Origin-Destination Trip and LRT Ridership Estimation with New Data Source
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
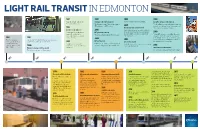
40 Years LRT Timeline
LIGHT RAIL TRANSIT IN EDMONTON 1981 2001 2004 2008 A 2.2 kilometre LRT extension to Customer service further improves The ETS Trip Planner becomes available. Innovative customer service starts up Clareview station opens. The City partners with Telus and installs public The City of Edmonton starts 311, a service that lets TTY payphones in all LRT stations. 2005 residents access information on city programs and 1983 More inclusive and customer focused services, including transit information. All riders’ needs considered 2001 The Mobility Card for persons with disabilities is The Bay and Corona LRT stations LRT gets a fresh, new look improved. A subsidized monthly transit pass for 2009 Edmonton AISH recipients becomes a regular, open up. For the first time, The new updated Clareview LRT Station opens. The Bay LRT station is re-named Bay/Enterprise accessibility features are added, ongoing program. Square and the Health Sciences LRT station is re- 1951 1961 such as elevators. 2003 named Health Sciences/Jubilee. New LRT stations The vision for a more Superintendent D.L. (Don) MacDonald submits the first 2006 open at South Campus and McKernan/Belgravia. efficient, environmentally- report to city council on the benefits of LRT. 1989 LRT is 25 years old LRT continues to grow Council accepts LRT Network Plan. friendly public transit, Edmonton’s LRT system celebrates 25 years of Grandin Station opens at the The Health Sciences LRT Station opens making the 2010 including Light Rail Transit 1960s Government Centre, near Alberta’s service. Monthly pass for seniors introduced. track 12.9 kilometres long. (LRT), begins. -

Metro Line Fact Sheet – Operations
METRO LINE FACT SHEET – OPERATIONS For the first time in Edmonton, two different LRT lines are operating on the same set of tracks. The Capital Line continues to operate between Century Park Station and Clareview Station, while the Metro Line is designed to operate between Health Sciences Station and the new NAIT Station. LRT passengers will be able to change between the Capital Line and the Metro Line anywhere between Health Sciences Station and NAIT Station. SIGNALLING SYSTEM Light rail systems operate according to a few basic principles, including ensuring enough space between trains for the system to operate safely. Edmonton’s original LRT system, the Capital Line, has used a fixed-block signalling system, which divides the track into defined blocks and ensures there is always at least one empty block between trains. A new signalling system is being installed to manage train movements on both the Metro and Capital Lines. The communication-based train control signaling system that the Metro Line uses is a type of moving-block system, which maintains a block of space around each train rather than a block of space between each train. This allows ETS to safely tighten up the spacing between trains so they can run more frequently. It has taken the contractor much longer than anticipated to deliver the new signalling system, which has delayed the opening of the Metro Line. STAGED IMPLEMENTATION The City has developed an interim solution in order to open the Metro Line to public service as soon as possible: Fixed Block vs. Moving Block Signalling In the short term, Metro Line trains will run every 15 minutes between Century Park and NAIT. -

LRT Lessons That Can Be Learned from Edmonton and Calgary
TRANSPORTATION RESEARCH RECORD 1361 39 LRT Lessons That Can Be Learned from Edmonton and Calgary J. J. BAKKER Although Edmonton established the first light rail transit (LRT) the southwest via the University of Alberta, and one to the system on the North American continent, it did not sustain mo northwest. The downtown distribution was in the form of a mentum. Edmonton learned from cities such as Cleveland, Frank loop with one-way operation, in tunnel under Jasper Avenue furt am Main, and Philadelphia. In turn Calgary learned from with a single track and above ground along the Canadian Edmonton. Now, 14 yeiirs since the first line in Edmonton opened, it is useful to sum up the lessons. First, continue at a steady rate National (CN) right-of-way. In the early 1970s it was finally of development so that there is continuity in the planning and realized that Edmonton could not afford to build freeways design experience. This also allows local contractors to develop towards the central business district (CBD). The planning expertise. Second, keep the stations simple. With a proof-of evolved from heavy rail to light rail and, some would say, payment fare system, stations can be simple. Avoid changes in back again. levels for passengers, and make the stations user friendly. Third, surface lines should be introduced early. Once tunneling has started, a constituency develops that wants to build a metro system rather than the light construction really needed. Fourth, ridership should Influence of Other Cities be developed by first introducing express buses, which can later be transformed into feeder bus lines to the LRT. -

Canada Rail Opportunities Scoping Report Preface
01 Canada Rail Opportunities Canada Rail Opportunities Scoping Report Preface Acknowledgements Photo and image credits The authors would like to thank the Agence Métropolitaine de Transport following organisations for their help and British Columbia Ministry of Transportation support in the creation of this publication: and Infrastructure Agence Métropolitaine de Transport BC Transit Alberta Ministry of Transport Calgary Transit Alberta High Speed Rail City of Brampton ARUP City of Hamilton Balfour Beatty City of Mississauga Bombardier City of Ottawa Calgary Transit Edmonton Transit Canadian National Railway Helen Hemmingsen, UKTI Toronto Canadian Urban Transit Association Metrolinx Edmonton Transit OC Transpo GO Transit Sasha Musij, UKTI Calgary Metrolinx Société de Transport de Montréal RailTerm TransLink SNC Lavalin Toronto Transit Commission Toronto Transit Commission Wikimedia Commons Wikipedia Front cover image: SkyTrain in Richmond, Vancouver Canada Rail Opportunities Contents Preface Foreword 09 About UK Trade & Investment 10 High Value Opportunities Programme 11 Executive Summary 12 1.0 Introduction 14 2.0 Background on Canada 15 2.1 Macro Economic Review 16 2.2 Public-Private Partnerships 18 3.0 Overview of the Canadian Rail Sector 20 4.0 Review of Urban Transit Operations and Opportunities by Province 21 4.1 Summary Table of Existing Urban Transit Rail Infrastructure and Operations 22 4.2 Summary Table of Key Project Opportunities 24 4.3 Ontario 26 4.4 Québec 33 4.5 Alberta 37 4.6 British Columbia 41 5.0 In-Market suppliers 45 5.1 Contractors 45 5.2 Systems and Rolling Stock 48 5.3 Consultants 49 6.0 Concluding Remarks 51 7.0 Annexes 52 7.1 Doing Business in Canada 52 7.2 Abbreviations 53 7.3 Bibliography 54 7.4 List of Reference Websites 56 7.5 How can UKTI Help UK Organisations Succeed in Canada 58 Contact UKTI 59 04 Canada Rail Opportunities About the Authors David Bill Helen Hemmingsen David is the International Helen Hemmingsen is a Trade Officer Development Director for the UK with the British Consulate General Railway Industry Association (RIA). -

Edmonton's Transit Oriented Development Journey
Edmonton’s Transit Oriented Development Journey Tom Young, MCIP, MCP NZ Group Manager, Urban Planning & Environmental Services Auckland Design Office Lunchtime Learning [email protected] July 2018 Agenda 1 Edmonton? I’m vaguely familiar… 2 Refresher: What is TOD? 3 Edmonton’s Slow Start 4 Getting Up to Speed 5 Lessons for Auckland That’s a Long Way 12,000 km from Auckland The Cities Compared Auckland Edmonton The Cities Compared Auckland Edmonton Regional Population 1.7 million 1.3 million Population by 2042 2.3 million 2.0 million Auto Mode Share 83% 78% PT Mode Share (Commute) 8.4% 14.6% PT Trips Per Capita 55/year 97/year Urban Density 1,400/km2 1,850/km2 2 Refresher: What is TOD? TOD is… “A compact development, with moderate to higher densities, located within an easy walk of a transit station, generally with a mix of residential, employment, and shopping opportunities designed for pedestrians [and cyclists] without excluding the auto.” Source: Arrington, Transit Oriented Development: Understanding the Fundamentals of TOD, 2007 TOD aims to… Encourage walking, cycling and PT Increase public transport revenues Improve safety outcomes Provide public health benefits Support move towards Zero Carbon Create more livable communities Density of Development 400 m (5 min. walk) 200 m Station 800m (and more depending on form of transit) Diversity – A Mix of Uses Housing Shopping Jobs Design – Buildings, Streets and Public Spaces Architecture and Street Multi-modal Streets Relationships Design – Connected Networks 3 Edmonton’s Slow Start 1978 -

LRT for EVERYONE 2 LRT for Everyone
THE WAY WE MOVE LRT FOR EVERYONE 2 LRT for Everyone LRT FOR EVERYONE Light rail is about more than transit; it’s about transforming Edmonton. As the city grows, so do its transportation needs. LRT is an investment in Edmonton’s future: the development of a modern, globally competitive city with a transportation system that meets the needs of a diverse, dynamic and growing population. LRT is reliable, accessible and frequent. LRT is a preferred choice that gets people where they need to go. THE WAY WE MOVE The Way We Move is the City’s 30-year transportation master plan to help Edmonton: GO GROW THRIVE Create sustainable transportation Accommodate a growing city by Develop a city that is economically, options, such as public transit, that providing transportation alternatives socially and environmentally make getting around reliable and designed and built for generations of sustainable with an integrated accessible. Edmontonians. transportation system that creates links throughout the city. High-Floor light rail vehicles are used on Low-Floor light rail vehicles adopt a more Edmonton’s existing LRT system and will be urban style that does not require a station used on future extensions of the Capital and with a raised platform but only a raised curb. Metro lines. Low-Floor vehicles will be used on the Valley Line LRT. 3 LRT NETWORK PLAN AND PROJECTS Edmonton’s LRT Network Plan is a • most tracks at street level. LRT in Edmonton will always have long-term vision to expand the City’s • stations built closer together. dedicated right-of-way but the Valley LRT to five lines by 2040. -

Edmonton City 1986 Mar X to Z
WRI-WUN EDMONTON 794 Wright J A810-1081147 Ave 437-M28 Wright Richard7 LennoxDrStAlb 458-0524 WSG Benefit Consultants Ltd Wright J C9354 79 St 466-2871 Wright Rick103-821583 Ave 465-5743 314-8925 51 Ave.. 466-319! Wright B 556 Ma-UnivCamp 433-0043 Wright J C9104 167Si 484-1304 Wright Rick 041 GlenhavenCrSIAlb... 459-2035 WSG INSURANCE SERVICES Wrights A121-4031 108SL 436-5853 Wright J D10408 Uuder Ave 475-3513 WrightRobertl45246lASi 476-7111 (EDMONTON) LTD Wright BC 5520 40 Ave 462-9336 Wright JFCl681l95Ave 484-2654 Wright Rev Robert Morrison Wright J19-10724115 St 425-8967 314-8925 51 Ave..466-3191 Wright 6 J 146-11004 145 Ave 457-2345 4312 70 St. 463-0297 Wtchuk Willie1231767st 479-1186 Wright Barry 151 Marftmrough PI 481-3835 Wright JN3812 86 SI ; 462-1335 Wright Ron24-10839 UnivAve 433-5127 W2ConsultantsLtd rR4 ShPk 467-935S Wright Barry 990l 163Si 484-2557 Wright J R6508 92AAve 469-6587 Wright RoyS ll71543Ave 434-8638 Wu DrAndrewPath10924107Ave 426-4160 Wright Bernard 104-8518 106 St 431-0317 Wright JS R10992 73 Ave 436-5550 Wrights 8411 69 Ave 469-8056 Wright Jack W50 WooOlake FW Sh Pk... 467-2174 Wu Andrew 15219 43 Ave 430-6676 Wright Bill 14507 20 st 478-4007 WrightS30l-10315ll4Sl 425-0544 WuC508-9930 Bellamy Hill 423-2648 Wright Blue RR4 Sh Pk 922-3954 Wright Jack W265Scothaven ShPk 467-9598 WrightS14245 23Sl 476-6321 WrightJames 9034142st 483-9357 Wu CT 3623 30 Ave 461-4723 WRIGHT BOB AUTO PARTS LTD Wrights 18Groat PiSpGr %2-8869 WuChaolun 1207-9925 JesprAve 426-1826 11338132 Ave. -

CAPITAL Light Rail Time Schedule & Line Route
CAPITAL light rail time schedule & line map CAPITAL Century Park View In Website Mode The CAPITAL light rail line (Century Park) has 2 routes. For regular weekdays, their operation hours are: (1) Century Park: 12:10 AM - 11:55 PM (2) Clareview: 12:10 AM - 11:55 PM Use the Moovit App to ƒnd the closest CAPITAL light rail station near you and ƒnd out when is the next CAPITAL light rail arriving. Direction: Century Park CAPITAL light rail Time Schedule 16 stops Century Park Route Timetable: VIEW LINE SCHEDULE Sunday 12:10 AM - 11:55 PM Monday 5:10 AM - 11:55 PM Clareview Station Tuesday 12:10 AM - 11:55 PM Dl Macdonald Platform Wednesday 12:10 AM - 11:55 PM Belvedere Station Thursday 12:10 AM - 11:55 PM Coliseum Station Friday 12:10 AM - 11:55 PM Stadium Station Saturday 12:10 AM - 11:55 PM 8328 111 Avenue North-west, Edmonton Churchill Station 99 Street NW, Edmonton CAPITAL light rail Info Central Station Direction: Century Park Jasper Avenue NW, Edmonton Stops: 16 Trip Duration: 34 min Bay Enterprise Square Line Summary: Clareview Station, Dl Macdonald 10309 Jasper Avenue North-west, Edmonton Platform, Belvedere Station, Coliseum Station, Stadium Station, Churchill Station, Central Station, Corona Station Bay Enterprise Square, Corona Station, Government 10660 Jasper Avenue North-west, Edmonton Centre Station, University Station, Health Sciences Jubilee Station, Mckernan Belgravia Station, South Government Centre Station Campus Station, Southgate Station, Century Park 9759 110 Street North-west, Edmonton Station University Station Health -

Solving the ‘First Mile Problem’ Opportunities for Bike-Transit Integration in Edmonton, Alberta by Derek Yau
Solving the ‘First Mile Problem’ Opportunities for bike-transit integration in Edmonton, Alberta by Derek Yau A practicum submitted to the Faculty of Graduate Studies of the University of Manitoba in partial fulfillment of the requirements of the degree of MASTER OF CITY PLANNING Department of City Planning Faculty of Architecture University of Manitoba Winnipeg Copyright © 2016 Derek Yau Abstract In an effort to shift reliance away from single-occupancy vehicles, many cities have been investing in active and public transportation, and promoting multi-modal travel. It has been recognized both academically and professionally that there is a need to address issues regarding access to transit stations and nodes – the ‘first mile problem.’ Many see bicycles as the answer to the first mile problem; however, scholarly literature has generally neglected exploring how to accommodate bicycles at different stations. This practicum investigates the first mile problem in Edmonton, Alberta, and identifies existing challenges with bicycle access to Edmonton’s Light Rail Transit (LRT) system. The findings suggest three distinct LRT ‘station types’, each requiring a nuanced suite of infrastructure improvements in order to encourage more bicycle access. Further, these improvements can only be realized through the development and execution of comprehensive policies and regulations that support cycling and bike-transit integration. [Keywords: Cycling, first mile problem, transit accessibility, active transportation, Edmonton] i Acknowledgements I would like to extend a sincere thanks to my advisor, Dr. Orly Linovski, for her invaluable guidance throughout the writing of this practicum. I would also like to thank committee members Dr. Rae Bridgman and the University of Alberta’s Dr. -

MARTIN GARBER-CONRAD P13 Leader of Legacy TIME TRAVEL P16 Streetcars to Light Rail
FALL 2019 MARTIN GARBER-CONRAD p13 Leader of Legacy TIME TRAVEL p16 Streetcars to light rail WILD THINGS p6 When your mission is rescue We are pleased to support the Edmonton Community Foundation Global private markets investment solutions for Canadian institutional investors. www.northleafcapital.com TORONTO / MONTREAL / LONDON / NEW YORK / CHICAGO / MENLO PARK / MELBOURNE Edmonton Community Foundation is pleased to present free public seminars that provide professional information on wills and estates. Please join us at one of the sessions listed below. Mon, Oct. 7 9:30 - 11:30 a.m. Tues, Oct. 8 6:30 - 8:30 p.m. Thurs, Oct. 10 6:30 - 8:30 p.m. Northgate Lions Senior Rec. Centre Millennium Place Northgate Lions Senior Rec. Centre 7524 139 Avenue N.W. 2000 Premier Way, Sherwood Park 7524 139 Avenue N.W. Mon, Oct. 7 6:30 - 8:30 p.m. Wed, Oct. 9 6:30 - 8:30 p.m. Fri, Oct. 11 9:30 - 11:30 a.m. South East Edmonton Seniors Assoc. Mill Woods Seniors & Multi-Cultural Central Lions Seniors Association Activity Centre 9350 82 Street N.W. Centre, Rm 231, 2610 Hewes Way N.W. 11113 113 Street N.W. Mon, Oct. 7 6:30 - 8:30 p.m. Wed, Oct. 9 6:30 - 8:30 p.m. Fri, Oct. 11 6:30 - 8:30 p.m. The Red Willow, St. Albert Seniors Terwillegar Rec Centre, Telus World of Science, Association 7 Tache Street Rm 6, 2051 Leger Road NW 2nd Floor, 11211 142 Street N.W. Tues, Oct. 8 6:30 - 8:30 p.m. -

Transit Master Plan Project No
Strathcona County Transit Transit Master Plan Project No. 10-013 December 2011 Final Report Transit Solutions GENIVAR Inc. 2800 Fourteenth Avenue, Suite 210, Markham, Ontario L3R 0E4 Telephone: 905.946.8900 Fax: 905.946.8966 www.genivar.com Contact: Dennis Fletcher, M.E.S. E-mail: [email protected] Strathcona County Transit Master Plan Final Report Table of Contents TABLE OF CONTENTS .......................................................................................................................... I LIST OF EXHIBITS ............................................................................................................................... III EXECUTIVE SUMMARY ....................................................................................................................... 1 Introduction .......................................................................................................................... 1 Needs and Opportunities...................................................................................................... 2 Recommendations ............................................................................................................... 4 1. INTRODUCTION .......................................................................................................................... 11 1.1.1 The Transit Master Plan Process and Structure .......................................... 11 2. NEEDS AND OPPORTUNITIES ................................................................................................. -

Edmonton City Museum Project
& WorldViews Consulting Title Edmonton City Museum Project Description Background Research Date Issued 27 February 2015 Recipient Edmonton Heritage Council REPORT email: [email protected] address: phone: +1 403 589 5646 1221B Kensington Road NW web: intelligentfutures.ca Calgary AB twitter: @intfutures Canada T2N 3P8 Document prepared and submitted February 2015. iii Contents The City & History 1 1 an introduction to the edmonton city museum Story & Practice 3 2 best practices in museum design Edmonton Then & Now 19 3 where we’ve been and where we’re going Moving Forward 39 4 where we’re headed next The City Museum Concept 43 A appendix a: previous city museum work A Reading List 63 B appendix b: sources consulted 1 THE CITY & HISTORY An introduction to the Edmonton City Museum Government of Alberta Government 2 he following research report will provide a base from which to develop a strategy for the Edmonton City Museum Project. The discussion of a city museum has been part of the municipal conversation for decades. As a result, there has been a lot of informative and Titerative work conducted to frame the project over the last number of years. This report strives to complement this existing work by focusing on two evolving contexts - evolving museum practices and the evolving Edmonton context. The first part of this report reviews changing practices in museums. Traditional museum models still dominate the field today, yet there is tremendous potential to create a model that is more responsive to its local context. An analysis of progressive museums around the world is intended to evolve the thinking on the Edmonton City Museum and open up new possibilities for consideration.