Integrating Life History Traits Into Predictive Phylogeography
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Interior Columbia Basin Mollusk Species of Special Concern
Deixis l-4 consultants INTERIOR COLUMl3lA BASIN MOLLUSK SPECIES OF SPECIAL CONCERN cryptomasfix magnidenfata (Pilsbly, 1940), x7.5 FINAL REPORT Contract #43-OEOO-4-9112 Prepared for: INTERIOR COLUMBIA BASIN ECOSYSTEM MANAGEMENT PROJECT 112 East Poplar Street Walla Walla, WA 99362 TERRENCE J. FREST EDWARD J. JOHANNES January 15, 1995 2517 NE 65th Street Seattle, WA 98115-7125 ‘(206) 527-6764 INTERIOR COLUMBIA BASIN MOLLUSK SPECIES OF SPECIAL CONCERN Terrence J. Frest & Edward J. Johannes Deixis Consultants 2517 NE 65th Street Seattle, WA 98115-7125 (206) 527-6764 January 15,1995 i Each shell, each crawling insect holds a rank important in the plan of Him who framed This scale of beings; holds a rank, which lost Would break the chain and leave behind a gap Which Nature’s self wcuid rue. -Stiiiingfieet, quoted in Tryon (1882) The fast word in ignorance is the man who says of an animal or plant: “what good is it?” If the land mechanism as a whole is good, then every part is good, whether we understand it or not. if the biota in the course of eons has built something we like but do not understand, then who but a fool would discard seemingly useless parts? To keep every cog and wheel is the first rule of intelligent tinkering. -Aido Leopold Put the information you have uncovered to beneficial use. -Anonymous: fortune cookie from China Garden restaurant, Seattle, WA in this “business first” society that we have developed (and that we maintain), the promulgators and pragmatic apologists who favor a “single crop” approach, to enable a continuous “harvest” from the natural system that we have decimated in the name of profits, jobs, etc., are fairfy easy to find. -

Comprehensive Conservation Plan Benton Lake National Wildlife
Glossary accessible—Pertaining to physical access to areas breeding habitat—Environment used by migratory and activities for people of different abilities, es- birds or other animals during the breeding sea- pecially those with physical impairments. son. A.D.—Anno Domini, “in the year of the Lord.” canopy—Layer of foliage, generally the uppermost adaptive resource management (ARM)—The rigorous layer, in a vegetative stand; mid-level or under- application of management, research, and moni- story vegetation in multilayered stands. Canopy toring to gain information and experience neces- closure (also canopy cover) is an estimate of the sary to assess and change management activities. amount of overhead vegetative cover. It is a process that uses feedback from research, CCP—See comprehensive conservation plan. monitoring, and evaluation of management ac- CFR—See Code of Federal Regulations. tions to support or change objectives and strate- CO2—Carbon dioxide. gies at all planning levels. It is also a process in Code of Federal Regulations (CFR)—Codification of which the Service carries out policy decisions the general and permanent rules published in the within a framework of scientifically driven ex- Federal Register by the Executive departments periments to test predictions and assumptions and agencies of the Federal Government. Each inherent in management plans. Analysis of re- volume of the CFR is updated once each calendar sults helps managers decide whether current year. management should continue as is or whether it compact—Montana House bill 717–Bill to Ratify should be modified to achieve desired conditions. Water Rights Compact. alternative—Reasonable way to solve an identi- compatibility determination—See compatible use. -

2010 Animal Species of Concern
MONTANA NATURAL HERITAGE PROGRAM Animal Species of Concern Species List Last Updated 08/05/2010 219 Species of Concern 86 Potential Species of Concern All Records (no filtering) A program of the University of Montana and Natural Resource Information Systems, Montana State Library Introduction The Montana Natural Heritage Program (MTNHP) serves as the state's information source for animals, plants, and plant communities with a focus on species and communities that are rare, threatened, and/or have declining trends and as a result are at risk or potentially at risk of extirpation in Montana. This report on Montana Animal Species of Concern is produced jointly by the Montana Natural Heritage Program (MTNHP) and Montana Department of Fish, Wildlife, and Parks (MFWP). Montana Animal Species of Concern are native Montana animals that are considered to be "at risk" due to declining population trends, threats to their habitats, and/or restricted distribution. Also included in this report are Potential Animal Species of Concern -- animals for which current, often limited, information suggests potential vulnerability or for which additional data are needed before an accurate status assessment can be made. Over the last 200 years, 5 species with historic breeding ranges in Montana have been extirpated from the state; Woodland Caribou (Rangifer tarandus), Greater Prairie-Chicken (Tympanuchus cupido), Passenger Pigeon (Ectopistes migratorius), Pilose Crayfish (Pacifastacus gambelii), and Rocky Mountain Locust (Melanoplus spretus). Designation as a Montana Animal Species of Concern or Potential Animal Species of Concern is not a statutory or regulatory classification. Instead, these designations provide a basis for resource managers and decision-makers to make proactive decisions regarding species conservation and data collection priorities in order to avoid additional extirpations. -
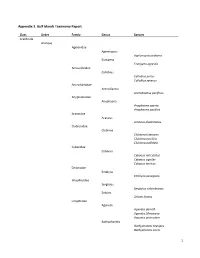
1 Appendix 3. Gulf Islands Taxonomy Report
Appendix 3. Gulf Islands Taxonomy Report Class Order Family Genus Species Arachnida Araneae Agelenidae Agelenopsis Agelenopsis utahana Eratigena Eratigena agrestis Amaurobiidae Callobius Callobius pictus Callobius severus Antrodiaetidae Antrodiaetus Antrodiaetus pacificus Anyphaenidae Anyphaena Anyphaena aperta Anyphaena pacifica Araneidae Araneus Araneus diadematus Clubionidae Clubiona Clubiona lutescens Clubiona pacifica Clubiona pallidula Cybaeidae Cybaeus Cybaeus reticulatus Cybaeus signifer Cybaeus tetricus Dictynidae Emblyna Emblyna peragrata Gnaphosidae Sergiolus Sergiolus columbianus Zelotes Zelotes fratris Linyphiidae Agyneta Agyneta darrelli Agyneta fillmorana Agyneta protrudens Bathyphantes Bathyphantes brevipes Bathyphantes keeni 1 Centromerita Centromerita bicolor Ceratinops Ceratinops latus Entelecara Entelecara acuminata Erigone Erigone aletris Erigone arctica Erigone cristatopalpus Frederickus Frederickus coylei Grammonota Grammonota kincaidi Linyphantes Linyphantes nehalem Linyphantes nigrescens Linyphantes pacificus Linyphantes pualla Linyphantes victoria Mermessus Mermessus trilobatus Microlinyphia Microlinyphia dana Neriene Neriene digna Neriene litigiosa Oedothorax Oedothorax alascensis Pityohyphantes Pityohyphantes alticeps Pocadicnemis Pocadicnemis pumila Poeciloneta Poeciloneta fructuosa Saaristoa Saaristoa sammamish Scotinotylus Scotinotylus sp. 5GAB Semljicola Semljicola sp. 1GAB Sisicottus Spirembolus Spirembolus abnormis Spirembolus mundus Tachygyna Tachygyna ursina Tachygyna vancouverana Tapinocyba Tapinocyba -

Abstract Volume
ABSTRACT VOLUME August 11-16, 2019 1 2 Table of Contents Pages Acknowledgements……………………………………………………………………………………………...1 Abstracts Symposia and Contributed talks……………………….……………………………………………3-225 Poster Presentations…………………………………………………………………………………226-291 3 Venom Evolution of West African Cone Snails (Gastropoda: Conidae) Samuel Abalde*1, Manuel J. Tenorio2, Carlos M. L. Afonso3, and Rafael Zardoya1 1Museo Nacional de Ciencias Naturales (MNCN-CSIC), Departamento de Biodiversidad y Biologia Evolutiva 2Universidad de Cadiz, Departamento CMIM y Química Inorgánica – Instituto de Biomoléculas (INBIO) 3Universidade do Algarve, Centre of Marine Sciences (CCMAR) Cone snails form one of the most diverse families of marine animals, including more than 900 species classified into almost ninety different (sub)genera. Conids are well known for being active predators on worms, fishes, and even other snails. Cones are venomous gastropods, meaning that they use a sophisticated cocktail of hundreds of toxins, named conotoxins, to subdue their prey. Although this venom has been studied for decades, most of the effort has been focused on Indo-Pacific species. Thus far, Atlantic species have received little attention despite recent radiations have led to a hotspot of diversity in West Africa, with high levels of endemic species. In fact, the Atlantic Chelyconus ermineus is thought to represent an adaptation to piscivory independent from the Indo-Pacific species and is, therefore, key to understanding the basis of this diet specialization. We studied the transcriptomes of the venom gland of three individuals of C. ermineus. The venom repertoire of this species included more than 300 conotoxin precursors, which could be ascribed to 33 known and 22 new (unassigned) protein superfamilies, respectively. Most abundant superfamilies were T, W, O1, M, O2, and Z, accounting for 57% of all detected diversity. -

Determining the Occurrence and Range of Deroceras Hesperium On
FY2012 ISSSP Report on Determining the Occurrence and Range of Deroceras hesperium* on the Willamette National Forest using Summer Surveys of Unique Habitats and Comparison of Summer Surveys versus Spring/Fall Mollusk Protocol Surveys for Detection of this Species Authored by Tiffany Young and Joe Doerr (Willamette National Forest). Dated 08/21/13. [*Note on Taxonomy: During the course of our study, a genetic investigation concluded that the Deroceras hesperium (the evening field slug) should be consider a junior synonym of Deroceras laeve (the meadow slug) (Roth et al. 2013). Our report, based on a study that began when two species were recognized, continues to use the original convention of referring to Deroceras with tripartite soles as D. hesperium and those with uniformly colored soles as D. laeve. We recognize the difficulty in making this distinction and our usage of the 2 species is not intended to imply that we consider them separate species. Moreover, in our study, both types used similar habitat and we have assumed that all detections help define the habitat preferences of both types.] Introduction: Prior to Roth et al. (2013,), Deroceras hesperium (DEHE) was considered a rare species in Region 6 with few documented locations at scattered sites in western Oregon. In 2008 it was listed as a “suspected” sensitive species on the Willamette NF because it had been found at nearby locations on Salem BLM. However, it has never been detected on the Willamette Forest itself, despite more than a decade of project mollusk surveys. Deroceras hesperium is also managed as a Category B sensitive species in Region 6 that requires equivalent effort surveys for habitat disturbing actions. -

Montana's State Wildlife Action Plan 2015
MONTANA’S STATE WILDLIFE ACTION PLAN MONTANA FISH, WILDLIFE & PARKS 2015 The mission of Montana Fish, Wildlife & Parks (FWP) is to provide for the stewardship of the fish, wildlife, parks, and recreational resources of Montana, while contributing to the quality of life for present and future generations. To carry out its mission, FWP strives to provide and support fiscally responsible programs that conserve, enhance, and protect Montana’s 1) aquatic ecotypes, habitats, and species; 2) terrestrial ecotypes, habitats, and species; and 3) important cultural and recreational resources. This document should be cited as Montana’s State Wildlife Action Plan. 2015. Montana Fish, Wildlife & Parks, 1420 East Sixth Avenue, Helena, MT 59620. 441 pp. EXECUTIVE SUMMARY Montana’s first State Wildlife Action Plan (SWAP), the Comprehensive Fish and Wildlife Conservation Strategy (CFWCS), was approved by the U.S. Fish and Wildlife Service in 2006. Since then, many conservation partners have used the plan to support their conservation work and to seek additional funding to continue their work. For Montana Fish, Wildlife & Parks (FWP), State Wildlife Grant (SWG) dollars have helped implement the strategy by supporting conservation efforts for many different species and habitats. This revision details implemented actions since 2006 (Appendix C). This SWAP identifies community types, Focal Areas, and species in Montana with significant issues that warrant conservation attention. The plan is not meant to be an FWP plan, but a plan to guide conservation throughout Montana. One hundred and twenty-eight Species of Greatest Conservation Need (SGCN) are identified in this revision. Forty-seven of these are identified as being in most critical conservation need. -

Figure S1. Maximum Likelihood Phylogenetic Tree of The
100 Cochlicopa 55 Vallonia 92 Pupilloidei Buliminus [= Orthurethra] Chondrina Arion 100 Arionoidei 66 Meghimatium Vitrina 100 Oxychilus Limacoidei 82 100 Euconulus Cryptozona Albinaria Clausilioidei Corilla [Corillidae] Plectopyloidea 70 Rhytida [Rhytididae] Helicina 53 Dorcasia [Dorcasiidae] [‘non-achatinoid clade’] Caryodes [Caryodidae] Rhytidoidei Megalobulimus Testacella Testacelloidea Drymaeus 94 Orthalicoidei Gaeotis 82 93 Satsuma Stylommatophora 100 Bradybaena Helicoidei Monadenia 87 93 84 Trochulus Haplotrema Haplotrematoidea 93 Euglandina Oleacinoidea Coeliaxis 92 Thyrophorella Achatina 92 Achatinina 100 Glessula Achatinoidea [‘achatinoid clade’] 100 Subulina Ferussacia 76 Gonaxis Streptaxoidea 100 Guestieria Systrophia Scolodontoidea Scolodontina Laevicaaulis Laemodonta ‘non-stylommatophoran Carychium pulmonates’ Siphonaria 1% 0.01 Figure S1. Maximum likelihood phylogenetic tree of the Stylommatophora based on concatenated sequences of 5782 unambiguously aligned nucleotides from the combined dataset of the LSU (and 5.8S) gene, the SSU gene, the H3 gene and the 1st and 2nd codon positions of the CO1 gene. The optimal model GTR+G was used. The phylogeny is rooted on the siphonariid Siphonaria pectinata. Values on the nodes represent bootstrap support (1000 replicates). Bootstrap support values less than 50% are not shown. The scale bar represents 1 substitutional change per 100 nucleotide positions. 1 91 Satsuma 100 Bradybaena Trochulus 97 Helicoidei 68 Monadenia 87 Haplotrema Haplotrematoidea Euglandina Oleacinoidea 100 Vallonia -

Terrestrial Mollusk Surveys on Region 1 USFS Lands
Terrestrial Mollusk Surveys on Region 1 USFS Lands Paul Hendricks, Bryce Maxell, Susan Lenard, Coburn Currier, and Ryan Kilacky Montana Natural Heritage Program http://nhp.nris.state.mt.us Globally Rare Land Snails Present on R1 Forests • Selway Forestsnail (Allogona lombardii) (ID) G1 • Dry Land Forestsnail (Allogona ptychophora solida) (ID)? G5T2T3 • Nimapuna Tigersnail (Anguispira nimapuna) (ID) G1 • Chrome Ambershell (Catinella rehderi) (MT, ID?) G1G2Q* • Salmon Oregonian (Cryptomastix harfordiana) (ID)? G3G4 • Mission Creek Oregonian (Cryptomastix magnidentata) (ID)? G1 • Oregonian (Cryptomastix mullani blandi) (ID)? G4T1 • River of No Return Oregonian (Cryptomastix mullani clappi) (ID) G4T1 • Kingston Oregonian (Cryptomastix sanburni) (ID)? G1 SUMMARY • Lake Disc (Discus brunsoni) (MT)? G1 • Marbled Disc (Discus marmorensis) (ID) G1G3 • 31 Species G1-G3 so USFS SOC • Striate Disc (Discus shimekii) (MT, ID?) G5 • 2 Species G5, but S1-S3 so USFS SOI • Salmon Coil (Helicodiscus salmonaceus) (ID) G1G2 • Alpine Mountainsnail (Oreohelix alpina) (MT) G1 • Bitterroot Mountainsnail (Oreohelix amariradix) (MT) G1G2 • Keeled Mountainsnail (Oreohelix carinifera) (MT) G1 • Carinate Mountainsnail (Oreohelix elrodi) (MT) G1 • Seven Devils Mountainsnail (Oreohelix hammeri) (ID) G1 • A Land Snail (Hells Canyon) (Oreohelix idahoensis baileyi) (ID) G1G2T1 • Costate Mountainsnail (Oreohelix idahoensis idahoensis) (ID)? G1G2T1T2 • Deep Slide Mountainsnail (Oreohelix intersum) (ID)? G1 • Boulder Pile Mountainsnail (Oreohelix jugalis) (ID)? G1 • Berry’s -

Snail and Slug Dissection Tutorial: Many Terrestrial Gastropods Cannot Be
IDENTIFICATION OF AGRICULTURALLY IMPORTANT MOLLUSCS TO THE U.S. AND OBSERVATIONS ON SELECT FLORIDA SPECIES By JODI WHITE-MCLEAN A DISSERTATION PRESENTED TO THE GRADUATE SCHOOL OF THE UNIVERSITY OF FLORIDA IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF DOCTOR OF PHILOSOPHY UNIVERSITY OF FLORIDA 2012 1 © 2012 Jodi White-McLean 2 To my wonderful husband Steve whose love and support helped me to complete this work. I also dedicate this work to my beautiful daughter Sidni who remains the sunshine in my life. 3 ACKNOWLEDGMENTS I would like to express my sincere gratitude to my committee chairman, Dr. John Capinera for his endless support and guidance. His invaluable effort to encourage critical thinking is greatly appreciated. I would also like to thank my supervisory committee (Dr. Amanda Hodges, Dr. Catharine Mannion, Dr. Gustav Paulay and John Slapcinsky) for their guidance in completing this work. I would like to thank Terrence Walters, Matthew Trice and Amanda Redford form the United States Department of Agriculture - Animal and Plant Health Inspection Service - Plant Protection and Quarantine (USDA-APHIS-PPQ) for providing me with financial and technical assistance. This degree would not have been possible without their help. I also would like to thank John Slapcinsky and the staff as the Florida Museum of Natural History for making their collections and services available and accessible. I also would like to thank Dr. Jennifer Gillett-Kaufman for her assistance in the collection of the fungi used in this dissertation. I am truly grateful for the time that both Dr. Gillett-Kaufman and Dr. -

The Morphology of the Reproductive Tracts of the Pacific Northwest Pulmonates
AN ABSTRACT OF THE THESIS OF Clarence Alan Porter for the M.S. in Zoology (Degree) (Major) Date thesis is presented /t ll.l / 5 / /(o L/ U Title The Morphology of the Reproductive Tracts of the Pacific Northwest Pulmonates Abstract approved (Major Professor) The morphology and taxonomic use of the reproductive tracts of some of the Pacific Northwest Pulmonates were studied. The snails examined were, Monadenia fidelis (Gray), Vespericola columbiana (Lea), Allogona townsendiana (Lea), Haplotrema sportella (Gould), and Haplotrema vancouverense (Lea). The length of the reproductive tracts of nine or more individuals of each species were measured in millimeters and these measurements were used as a quantitative means for identifying each species. Each snail not only varies in the length of specific structures, but also was seen to differ from others by the presence or absence and the position of certain structures. Some of the structures used to separate the species were: The muscular collar on the vagina in Haplotrema sportella and Haplotrema vancouverense, along with the size and shape of the talon; the presence or absence of a stimulator, verge, flagellum and epiphallus in Allogona townsendiana and Vespericola columbiana; and the presence of a dart, mucus gland, and mucus ejector in Monadenia fidelis. The use of reproductive tract data in taxonomy appears to provide a more accurate means of identifying species. It does not have the problems that are prevalent in shell characters, nor does it require the skill necessary in preparing and reading radula mounts. Combined with the other taxonomic characters it probably provides a better phylogenetic diagnosis of the various species. -

Effects of Forest Land Management on Terrestrial Mollusks: a Literature Review
Effects of Forest Land Management on Terrestrial Mollusks: A Literature Review Salmon coil, Helicodiscus salmonaceous. Photograph by William Leonard, used with permission. Sarah Foltz Jordan and Scott Hoffman Black The Xerces Society for Invertebrate Conservation Portland, Oregon February 2012 Under an Agreement With the Interagency Special Status and Sensitive Species Program USDA Forest Service, Region 6 and USDI Oregon/Washington Bureau of Land Management 1 Dedication: This report is dedicated to Suzanne Abele, 27 year old ecologist who tragically lost her life in an ATV accident August 18 th , 2011 while researching the impact of forestry practices on terrestrial snails and slugs. Although cut far too short, Suzanne's contributions to this field are significant and deeply appreciated. Foreword: National policies for the Forest Service (Forest Service Manual (FSM) Section 2670) and the Bureau of Land Management (BLM Manual Section 6840) establish categories of “Sensitive” species, where analysis is required to ensure the conservation of these species during land management actions. Under Forest Service policy, agency botanists and biologists complete a Biological Evaluation in which programs and activities are reviewed to determine their potential effects on Sensitive species. Proposed management actions “must not result in a loss of species viability or create significant trends toward Federal listing” (FSM 2670.32) of any Sensitive species. Similarly, under BLM policy, BLM personnel must assess, review and document the effects of a proposed action on Bureau Sensitive species. These effects are documented through a systematic, interdisciplinary evaluation following the decision making process as described in the National Environmental Policy Act of 1969. The BLM must also ensure that project decisions would not contribute to the need to list Bureau Sensitive species under the Endangered Species Act.