Formal Specification of the X86 Instruction Set Architecture
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Theendokernel: Fast, Secure
The Endokernel: Fast, Secure, and Programmable Subprocess Virtualization Bumjin Im Fangfei Yang Chia-Che Tsai Michael LeMay Rice University Rice University Texas A&M University Intel Labs Anjo Vahldiek-Oberwagner Nathan Dautenhahn Intel Labs Rice University Abstract Intra-Process Sandbox Multi-Process Commodity applications contain more and more combina- ld/st tions of interacting components (user, application, library, and Process Process Trusted Unsafe system) and exhibit increasingly diverse tradeoffs between iso- Unsafe ld/st lation, performance, and programmability. We argue that the Unsafe challenge of future runtime isolation is best met by embracing syscall()ld/st the multi-principle nature of applications, rethinking process Trusted Trusted read/ architecture for fast and extensible intra-process isolation. We IPC IPC write present, the Endokernel, a new process model and security Operating System architecture that nests an extensible monitor into the standard process for building efficient least-authority abstractions. The Endokernel introduces a new virtual machine abstraction for Figure 1: Problem: intra-process is bypassable because do- representing subprocess authority, which is enforced by an main is opaque to OS, sandbox limits functionality, and inter- efficient self-isolating monitor that maps the abstraction to process is slow and costly to apply. Red indicates limitations. system level objects (processes, threads, files, and signals). We show how the Endokernel Architecture can be used to develop enforces subprocess access control to memory and CPU specialized separation abstractions using an exokernel-like state [10, 17, 24, 25, 75].Unfortunately, these approaches only organization to provide virtual privilege rings, which we use virtualize minimal parts of the CPU and neglect tying their to reorganize and secure NGINX. -

Memory Layout and Access Chapter Four
Memory Layout and Access Chapter Four Chapter One discussed the basic format for data in memory. Chapter Three covered how a computer system physically organizes that data. This chapter discusses how the 80x86 CPUs access data in memory. 4.0 Chapter Overview This chapter forms an important bridge between sections one and two (Machine Organization and Basic Assembly Language, respectively). From the point of view of machine organization, this chapter discusses memory addressing, memory organization, CPU addressing modes, and data representation in memory. From the assembly language programming point of view, this chapter discusses the 80x86 register sets, the 80x86 mem- ory addressing modes, and composite data types. This is a pivotal chapter. If you do not understand the material in this chapter, you will have difficulty understanding the chap- ters that follow. Therefore, you should study this chapter carefully before proceeding. This chapter begins by discussing the registers on the 80x86 processors. These proces- sors provide a set of general purpose registers, segment registers, and some special pur- pose registers. Certain members of the family provide additional registers, although typical application do not use them. After presenting the registers, this chapter describes memory organization and seg- mentation on the 80x86. Segmentation is a difficult concept to many beginning 80x86 assembly language programmers. Indeed, this text tends to avoid using segmented addressing throughout the introductory chapters. Nevertheless, segmentation is a power- ful concept that you must become comfortable with if you intend to write non-trivial 80x86 programs. 80x86 memory addressing modes are, perhaps, the most important topic in this chap- ter. -

Meltdown and Spectre Understanding And
Meltdown and Spectre Prepared by Christopher Clai January 18th, 2018 Understanding and Remediation Strategy Broad Overview The General Law of Cross-Task Information Leakage “In any setting where short-term performance optimizations have global effect, a sufficiently clever task can infer the recent history of other tasks by observing its own performance.” Meltdown and Spectre are two hardware vulnerabilities that target the Central Processing Unit (CPU) of computing systems with cross-task information leakage. They were identified by four separate teams of security researchers who then disclosed the vulnerabilities to the company’s months prior to public disclosure. These vulnerabilities leverage the performance optimization architecture of modern day processors to their advantage. • Meltdown allows an attacker to retrieve kernel memory, which is privileged space in your Operating System that may contain password hashes and private keys for data decryption. • Spectre allows an attacker to retrieve information within the process it operates in, and execute code even if it was isolated in a sandbox within a process. The vulnerabilities require attackers to already have a way into your network, and at most can exfiltrate data from memory. They are unable to cause things such as privilege escalation, holding your data for ransom, or causing business disruption. They data they retrieve however, may be used for that purpose if it contains the information they are seeking. The initial rush of patches and microcode (firmware for CPU) updates have been somewhat brute and simplistic in their methods and only seek to mitigate potential practical exploit paths for these vulnerabilities. Researchers do not believe there will potential to fully prevent these types of exploits. -

Lecture Notes in Assembly Language
Lecture Notes in Assembly Language Short introduction to low-level programming Piotr Fulmański Łódź, 12 czerwca 2015 Spis treści Spis treści iii 1 Before we begin1 1.1 Simple assembler.................................... 1 1.1.1 Excercise 1 ................................... 2 1.1.2 Excercise 2 ................................... 3 1.1.3 Excercise 3 ................................... 3 1.1.4 Excercise 4 ................................... 5 1.1.5 Excercise 5 ................................... 6 1.2 Improvements, part I: addressing........................... 8 1.2.1 Excercise 6 ................................... 11 1.3 Improvements, part II: indirect addressing...................... 11 1.4 Improvements, part III: labels............................. 18 1.4.1 Excercise 7: find substring in a string .................... 19 1.4.2 Excercise 8: improved polynomial....................... 21 1.5 Improvements, part IV: flag register ......................... 23 1.6 Improvements, part V: the stack ........................... 24 1.6.1 Excercise 12................................... 26 1.7 Improvements, part VI – function stack frame.................... 29 1.8 Finall excercises..................................... 34 1.8.1 Excercise 13................................... 34 1.8.2 Excercise 14................................... 34 1.8.3 Excercise 15................................... 34 1.8.4 Excercise 16................................... 34 iii iv SPIS TREŚCI 1.8.5 Excercise 17................................... 34 2 First program 37 2.1 Compiling, -

A Superscalar Out-Of-Order X86 Soft Processor for FPGA
A Superscalar Out-of-Order x86 Soft Processor for FPGA Henry Wong University of Toronto, Intel [email protected] June 5, 2019 Stanford University EE380 1 Hi! ● CPU architect, Intel Hillsboro ● Ph.D., University of Toronto ● Today: x86 OoO processor for FPGA (Ph.D. work) – Motivation – High-level design and results – Microarchitecture details and some circuits 2 FPGA: Field-Programmable Gate Array ● Is a digital circuit (logic gates and wires) ● Is field-programmable (at power-on, not in the fab) ● Pre-fab everything you’ll ever need – 20x area, 20x delay cost – Circuit building blocks are somewhat bigger than logic gates 6-LUT6-LUT 6-LUT6-LUT 3 6-LUT 6-LUT FPGA: Field-Programmable Gate Array ● Is a digital circuit (logic gates and wires) ● Is field-programmable (at power-on, not in the fab) ● Pre-fab everything you’ll ever need – 20x area, 20x delay cost – Circuit building blocks are somewhat bigger than logic gates 6-LUT 6-LUT 6-LUT 6-LUT 4 6-LUT 6-LUT FPGA Soft Processors ● FPGA systems often have software components – Often running on a soft processor ● Need more performance? – Parallel code and hardware accelerators need effort – Less effort if soft processors got faster 5 FPGA Soft Processors ● FPGA systems often have software components – Often running on a soft processor ● Need more performance? – Parallel code and hardware accelerators need effort – Less effort if soft processors got faster 6 FPGA Soft Processors ● FPGA systems often have software components – Often running on a soft processor ● Need more performance? – Parallel -

Extended Memory 64 Technology Software Developer's Manual
IA-32 Intel® Architecture and Intel® Extended Memory 64 Technology Software Developer’s Manual Documentation Changes November 2004 Notice: The IA-32 Intel® Architecture and Intel® Extended Memory 64 Technology may contain design defects or errors known as errata that may cause the product to deviate from published specifications. Current characterized errata are documented in the specification updates. Document Number: 252046-011 INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL® PRODUCTS. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO ANY INTELLECTUAL PROPERTY RIGHTS IS GRANTED BY THIS DOCUMENT. EXCEPT AS PROVIDED IN INTEL'S TERMS AND CONDITIONS OF SALE FOR SUCH PRODUCTS, INTEL ASSUMES NO LIABILITY WHATSOEVER, AND INTEL DISCLAIMS ANY EXPRESS OR IMPLIED WARRANTY, RELATING TO SALE AND/OR USE OF INTEL PRODUCTS INCLUDING LIABILITY OR WARRANTIES RELATING TO FITNESS FOR A PARTICULAR PURPOSE, MERCHANTABILITY, OR INFRINGEMENT OF ANY PATENT, COPYRIGHT OR OTHER INTELLECTUAL PROPERTY RIGHT. Intel products are not intended for use in medical, life saving, or life sustaining applications. Intel may make changes to specifications and product descriptions at any time, without notice. Designers must not rely on the absence or characteristics of any features or instructions marked “reserved” or “undefined.” Intel reserves these for future definition and shall have no responsibility whatsoever for conflicts or incompatibilities arising from future changes to them. The IA-32 Intel® Architecture and Intel® Extended Memory 64 Technology may contain design defects or errors known as errata which may cause the product to deviate from published specifications. Current characterized errata are available on request. Contact your local Intel sales office or your distributor to obtain the latest specifications and before placing your product order. -

SIMD Extensions
SIMD Extensions PDF generated using the open source mwlib toolkit. See http://code.pediapress.com/ for more information. PDF generated at: Sat, 12 May 2012 17:14:46 UTC Contents Articles SIMD 1 MMX (instruction set) 6 3DNow! 8 Streaming SIMD Extensions 12 SSE2 16 SSE3 18 SSSE3 20 SSE4 22 SSE5 26 Advanced Vector Extensions 28 CVT16 instruction set 31 XOP instruction set 31 References Article Sources and Contributors 33 Image Sources, Licenses and Contributors 34 Article Licenses License 35 SIMD 1 SIMD Single instruction Multiple instruction Single data SISD MISD Multiple data SIMD MIMD Single instruction, multiple data (SIMD), is a class of parallel computers in Flynn's taxonomy. It describes computers with multiple processing elements that perform the same operation on multiple data simultaneously. Thus, such machines exploit data level parallelism. History The first use of SIMD instructions was in vector supercomputers of the early 1970s such as the CDC Star-100 and the Texas Instruments ASC, which could operate on a vector of data with a single instruction. Vector processing was especially popularized by Cray in the 1970s and 1980s. Vector-processing architectures are now considered separate from SIMD machines, based on the fact that vector machines processed the vectors one word at a time through pipelined processors (though still based on a single instruction), whereas modern SIMD machines process all elements of the vector simultaneously.[1] The first era of modern SIMD machines was characterized by massively parallel processing-style supercomputers such as the Thinking Machines CM-1 and CM-2. These machines had many limited-functionality processors that would work in parallel. -

SYSCALL, IRET ● Opportunistic SYSRET Failed, Do IRET
entry_*.S A carefree stroll through kernel entry code Borislav Petkov SUSE Labs [email protected] Reasons for entry into the kernel ● System calls (64-bit, compat, 32-bit) ● Interrupts (NMIs, APIC, timer, IPIs... ) – software: INT 0x0-0xFF, INT3, … – external (hw-generated): CPU-ext logic, async to insn exec ● Architectural exceptions (sync vs async) – faults: precise, reported before faulting insn => restartable (#GP,#PF) – traps: precise, reported after trapping insn (#BP,#DB-both) – aborts: imprecise, not reliably restartable (#MC, unless MCG_STATUS.RIPV) 2 Intr/Ex entry ● IDT, int num index into it (256 vectors); all modes need an IDT ● If handler has a higher CPL, switch stacks ● A picture is always better: 3 45sec guide to Segmentation ● Continuous range at an arbitrary position in VA space ● Segments described by segment descriptors ● … selected by segment selectors ● … by indexing into segment descriptor tables (GDT,LDT,IDT,...) ● … and loaded by the hw into segment registers: – user: CS,DS,{E,F,G}S,SS – system: GDTR,LDTR,IDTR,TR (TSS) 4 A couple more seconds of Segmentation ● L (bit 21) new long mode attr: 1=long mode, 0=compat mode ● D (bit 22): default operand and address sizes ● legacy: D=1b – 32bit, D=0b – 16bit ● long mode: D=0b – 32-bit, L=1,D=1 reserved for future use ● G (bit 23): granularity: G=1b: seg limit scaled by 4K ● DPL: Descriptor Privilege Level of the segment 5 Legacy syscalls ● Call OS through gate descriptor (call, intr, trap or task gate) ● Overhead due to segment-based protection: – load new selector + desc into -

Lazy Threads� Compiler and Runtime Structures For
Lazy Threads Compiler and Runtime Structures for FineGrained Parallel Programming by Seth Cop en Goldstein BSE Princeton University MSE University of CaliforniaBerkeley A dissertation submitted in partial satisfaction of the requirements for the degree of Do ctor of Philosophy in Computer Science in the GRADUATE DIVISION of the UNIVERSITY of CALIFORNIA at BERKELEY Committee in charge Professor David E Culler Chair Professor Susan L Graham Professor Paul McEuen Professor Katherine A Yelick Fall Abstract Lazy Threads Compiler and Runtime Structures for FineGrained Parallel Programming by Seth Cop en Goldstein Do ctor of Philosophy in Computer Science University of California Berkeley Professor David E Culler Chair Many mo dern parallel languages supp ort dynamic creation of threads or require multithreading in their implementations The threads describ e the logical parallelism in the program For ease of expression and b etter resource utilization the logical parallelism in a program often exceeds the physical parallelism of the machine and leads to applications with many negrained threads In practice however most logical threads need not b e indep endent threads Instead they could b e run as sequential calls which are inherently cheap er than indep endent threads The challenge is that one cannot generally predict which logical threads can b e implemented as sequential calls In lazy multithreading systems each logical thread b egins execution sequentially with the attendant ecientstack management and direct transfer of control and data -

Towards Scalable Multiprocessor Virtual Machines
USENIX Association Proceedings of the Third Virtual Machine Research and Technology Symposium San Jose, CA, USA May 6–7, 2004 © 2004 by The USENIX Association All Rights Reserved For more information about the USENIX Association: Phone: 1 510 528 8649 FAX: 1 510 548 5738 Email: [email protected] WWW: http://www.usenix.org Rights to individual papers remain with the author or the author's employer. Permission is granted for noncommercial reproduction of the work for educational or research purposes. This copyright notice must be included in the reproduced paper. USENIX acknowledges all trademarks herein. Towards Scalable Multiprocessor Virtual Machines Volkmar Uhlig Joshua LeVasseur Espen Skoglund Uwe Dannowski System Architecture Group Universitat¨ Karlsruhe [email protected] Abstract of guests, such that they only ever access a fraction of the physical processors, or alternatively time-multiplex A multiprocessor virtual machine benefits its guest guests across a set of physical processors to, e.g., ac- operating system in supporting scalable job throughput commodate for spikes in guest OS workloads. It can and request latency—useful properties in server consol- also map guest operating systems to virtual processors idation where servers require several of the system pro- (which can exceed the number of physical processors), cessors for steady state or to handle load bursts. and migrate between physical processors without no- Typical operating systems, optimized for multipro- tifying the guest operating systems. This allows for, cessor systems in their use of spin-locks for critical sec- e.g., migration to other machine configurations or hot- tions, can defeat flexible virtual machine scheduling due swapping of CPUs without adequate support from the to lock-holder preemption and misbalanced load. -

OS Structures and System Calls
COS 318: Operating Systems OS Structures and System Calls Kai Li Computer Science Department Princeton University (http://www.cs.princeton.edu/courses/cos318/) Outline Protection mechanisms OS structures System and library calls 2 Protection Issues CPU Kernel has the ability to take CPU away from users to prevent a user from using the CPU forever Users should not have such an ability Memory Prevent a user from accessing others’ data Prevent users from modifying kernel code and data structures I/O Prevent users from performing “illegal” I/Os Question What’s the difference between protection and security? 3 Architecture Support: Privileged Mode An interrupt or exception (INT) User mode Kernel (privileged) mode • Regular instructions • Regular instructions • Access user memory • Privileged instructions • Access user memory • Access kernel memory A special instruction (IRET) 4 Privileged Instruction Examples Memory address mapping Flush or invalidate data cache Invalidate TLB entries Load and read system registers Change processor modes from kernel to user Change the voltage and frequency of processor Halt a processor Reset a processor Perform I/O operations 5 x86 Protection Rings Privileged instructions Can be executed only When current privileged Level (CPR) is 0 Operating system kernel Level 0 Operating system services Level 1 Level 2 Applications Level 3 6 Layered Structure Hiding information at each layer Layered dependency Examples Level N THE (6 layers) . MS-DOS (4 layers) . Pros Level 2 Layered abstraction -
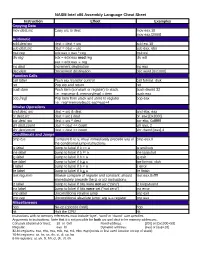
NASM Intel X86 Assembly Language Cheat Sheet
NASM Intel x86 Assembly Language Cheat Sheet Instruction Effect Examples Copying Data mov dest,src Copy src to dest mov eax,10 mov eax,[2000] Arithmetic add dest,src dest = dest + src add esi,10 sub dest,src dest = dest – src sub eax, ebx mul reg edx:eax = eax * reg mul esi div reg edx = edx:eax mod reg div edi eax = edx:eax reg inc dest Increment destination inc eax dec dest Decrement destination dec word [0x1000] Function Calls call label Push eip, transfer control call format_disk ret Pop eip and return ret push item Push item (constant or register) to stack. push dword 32 I.e.: esp=esp-4; memory[esp] = item push eax pop [reg] Pop item from stack and store to register pop eax I.e.: reg=memory[esp]; esp=esp+4 Bitwise Operations and dest, src dest = src & dest and ebx, eax or dest,src dest = src | dest or eax,[0x2000] xor dest, src dest = src ^ dest xor ebx, 0xfffffff shl dest,count dest = dest << count shl eax, 2 shr dest,count dest = dest >> count shr dword [eax],4 Conditionals and Jumps cmp b,a Compare b to a; must immediately precede any of cmp eax,0 the conditional jump instructions je label Jump to label if b == a je endloop jne label Jump to label if b != a jne loopstart jg label Jump to label if b > a jg exit jge label Jump to label if b > a jge format_disk jl label Jump to label if b < a jl error jle label Jump to label if b < a jle finish test reg,imm Bitwise compare of register and constant; should test eax,0xffff immediately precede the jz or jnz instructions jz label Jump to label if bits were not set (“zero”) jz looparound jnz label Jump to label if bits were set (“not zero”) jnz error jmp label Unconditional relative jump jmp exit jmp reg Unconditional absolute jump; arg is a register jmp eax Miscellaneous nop No-op (opcode 0x90) nop hlt Halt the CPU hlt Instructions with no memory references must include ‘byte’, ‘word’ or ‘dword’ size specifier.