Reference Architecture Description
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
![Archons (Commanders) [NOTICE: They Are NOT Anlien Parasites], and Then, in a Mirror Image of the Great Emanations of the Pleroma, Hundreds of Lesser Angels](https://docslib.b-cdn.net/cover/8862/archons-commanders-notice-they-are-not-anlien-parasites-and-then-in-a-mirror-image-of-the-great-emanations-of-the-pleroma-hundreds-of-lesser-angels-438862.webp)
Archons (Commanders) [NOTICE: They Are NOT Anlien Parasites], and Then, in a Mirror Image of the Great Emanations of the Pleroma, Hundreds of Lesser Angels
A R C H O N S HIDDEN RULERS THROUGH THE AGES A R C H O N S HIDDEN RULERS THROUGH THE AGES WATCH THIS IMPORTANT VIDEO UFOs, Aliens, and the Question of Contact MUST-SEE THE OCCULT REASON FOR PSYCHOPATHY Organic Portals: Aliens and Psychopaths KNOWLEDGE THROUGH GNOSIS Boris Mouravieff - GNOSIS IN THE BEGINNING ...1 The Gnostic core belief was a strong dualism: that the world of matter was deadening and inferior to a remote nonphysical home, to which an interior divine spark in most humans aspired to return after death. This led them to an absorption with the Jewish creation myths in Genesis, which they obsessively reinterpreted to formulate allegorical explanations of how humans ended up trapped in the world of matter. The basic Gnostic story, which varied in details from teacher to teacher, was this: In the beginning there was an unknowable, immaterial, and invisible God, sometimes called the Father of All and sometimes by other names. “He” was neither male nor female, and was composed of an implicitly finite amount of a living nonphysical substance. Surrounding this God was a great empty region called the Pleroma (the fullness). Beyond the Pleroma lay empty space. The God acted to fill the Pleroma through a series of emanations, a squeezing off of small portions of his/its nonphysical energetic divine material. In most accounts there are thirty emanations in fifteen complementary pairs, each getting slightly less of the divine material and therefore being slightly weaker. The emanations are called Aeons (eternities) and are mostly named personifications in Greek of abstract ideas. -

Siren Song: a Rhetorical Analysis of Gender and Intimate Partner Violence in Gotham City Sirens
Graduate Research Symposium (GCUA) (2010 - 2017) Graduate Research Symposium 2015 Apr 20th, 1:00 PM - 2:30 PM Siren Song: A Rhetorical Analysis of Gender and Intimate Partner Violence In Gotham City Sirens Scarlett Schmidt University of Nevada, Las Vegas Follow this and additional works at: https://digitalscholarship.unlv.edu/grad_symposium Part of the Gender, Race, Sexuality, and Ethnicity in Communication Commons, and the Public Affairs Commons Repository Citation Schmidt, Scarlett, "Siren Song: A Rhetorical Analysis of Gender and Intimate Partner Violence In Gotham City Sirens" (2015). Graduate Research Symposium (GCUA) (2010 - 2017). 1. https://digitalscholarship.unlv.edu/grad_symposium/2015/april20/1 This Event is protected by copyright and/or related rights. It has been brought to you by Digital Scholarship@UNLV with permission from the rights-holder(s). You are free to use this Event in any way that is permitted by the copyright and related rights legislation that applies to your use. For other uses you need to obtain permission from the rights-holder(s) directly, unless additional rights are indicated by a Creative Commons license in the record and/ or on the work itself. This Event has been accepted for inclusion in Graduate Research Symposium (GCUA) (2010 - 2017) by an authorized administrator of Digital Scholarship@UNLV. For more information, please contact [email protected]. Siren Song: A Rhetorical Analysis of Gender and Intimate Partner Violence in Gotham City Sirens Scarlett Schmidt Abstract Justification Communication Studies 1. Superheroes have been cultural fixtures since 1938 and have been growing in This project investigates comic book discourse. Specifically, I investigate how comic popularity over the past ten years. -

“Justice League Detroit”!
THE RETRO COMICS EXPERIENCE! t 201 2 A ugus o.58 N . 9 5 $ 8 . d e v r e s e R s t h ® g i R l l A . s c i m o C C IN THE BRONZE AGE! D © & THE SATELLITE YEARS M T a c i r e INJUSTICE GANG m A f o e MARVEL’s JLA, u g a e L SQUADRON SUPREME e c i t s u J UNOFFICIAL JLA/AVENGERS CROSSOVERS 7 A SALUTE TO DICK DILLIN 0 8 2 “PRO2PRO” WITH GERRY 6 7 7 CONWAY & DAN JURGENS 2 8 5 6 And the team fans 2 8 love to hate — 1 “JUSTICE LEAGUE DETROIT”! The Retro Comics Experience! Volume 1, Number 58 August 2012 Celebrating the Best Comics of the '70s, '80s, '90s, and Beyond! EDITOR Michael “Superman”Eury PUBLISHER John “T.O.” Morrow GUEST DESIGNER Michael “BaTman” Kronenberg COVER ARTIST ISSUE! Luke McDonnell and Bill Wray . s c i m COVER COLORIST o C BACK SEAT DRIVER: Editorial by Michael Eury .........................................................2 Glenn “Green LanTern” WhiTmore C D © PROOFREADER & Whoever was sTuck on MoniTor DuTy FLASHBACK: 22,300 Miles Above the Earth .............................................................3 M T . A look back at the JLA’s “Satellite Years,” with an all-star squadron of creators a c i r SPECIAL THANKS e m Jerry Boyd A Rob Kelly f o Michael Browning EllioT S! Maggin GREATEST STORIES NEVER TOLD: Unofficial JLA/Avengers Crossovers ................29 e u Rich Buckler g Luke McDonnell Never heard of these? Most folks haven’t, even though you might’ve read the stories… a e L Russ Burlingame Brad MelTzer e c i T Snapper Carr Mi ke’s Amazing s u J Dewey Cassell World of DC INTERVIEW: More Than Marvel’s JLA: Squadron Supreme ....................................33 e h T ComicBook.com Comics SS editor Ralph Macchio discusses Mark Gruenwald’s dictatorial do-gooders g n i r Gerry Conway Eri c Nolen- r a T s DC Comics WeaThingTon , ) 6 J. -

Batwoman and Catwoman: Treatment of Women in DC Comics
Wright State University CORE Scholar Browse all Theses and Dissertations Theses and Dissertations 2013 Batwoman and Catwoman: Treatment of Women in DC Comics Kristen Coppess Race Wright State University Follow this and additional works at: https://corescholar.libraries.wright.edu/etd_all Part of the English Language and Literature Commons Repository Citation Race, Kristen Coppess, "Batwoman and Catwoman: Treatment of Women in DC Comics" (2013). Browse all Theses and Dissertations. 793. https://corescholar.libraries.wright.edu/etd_all/793 This Thesis is brought to you for free and open access by the Theses and Dissertations at CORE Scholar. It has been accepted for inclusion in Browse all Theses and Dissertations by an authorized administrator of CORE Scholar. For more information, please contact [email protected]. BATWOMAN AND CATWOMAN: TREATMENT OF WOMEN IN DC COMICS A thesis submitted in partial fulfillment of the requirements for the degree of Master of Arts By KRISTEN COPPESS RACE B.A., Wright State University, 2004 M.Ed., Xavier University, 2007 2013 Wright State University WRIGHT STATE UNIVERSITY GRADUATE SCHOOL Date: June 4, 2013 I HEREBY RECOMMEND THAT THE THESIS PREPARED UNDER MY SUPERVISION BY Kristen Coppess Race ENTITLED Batwoman and Catwoman: Treatment of Women in DC Comics . BE ACCEPTED IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF Master of Arts. _____________________________ Kelli Zaytoun, Ph.D. Thesis Director _____________________________ Carol Loranger, Ph.D. Chair, Department of English Language and Literature Committee on Final Examination _____________________________ Kelli Zaytoun, Ph.D. _____________________________ Carol Mejia-LaPerle, Ph.D. _____________________________ Crystal Lake, Ph.D. _____________________________ R. William Ayres, Ph.D. -

PDF Download Aquaman: Kingdom Lost 1St Edition Ebook
AQUAMAN: KINGDOM LOST 1ST EDITION PDF, EPUB, EBOOK John Arcudi | 9781401271299 | | | | | Aquaman: Kingdom Lost 1st edition PDF Book His plan now despoiled by his exile from their world, Namor returns to Earth to resume his war with the land dwellers after jokingly citing how the Non-Team up of the Defenders had saved it from annihilation. In Sword of Atlantis 57, the series' final issue, Aquaman is visited by the Lady of the Lake, who explains his origins. Vintage Dictionary. See All - Best Selling. In the Marvel limited series Fantastick Four , Namor is reinvented as Numenor , Emperor of Bensaylum, a city beyond the edge of the world. Archived from the original on April 22, Bill Everett. These included: the ability to instantly dehydrate to death anyone he touched, shoot jets of scalding or freezing water from it, healing abilities, the ability to create portals into mystical dimensions that could act as spontaneous transport, control and negate magic, manipulate almost any body of water he sets his focuses on [2] and the capability to communicate with the Lady of the Lake through his magic water hand. When his former friend Captain America presented himself to the Atlanteans to broker an agreement with Namor, he attacked Captain America in a rage while ranting about how Atlantis has taken the heat of the surface world's battles time and time again. Character Facts Powers: super strength, durability, control over sea life, exceptional swimming ability, ability to breathe underwater. Aquaman was given an eighth volume of his eponymous series, which started with a one-shot comic book entitled Aquaman: Rebirth 1 August Aquaman 1. -

Customer Order Form
#350 | NOV17 PREVIEWS world.com ORDERS DUE NOV 18 THE COMIC SHOP’S CATALOG PREVIEWSPREVIEWS CUSTOMER ORDER FORM CUSTOMER 601 7 Nov17 Cover ROF and COF.indd 1 10/5/2017 11:39:39 AM Nov17 Abstract C3.indd 1 10/5/2017 9:16:14 AM INVINCIBLE #144 HUNGRY GHOSTS #1 IMAGE COMICS DARK HORSE COMICS THE TERRIFICS #1 DC ENTERTAINMENT KOSCHEI THE DEATHLESS #1 THE WALKING DARK HORSE COMICS DEAD #175 IMAGE COMICS STAR WARS ADVENTURES: FORCES OF DESTINY ONE-SHOTS IDW ENTERTAINMENT SIDEWAYS #1 OLD MAN DC ENTERTAINMENT HAWKEYE #1 MARVEL COMICS Nov17 Gem Page ROF COF.indd 1 10/5/2017 3:24:03 PM FEATURED ITEMS COMIC BOOKS & GRAPHIC NOVELS Strangers In Paradise XVX #1 l ABSTRACT STUDIOS Pestilence Volume 1 TP l AFTERSHOCK COMICS Uber Volume 6 TP l AVATAR PRESS INC Mech Cadet Yu Volume 1 TP l BOOM! STUDIOS Planet of the Apes: Ursus #1 l BOOM! STUDIOS 1 Dejah Thoris #0 l D. E./DYNAMITE ENTERTAINMENT Battlestar Galactica Vs. Battlestar Galactica #1 l D. E./DYNAMITE ENTERTAINMENT Sailor Moon Volume 1 Eternal Edition SC l KODANSHA COMICS Sci-Fu GN l ONI PRESS INC. Devilman Vs. Hades Volume 1 GN l SEVEN SEAS ENTERTAINMENT LLC Yokai Girls Volume 1 GN l SEVEN SEAS GHOST SHIP Warhammer 40,000: Deathwatch #1 l TITAN COMICS Assassin’s Creed Origins #1 l TITAN COMICS Mega Man Mastermix #1 l UDON ENTERTAINMENT INC 1 Ninjak Vs The Valiant Universe #1 l VALIANT ENTERTAINMENT LLC RWBY GN l VIZ MEDIA LLC BOOKS Marvel Black Panther: The Ultimate Guide HC l COMICS Marvels Black Panther: Illustrated History of a King HC l COMICS A Tribute To Mike Mignola’s Hellboy Show Catalogue -

With Gerry Conway & Dan Jurgens
Justice League of America TM & © DC Comics. All Rights Reserved. 0 7 No.58 August 2012 $ 8 . 9 5 1 82658 27762 8 THE RETRO COMICS EXPERIENCE! IN THE BRONZE AGE! “JUSTICE LEAGUE DETROIT”! UNOFFICIAL JLA/AVENGERS CONWAY & DAN JURGENS A SALUTE TO DICK DILLIN “PRO2PRO” WITH GERRY THE SATELLITE YEARS SQUADRON SUPREME And the team fans love to hate — INJUSTICE GANG MARVEL’s JLA, CROSSOVERS ® The Retro Comics Experience! Volume 1, Number 58 August 2012 Celebrating the Best Comics of the '70s, '80s, '90s, and Beyond! EDITOR Michael “Superman”Eury PUBLISHER John “T.O.” Morrow GUEST DESIGNER Michael “Batman” Kronenberg COVER ARTIST ISSUE! Luke McDonnell and Bill Wray COVER COLORIST BACK SEAT DRIVER: Editorial by Michael Eury.........................................................2 Glenn “Green Lantern” Whitmore PROOFREADER Whoever was stuck on Monitor Duty FLASHBACK: 22,300 Miles Above the Earth .............................................................3 A look back at the JLA’s “Satellite Years,” with an all-star squadron of creators SPECIAL THANKS Jerry Boyd Rob Kelly Michael Browning Elliot S! Maggin GREATEST STORIES NEVER TOLD: Unofficial JLA/Avengers Crossovers................29 Rich Buckler Luke McDonnell Never heard of these? Most folks haven’t, even though you might’ve read the stories… Russ Burlingame Brad Meltzer Snapper Carr Mike’s Amazing Dewey Cassell World of DC INTERVIEW: More Than Marvel’s JLA: Squadron Supreme....................................33 ComicBook.com Comics SS editor Ralph Macchio discusses Mark Gruenwald’s dictatorial do-gooders Gerry Conway Eric Nolen- DC Comics Weathington J. M. DeMatteis Martin Pasko BRING ON THE BAD GUYS: The Injustice Gang.....................................................43 Rich Fowlks Chuck Patton These baddies banded together in the Bronze Age to bedevil the League Mike Friedrich Shannon E. -

ANDREW BURTCH Heralds of Doom
ANDREW BURTCH Heralds of Doom Résumé : Abstract Du début de la Guerre froide jusqu’au milieu des années From the early Cold War until the mid-1960s, 1960, le gouvernement et les agences gouvernementales government and military agencies moved to purchase ont acheté et installé des sirènes pour prévenir des raids and install air raid sirens across the country, as part of a aériens à travers le pays dans le cadre du programme program to prepare Canada for nuclear war. The sirens devant préparer le Canada à la guerre nucléaire. Les transformed everyday public sites into often unwelcome sirènes transformèrent les lieux du quotidien en rappels reminders of the ever-present threat of nuclear war. The souvent malvenus de la menace constante de la guerre siren network was dismantled at the end of the Cold nucléaire. Le réseau des sirènes fut démantelé à la fin War, yet, in the past five years, “rediscovery” of sirens has de la Guerre froide, mais cependant, ces cinq dernières generated debate over whether to restore and repurpose années, la « redécouverte » des sirènes a suscité des débats the alarms for commemorative display or to discard them pour savoir s’il fallait les restaurer et leur conférer une as a legacy of the absurdity of nuclear survival plans. nouvelle fonction commémorative, ou les éliminer car This study, using recently released archival sources, elles représentaient un héritage de l’absurdité des plans presents the material history and cultural impact of the de survie nucléaire. Cette étude, qui recourt à des sources Canadian air raid siren. d’archives disponibles depuis peu, présente l’histoire matérielle et l’impact culturel des sirènes anti-raids aériens au Canada. -

Cathy Trask, Monstrosity, and Gender-Based Fears in John Steinbeckâ•Žs East of Eden
Brigham Young University BYU ScholarsArchive Theses and Dissertations 2014-06-01 Cathy Trask, Monstrosity, and Gender-Based Fears in John Steinbeck’s East of Eden Claire Warnick Brigham Young University - Provo Follow this and additional works at: https://scholarsarchive.byu.edu/etd Part of the Classics Commons, and the Comparative Literature Commons BYU ScholarsArchive Citation Warnick, Claire, "Cathy Trask, Monstrosity, and Gender-Based Fears in John Steinbeck’s East of Eden" (2014). Theses and Dissertations. 5282. https://scholarsarchive.byu.edu/etd/5282 This Thesis is brought to you for free and open access by BYU ScholarsArchive. It has been accepted for inclusion in Theses and Dissertations by an authorized administrator of BYU ScholarsArchive. For more information, please contact [email protected], [email protected]. Cathy Trask, Monstrosity, and Gender-Based Fears in John Steinbeck’s East of Eden Claire Warnick A thesis submitted to the faculty of Brigham Young University in partial fulfillment of the requirements for the degree of Master of Arts Carl H. Sederholm, Chair Francesca R. Lawson Kerry D. Soper Department of Humanities, Classics, and Comparative Literature Brigham Young University June 2014 Copyright © 2014 Claire Warnick All Rights Reserved ABSTRACT Cathy Trask, Monstrosity, and Gender-Based Fears in John Steinbeck’s East of Eden Claire Warnick Department of Humanities, Classics, and Comparative Literature, BYU Master of Arts In recent years, the concept of monstrosity has received renewed attention by literary critics. Much of this criticism has focused on horror texts and other texts that depict supernatural monsters. However, the way that monster theory explores the connection between specific cultures and their monsters illuminates not only our understanding of horror texts, but also our understanding of any significant cultural artwork. -
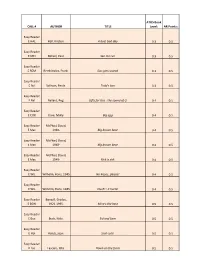
Master List for AR Revised
ATOS Book CALL # AUTHOR TITLE Level: AR Points: Easy Reader E HAL Hall, Kirsten. A bad, bad day 0.3 0.5 Easy Reader E MEI Meisel, Paul. See me run 0.3 0.5 Easy Reader E REM Remkiewicz, Frank. Gus gets scared 0.3 0.5 Easy Reader E Sul Sullivan, Paula. Todd's box 0.3 0.5 Easy Reader E Bal Ballard, Peg. Gifts for Gus : the sound of G 0.4 0.5 Easy Reader E COX Coxe, Molly. Big egg 0.4 0.5 Easy Reader McPhail, David, E Mac 1940- Big brown bear 0.4 0.5 Easy Reader McPhail, David, E Mac 1940- Big brown bear 0.4 0.5 Easy Reader McPhail, David, E Mac 1940- Rick is sick 0.4 0.5 Easy Reader E WIL Wilhelm, Hans, 1945- No kisses, please! 0.4 0.5 Easy Reader E WIL Wilhelm, Hans, 1945- Ouch! : it hurts! 0.4 0.5 Easy Reader Bonsall, Crosby, E BON 1921-1995. Mine's the best 0.5 0.5 Easy Reader E Buc Buck, Nola. Sid and Sam 0.5 0.5 Easy Reader E Hol Holub, Joan. Scat cats! 0.5 0.5 Easy Reader E Las Lascaro, Rita. Down on the farm 0.5 0.5 Easy Reader E Mor Moran, Alex. Popcorn 0.5 0.5 Easy Reader E Tri Trimble, Patti. What day is it? 0.5 0.5 Easy Reader E Wei Weiss, Ellen, 1949- Twins in the park 0.5 0.5 Easy Reader E Kli Amoroso, Cynthia. -

Name: Jackie Moore EDX Username: Keriangel Email: [email protected] the RISE of SUPERHEROES and THEIR IMPACT on POP CULTURE // SUPERHERO DOSSIER
Name: Jackie Moore EDX Username: keriangel Email: [email protected] THE RISE OF SUPERHEROES AND THEIR IMPACT ON POP CULTURE // SUPERHERO DOSSIER WHO DID WE MISS ? dossier (noun): a group of papers containing detailed information about a person or group It’s the end of the course and you can’t believe we only talked about a handful of comic book creations! We know that the comic book world has many more superheroes and villains than we could possibly fit in a six-week course. That’s why we want to give you a chance to create your own superhero dossier. In this companion to The Rise of Superheroes & Their Impact on Pop Culture, we will lead you through the process of compiling a dossier of a character of your choice in the same style you saw in the course’s Superhero Biographies. You’ll give the character’s basic information (name, aliases, enemies, etc.) Next, you’ll share a signature quote from that character. You’ll explain the important social issues and historical events going on at the time of the character’s creation. (This is where all that research you’ve done over the course will kick in!) Finally, you’ll select a scene from one of your character’s comic books that explains who he or she is and why he or she is so important to the history of comics. It’s up to you to select who you want to write about. Choose from any genre - comic book, graphic novels, manga - and any kind of character - superhero or villain. -

Region 22 Ema Covid-19 Update
REGION 22 EMA COVID-19 UPDATE ISSUE NO 83 | JANUARY 21, 2021 | THURSDAY UNITED STATES Total Cases: 24,135,690 Total Deaths: 400,306 NEBRASKA Total Cases: 184,482 Recovered: 129,608 Active Cases: 53,012 Total Deaths: 1,862 VACCINATIONS MARCH ALONG The Vaccine Distribution in Scotts In addition to those clinics, we continue to Bluff County is beginning to move schedule the elderly population into drive- REGION 22 faster, thanks to regular shipments of through or walk-in clinics. The next one of SCOTTS BLUFF COUNTY vaccine from the state. Next week those will be a drive through clinic on Total Cases: 4,291 th will see the second round of shots for Friday, January 29 . Those that have Recovered: 4,115 those who received them in the last signed up through a web link at Active Cases: 98 week of December. These were https://nalhd.sjc1.qualtrics.com/jfe/form/ Deaths: 78 mostly healthcare workers, first SV_ac2SldBi7psAD0p or have called 308- responders, some teachers and 262-5764 or 308-633-2866 Extension 101 will BANNER COUNTY some public transportation workers. be contacted next week to report to the Total Cases: 23 Locations for those clinics are location on Friday. The list created by Recovered: 23 WestWay Church in Scottsbluff on these registrations is then sorted by date of Active Cases: 0 Deaths: 0 January 26th and Gering Street birth. The older individuals are being Department on January 27th. assigned first, so we ask for patience while Announcements to those people will we work through the list. These people are go out today by Panhandle Alert.