Msc Thesis VIBOT Sign Language Translator Using Microsoft Kinect XBOX 360TM
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Get Ubuntu Software Center
Get ubuntu software center I believe the Ubuntu Software Centre was replaced by the GNOME Software if not then try to get the packages sudo apt-get *software-center*. Ubuntu Software Center lets you browse and install thousands of free and paid applications It also appears to take longer to install than an apt-get command. Ubuntu Software Center is a one-stop shop for installing and removing you can find it by clicking the Ubuntu button, then “More Apps”, then. How To Install ubuntu Software Center On Any Linux OS Command apt-get install software. Open Terminal: sudo apt update sudo apt install software-properties-gtk # for Software & Updates sudo apt install software-center # for Ubuntu. So I want to install Ubuntu Software Center. Pls tell me how to install it on terminal I need an apt-get command . Waiting thanks![ubuntu] cant find wine in software center - Ubuntu Forums. You can easily find and install software, and purchase commercial software. You can rate and review software, and these ratings are used to rank software by. The Ubuntu Software Center is an app interface that allows you to both manage and sudo apt-get --purge --reinstall install software-center. In order to get the most out of the Software Centre you should read this guide which shows how to add extra repositories within Ubuntu. Ubuntu Software Center is a free application created by Canonical that allows you You will also find the corresponding controls for installing or uninstalling the. To do this, first configure the Ubuntu Software Center to allow software packaged by Canonical for their partners. -

Technology User Guide Volume III: DRC INSIGHT
Technology User Guide Volume III: DRC INSIGHT WISCONSIN Data Recognition Corporation (DRC) 13490 Bass Lake Road Maple Grove, MN 55311 Wisconsin Service Line: 1-800-459-6530 DRC INSIGHT Portal: https://wi.drcedirect.com Email: [email protected] Revision Date: November 12, 2020 COPYRIGHT Copyright © 2020 Data Recognition Corporation The following items in DRC INSIGHT are protected by copyright law: • The User Guide. • All text and titles on the software’s entry and display, including the look and feel of the interaction of the windows, supporting menus, pop-up windows, and layout. DRC INSIGHT Online Learning System and DRC INSIGHT Portal are trademarked by Data Recognition Corporation. Any individuals or corporations who violate these copyrights and trademarks will be prosecuted under both criminal and civil laws, and any resulting products will be required to be withdrawn from the marketplace. The following are trademarks or registered trademarks of Microsoft Corporation in the United States and/or other countries: Internet Explorer Microsoft Windows Windows Vista Windows XP Windows 7 Windows 8 Windows 10 The following are trademarks or registered trademarks of Apple Corporation in the United States and/or other countries: Apple Macintosh Mac OS X and macOS iPad iPadOS iOS* *iOS is a trademark or registered trademark of Cisco in the U.S. and other countries and is used under license. Safari The following are trademarks or registered trademarks of Google Corporation in the United States and/or other countries. Chrome Chromebook Google Play The following is a trademark or registered trademark of Mozilla Corporation in the United States and/or other countries. -

2.5 the Ubuntu Operating System 7
By Courtney Loo http://courtneyloo.wordpress.com Edited by Justin Pot This manual is the intellectual property of MakeUseOf. It must only be published in its original form. Using parts or republishing altered parts of this guide is prohibited without permission from MakeUseOf.com Think you’ve got what it takes to write a manual for MakeUseOf.com? We’re always willing to hear a pitch! Send your ideas to [email protected]; you might earn up to $400. UBUNTU: AN ABSOLUTE BEGINNER’S GUIDE Table Of Contents 1. Introduction 5 2. Ubuntu 101 6 2.1 What Is Ubuntu? 6 2.2 The Ubuntu Philosophy 6 2.3 Proprietary Software vs Free/Libre Open-Source Software 6 2.4 How Can Ubuntu Be Free? 7 1. It’s Maintained By The FLOSS Community. 7 2. It’s Managed & Funded By Canonical 7 2.5 The Ubuntu Operating System 7 Linux: The Dreaded ‘L’ Word 7 What Is The Linux Kernel? 7 How Then Are Ubuntu & Linux Related? 8 2.6 Why Use Ubuntu? 8 3. Ubuntu Releases 9 3.1 Ubuntu Version Numbers 9 3.2 Ubuntu Code Names 9 3.3 Normal Releases vs. Long Term Support (LTS) Releases 9 4. Installing Ubuntu 10 4.1 Different Ways To Install Ubuntu 10 4.2 Installing Ubuntu Alongside Windows 7 With Wubi 10 What Is Wubi? 10 What Does Wubi Do? 10 5. Support & Community 14 5.1 Ubuntu Local Communities 14 Get Involved! 14 5.2 Free Documentation 14 Official Documentation 14 Community Documentation 15 5.3 Launchpad Answers 15 What Is Launchpad ? 15 HTTP://MAKEUSEOF.COM HTTP://COURTNEYLOO.WORDPRESS.COM, COURTNEY LOO 3 UBUNTU: AN ABSOLUTE BEGINNER’S GUIDE Why Should You Use Launchpad Answers? 15 6. -

Praise for the Official Ubuntu Book
Praise for The Official Ubuntu Book “The Official Ubuntu Book is a great way to get you started with Ubuntu, giving you enough information to be productive without overloading you.” —John Stevenson, DZone Book Reviewer “OUB is one of the best books I’ve seen for beginners.” —Bill Blinn, TechByter Worldwide “This book is the perfect companion for users new to Linux and Ubuntu. It covers the basics in a concise and well-organized manner. General use is covered separately from troubleshooting and error-handling, making the book well-suited both for the beginner as well as the user that needs extended help.” —Thomas Petrucha, Austria Ubuntu User Group “I have recommended this book to several users who I instruct regularly on the use of Ubuntu. All of them have been satisfied with their purchase and have even been able to use it to help them in their journey along the way.” —Chris Crisafulli, Ubuntu LoCo Council, Florida Local Community Team “This text demystifies a very powerful Linux operating system . in just a few weeks of having it, I’ve used it as a quick reference a half dozen times, which saved me the time I would have spent scouring the Ubuntu forums online.” —Darren Frey, Member, Houston Local User Group This page intentionally left blank The Official Ubuntu Book Sixth Edition This page intentionally left blank The Official Ubuntu Book Sixth Edition Benjamin Mako Hill Matthew Helmke Amber Graner Corey Burger With Jonathan Jesse, Kyle Rankin, and Jono Bacon Upper Saddle River, NJ • Boston • Indianapolis • San Francisco New York • Toronto • Montreal • London • Munich • Paris • Madrid Capetown • Sydney • Tokyo • Singapore • Mexico City Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. -
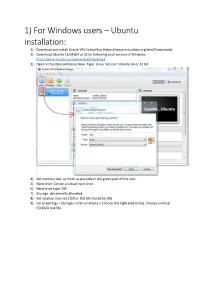
1) for Windows Users – Ubuntu Installation: 1) Download and Install Oracle VM Virtual Box (
1) For Windows users – Ubuntu installation: 1) Download and install Oracle VM Virtual Box (https://www.virtualbox.org/wiki/Downloads). 2) Download Ubuntu 16.04 (64 or 32 bit following your version of Windows, http://www.ubuntu.com/download/desktop) 3) Open Virtual Box and press New. Type: Linux. Version: Ubuntu 64 or 32 bit. 4) Set memory size: as much as possible in the green part of the rule. 5) Hard drive: Create a virtual hard drive. 6) Hard drive type: VDI. 7) Storage: dynamically allocated. 8) Set location and size (100 or 200 GB should be OK). 9) Go to Settings > Storage > Click on Empty > Click on the right (red circle): Choose a virtual CD/DVD disk file. 10) Select the “.iso” file you previously downloaded in step 2 and containing Ubuntu, then OK. 11) Click on Start in the main menu to launch the Virtual Machine. 12) Click on Install Ubuntu. 13) Preparing to install Ubuntu: click on Continue (no need to install third-party software). 14) Installation type: Select “Erase disk and Install Ubuntu” and continue the process until the beginning of Ubuntu installation. 15) When installation is finished, restart. 16) Press Enter. 17) Write down your password and enter Ubuntu. 2) Downloading GRASS GIS: 1) Type Ctrl+Alt+T to open a terminal. 2) Write in the terminal: sudo apt-get install grass 3) Write grass in the terminal to open GRASS GIS. 4) Go to Desktop, right click and create a new folder called grassdata. 4) Go back to GRASS, click on Browse, and select grassdata folder. -

How to Develop Android Apps Under Linux (Ubuntu) Install Ubuntu Linux
How to develop Android Apps under Linux (Ubuntu) Install Ubuntu Linux alongside with Windows 1. First install Windows. Let an empty partition of minumum 10 GB at the end of all Windows partitions or resize the last Windows partition with Windows Disk Manager to get an non- partitioned space the end of all Windows partitions. 2. For Windows XP: Download from the Ubuntu download section the latest 32-bit or 64-bit version of the .iso image. To create an Ubuntu boot CD: Install on Windows PC InfraRecorder from Internet Start it and select Write Image. Burn the image to an empty CD. 3. For Win7: Right-click on .iso image and select Burn to CD/DVD. 4. Boot with CD (change the boot order in BIOS if necessary). Press Enter to get the Language Menu and select your language (English). 5. Select Install Ubuntu. 6. Select Install Ubunty alongside with Windows (should install on free disk space) (If the system hangs during boot-up, see appendix.) 7. Select Menu Applications | Ubuntu Software Center. Select Menu Edit | Software Sources. Enter password. Select Tab Other Software and check the two upper check boxes. Press Close. 8. In Ubuntu Software Center Type in Search “startupmanager”. Download and install. 9. Select Menu System | Administration | Startup-Manager. In Dialog Field “Default operation system” select what you want, e.g. Windows. 10. For 64-bit systems: Ubuntu Software Center: Search Aptitude and install this packet manager Start Aptitude (Menu System | Administration). Search ia32. Select ia32-libs and press Install ia32-libs version xxx. (Alternative: Execute in shell sudo apt-get install ia32-libs). -

Install Gnome Software Center Arch
Install gnome software center arch Upstream URL: License(s): GPL2. Maintainers: Jan Steffens. Package Size: MB. Installed Size: Installed Size: MB. gnome-software will be available as a preview in It can install, remove applications on systems with PackageKit. It can install updates on Gnome software will not start / Applications & Desktop. A quick video on Gnome Software Center in Arch Linux. Gnome unstable repository. There is a component called Polkit that is used by many applications to request root permissions to do things (it can do so because it's a. GNOME Software on #archlinux with native PackageKit backend, and this is a gui for installing software, ala ubuntu software manager, but distro This is some kind of Ubuntu Software Centre, with comments and all that. Need help installing Gnome Software Center for Arch Linux? Here are some instructions: Click DOWNLOAD HERE in the menu. Download the file. Make the file. I had to install it with along with packagekit. This is what's missing to make Antergos *the* beginner-friendly Arch-based distro, or general So, it is not a bad idea for the “Gnome Software Center” to include by default. GNOME software software center graphic that we will find the default in future releases of Fedora in addition to being installed in Arch Linux Please help me to install GNOME Software on. GNOME Software Will Work On Arch Linux With PackageKit the Alpm/Pacman back-end for using this GNOME application to install and. From: Sriram Ramkrishna ; To: desktop-devel-list devel-list gnome org>; Subject: gnome- software/packagekit. -

Installation Guide for Linux®
DNASTAR® SeqMan NGen® ® Installation Guide for Linux DNASTAR, Inc. 2014 Before You Begin We’re here to help! If you have any difficulties with or questions about installation, please contact a DNASTAR support representative: • E-mail: [email protected] • Phone (Madison, WI, USA): 608-258-7420 • In the USA and Canada, call toll free: 1-866-511-5090 • In the UK, call free on: 0-808-234-1643 • In Germany, call free on: 0-800-182-4747 This document pertains to SeqMan NGen® version 12 and was last updated on September 15, 2014. For copyright and trademark information, please see the Legal Information page of our website. Technical Requirements For requirements related to the installation of SeqMan NGen, please refer to our SeqMan NGen Technical Requirements web page. Administrator privileges are required to perform this installation. 2 SeqMan NGen Installation Guide for Linux Installing and Uninstalling Via the Graphical User Interface SeqMan NGen may be installed/uninstalled via the Graphical User Interface (pp. 3-4) or via the Terminal (pp. 5-6). Both methods require administrator rights. CentOS users should note that the RPM package of SeqMan NGen Linux is digitally signed using GNU Privacy Guard (GPG). Installing a Public Key before you install SeqMan NGen lets you verify that the software is a genuine DNASTAR product. CentOS users who do not have the Public Key will receive a warning message during installation. You can safely ignore this warning and continue with the installation. If you wish to install the Public Key, you must have administrator rights. Download the key from our website to your desktop. -

Linux and Amateur Radio By: Dave Mamanakis, KD7GR
Linux and Amateur Radio By: Dave Mamanakis, KD7GR What Is Linux Linux is a free and Open Source Operating System for Computers, not unlike Windows (by Microsoft) or MacOS (by Apple). There are a great many differences between them, though... more than just "cost": Linux tends to be stable on just about any hardware, both PC and Mac. Linux is also capable of running on older hardware (that old PC you don't know what to do with). Linux can and does also run on Phones and Tablets (Android is a form of Linux). There are also a lot of similarities: Linux has a UI (but can also be run like DOS of yesteryear). Linux can run all manner of programs It uses a keyboard, mouse, and works with most other hardware, speakers, etc. Flavors of Linux Linux also comes in a variety of roots: Debian Slackware Red Hat Each of these roots have spawned sub distributions: Ubuntu, Knoppix SUsE Mandrake, Fedora Core, CentOS And in succession, each of these subs have spawned other distros: Mint openSUsE Mandria, Mageia There are others, too, which are independent: Puppy Arch Computers in Amateur Radio Amateur Radio has been around longer than Computers Natural evolution, curiosity and good old-fashioned ingenuity has brought Radios and Computers together (in more than one way) Everything from Hardware and Software that allows your computer to interface with your radio: To Hardware and Software that allows you to turn your computer into a radio: Radio in Computers And even Radio Communications used exclusively for Computers: Bluetooth and WiFi are 5 or 2.4 GHz Bluetooth is on the ISM band that is 83 MHz-wide. -

Gaikai - Wikipedia Case 3:19-Cv-07027-WHA Document 28-2 Filed 10/14/19 Page 2 of 8 Not Logged in Talk Contributions Create Account Log In
Case 3:19-cv-07027-WHA Document 28-2 Filed 10/14/19 Page 1 of 8 EXHIBIT B Gaikai - Wikipedia Case 3:19-cv-07027-WHA Document 28-2 Filed 10/14/19 Page 2 of 8 Not logged in Talk Contributions Create account Log in Article Talk Read Edit View history Gaikai From Wikipedia, the free encyclopedia Main page Gaikai (外海, lit. "open sea", i.e. an expansive outdoor space) is an American company which provides technology for the streaming of high- Contents Gaikai Featured content end video games.[1] Founded in 2008, it was acquired by Sony Interactive Entertainment in 2012. Its technology has multiple applications, Current events including in-home streaming over a local wired or wireless network (as in Remote Play between the PlayStation 4 and PlayStation Vita), as Random article well as cloud-based gaming where video games are rendered on remote servers and delivered to end users via internet streaming (such as Donate to Wikipedia the PlayStation Now game streaming service.[2]) As a startup, before its acquisition by Sony, the company announced many partners using Wikipedia store [3] the technology from 2010 through 2012 including game publishers, web portals, retailers and consumer electronics manufacturers. On July Founded November 2008 Interaction 2, 2012, Sony announced that a formal agreement had been reached to acquire the company for $380 million USD with plans of establishing Headquarters Aliso Viejo, California, U.S. [4] Help their own new cloud-based gaming service, as well as integrating streaming technology built by Gaikai into PlayStation products, resulting Owner Sony [5] [6] About Wikipedia in PlayStation Now and Remote Play. -

From Windows to Ubuntu & Ticket to Read Instructions
From Windows to Ubuntu & Ticket to Read Instructions This document is intended to help you use your new computer by helping you understand the Ubuntu Operating system that is installed on it and most often relating it to the same Windows feature that you are more likely to be familiar with. Keep in mind that this is more of a simple starter document, if you want to research more about these topics I would encourage it and let you know that Google [ www.google.com ] is your friend J At the bottom of this document you will find instructions for using www.tickettoread.com as well as other websites requiring Adobe Flash player. Index 1. Setting up your computer. a. Plugging your computer in b. Logging on/Changing your account name/password 2. The Desktop 3. Common Relations to Windows 4. Updating your computer 5. Running Programs in Ubuntu 6. Microsoft Office to LibreOffice 7. Getting New Ubuntu Programs 8. Running Windows Programs (Wine) 9. Help Resources 10. About Ubuntu and Operating Systems 1. Setting up your computer Plugging your computer in: Your computer will need several things attached to it in order for it to work for you. You will need a power supply box, it is about half the size of the computer itself with two cables coming out of it. They a monitor, mouse and keyboard. These plug in relatively straight forward into their own distinctive sockets. Just remember that the computer and monitor will need to plug into the wall to get power, otherwise everything plugs into the computer itself. -

Gaming on Ubuntu
Gaming On Ubuntu by iheartubuntu It's 2012 already. Lets play some games. Gaming in Ubuntu has come a long way. You no longer have to spend hours on the internet searching for games that work on Ubuntu. Nor do you need to learn distro packaging or learn how to compile programs from the terminal. It is now easy to find and install games. Great games. Lets take a look... Where to find new & breaking information about games There are several websites that offer great news & info about Ubuntu games. These websites usually will provide links to download the games and instructions on how to install. OMG! Ubuntu! http://omgubuntu.co.uk/ I Heart Ubuntu http://www.iheartubuntu.com/ Linux Games http://www.linuxgames.com/ Full Circle Magazine http://fullcirclemagazine.org/ OMG! Ubuntu! has breaking news about recently released Ubuntu games and is a great source of info. I Heart Ubuntu loves to cover legacy games like chess and backgammon. Linux Games always has up to date game info, and Full Circle Magazine has great in depth reviews of games. Where to Find Ubuntu Games There are now several places to find games that will work on Ubuntu. The Ubuntu Software Center is packed full of games to keep you busy. It's that little orange shopping bag icon on your Unity dash. The Desura.com game distribution website has high quality games available for Ubuntu. Many of the hottest games are now appearing there first. http://www.desura.com/platforms/set/linux64 Humble Bundle continues to release fresh new game content and gives you the choice of how much to spend and where to allocate your payment (to developers, to charity, etc) http://www.humblebundle.com/ Playdeb.net caters to the Ubuntu gamer and attempts to make it easy to find, browse and install Ubuntu games.