A Data-Driven Method for In-Game Decision Making in MLB
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

2017 Information & Record Book
2017 INFORMATION & RECORD BOOK OWNERSHIP OF THE CLEVELAND INDIANS Paul J. Dolan John Sherman Owner/Chairman/Chief Executive Of¿ cer Vice Chairman The Dolan family's ownership of the Cleveland Indians enters its 18th season in 2017, while John Sherman was announced as Vice Chairman and minority ownership partner of the Paul Dolan begins his ¿ fth campaign as the primary control person of the franchise after Cleveland Indians on August 19, 2016. being formally approved by Major League Baseball on Jan. 10, 2013. Paul continues to A long-time entrepreneur and philanthropist, Sherman has been responsible for establishing serve as Chairman and Chief Executive Of¿ cer of the Indians, roles that he accepted prior two successful businesses in Kansas City, Missouri and has provided extensive charitable to the 2011 season. He began as Vice President, General Counsel of the Indians upon support throughout surrounding communities. joining the organization in 2000 and later served as the club's President from 2004-10. His ¿ rst startup, LPG Services Group, grew rapidly and merged with Dynegy (NYSE:DYN) Paul was born and raised in nearby Chardon, Ohio where he attended high school at in 1996. Sherman later founded Inergy L.P., which went public in 2001. He led Inergy Gilmour Academy in Gates Mills. He graduated with a B.A. degree from St. Lawrence through a period of tremendous growth, merging it with Crestwood Holdings in 2013, University in 1980 and received his Juris Doctorate from the University of Notre Dame’s and continues to serve on the board of [now] Crestwood Equity Partners (NYSE:CEQP). -

Weekly Notes 072817
MAJOR LEAGUE BASEBALL WEEKLY NOTES FRIDAY, JULY 28, 2017 BLACKMON WORKING TOWARD HISTORIC SEASON On Sunday afternoon against the Pittsburgh Pirates at Coors Field, Colorado Rockies All-Star outfi elder Charlie Blackmon went 3-for-5 with a pair of runs scored and his 24th home run of the season. With the round-tripper, Blackmon recorded his 57th extra-base hit on the season, which include 20 doubles, 13 triples and his aforementioned 24 home runs. Pacing the Majors in triples, Blackmon trails only his teammate, All-Star Nolan Arenado for the most extra-base hits (60) in the Majors. Blackmon is looking to become the fi rst Major League player to log at least 20 doubles, 20 triples and 20 home runs in a single season since Curtis Granderson (38-23-23) and Jimmy Rollins (38-20-30) both accomplished the feat during the 2007 season. Since 1901, there have only been seven 20-20-20 players, including Granderson, Rollins, Hall of Famers George Brett (1979) and Willie Mays (1957), Jeff Heath (1941), Hall of Famer Jim Bottomley (1928) and Frank Schulte, who did so during his MVP-winning 1911 season. Charlie would become the fi rst Rockies player in franchise history to post such a season. If the season were to end today, Blackmon’s extra-base hit line (20-13-24) has only been replicated by 34 diff erent players in MLB history with Rollins’ 2007 season being the most recent. It is the fi rst stat line of its kind in Rockies franchise history. Hall of Famer Lou Gehrig is the only player in history to post such a line in four seasons (1927-28, 30-31). -

2012 Information Guide
2012 INFORMATION GUIDE Mesa Peoria Phoenix Salt River Scottsdale Surprise Solar Sox Javelinas Desert Dogs Rafters Scorpions Saguaros BRYCE HARPER INTRODUCING THE UA SPINE HIGHLIGHT SUPER-HIGH. RIDICULOUSLY LIGHT. This season, Bryce Harper put everyone on notice while wearing the most innovative baseball cleats ever made. Stable, supportive, and shockingly light, they deliver the speed and power that will define the legends of this generation. Under Armour® has officially changed the game. Again. AVAILABLE 11.1.12 OFFICIAL PERFORMANCE Major League Baseball trademarks and copyrights are used with permission ® of Major League Baseball Properties, Inc. Visit MLB.com FOOTWEAR SUPPLIER OF MLB E_02_Ad_Arizona.indd 1 10/3/12 2:27 PM CONTENTS Inside Q & A .......................................2-5 Organizational Assignments ......3 Fall League Staff .........................5 Arizona Fall League Schedules ................................6-7 Through The Years Umpires .....................................7 Diamondbacks Saguaros Lists.......................................8-16 Chandler . 1992–94 Peoria.................2003–10 Desert Dogs Phoenix ...................1992 Top 100 Prospects ....................11 Mesa . .2003 Maryvale............1998–2002 Player Notebook ..................17-29 Phoenix ..... 1995–2002, ’04–11 Mesa . .1993–97 Mesa Solar Sox ....................31-48 Javelinas Surprise...................2011 Peoria Javelinas ...................49-66 Tucson . 1992–93 Scorpions Peoria...............1994–2011 Scottsdale . 1992–2004, ’06–11 -

Fri Feb 06 06:30Pm EST,Nfl Womens Jerseys Boston's Truck Day Signals T-Minus Some Form of Week 'Til End to Do with Darkness by 'Duk
Fri Feb 06 06:30pm EST,nfl womens jerseys Boston's Truck Day signals t-minus some form of week 'til end to do with darkness By 'Duk Other teams have already shipped their gadgets trucks to the south,baseball jerseys,nfl jerseys wholesale,but take heart as any Red Sox fan not only can they tell you the preparing any other part a well known fact access about spring will be the as soon as the Red Sox always keep their "Truck Day" at Fenway Park. The team for that matter has its different version to do with Punxsutawney Phil with 89-year-old Johnny Pesky above doing the honors concerning turning the a critical as part of your truck's ignition. Rumble all over the Mr. Pesky! It's hard to educate yourself regarding believe but we now have made it throughout baseball's dead period of time The Indians' pitchers and catchers not only can they credit report for more information regarding Arizona throughout the Thursday and people teams will observe suit on Friday and Saturday. Even however Opening Day has to be that having said all that about two months away, it's hard by no means for more information regarding really do not think like a multi functional six-year-old leaped up everywhere in the Jolt and Pop Rocks,nfl jersey s, isn't element? Next week or so I'll be hunkering down so that you have a portion of the surpass Yahoos,nike jerseys! and formulating an attack plan gorgeous honeymoons as well the upcoming season. -

2021 SWB Railriders Media Guide
2019 & 2020 yankees draft picks & top prospects all-time swb roster == A == Esteban Beltre .............................96 Paul Byrd ...............................00-01 Cale Coshow .........................17-19 Kyle Abbott ............................92-93 Gary Bennett ............ 95-96, 98, 00 Chris Coste ............................05-06 Paul Abbott ..................................04 Joel Bennett ...........................98-99 == C == Caleb Cotham .......................13-15 Andury Acevedo .........................15 Mike Benjamin ...........................96 Cesar Cabral ..........................13-14 Neal Cotts ....................................16 Domingo Acevedo ............... 17, 19 Peter Bergeron ............................06 Jose Cabrera ................................03 Danny Coulombe .......................19 Alfredo Aceves ................08-10, 14 Adam Bernero .............................06 Melky Cabrera .............................08 Dan Cox .......................................08 Dustin Ackley..............................15 Doug Bernier...................09, 11-12 Bruce Caldwell ............................18 Danny Cox...................................91 David Adams ...............................13 Angel Berroa ...............................09 Daniel Camarena ..................16-19 J.B. Cox ...................................08-09 Chance Adams ......................17-19 Quintin Berry ..............................18 Ryan Cameron ............................06 Carlos Crawford .........................96 -

Media/Scouts Notes • Monday, October 29, 2007
Media/Scouts Notes • Monday, October 29, 2007 Media Relations Contacts: Paul Jensen (cell 480/710-8201, [email protected]) Ed Collari (cell 770/367-5986, [email protected]) John Meyer (cell 515/770-4190, [email protected]) AFL Standings East Division Team W L Pct. GB Home Away Division Streak Last 10 Mesa Solar Sox 9 6 .600 - 5-3 4-3 4-1 L1 6-3 Phoenix Desert Dogs 9 7 .563 0.5 6-3 3-4 4-1 L2 5-4 Scottsdale Scorpions 5 11 .313 4.5 4-4 1-7 0-6 W2 5-5 West Division Team W L Pct. GB Home Away Division Streak Last 10 Surprise Rafters 11 5 .688 - 6-2 5-3 4-2 W1 6-4 Peoria Javelinas 9 7 .563 2.0 7-2 2-5 4-2 W3 5-5 Peoria Saguaros 5 11 .313 6.0 3-4 2-7 1-5 L2 2-8 International Teams W L Pct. GB Home Away Division Streak Last 10 Team USA 1 1 .500 - 1-0 0-1 0-0 W1 1-1 Team China 1 2 .333 0.5 0-0 1-2 0-0 L1 1-2 Saturday’s Results Scottsdale 3, Saguaros 0 — WP: Smith (1-1). LP: Overholt (1-2). SV: Anderson (2). Scorpions IF Sergio Santos (TOR) was 2-4 with 2 home runs, 2 runs, and 2 RBI … Scorpions LHP Greg Smith (ARI) threw 3.0 innings, allowed 4 hits, and struck out 3 … seven Scorpions pitchers shut out the Saguaros … Saguaros IF Scott Sizemore (DET) 2-5 … Saguaros IF Michael Costanzo (PHI) was 2-3. -
Big 12 Baseball Record Book
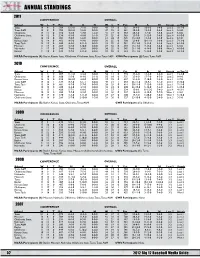
ANNUAL STANDINGS 2011 CONFERENCE OVERALL School W L T Pct. H A N W L T Pct. H A N Streak vs. Top 25 Texas 19 8 0 .704 12-3-0 7-5-0 0-0-0 49 19 0 .721 36-9-0 10-6-0 3-4-0 Lost 2 10-7-0 Texas A&M 19 8 0 .704 10-2-0 9-6-0 0-0-0 47 22 0 .681 30-9-0 12-9-0 5-4-0 Lost 2 9-9-0 Oklahoma 14 11 0 .560 9-2-0 4-7-0 1-2-0 41 19 0 .683 28-4-0 9-9-0 4-6-0 Lost 3 6-8-0 Oklahoma State 14 12 0 .538 8-3-0 4-8-0 2-1-0 35 25 0 .583 25-7-0 5-12-0 5-6-0 Lost 4 6-10-0 Baylor 13 14 0 .481 7-8-0 6-6-0 0-0-0 31 28 0 .525 16-14-0 11-9-0 3-5-0 Lost 2 8-9-0 Kansas State 12 14 0 .462 8-5-0 4-9-0 0-0-0 36 25 0 .590 23-8-0 10-11-0 3-6-0 Lost 3 7-13-0 Texas Tech 12 15 0 .444 8-4-0 4-11-0 0-0-0 33 25 0 .561 22-12-0 9-11-0 2-2-0 Lost 2 6-14-0 Missouri 11 15 0 .423 6-5-0 5-10-0 0-0-0 27 32 0 .458 15-13-0 7-15-0 5-4-0 Lost 1 5-9-0 Nebraska 9 17 0 .346 7-8-0 2-9-0 0-0-0 30 25 0 .545 21-11-0 4-14-0 5-0-0 Won 2 4-10-0 Kansas 9 18 0 .333 7-7-0 2-11-0 0-0-0 26 30 0 .464 19-11-0 5-16-0 2-3-0 Lost 3 4-13-0 NCAA Participants (6): Baylor, Kansas State, Oklahoma, Oklahoma State, Texas, Texas A&M CWS Participants (2): Texas, Texas A&M 2010 CONFERENCE OVERALL School W L T Pct. -

PITTSBURGH PIRATES (25-49) Vs
PITTSBURGH PIRATES (25-49) vs. OAKLAND ATHLETICS (36-40) JUNE 27 , 2010 AT THE COLISEUM IN OAKLAND --- GAME #75, ROAD #40 RHP ROSS OHLENDORF (0-6, 5.43 ERA) vs. LHP GIO GONZALEZ (6-5, 3.89 ERA) THE PIRATES... have lost five straight games after winning back-to-back games against the Indians last Saturday and Sunday...Lost a season-high 12 straight from 6/6-18 and have gone 5-23 in their last 28 contests, dating back to 5/26...Began season with two straight wins over the Dodgers at PNC Park on 4/5 and 4/7 and had a 7-5 record prior to dropping seven straight games from 4/20-26...Have won a season-high three straight games on three occasions (5/4-6, 4/27-29 and 4/16-18)...Were 35-39 after 74 games last season (35-40 after 75). BUCS WHEN... G-MAN AGAINST THE A.L.: In 14 games against the American League this season, Garrett Jones is hitting .396, going Last five games . .0-5 21-for-53 with eight multi-hit efforts and 11 RBI...The club’s single-season record for highest average in interleague play Last ten games . .2-8 is held by Rob Mackowiak , who hit .441 (15-for-34) in 2001...The single-season club record for most RBI is 14, shared by Brian Giles (2001) and Ed Sprague (1999)...Jones also ranks fifth among all Major League players in interleague Leading after 6 . .15-4 average this season behind Josh Hamilton (.493), Justin Upton (.453), Gabby Sanchez (.433) and Adrian Gonzalez (.426). -

PITTSBURGH PIRATES (25-48) Vs
PITTSBURGH PIRATES (25-48) vs. OAKLAND ATHLETICS (35-40) JUNE 26 , 2010 AT THE COLISEUM IN OAKLAND --- GAME #74, ROAD #39 RHP DANIEL McCUTCHEN (0-2, 13.50 ERA) vs. RHP TREVOR CAHILL (6-2, 3.21 ERA) THE PIRATES... have lost four straight games after winning back-to-back games against the Indians last Saturday and Sunday...Lost a season-high 12 straight from 6/6-18 and have gone 5-22 in their last 27 contests, dating back to 5/26...Began season with two straight wins over the Dodgers at PNC Park on 4/5 and 4/7 and had a 7-5 record prior to dropping seven straight games from 4/20-26...Have won a season-high three straight games on three occasions (5/4-6, 4/27-29 and 4/16-18)...Were 34-39 after 73 games last season (35-39 after 74). BUCS WHEN... ROSTER MOVE: Prior to tonight’s game the Pirates will recall RHP Daniel McCutchen (#34) to start the game...The Last five games . .1-4 club will also make a corresponding move prior to the game tonight in Oakland. Last ten games . .2-8 BUC BATS GETTING WARM IN SUMMER: In the four games played since the summer solstice began on Monday, the Leading after 6 . .15-4 Pirates are hitting .277 (39-for-141)...They have raised their team batting average from .237 to .240 in that time - its highest point since 5/10 (.240). Tied after 6 . .6-3 Trailing after 6 . .4-41 GROOVY KIND OF DAY: Tonight the Pirates and Athletics will be wearing uniforms from the 70’s as Oakland turns back the clock to that far-out decade...The Buccos will be wearing black pants with black tops while the A’s will be sporting the Leading after 7 . -

2021 SWB Railriders Media Guide
grand slam history 1989 2005 Keith Miller April 19 @ Syracuse Shane Victorino May 10 vs. Pawtucket Greg Legg May 15 vs Oklahoma City Chris Coste May 15 @ Rochester Floyd Rayford June 24 vs Tidewater (PH) Ryan Howard May 28 @ Richmond Anthony Medrano August 10 @ Syracuse 1990 Jorge Padilla August 15 @ Louisville Steve Stanicek May 1 @ Richmond John Gibbons July 27 @ Indianapolis 2006 Kelly Heath August 21 @ Pawtucket Brennan King July 14, 2006 vs. Toledo Steve Stanicek August 22 @ Pawtucket Joe Thurston July 28, 2006 vs. Richmond Michael Bourn August 15, 2006 vs. Syracuse 1991 Sil Campusano April 27 @ Columbus 2007 Sil Campusano June 10 @ Columbus Shelley Duncan June 18, 2007 @ Durham Kevin Reese July 22, 2007 vs. Charlotte 1992 Steve Scarsone April 11 vs Syracuse 2008 Gary Alexander June 3 @ Syracuse Jason Lane May 4, 2008 vs. Durham Rick Schu July 5 vs Syracuse Nick Green July 13, 2008 @ Columbus Ruben Amaro August 7 @ Pawtucket Gary Alexander September 7 @ Columbus 2009 Colin Curtis July 3 @ Pawtucket 1993 Chris Stewart July 7 @ Buffalo Victor Rodriguez May 18 vs Ottawa Shelley Duncan August 30 vs. Pawtucket 1994 2010 None Jesus Montero May 17 vs. Charlotte 1995 2011 Phil Geisler August 12 vs Pawtucket Kevin Russo July 15 @ Toledo 1996 2012 Gene Schall April 27 @ Rochester Cole Garner July 21 @ Gwinnett David Doster May 22 @ Norfolk Wendell Magee August 3 vs Charlotte 2013 Cody Grice June 19, 2013 1997 Melky Mesa August 9, 2013 Mike Robertson May 1 @ Columbus Tony Barron May 16 @ Syracuse 2014 Wendell Magee Jr. June 28 vs Pawtucket Zelous Wheeler May 28 @ Louisville Mike Robertson August 10 @ Syracuse Rob Segedin July 22 @ Gwinnett 1998 2015 Doug Angeli June 8 @ Charlotte Tyler Austin June 2 vs. -

Lamarre Age: 24 Ht.: 6-1 Wt.: 204 Bats: R Throws: L ML Service: 0.000
2013 REDS Non-Roster Ryan OF LaMARRE Age: 24 Ht.: 6-1 Wt.: 204 Bats: R Throws: L ML Service: 0.000 Born: 11/21/88 Birthplace: Royal Oak, MI Resides: Jackson, MI Acquired: Was selected by the Reds in the second round of the June 2010 first-year player draft. Was signed by Brad Meador. Contract: Signed through the 2013 season. CAREER HIGHLIGHTS: Last name is pronounced la-MARR...following each of the last 3 seasons was rated by Baseball America the best defensive outfielder in the organization...in 2012 was a mid-season Southern League All-Star...in 2013 was invited to Major League spring training camp for the first time...while in minor league camp made 5 apps for the Reds during spring training 2011 and 8 apps with the Major League club in March 2012. 2012 SEASON: In his first full season at Class AA was a mid-season Southern League All-Star for Pensacola... with 30 stolen bases ranked T4th among all Reds farmhands and fifth in the SL...for the third straight season was rated the best defensive outfielder in the organization...in January 2013 was invited to Major League spring training camp for the first time. SEASON HIGHLIGHTS 2011: In 122 apps at Class A Bakersfield combined to hit .278 (6hr, 47rbi, 55sb)...his 55 steals ranked second in the organization, third in the California League and T7th among all minor leaguers...for the second consecutive season was rated the organization’s best defensive outfielder...entered the season as the Reds’ 11th-best prospect...2010: In his first professional season produced 19 stolen bases for Class A Dayton and Lynchburg...following the season was rated the organization’s best defensive outfielder. -
PRESS RELEASE OCTOBER 24 Ththth 2007
PRESS RELEASE OCTOBER 24 ththth 2007 37th BASEBALL WORLD CUP Live on www.stadeo.tv Sixteen nations, eager to prove global supremacy and anxious to establish momentum heading into the 2008 Olympic Games in Beijing, collide at this year’s InternatInternationalional Baseball Federation (IBAF) World Cup of Baseball from Nov. 6---18-18 in Taiwan. www.stadeo.tv will play host to the 37 ththth Baseball World Cup live on the internet, a twotwo----weekweek showcase of continuous diamond action between the top international baseball powpowersers in the world. 41 games Live and Free stadeo.tv, fresh off its hugely successful coverage of the European Baseball Championships in Barcelona in August, will once again be on hand using cutting edge streaming technology to broadcast live and free 41 of the 68 games to the international baseball audience, including all quarterfinal, semifinal and championship final action. Nine-time defending champion Cuba will be seeking a remarkable tenth straight World Championship but will have to battle World Baseball Classic champion Japan, as well as 14 other nations, including recent world medalists Chinese Taipei, the United States, Korea and Panama for championship glory. Sanctioned by the IBAF, the Baseball World Cup returns to Chinese Taipei for the first time since 2001. The Netherlands hosted the 2005 World Cup, a tournament that once again displayed Cuba’s gold medal dominance and saw Korea win silver and Panama capture the bronze. And just like 2005, expect the unexpected, like Korea’s 5-1 upset of Japan in the quarterfinals to knock the Japanese out of medal contention.