Exploring Geospatial Music Listening Patterns in Microblog Data
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Hip Hop Pedagogies of Black Women Rappers Nichole Ann Guillory Louisiana State University and Agricultural and Mechanical College
Louisiana State University LSU Digital Commons LSU Doctoral Dissertations Graduate School 2005 Schoolin' women: hip hop pedagogies of black women rappers Nichole Ann Guillory Louisiana State University and Agricultural and Mechanical College Follow this and additional works at: https://digitalcommons.lsu.edu/gradschool_dissertations Part of the Education Commons Recommended Citation Guillory, Nichole Ann, "Schoolin' women: hip hop pedagogies of black women rappers" (2005). LSU Doctoral Dissertations. 173. https://digitalcommons.lsu.edu/gradschool_dissertations/173 This Dissertation is brought to you for free and open access by the Graduate School at LSU Digital Commons. It has been accepted for inclusion in LSU Doctoral Dissertations by an authorized graduate school editor of LSU Digital Commons. For more information, please [email protected]. SCHOOLIN’ WOMEN: HIP HOP PEDAGOGIES OF BLACK WOMEN RAPPERS A Dissertation Submitted to the Graduate Faculty of the Louisiana State University and Agricultural and Mechanical College in partial fulfillment of the requirements for the degree of Doctor of Philosophy in The Department of Curriculum and Instruction by Nichole Ann Guillory B.S., Louisiana State University, 1993 M.Ed., University of Louisiana at Lafayette, 1998 May 2005 ©Copyright 2005 Nichole Ann Guillory All Rights Reserved ii For my mother Linda Espree and my grandmother Lovenia Espree iii ACKNOWLEDGMENTS I am humbled by the continuous encouragement and support I have received from family, friends, and professors. For their prayers and kindness, I will be forever grateful. I offer my sincere thanks to all who made sure I was well fed—mentally, physically, emotionally, and spiritually. I would not have finished this program without my mother’s constant love and steadfast confidence in me. -

Adult Contemporary Radio at the End of the Twentieth Century
University of Kentucky UKnowledge Theses and Dissertations--Music Music 2019 Gender, Politics, Market Segmentation, and Taste: Adult Contemporary Radio at the End of the Twentieth Century Saesha Senger University of Kentucky, [email protected] Digital Object Identifier: https://doi.org/10.13023/etd.2020.011 Right click to open a feedback form in a new tab to let us know how this document benefits ou.y Recommended Citation Senger, Saesha, "Gender, Politics, Market Segmentation, and Taste: Adult Contemporary Radio at the End of the Twentieth Century" (2019). Theses and Dissertations--Music. 150. https://uknowledge.uky.edu/music_etds/150 This Doctoral Dissertation is brought to you for free and open access by the Music at UKnowledge. It has been accepted for inclusion in Theses and Dissertations--Music by an authorized administrator of UKnowledge. For more information, please contact [email protected]. STUDENT AGREEMENT: I represent that my thesis or dissertation and abstract are my original work. Proper attribution has been given to all outside sources. I understand that I am solely responsible for obtaining any needed copyright permissions. I have obtained needed written permission statement(s) from the owner(s) of each third-party copyrighted matter to be included in my work, allowing electronic distribution (if such use is not permitted by the fair use doctrine) which will be submitted to UKnowledge as Additional File. I hereby grant to The University of Kentucky and its agents the irrevocable, non-exclusive, and royalty-free license to archive and make accessible my work in whole or in part in all forms of media, now or hereafter known. -
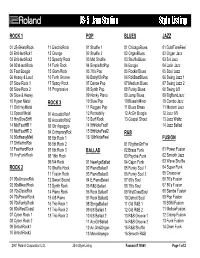
PTSVNWU JS-5 Jam Station Style Listing
PTSVNWU JS-5 Jam Station Style Listing ROCK 1 POP BLUES JAZZ 01 JS-5HardRock 11 ElectricRock 01 Shuffle 1 01 ChicagoBlues 01 DublTimeFeel 02 BritHardRck1 12 Grunge 02 Shuffle 2 02 OrganBlues 02 Organ Jazz 03 BritHardRck2 13 Speedy Rock 03 Mid Shuffle 03 ShuffleBlues 03 5/4 Jazz 04 80'sHardRock 14 Funk Rock 04 Simple8btPop 04 Boogie 04 Latin Jazz 05 Fast Boogie 15 Glam Rock 05 70's Pop 05 Rockin'Blues 05 Soul Jazz 06 Heavy & Loud 16 Funk Groove 06 Early80'sPop 06 RckBeatBlues 06 Swing Jazz 1 07 Slow Rock 1 17 Spacy Rock 07 Dance Pop 07 Medium Blues 07 Swing Jazz 2 08 Slow Rock 2 18 Progressive 08 Synth Pop 08 Funky Blues 08 Swing 6/8 09 Slow & Heavy 09 Honky Piano 09 Jump Blues 09 BigBandJazz 10 Hyper Metal ROCK 3 10 Slow Pop 10 BluesInMinor 10 Combo Jazz 11 Old HvyMetal 11 Reggae Pop 11 Blues Brass 11 Modern Jazz 12 Speed Metal 01 AcousticRck1 12 Rockabilly 12 AcGtr Boogie 12 Jazz 6/8 13 HvySlowShffl 02 AcousticRck2 13 Surf Rock 13 Gospel Shout 13 Jazz Waltz 14 MidFastHR 1 03 Gtr Arpeggio 14 8thNoteFeel1 14 Jazz Ballad 15 MidFastHR 2 04 CntmpraryRck 15 8thNoteFeel2 R&B 16 80sHeavyMetl 05 8bt Rock 1 16 16thNoteFeel FUSION 17 ShffleHrdRck 06 8bt Rock 2 01 RhythmGtrFnk 18 FastHardRock 07 8bt Rock 3 BALLAD 02 Brass Funk 01 Power Fusion 19 HvyFunkRock 08 16bt Rock 03 Psyche-Funk 02 Smooth Jazz 09 5/4 Rock 01 NewAgeBallad 04 Cajun Funk 03 Wave Shuffle ROCK 2 10 Shuffle Rock 02 PianoBallad1 05 Funky Soul 1 04 Super Funk 11 Fusion Rock 03 PianoBallad2 06 Funky Soul 2 05 Crossover 01 90sGrooveRck 12 Sweet Sound 04 E.PianoBalad 07 60's Soul 06 -

ENG 350 Summer12
ENG 350: THE HISTORY OF HIP-HOP With your host, Dr. Russell A. Potter, a.k.a. Professa RAp Monday - Thursday, 6:30-8:30, Craig-Lee 252 http://350hiphop.blogspot.com/ In its rise to the top of the American popular music scene, Hip-hop has taken on all comers, and issued beatdown after beatdown. Yet how many of its fans today know the origins of the music? Sure, people might have heard something of Afrika Bambaataa or Grandmaster Flash, but how about the Last Poets or Grandmaster CAZ? For this class, we’ve booked a ride on the wayback machine which will take us all the way back to Hip-hop’s precursors, including the Blues, Calypso, Ska, and West African griots. From there, we’ll trace its roots and routes through the ‘parties in the park’ in the late 1970’s, the emergence of political Hip-hop with Public Enemy and KRS-One, the turn towards “gangsta” style in the 1990’s, and on into the current pantheon of rappers. Along the way, we’ll take a closer look at the essential elements of Hip-hop culture, including Breaking (breakdancing), Writing (graffiti), and Rapping, with a special look at the past and future of turntablism and digital sampling. Our two required textbook are Bradley and DuBois’s Anthology of Rap (Yale University Press) and Neal and Forman’s That's the Joint: The Hip-Hop Studies Reader are both available at the RIC campus store. Films shown in part or in whole will include Bamboozled, Style Wars, The Freshest Kids: A History of the B-Boy, Wild Style, and Zebrahead; there will is also a course blog with a discussion board and a wide array of links to audio and text resources at http://350hiphop.blogspot.com/ WRITTEN WORK: An informal response to our readings and listenings is due each week on the blog. -

16: the Up-And-Coming Metro Phoenix Bands to Watch This Year
1/28/2016 16 Metro Phoenix Bands to Watch in 2016 | Phoenix New Times 16 FOR '16: THE UP-AND-COMING METRO PHOENIX BANDS TO WATCH THIS YEAR BY AMY YOUNG, LAUREN WISE, JARON IKNER, TOM REARDON, JEFF MOSES, ROGER CALAMAIO, GARYN KLASEK, SERENE DOMINIC, JASON KEIL, JASON P. WOODBURY, MITCHELL HILLMAN WEDNESDAY, JANUARY 27, 2016 | 1 DAY AGO Couples Fight Jim Louvau The new year means new beginnings, fresh ideas, and more chances to give birth to new projects. In such a populous area, we are privy to a tremendous amount of ambition and diversity when it comes to the local music scene. The area's creative class constantly churns out new music. The city overflows with talent, from bands with members not old enough to drink to veterans with decades of music experience in the scene. With that in mind, we present to you 16 promising local bands to watch in 2016. These bands span a range of genres, from noisy punk to electro pop to surf-tinged garage rock, but they all share a common drive to create great music and share it with the world. Don't be surprised to see these bands popping up on lineups at venues around town and filling out the local slots once festival season hits. Give these bands a listen. We don't think you'll be disappointed. http://www.phoenixnewtimes.com/music/16for16theupandcomingmetrophoenixbandstowatchthisyear8001905 1/10 1/28/2016 16 Metro Phoenix Bands to Watch in 2016 | Phoenix New Times Molly and the Molluscs Dani Perez Molly and the Molluscs These band members are having a better time than you. -

Aaron Spectre «Lost Tracks» (Ad Noiseam, 2007) | Reviews На Arrhythmia Sound
2/22/2018 Aaron Spectre «Lost Tracks» (Ad Noiseam, 2007) | Reviews на Arrhythmia Sound Home Content Contacts About Subscribe Gallery Donate Search Interviews Reviews News Podcasts Reports Home » Reviews Aaron Spectre «Lost Tracks» (Ad Noiseam, 2007) Submitted by: Quarck | 19.04.2008 no comment | 198 views Aaron Spectre , also known for the project Drumcorps , reveals before us completely new side of his work. In protovoves frenzy breakgrindcore Specter produces a chic downtempo, idm album. Lost Tracks the result of six years of work, but despite this, the rumor is very fresh and original. The sound is minimalistic without excesses, but at the same time the melodies are very beautiful, the bit powerful and clear, pronounced. Just want to highlight the composition of Break Ya Neck (Remix) , a bit mystical and mysterious, a feeling, like wandering somewhere in the http://www.arrhythmiasound.com/en/review/aaron-spectre-lost-tracks-ad-noiseam-2007.html 1/3 2/22/2018 Aaron Spectre «Lost Tracks» (Ad Noiseam, 2007) | Reviews на Arrhythmia Sound dusk. There was a place and a vocal, in a track Degrees the gentle voice Kazumi (Pink Lilies) sounds. As a result, Lost Tracks can be safely put on a par with the works of such mastadonts as Lusine, Murcof, Hecq. Tags: downtempo, idm Subscribe Email TOP-2013 Submit TOP-2014 TOP-2015 Tags abstract acid ambient ambient-techno artcore best2012 best2013 best2014 best2015 best2016 best2017 breakcore breaks cyberpunk dark ambient downtempo dreampop drone drum&bass dub dubstep dubtechno electro electronic experimental female vocal future garage glitch hip hop idm indie indietronica industrial jazzy krautrock live modern classical noir oldschool post-rock shoegaze space techno tribal trip hop Latest The best in 2017 - albums, places 1-33 12/30/2017 The best in 2017 - albums, places 66-34 12/28/2017 The best in 2017. -

BEACH BOYS Vs BEATLEMANIA: Rediscovering Sixties Music
The final word on the Beach Boys versus Beatles debate, neglect of American acts under the British Invasion, and more controversial critique on your favorite Sixties acts, with a Foreword by Fred Vail, legendary Beach Boys advance man and co-manager. BEACH BOYS vs BEATLEMANIA: Rediscovering Sixties Music Buy The Complete Version of This Book at Booklocker.com: http://www.booklocker.com/p/books/3210.html?s=pdf BEACH BOYS vs Beatlemania: Rediscovering Sixties Music by G A De Forest Copyright © 2007 G A De Forest ISBN-13 978-1-60145-317-4 ISBN-10 1-60145-317-5 All rights reserved. No part of this publication may be reproduced, stored in a retrieval system, or transmitted in any form or by any means, electronic, mechanical, recording or otherwise, without the prior written permission of the author. Printed in the United States of America. Booklocker.com, Inc. 2007 CONTENTS FOREWORD BY FRED VAIL ............................................... XI PREFACE..............................................................................XVII AUTHOR'S NOTE ................................................................ XIX 1. THIS WHOLE WORLD 1 2. CATCHING A WAVE 14 3. TWIST’N’SURF! FOLK’N’SOUL! 98 4: “WE LOVE YOU BEATLES, OH YES WE DO!” 134 5. ENGLAND SWINGS 215 6. SURFIN' US/K 260 7: PET SOUNDS rebounds from RUBBER SOUL — gunned down by REVOLVER 313 8: SGT PEPPERS & THE LOST SMILE 338 9: OLD SURFERS NEVER DIE, THEY JUST FADE AWAY 360 10: IF WE SING IN A VACUUM CAN YOU HEAR US? 378 AFTERWORD .........................................................................405 APPENDIX: BEACH BOYS HIT ALBUMS (1962-1970) ...411 BIBLIOGRAPHY....................................................................419 ix 1. THIS WHOLE WORLD Rock is a fickle mistress. -

Background Music
BACKGROUND MUSIC GET THE BEST MUSIC ALL DAY LONG TouchTunes’ music programmers are passionate about music. They create a variety of fully licensed background music channels for TouchTunes locations to choose from. From Classic Rock and The Hits to Decades Variety and Holiday Mix, TouchTunes jukeboxes are designed to keep the party going all night long while still allowing patrons to make their own song selections. HIGHLIGHTS • Fully licensed for commercial establishments • Over 20 themed music channels to choose from • Each channel features over 30 hours of music • Refreshed monthly with new music • Channels can be changed instantly using the jukebox remote • Can be scheduled for a specific time of the day or all day long LITCMP V.032016 BACKGROUND MUSIC ADULT CONTEMPORARY REGGAE Easy light favorites from the ‘90s to today. Classic jams from Reggae legends. ALTERNATIVE ROCK THE HITS A diverse selection of alternative rock songs. A mix of current and mainstream hits across all genres. BLUES URBAN & HIP HOP A contemporary collection of blues artists. A contemporary mix of urban and hip-hop songs. CLASSIC R&B & SOUL ROCK MIX Sounds from the pioneers of R&B and Soul. The ultimate rock selection featuring timeless rock songs from CLASSIC ROCK the past 30 years. Rock’s biggest bands and timeless hits. DECADES VARIETY COUNTRY MIX Great songs by great artists from the 70’s to today. Mid-tempo mix of country music from the last 30 years. LATIN MIX EASY LISTENING A mix of Latin styles including Regional Mexican, Pop Rock, Lite pop and rock hits from the ‘80s, ‘90s and today. -

Networks of Music Groups As Success Predictors
Networks of Music Groups as Success Predictors Dmitry Zinoviev Mathematics and Computer Science Department Suffolk University Boston, Massachussets 02114 Email: dzinoviev@suffolk.edu Abstract—More than 4,600 non-academic music groups process of penetration of the Western popular music culture emerged in the USSR and post-Soviet independent nations in into the post-Soviet realm but fails to outline the aboriginal 1960–2015, performing in 275 genres. Some of the groups became music landscape. On the other hand, Bright [12] presents an legends and survived for decades, while others vanished and are known now only to select music history scholars. We built a excellent narrative overview of the non-academic music in the network of the groups based on sharing at least one performer. USSR from the early XXth century to the dusk of the Soviet We discovered that major network measures serve as reason- Union—but with no quantitative analysis. Sparse and narrowly ably accurate predictors of the groups’ success. The proposed scoped studies of few performers [13] or aspects [14] only network-based success exploration and prediction methods are make the barren landscape look more barren. transferable to other areas of arts and humanities that have medium- or long-term team-based collaborations. In this paper, we apply modern quantitative analysis meth- Index Terms—Popular music, network analysis, success pre- ods, including statistical analysis, social network analysis, and diction. machine learning, to a collection of 4,600 music groups and bands. We build a network of groups, quantify groups’ success, I. Introduction correlate it with network measures, and attempt to predict Exploring and predicting the success of creative collabo- success, based solely on the network measures. -

“Whiskey in the Jar”: History and Transformation of a Classic Irish Song Masters Thesis Presented in Partial Fulfillment Of
“Whiskey in the Jar”: History and Transformation of a Classic Irish Song Masters Thesis Presented in partial fulfillment of the requirements for the degree of Master of Arts in the Graduate School of The Ohio State University By Dana DeVlieger, B.A., M.A. Graduate Program in Music The Ohio State University 2016 Thesis Committee: Graeme M. Boone, Advisor Johanna Devaney Anna Gawboy Copyright by Dana Lauren DeVlieger 2016 Abstract “Whiskey in the Jar” is a traditional Irish song that is performed by musicians from many different musical genres. However, because there are influential recordings of the song performed in different styles, from folk to punk to metal, one begins to wonder what the role of the song’s Irish heritage is and whether or not it retains a sense of Irish identity in different iterations. The current project examines a corpus of 398 recordings of “Whiskey in the Jar” by artists from all over the world. By analyzing acoustic markers of Irishness, for example an Irish accent, as well as markers of other musical traditions, this study aims explores the different ways that the song has been performed and discusses the possible presence of an “Irish feel” on recordings that do not sound overtly Irish. ii Dedication Dedicated to my grandfather, Edward Blake, for instilling in our family a love of Irish music and a pride in our heritage iii Acknowledgments I would like to thank my advisor, Graeme Boone, for showing great and enthusiasm for this project and for offering advice and support throughout the process. I would also like to thank Johanna Devaney and Anna Gawboy for their valuable insight and ideas for future directions and ways to improve. -

2011 – Cincinnati, OH
Society for American Music Thirty-Seventh Annual Conference International Association for the Study of Popular Music, U.S. Branch Time Keeps On Slipping: Popular Music Histories Hosted by the College-Conservatory of Music University of Cincinnati Hilton Cincinnati Netherland Plaza 9–13 March 2011 Cincinnati, Ohio Mission of the Society for American Music he mission of the Society for American Music Tis to stimulate the appreciation, performance, creation, and study of American musics of all eras and in all their diversity, including the full range of activities and institutions associated with these musics throughout the world. ounded and first named in honor of Oscar Sonneck (1873–1928), early Chief of the Library of Congress Music Division and the F pioneer scholar of American music, the Society for American Music is a constituent member of the American Council of Learned Societies. It is designated as a tax-exempt organization, 501(c)(3), by the Internal Revenue Service. Conferences held each year in the early spring give members the opportunity to share information and ideas, to hear performances, and to enjoy the company of others with similar interests. The Society publishes three periodicals. The Journal of the Society for American Music, a quarterly journal, is published for the Society by Cambridge University Press. Contents are chosen through review by a distinguished editorial advisory board representing the many subjects and professions within the field of American music.The Society for American Music Bulletin is published three times yearly and provides a timely and informal means by which members communicate with each other. The annual Directory provides a list of members, their postal and email addresses, and telephone and fax numbers. -

“Punk Rock Is My Religion”
“Punk Rock Is My Religion” An Exploration of Straight Edge punk as a Surrogate of Religion. Francis Elizabeth Stewart 1622049 Submitted in fulfilment of the doctoral dissertation requirements of the School of Language, Culture and Religion at the University of Stirling. 2011 Supervisors: Dr Andrew Hass Dr Alison Jasper 1 Acknowledgements A debt of acknowledgement is owned to a number of individuals and companies within both of the two fields of study – academia and the hardcore punk and Straight Edge scenes. Supervisory acknowledgement: Dr Andrew Hass, Dr Alison Jasper. In addition staff and others who read chapters, pieces of work and papers, and commented, discussed or made suggestions: Dr Timothy Fitzgerald, Dr Michael Marten, Dr Ward Blanton and Dr Janet Wordley. Financial acknowledgement: Dr William Marshall and the SLCR, The Panacea Society, AHRC, BSA and SOCREL. J & C Wordley, I & K Stewart, J & E Stewart. Research acknowledgement: Emily Buningham @ ‘England’s Dreaming’ archive, Liverpool John Moore University. Philip Leach @ Media archive for central England. AHRC funded ‘Using Moving Archives in Academic Research’ course 2008 – 2009. The 924 Gilman Street Project in Berkeley CA. Interview acknowledgement: Lauren Stewart, Chloe Erdmann, Nathan Cohen, Shane Becker, Philip Johnston, Alan Stewart, N8xxx, and xEricx for all your help in finding willing participants and arranging interviews. A huge acknowledgement of gratitude to all who took part in interviews, giving of their time, ideas and self so willingly, it will not be forgotten. Acknowledgement and thanks are also given to Judy and Loanne for their welcome in a new country, providing me with a home and showing me around the Bay Area.