence • Unique challenges of avatar design in VR • Robot roleplaying: attempting to build a vessel for everyone Studio History . Founded in 2003 . Developed Daxter, God of War: Chains of Olympus, and God of War: Ghost of Sparta for the PSP . Built all new engine and tools from scratch for first original IP, The Order: 1886 . Recently shipped Deformers, original IP MOBA (released across PS4, XB1, and PC) 2006 2008 2010 2015 2017 Lone Echo / Echo Arena . Development began mid 2015 . Team size of about 45 . Built on engine from The Order: 1886 . Born out of idea for comfortable, free locomotion . Additional goals and challenges • AAA quality, but made ground-up for VR • Ambitious visuals, aggressive perf target • Not so ‘Lone Echo’ 2017 Part I: LONE ECHO AND THE MAGIC OF VR THE MAGIC OF THE MEDIUM Magic of the Medium: Presence and Immersion . Complete suspension of disbelief . More direct relationship with virtual world Magic of the Medium: Presence and Immersion . Complete suspension of disbelief . More direct relationship with virtual world . Real dreams and formed memories from a virtual experience Magic of the Medium: Characters and Storytelling . Forming an emotional bond with a virtual character . Richer acknowledgement of player presence Magic of the Medium: Characters and Storytelling Magic of the Medium: Characters and Storytelling Magic of the Medium: Characters and Storytelling See SIGGRAPH 2015 Character Session: readyatdawn.com/presentations/ Magic of the Medium: Characters and Storytelling . -

Ray Tracing Gems II Next Generation Real-Time Rendering with DXR, Vulkan, and Optix
Ray Tracing Gems II Next Generation Real-Time Rendering with DXR, Vulkan, and OptiX Edited by Adam Marrs, Peter Shirley, and Ingo Wald Section Editors Per Christensen David Hart Thomas Müller Jacob Munkberg Angelo Pesce Josef Spjut Michael Vance Cem Yuksel Ray Tracing Gems II: Next Generation Real-Time Rendering with DXR, Vulkan, and OptiX Edited by Section Editors Adam Marrs Per Christensen Angelo Pesce Peter Shirley David Hart Josef Spjut Ingo Wald Thomas Müller Michael Vance Jacob Munkberg Cem Yuksel ISBN-13 (pbk): 978-1-4842-7184-1 ISBN-13 (electronic): 978-1-4842-7185-8 https://doi.org/10.1007/978-1-4842-7185-8 Copyright © 2021 by NVIDIA Trademarked names, logos, and images may appear in this book. Rather than use a trademark symbol with every occurrence of a trademarked name, logo, or image we use the names, logos, and images only in an editorial fashion and to the beneft of the trademark owner, with no intention of infringement of the trademark. The use in this publication of trade names, trademarks, service marks, and similar terms, even if they are not identifed as such, is not to be taken as an expression of opinion as to whether or not they are subject to proprietary rights. While the advice and information in this book are believed to be true and accurate at the date of publication, neither the authors nor the editors nor the publisher can accept any legal responsibility for any errors or omissions that may be made. The publisher makes no warranty, express or implied, with respect to the material contained herein. -

Level Design in Virtual Reality
Level Design in Virtual Reality Veikka Saaristo BACHELOR’S THESIS November 2020 Degree Programme in Business Information Systems Game Development ABSTRACT Tampereen ammattikorkeakoulu Tampere University of Applied Sciences Degree Programme in Business Information Systems Game Development SAARISTO, VEIKKA: Level Design in Virtual Reality Bachelor's thesis 68 pages November 2020 This thesis studies level design methodology and best practices regarding both traditional and virtual reality level design, as well as the author’s own professional experience as a virtual reality level designer with the objective of creating a custom map extension to Half-Life: Alyx (Valve 2020). The purpose of this thesis was to introduce virtual reality level design and to display how virtual reality levels are designed and created through a documented example. The thesis focuses on methods and practices that are applicable to work outside of a specific engine or editor. Data was collected from various sources, including several online publications, the individual views of industry professionals, developer websites of headset fabricators, and from literature. The map extension was created as a part of this thesis. It was developed using Valve’s own Hammer editor, which enabled building the level based on an original design. In addition to theory, this thesis addresses the design and creation of this map extension, offering excerpts from the process in form of in-editor screenshots and descriptions. During the creation of this thesis, the superiority of the Hammer editor compared to other editors and game engines used before was noted due to its first-class built-in level design tools. Learning a new work environment from the beginning and the choice of virtual reality headset used in the development proved challenging as the older Oculus Rift headset caused issues while working with a game as new as the one used as the case study. -

Investigation of Competition in Digital Markets, the Subcommittee Conducted a Thorough Examination of the Adequacy of Current Laws and Enforcement Levels
MAJORITY STAFF SUBCOMMITTEE ON ANTITRUST, COMMERCIAL AND ADMINISTRATIVE LAW SLADE BOND Chief Counsel LINA KHAN AMANDA LEWIS Counsel Counsel on Detail, Federal Trade Commission PHILLIP BERENBROICK ANNA LENHART Counsel Technologist JOSEPH EHRENKRANTZ CATHERINE LARSEN Special Assistant Special Assistant JOSEPH VAN WYE Professional Staff Member COMMITTEE ON THE JUDICIARY PERRY APELBAUM AMY RUTKIN JOHN DOTY Staff Director and Chief Counsel Chief of Staff Senior Advisor AARON HILLER JOHN WILLIAMS DAVID GREENGRASS Deputy Chief Counsel Parliamentarian Senior Counsel SHADAWN REDDICK-SMITH DANIEL SCHWARZ ARYA HARIHARAN Communications Director Director of Strategic Communications Deputy Chief Oversight Counsel JESSICA PRESLEY MOH SHARMA MATTHEW ROBINSON Director of Digital Strategy Director of Member Services and Counsel MADELINE STRASSER Outreach & Policy Advisor KAYLA HAMEDI Chief Clerk Deputy Press Secretary NATHAN ADAL BENJAMIN FEIS ARMAN RAMNATH Legal Fellow Legal Fellow Legal Fellow KARNA ADAM CORY GORDON REED SHOWALTER Legal Fellow Legal Fellow Legal Fellow WILLIAM BEKKER ETHAN GURWITZ JÖEL THOMPSON Legal Fellow Legal Fellow Legal Fellow KYLE BIGLEY DOMENIC POWELL KURT WALTERS Legal Fellow Legal Fellow Legal Fellow MICHAEL ENSEKI-FRANK KRYSTALYN WEAVER Legal Fellow Legal Fellow TABLE OF CONTENTS A. Chairs’ Foreword ....................................................................................................................... 6 B. Executive Summary .................................................................................................................. -

V7.20 Patch Notes |
IMAGE: TENCENT IMAGE: V7.20 PATCH NOTES | NOTES PATCH V7.20 JULY 2020 REPORT MICROSOFT, TENCENT AND MORE BIG TAKEAWAYS PAGE 3 A quick summary of what stood out to us TABLE OF TRENDING PAGE 4 Trends we saw in the past month and the impact we expect them to have BRAND ACTIVATIONS PAGE 9 Interesting activations from some nonendemic brands OTHER IMPORTANTS PAGE 12 A hodgepodge of information from data to missteps PAGE 2 BIG TAKEAWAYS Powerhouse brands are making big moves to solidify their future in gaming. Nonendemic brands continue to look for ways to create in-game experiences. Even the biggest names in gaming and politics aren’t immune to criticism or Twitch bans. JULY 2020 More apparel brands are seeing the opportunity to JULY 2020 attach themselves to the gaming industry. IMAGE: NAUGHTY DOG JULY 2020 JULY 2020 PAGE 3 TRENDING NO.001 SECTION WHAT’S INCLUDED A collection of new and interesting things that caught our attention last month. IMAGE: THE WALL STREET JOURNAL MICROSOFT SHAKES THINGS UP IMAGE: S0APY WHAT HAPPENED WHY IT MATTERS With the next generation of consoles on the horizon, Microsoft While Microsoft's retail locations were not nearly as successful as Apple's, it 001 is making major organizational shifts. All of Microsoft's physical was surprising to see them close before the release of the Xbox Series X. NO. retail stores have closed except for four locations that were Mixer closing was even more shocking. Microsoft made waves in the renamed to "Experience Centers." Then we saw the end of livestreaming industry by signing Ninja, Shroud and other prominent talents Microsoft's livestreaming platform Mixer and the beginning of a to exclusive contracts. -

The Secret Sauce of Indie Games
EVERY ISSUE INCL. COMPANY INDEX 03-04/2017 € 6,90 OFFICIAL PARTNER OF DESIGN BUSINESS ART TECHNOLOGY THE SECRET SAUCE OF FEATURING NDIEThe Dwarves INDIE GAMES Can‘t Drive This I Cubiverse Savior GAMES GREENLIGHT BEST PRACTICE: TIPS TO NOT GET LOST ON STEAM LEVEL ARCHITECTURE CASE STUDY GREENLIGHT POST MORTEM INTERVIEW WITH JASON RUBIN HOW THE LEVEL DESIGN AFFECTS HOW WINCARS RACER GOT OCULUS‘ HEAD OF CONTENT ABOUT THE DIFFICULTY LEVEL GREENLIT WITHIN JUST 16 DAYS THE LAUNCH AND FUTURE OF VR Register by February 25 to save up to $300 gdconf.com Join 27,000 game developers at the world’s largest professional game industry event. Learn from experts in 500 sessions covering tracks that include: Advocacy Monetization Audio Production & Team Management Business & Marketing Programming Design Visual Arts Plus more than 50 VR sessions! NEW YEAR, NEW GAMES, NEW BEGINNINGS! is about 1.5 the world on edge with never-ending ques- months old, tionable decisions. Recently, Trump’s Muslim Dirk Gooding and just ban for entry into the United States caused Editor-in-Chief of Making Games Magazin within these mass protests and numerous reactions by few weeks it the international games industry which is seemed that negatively affected by such a ban in a not-to- 2017one news followed the other. The first big be underestimated way. Will 2017 be another conferences and events like Global Game troublesome year? Before Christmas, we Jam, PAX South, GIST, Casual Connect or asked acclaimed experts and minds of the White Nights in Prague are over, but the German games industry to name their tops planning for the next events like QUO and flops, desires and predictions – for both Nico Balletta VADIS and our very own Making Games last and this year.