ZFS Filesystem Metadata – Impact: Led to Corruption of Labels on Each of the Vdevs (Virtual Devices) in the Data Pool
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Hybrid Drowsy SRAM and STT-RAM Buffer Designs for Dark-Silicon
This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination. IEEE TRANSACTIONS ON VERY LARGE SCALE INTEGRATION (VLSI) SYSTEMS 1 Hybrid Drowsy SRAM and STT-RAM Buffer Designs for Dark-Silicon-Aware NoC Jia Zhan, Student Member, IEEE, Jin Ouyang, Member, IEEE,FenGe,Member, IEEE, Jishen Zhao, Member, IEEE, and Yuan Xie, Fellow, IEEE Abstract— The breakdown of Dennard scaling prevents us MCMC MC from powering all transistors simultaneously, leaving a large fraction of dark silicon. This crisis has led to innovative work on Tile link power-efficient core and memory architecture designs. However, link link RouterRouter the research for addressing dark silicon challenges with network- To router on-chip (NoC), which is a major contributor to the total chip NI power consumption, is largely unexplored. In this paper, we Core link comprehensively examine the network power consumers and L1-I$ L2 L1-D$ the drawbacks of the conventional power-gating techniques. To overcome the dark silicon issue from the NoC’s perspective, we MCMC MC propose DimNoC, a dim silicon scheme, which leverages recent drowsy SRAM design and spin-transfer torque RAM (STT-RAM) Fig. 1. 4 × 4 NoC-based multicore architecture. In each node, the local technology to replace pure SRAM-based NoC buffers. processing elements (core, L1, L2 caches, and so on) are attached to a router In particular, we propose two novel hybrid buffer architectures: through an NI. Routers are interconnected through links to form an NoC. 1) a hierarchical buffer architecture, which divides the input Four memory controllers are attached at the four corners, which will be used buffers into a set of levels with different power states and 2) a for off-chip memory access. -

An Analysis of Data Corruption in the Storage Stack
An Analysis of Data Corruption in the Storage Stack Lakshmi N. Bairavasundaram∗, Garth R. Goodson†, Bianca Schroeder‡ Andrea C. Arpaci-Dusseau∗, Remzi H. Arpaci-Dusseau∗ ∗University of Wisconsin-Madison †Network Appliance, Inc. ‡University of Toronto {laksh, dusseau, remzi}@cs.wisc.edu, [email protected], [email protected] Abstract latent sector errors, within disk drives [18]. Latent sector errors are detected by a drive’s internal error-correcting An important threat to reliable storage of data is silent codes (ECC) and are reported to the storage system. data corruption. In order to develop suitable protection Less well-known, however, is that current hard drives mechanisms against data corruption, it is essential to un- and controllers consist of hundreds-of-thousandsof lines derstand its characteristics. In this paper, we present the of low-level firmware code. This firmware code, along first large-scale study of data corruption. We analyze cor- with higher-level system software, has the potential for ruption instances recorded in production storage systems harboring bugs that can cause a more insidious type of containing a total of 1.53 million disk drives, over a pe- disk error – silent data corruption, where the data is riod of 41 months. We study three classes of corruption: silently corrupted with no indication from the drive that checksum mismatches, identity discrepancies, and par- an error has occurred. ity inconsistencies. We focus on checksum mismatches since they occur the most. Silent data corruptionscould lead to data loss more of- We find more than 400,000 instances of checksum ten than latent sector errors, since, unlike latent sector er- mismatches over the 41-month period. -

Understanding Real World Data Corruptions in Cloud Systems
Understanding Real World Data Corruptions in Cloud Systems Peipei Wang, Daniel J. Dean, Xiaohui Gu Department of Computer Science North Carolina State University Raleigh, North Carolina {pwang7,djdean2}@ncsu.edu, [email protected] Abstract—Big data processing is one of the killer applications enough to require attention, little research has been done to for cloud systems. MapReduce systems such as Hadoop are the understand software-induced data corruption problems. most popular big data processing platforms used in the cloud system. Data corruption is one of the most critical problems in In this paper, we present a comprehensive study on the cloud data processing, which not only has serious impact on characteristics of the real world data corruption problems the integrity of individual application results but also affects the caused by software bugs in cloud systems. We examined 138 performance and availability of the whole data processing system. data corruption incidents reported in the bug repositories of In this paper, we present a comprehensive study on 138 real world four Hadoop projects (i.e., Hadoop-common, HDFS, MapRe- data corruption incidents reported in Hadoop bug repositories. duce, YARN [17]). Although Hadoop provides fault tolerance, We characterize those data corruption problems in four aspects: our study has shown that data corruptions still seriously affect 1) what impact can data corruption have on the application and system? 2) how is data corruption detected? 3) what are the the integrity, performance, and availability -

MRAM Technology Status
National Aeronautics and Space Administration MRAM Technology Status Jason Heidecker Jet Propulsion Laboratory Pasadena, California Jet Propulsion Laboratory California Institute of Technology Pasadena, California JPL Publication 13-3 2/13 National Aeronautics and Space Administration MRAM Technology Status NASA Electronic Parts and Packaging (NEPP) Program Office of Safety and Mission Assurance Jason Heidecker Jet Propulsion Laboratory Pasadena, California NASA WBS: 104593 JPL Project Number: 104593 Task Number: 40.49.01.09 Jet Propulsion Laboratory 4800 Oak Grove Drive Pasadena, CA 91109 http://nepp.nasa.gov i This research was carried out at the Jet Propulsion Laboratory, California Institute of Technology, and was sponsored by the National Aeronautics and Space Administration Electronic Parts and Packaging (NEPP) Program. Reference herein to any specific commercial product, process, or service by trade name, trademark, manufacturer, or otherwise, does not constitute or imply its endorsement by the United States Government or the Jet Propulsion Laboratory, California Institute of Technology. ©2013. California Institute of Technology. Government sponsorship acknowledged. ii TABLE OF CONTENTS 1.0 Introduction ............................................................................................................................................................ 1 2.0 MRAM Technology ................................................................................................................................................ 2 2.1 -

The Effects of Repeated Refresh Cycles on the Oxide Integrity of EEPROM Memories at High Temperature by Lynn Reed and Vema Reddy Tekmos, Inc
The Effects of Repeated Refresh Cycles on the Oxide Integrity of EEPROM Memories at High Temperature By Lynn Reed and Vema Reddy Tekmos, Inc. 4120 Commercial Center Drive, #400, Austin, TX 78744 [email protected], [email protected] Abstract Data retention in stored-charge based memories, such as Flash and EEPROMs, decreases with increasing temperature. Compensation for this shortening of retention time can be accomplished by refreshing the data using periodic erase-write refresh cycles, although the number of these cycles is limited by oxide integrity. An alternate approach is to use refresh cycles consisting of a rewrite only cycles, without the prior erase cycle. The viability of this approach requires that this refresh cycle induces less damage than an erase-write cycle. This paper studies the effects of repeated refresh cycles on oxide integrity in a high temperature environment and makes comparisons to the damage caused by erase-write cycles. The experiment consisted of running a large number of refresh cycles on a selected byte. The control group was other bytes which were not subjected to refresh only cycles. The oxide integrity was checked by performing repeated erase-write cycles on each of the two groups to determine if the refresh cycles decreased the number of erase-write cycles before failure. Data was collected from multiple parts, with different numbers of refresh cycles, and at temperatures ranging from 25C to 190C. The experiment was conducted on microcontrollers containing embedded EEPROM memories. The microcontrollers were programmed to test and measure their own memories, and to report the results to an external controller. -

On the Effects of Data Corruption in Files
Just One Bit in a Million: On the Effects of Data Corruption in Files Volker Heydegger Universität zu Köln, Historisch-Kulturwissenschaftliche Informationsverarbeitung (HKI), Albertus-Magnus-Platz, 50968 Köln, Germany [email protected] Abstract. So far little attention has been paid to file format robustness, i.e., a file formats capability for keeping its information as safe as possible in spite of data corruption. The paper on hand reports on the first comprehensive research on this topic. The research work is based on a study on the status quo of file format robustness for various file formats from the image domain. A controlled test corpus was built which comprises files with different format characteristics. The files are the basis for data corruption experiments which are reported on and discussed. Keywords: digital preservation, file format, file format robustness, data integ- rity, data corruption, bit error, error resilience. 1 Introduction Long-term preservation of digital information is by now and will be even more so in the future one of the most important challenges for digital libraries. It is a task for which a multitude of factors have to be taken into account. These factors are hardly predictable, simply due to the fact that digital preservation is something targeting at the unknown future: Are we still able to maintain the preservation infrastructure in the future? Is there still enough money to do so? Is there still enough proper skilled manpower available? Can we rely on the current legal foundation in the future as well? How long is the tech- nology we use at the moment sufficient for the preservation task? Are there major changes in technologies which affect the access to our digital assets? If so, do we have adequate strategies and means to cope with possible changes? and so on. -

Exploiting Asymmetry in Edram Errors for Redundancy-Free Error
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI 10.1109/TETC.2019.2960491, IEEE Transactions on Emerging Topics in Computing IEEE TRANSACTIONS ON EMERGING TOPICS IN COMPUTING 1 Exploiting Asymmetry in eDRAM Errors for Redundancy-Free Error-Tolerant Design Shanshan Liu (Member, IEEE), Pedro Reviriego (Senior Member, IEEE), Jing Guo, Jie Han (Senior Member, IEEE) and Fabrizio Lombardi (Fellow, IEEE) Abstract—For some applications, errors have a different impact on data and memory systems depending on whether they change a zero to a one or the other way around; for an unsigned integer, a one to zero (or zero to one) error reduces (or increases) the value. For some memories, errors are also asymmetric; for example, in a DRAM, retention failures discharge the storage cell. The tolerance of such asymmetric errors would result in a robust and efficient system design. Error Control Codes (ECCs) are one common technique for memory protection against these errors by introducing some redundancy in memory cells. In this paper, the asymmetry in the errors in Embedded DRAMs (eDRAMs) is exploited for error-tolerant designs without using any ECC or parity, which are redundancy-free in terms of memory cells. A model for the impact of retention errors and refresh time of eDRAMs on the False Positive rate or False Negative rate of some eDRAM applications is proposed and analyzed. Bloom Filters (BFs) and read-only or write-through caches implemented in eDRAMs are considered as the first case studies for this model. -

SŁOWNIK POLSKO-ANGIELSKI ELEKTRONIKI I INFORMATYKI V.03.2010 (C) 2010 Jerzy Kazojć - Wszelkie Prawa Zastrzeżone Słownik Zawiera 18351 Słówek
OTWARTY SŁOWNIK POLSKO-ANGIELSKI ELEKTRONIKI I INFORMATYKI V.03.2010 (c) 2010 Jerzy Kazojć - wszelkie prawa zastrzeżone Słownik zawiera 18351 słówek. Niniejszy słownik objęty jest licencją Creative Commons Uznanie autorstwa - na tych samych warunkach 3.0 Polska. Aby zobaczyć kopię niniejszej licencji przejdź na stronę http://creativecommons.org/licenses/by-sa/3.0/pl/ lub napisz do Creative Commons, 171 Second Street, Suite 300, San Francisco, California 94105, USA. Licencja UTWÓR (ZDEFINIOWANY PONIŻEJ) PODLEGA NINIEJSZEJ LICENCJI PUBLICZNEJ CREATIVE COMMONS ("CCPL" LUB "LICENCJA"). UTWÓR PODLEGA OCHRONIE PRAWA AUTORSKIEGO LUB INNYCH STOSOWNYCH PRZEPISÓW PRAWA. KORZYSTANIE Z UTWORU W SPOSÓB INNY NIŻ DOZWOLONY NA PODSTAWIE NINIEJSZEJ LICENCJI LUB PRZEPISÓW PRAWA JEST ZABRONIONE. WYKONANIE JAKIEGOKOLWIEK UPRAWNIENIA DO UTWORU OKREŚLONEGO W NINIEJSZEJ LICENCJI OZNACZA PRZYJĘCIE I ZGODĘ NA ZWIĄZANIE POSTANOWIENIAMI NINIEJSZEJ LICENCJI. 1. Definicje a."Utwór zależny" oznacza opracowanie Utworu lub Utworu i innych istniejących wcześniej utworów lub przedmiotów praw pokrewnych, z wyłączeniem materiałów stanowiących Zbiór. Dla uniknięcia wątpliwości, jeżeli Utwór jest utworem muzycznym, artystycznym wykonaniem lub fonogramem, synchronizacja Utworu w czasie z obrazem ruchomym ("synchronizacja") stanowi Utwór Zależny w rozumieniu niniejszej Licencji. b."Zbiór" oznacza zbiór, antologię, wybór lub bazę danych spełniającą cechy utworu, nawet jeżeli zawierają nie chronione materiały, o ile przyjęty w nich dobór, układ lub zestawienie ma twórczy charakter. -

ZFS: Love Your Data
ZFS: Love Your Data Neal H. Waleld LinuxCon Europe, 14 October 2014 ZFS Features I Security I End-to-End consistency via checksums I Self Healing I Copy on Write Transactions I Additional copies of important data I Snapshots and Clones I Simple, Incremental Remote Replication I Easier Administration I One shared pool rather than many statically-sized volumes I Performance Improvements I Hierarchical Storage Management (HSM) I Pooled Architecture =) shared IOPs I Developed for many-core systems I Scalable 128 I Pool Address Space: 2 bytes I O(1) operations I Fine-grained locks I On-disk data is protected by ECC I But, doesn't correct / catch all errors Silent Data Corruption I Data errors that are not caught by hard drive I = Read returns dierent data from what was written Silent Data Corruption I Data errors that are not caught by hard drive I = Read returns dierent data from what was written I On-disk data is protected by ECC I But, doesn't correct / catch all errors Uncorrectable Errors By Cory Doctorow, CC BY-SA 2.0 I Reported as BER (Bit Error Rate) I According to Data Sheets: 14 I Desktop: 1 corrupted bit per 10 (12 TB) 15 I Enterprise: 1 corrupted bit per 10 (120 TB) ∗ I Practice: 1 corrupted sector per 8 to 20 TB ∗Je Bonwick and Bill Moore, ZFS: The Last Word in File Systems, 2008 Types of Errors I Bit Rot I Phantom writes I Misdirected read / write 8 9 y I 1 per 10 to 10 IOs I = 1 error per 50 to 500 GB (assuming 512 byte IOs) I DMA Parity Errors By abdallahh, CC BY-SA 2.0 I Software / Firmware Bugs I Administration Errors yUlrich -
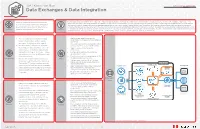
Data Exchanges & Data Integration
IOA KNOWLEDGE BASE DATA DESIGN PATTERNS Data Exchanges & Data Integration Deploy a data integration platform in the edge node. A data integration platform essentially takes data sources from a number of supported source interfaces (file, database, object store, etc.), Access to multiple types of data from numerous transforms it into a universal format, and then uses data services to provide varied consumer interface choices in order to consume the data. This already has widespread value to organizations sources and locations in either an event-based or that frequently need to integrate data between disparate applications (in one or more clouds). Used a different way, this platform also enables a data exchange. Data exchanges are groups of time-scheduled manner places a large burden on companies that are securely interconnected in the edge node for the purpose of accessing/sharing data (which is typically monetized). New data sources are valuable to data-oriented partners. As Problem enterprise data infrastructure and services. Solution in analytical processing, more data sources directly translate to more experience (it could be IoT data, scientific data, medical trial data, etc.). Even if "translation" is not required and data is passed straight through, the other governance functions provide significant value and needed oversight in a dynamic, automated environment. 1. There are hundreds of permutations of data 1. Deploy access (adapters/connectors), transformation and delivery services (adapters/ transfer occurring. Some of these require connectors). governance items that may not be applied. 2. Wire each step to go through boundary control 2. In a "trust nothing" environment, each action and inspection zone(s) (Security Blueprint*). -

Oracle ZFS Storage--Data Integrity White Paper
Oracle ZFS Storage—Data Integrity ORACLE WHITE P A P E R | M A Y 2 0 1 7 Table of Contents Introduction 1 Overview 2 Primary Design Goals 2 Shortcomings of Traditional Data Storage 2 RAID Design Problems 2 Traditional RAID Data Integrity Study 3 ZFS Data Integrity 4 ZFS Transactional Processing 4 ZFS Ditto Blocks 5 ZFS Self-Healing 5 University Research Testing and Validation of ZFS Data Integrity 5 Defining Corruption and How Often Corruption Happens 5 Problems Identified with Other File Systems and RAID 6 Research Testing Methodology 6 Testing Configuration and Data Layout 6 Oracle ZFS Storage Appliance Robustness 7 Reducing Risk Through Advanced Data Integrity 7 Robust Protection from Hardware Failures 7 ZFS Data Encryption 8 Conclusion 8 Related Links 9 ORACLE ZFS STORAGE—DATA INTEGRITY Introduction Studies have shown that traditional RAID technology, while effective for disk space savings, cannot provide sufficient end-to-end data integrity to ensure against data loss or corruption in contemporary cloud-scale data storage environments. For example, traditional RAID technology is unable to isolate and protect against firmware or driver bugs that can have a substantial impact on a storage system’s ability to protect against data corruption or loss. Modern storage architectures, like those incorporated into Oracle ZFS Storage Appliance, protect against these failure modes by providing advanced data integrity technology such as hierarchical checksums, redundant metadata, transactional processing, and integrated redundancy. These features -

Data Integrity for Silent Data Corruption in Gfarm File System
21st International Conference on Computing in High Energy and Nuclear Physics (CHEP2015) Contribution ID: 535 Type: poster presentation Data Integrity for Silent Data Corruption in Gfarm File System Files in storage are often corrupted silently without any explicit error. This is typically due to file system software bug, RAID controller firmware bug, and some other reasons. Most critical issue is damaged data is read without any error. Although there are several mechanisms to detect data corruption in different layers such as ECC in disk and memory and TCP checksum, the data may be damaged. To cope with the silent data corruption, the file system level detection is effective. Btrfs and ZFS have a mechanism to detect it by adding checksum in each block. However, data replication is often required to correct the damaged data, which may waste storage capacity in local file system since it is required only for data integrity. Gfarm file system is a distributed file system that federates storages among several institutions in wide area. Large installations include Japan Lattice Data Grid (JLDG) with 4PB storage capacity in 9storage sites, and HPCI shared storage with 20PB storage capacity in 3 storage sites. It has file replicas to improve access performance from distant clients, and also to improve fault tolerance. The number and the locations of file replicas are specified by an extended attribute of a directory or a file. We design the data integrity feature in Gfarm file system by automatically calculating digest like md5 or sha256 when accessing files. The file digest is calculatd at a storage node before writing to a storage when a file is created, and managed in file system metadata.