Recurrent Neural Networks Deep Learning - Recitation (2/16/2018) Table of Contents
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Backpropagation and Deep Learning in the Brain
Backpropagation and Deep Learning in the Brain Simons Institute -- Computational Theories of the Brain 2018 Timothy Lillicrap DeepMind, UCL With: Sergey Bartunov, Adam Santoro, Jordan Guerguiev, Blake Richards, Luke Marris, Daniel Cownden, Colin Akerman, Douglas Tweed, Geoffrey Hinton The “credit assignment” problem The solution in artificial networks: backprop Credit assignment by backprop works well in practice and shows up in virtually all of the state-of-the-art supervised, unsupervised, and reinforcement learning algorithms. Why Isn’t Backprop “Biologically Plausible”? Why Isn’t Backprop “Biologically Plausible”? Neuroscience Evidence for Backprop in the Brain? A spectrum of credit assignment algorithms: A spectrum of credit assignment algorithms: A spectrum of credit assignment algorithms: How to convince a neuroscientist that the cortex is learning via [something like] backprop - To convince a machine learning researcher, an appeal to variance in gradient estimates might be enough. - But this is rarely enough to convince a neuroscientist. - So what lines of argument help? How to convince a neuroscientist that the cortex is learning via [something like] backprop - What do I mean by “something like backprop”?: - That learning is achieved across multiple layers by sending information from neurons closer to the output back to “earlier” layers to help compute their synaptic updates. How to convince a neuroscientist that the cortex is learning via [something like] backprop 1. Feedback connections in cortex are ubiquitous and modify the -

Chombining Recurrent Neural Networks and Adversarial Training
Combining Recurrent Neural Networks and Adversarial Training for Human Motion Modelling, Synthesis and Control † ‡ Zhiyong Wang∗ Jinxiang Chai Shihong Xia Institute of Computing Texas A&M University Institute of Computing Technology CAS Technology CAS University of Chinese Academy of Sciences ABSTRACT motions from the generator using recurrent neural networks (RNNs) This paper introduces a new generative deep learning network for and refines the generated motion using an adversarial neural network human motion synthesis and control. Our key idea is to combine re- which we call the “refiner network”. Fig 2 gives an overview of current neural networks (RNNs) and adversarial training for human our method: a motion sequence XRNN is generated with the gener- motion modeling. We first describe an efficient method for training ator G and is refined using the refiner network R. To add realism, a RNNs model from prerecorded motion data. We implement recur- we train our refiner network using an adversarial loss, similar to rent neural networks with long short-term memory (LSTM) cells Generative Adversarial Networks (GANs) [9] such that the refined because they are capable of handling nonlinear dynamics and long motion sequences Xre fine are indistinguishable from real motion cap- term temporal dependencies present in human motions. Next, we ture sequences Xreal using a discriminative network D. In addition, train a refiner network using an adversarial loss, similar to Gener- we embed contact information into the generative model to further ative Adversarial Networks (GANs), such that the refined motion improve the quality of the generated motions. sequences are indistinguishable from real motion capture data using We construct the generator G based on recurrent neural network- a discriminative network. -

Training Autoencoders by Alternating Minimization
Under review as a conference paper at ICLR 2018 TRAINING AUTOENCODERS BY ALTERNATING MINI- MIZATION Anonymous authors Paper under double-blind review ABSTRACT We present DANTE, a novel method for training neural networks, in particular autoencoders, using the alternating minimization principle. DANTE provides a distinct perspective in lieu of traditional gradient-based backpropagation techniques commonly used to train deep networks. It utilizes an adaptation of quasi-convex optimization techniques to cast autoencoder training as a bi-quasi-convex optimiza- tion problem. We show that for autoencoder configurations with both differentiable (e.g. sigmoid) and non-differentiable (e.g. ReLU) activation functions, we can perform the alternations very effectively. DANTE effortlessly extends to networks with multiple hidden layers and varying network configurations. In experiments on standard datasets, autoencoders trained using the proposed method were found to be very promising and competitive to traditional backpropagation techniques, both in terms of quality of solution, as well as training speed. 1 INTRODUCTION For much of the recent march of deep learning, gradient-based backpropagation methods, e.g. Stochastic Gradient Descent (SGD) and its variants, have been the mainstay of practitioners. The use of these methods, especially on vast amounts of data, has led to unprecedented progress in several areas of artificial intelligence. On one hand, the intense focus on these techniques has led to an intimate understanding of hardware requirements and code optimizations needed to execute these routines on large datasets in a scalable manner. Today, myriad off-the-shelf and highly optimized packages exist that can churn reasonably large datasets on GPU architectures with relatively mild human involvement and little bootstrap effort. -

Q-Learning in Continuous State and Action Spaces
-Learning in Continuous Q State and Action Spaces Chris Gaskett, David Wettergreen, and Alexander Zelinsky Robotic Systems Laboratory Department of Systems Engineering Research School of Information Sciences and Engineering The Australian National University Canberra, ACT 0200 Australia [cg dsw alex]@syseng.anu.edu.au j j Abstract. -learning can be used to learn a control policy that max- imises a scalarQ reward through interaction with the environment. - learning is commonly applied to problems with discrete states and ac-Q tions. We describe a method suitable for control tasks which require con- tinuous actions, in response to continuous states. The system consists of a neural network coupled with a novel interpolator. Simulation results are presented for a non-holonomic control task. Advantage Learning, a variation of -learning, is shown enhance learning speed and reliability for this task.Q 1 Introduction Reinforcement learning systems learn by trial-and-error which actions are most valuable in which situations (states) [1]. Feedback is provided in the form of a scalar reward signal which may be delayed. The reward signal is defined in relation to the task to be achieved; reward is given when the system is successfully achieving the task. The value is updated incrementally with experience and is defined as a discounted sum of expected future reward. The learning systems choice of actions in response to states is called its policy. Reinforcement learning lies between the extremes of supervised learning, where the policy is taught by an expert, and unsupervised learning, where no feedback is given and the task is to find structure in data. -

Recurrent Neural Network for Text Classification with Multi-Task
Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence (IJCAI-16) Recurrent Neural Network for Text Classification with Multi-Task Learning Pengfei Liu Xipeng Qiu⇤ Xuanjing Huang Shanghai Key Laboratory of Intelligent Information Processing, Fudan University School of Computer Science, Fudan University 825 Zhangheng Road, Shanghai, China pfliu14,xpqiu,xjhuang @fudan.edu.cn { } Abstract are based on unsupervised objectives such as word predic- tion for training [Collobert et al., 2011; Turian et al., 2010; Neural network based methods have obtained great Mikolov et al., 2013]. This unsupervised pre-training is effec- progress on a variety of natural language process- tive to improve the final performance, but it does not directly ing tasks. However, in most previous works, the optimize the desired task. models are learned based on single-task super- vised objectives, which often suffer from insuffi- Multi-task learning utilizes the correlation between related cient training data. In this paper, we use the multi- tasks to improve classification by learning tasks in parallel. [ task learning framework to jointly learn across mul- Motivated by the success of multi-task learning Caruana, ] tiple related tasks. Based on recurrent neural net- 1997 , there are several neural network based NLP models [ ] work, we propose three different mechanisms of Collobert and Weston, 2008; Liu et al., 2015b utilize multi- sharing information to model text with task-specific task learning to jointly learn several tasks with the aim of and shared layers. The entire network is trained mutual benefit. The basic multi-task architectures of these jointly on all these tasks. Experiments on four models are to share some lower layers to determine common benchmark text classification tasks show that our features. -

Double Backpropagation for Training Autoencoders Against Adversarial Attack
1 Double Backpropagation for Training Autoencoders against Adversarial Attack Chengjin Sun, Sizhe Chen, and Xiaolin Huang, Senior Member, IEEE Abstract—Deep learning, as widely known, is vulnerable to adversarial samples. This paper focuses on the adversarial attack on autoencoders. Safety of the autoencoders (AEs) is important because they are widely used as a compression scheme for data storage and transmission, however, the current autoencoders are easily attacked, i.e., one can slightly modify an input but has totally different codes. The vulnerability is rooted the sensitivity of the autoencoders and to enhance the robustness, we propose to adopt double backpropagation (DBP) to secure autoencoder such as VAE and DRAW. We restrict the gradient from the reconstruction image to the original one so that the autoencoder is not sensitive to trivial perturbation produced by the adversarial attack. After smoothing the gradient by DBP, we further smooth the label by Gaussian Mixture Model (GMM), aiming for accurate and robust classification. We demonstrate in MNIST, CelebA, SVHN that our method leads to a robust autoencoder resistant to attack and a robust classifier able for image transition and immune to adversarial attack if combined with GMM. Index Terms—double backpropagation, autoencoder, network robustness, GMM. F 1 INTRODUCTION N the past few years, deep neural networks have been feature [9], [10], [11], [12], [13], or network structure [3], [14], I greatly developed and successfully used in a vast of fields, [15]. such as pattern recognition, intelligent robots, automatic Adversarial attack and its defense are revolving around a control, medicine [1]. Despite the great success, researchers small ∆x and a big resulting difference between f(x + ∆x) have found the vulnerability of deep neural networks to and f(x). -

An Overview of Deep Learning Strategies for Time Series Prediction
An Overview of Deep Learning Strategies for Time Series Prediction Rodrigo Neves Instituto Superior Tecnico,´ Lisboa, Portugal [email protected] June 2018 Abstract—Deep learning is getting a lot of attention in the last Jenkins methodology [2] and were developed mainly in the few years, mainly due to the state-of-the-art results obtained in area of econometrics and statistics. different areas like object detection, natural language processing, Driven by the rise of popularity and attention in the area sequential modeling, among many others. Time series problems are a special case of sequential data, where deep learning models of deep learning, due to the state-of-the-art results obtained can be applied. The standard option to this type of problems in several areas, Artificial Neural Networks (ANN), which are are Recurrent Neural Networks (RNNs), but recent results are non-linear function approximator, have also been receiving an supporting the idea that Convolutional Neural Networks (CNNs) increasing attention in time series field. This rise of popularity can also be applied to time series with good results. This raises is associated with the breakthroughs achieved in this area, with the following question - Which are the best attributes and architectures to apply in time series prediction problems? It was the successful application of CNNs and RNNs to sequential assessed which is the current state on deep learning applied to modeling problems, with promising results [3]. RNNs are a time-series and studied which are the most promising topologies type of artificial neural networks that were specially designed and characteristics on sequential tasks that are worth it to to deal with sequential tasks, and thus can be used on time be explored. -

Deep Learning Architectures for Sequence Processing
Speech and Language Processing. Daniel Jurafsky & James H. Martin. Copyright © 2021. All rights reserved. Draft of September 21, 2021. CHAPTER Deep Learning Architectures 9 for Sequence Processing Time will explain. Jane Austen, Persuasion Language is an inherently temporal phenomenon. Spoken language is a sequence of acoustic events over time, and we comprehend and produce both spoken and written language as a continuous input stream. The temporal nature of language is reflected in the metaphors we use; we talk of the flow of conversations, news feeds, and twitter streams, all of which emphasize that language is a sequence that unfolds in time. This temporal nature is reflected in some of the algorithms we use to process lan- guage. For example, the Viterbi algorithm applied to HMM part-of-speech tagging, proceeds through the input a word at a time, carrying forward information gleaned along the way. Yet other machine learning approaches, like those we’ve studied for sentiment analysis or other text classification tasks don’t have this temporal nature – they assume simultaneous access to all aspects of their input. The feedforward networks of Chapter 7 also assumed simultaneous access, al- though they also had a simple model for time. Recall that we applied feedforward networks to language modeling by having them look only at a fixed-size window of words, and then sliding this window over the input, making independent predictions along the way. Fig. 9.1, reproduced from Chapter 7, shows a neural language model with window size 3 predicting what word follows the input for all the. Subsequent words are predicted by sliding the window forward a word at a time. -

Unsupervised Speech Representation Learning Using Wavenet Autoencoders Jan Chorowski, Ron J
1 Unsupervised speech representation learning using WaveNet autoencoders Jan Chorowski, Ron J. Weiss, Samy Bengio, Aaron¨ van den Oord Abstract—We consider the task of unsupervised extraction speaker gender and identity, from phonetic content, properties of meaningful latent representations of speech by applying which are consistent with internal representations learned autoencoding neural networks to speech waveforms. The goal by speech recognizers [13], [14]. Such representations are is to learn a representation able to capture high level semantic content from the signal, e.g. phoneme identities, while being desired in several tasks, such as low resource automatic speech invariant to confounding low level details in the signal such as recognition (ASR), where only a small amount of labeled the underlying pitch contour or background noise. Since the training data is available. In such scenario, limited amounts learned representation is tuned to contain only phonetic content, of data may be sufficient to learn an acoustic model on the we resort to using a high capacity WaveNet decoder to infer representation discovered without supervision, but insufficient information discarded by the encoder from previous samples. Moreover, the behavior of autoencoder models depends on the to learn the acoustic model and a data representation in a fully kind of constraint that is applied to the latent representation. supervised manner [15], [16]. We compare three variants: a simple dimensionality reduction We focus on representations learned with autoencoders bottleneck, a Gaussian Variational Autoencoder (VAE), and a applied to raw waveforms and spectrogram features and discrete Vector Quantized VAE (VQ-VAE). We analyze the quality investigate the quality of learned representations on LibriSpeech of learned representations in terms of speaker independence, the ability to predict phonetic content, and the ability to accurately re- [17]. -
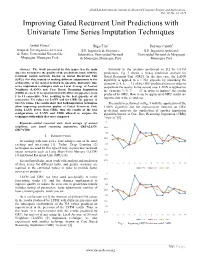
Improving Gated Recurrent Unit Predictions with Univariate Time Series Imputation Techniques
(IJACSA) International Journal of Advanced Computer Science and Applications, Vol. 10, No. 12, 2019 Improving Gated Recurrent Unit Predictions with Univariate Time Series Imputation Techniques 1 Anibal Flores Hugo Tito2 Deymor Centty3 Grupo de Investigación en Ciencia E.P. Ingeniería de Sistemas e E.P. Ingeniería Ambiental de Datos, Universidad Nacional de Informática, Universidad Nacional Universidad Nacional de Moquegua Moquegua, Moquegua, Perú de Moquegua, Moquegua, Perú Moquegua, Perú Abstract—The work presented in this paper has its main Similarly to the analysis performed in [1] for LSTM objective to improve the quality of the predictions made with the predictions, Fig. 1 shows a 14-day prediction analysis for recurrent neural network known as Gated Recurrent Unit Gated Recurrent Unit (GRU). In the first case, the LANN (GRU). For this, instead of making different adjustments to the algorithm is applied to a 1 NA gap-size by rebuilding the architecture of the neural network in question, univariate time elements 2, 4, 6, …, 12 of the GRU-predicted series in order to series imputation techniques such as Local Average of Nearest outperform the results. In the second case, LANN is applied for Neighbors (LANN) and Case Based Reasoning Imputation the elements 3, 5, 7, …, 13 in order to improve the results (CBRi) are used. It is experimented with different gap-sizes, from produced by GRU. How it can be appreciated GRU results are 1 to 11 consecutive NAs, resulting in the best gap-size of six improve just in the second case. consecutive NA values for LANN and for CBRi the gap-size of two NA values. -

Approaching Hanabi with Q-Learning and Evolutionary Algorithm
St. Cloud State University theRepository at St. Cloud State Culminating Projects in Computer Science and Department of Computer Science and Information Technology Information Technology 12-2020 Approaching Hanabi with Q-Learning and Evolutionary Algorithm Joseph Palmersten [email protected] Follow this and additional works at: https://repository.stcloudstate.edu/csit_etds Part of the Computer Sciences Commons Recommended Citation Palmersten, Joseph, "Approaching Hanabi with Q-Learning and Evolutionary Algorithm" (2020). Culminating Projects in Computer Science and Information Technology. 34. https://repository.stcloudstate.edu/csit_etds/34 This Starred Paper is brought to you for free and open access by the Department of Computer Science and Information Technology at theRepository at St. Cloud State. It has been accepted for inclusion in Culminating Projects in Computer Science and Information Technology by an authorized administrator of theRepository at St. Cloud State. For more information, please contact [email protected]. Approaching Hanabi with Q-Learning and Evolutionary Algorithm by Joseph A Palmersten A Starred Paper Submitted to the Graduate Faculty of St. Cloud State University In Partial Fulfillment of the Requirements for the Degree of Master of Science in Computer Science December, 2020 Starred Paper Committee: Bryant Julstrom, Chairperson Donald Hamnes Jie Meichsner 2 Abstract Hanabi is a cooperative card game with hidden information that requires cooperation and communication between the players. For a machine learning agent to be successful at the Hanabi, it will have to learn how to communicate and infer information from the communication of other players. To approach the problem of Hanabi the machine learning methods of Q- learning and Evolutionary algorithm are proposed as potential solutions. -

Linear Prediction-Based Wavenet Speech Synthesis
LP-WaveNet: Linear Prediction-based WaveNet Speech Synthesis Min-Jae Hwang Frank Soong Eunwoo Song Search Solution Microsoft Naver Corporation Seongnam, South Korea Beijing, China Seongnam, South Korea [email protected] [email protected] [email protected] Xi Wang Hyeonjoo Kang Hong-Goo Kang Microsoft Yonsei University Yonsei University Beijing, China Seoul, South Korea Seoul, South Korea [email protected] [email protected] [email protected] Abstract—We propose a linear prediction (LP)-based wave- than the speech signal, the training and generation processes form generation method via WaveNet vocoding framework. A become more efficient. WaveNet-based neural vocoder has significantly improved the However, the synthesized speech is likely to be unnatural quality of parametric text-to-speech (TTS) systems. However, it is challenging to effectively train the neural vocoder when the target when the prediction errors in estimating the excitation are database contains massive amount of acoustical information propagated through the LP synthesis process. As the effect such as prosody, style or expressiveness. As a solution, the of LP synthesis is not considered in the training process, the approaches that only generate the vocal source component by synthesis output is vulnerable to the variation of LP synthesis a neural vocoder have been proposed. However, they tend to filter. generate synthetic noise because the vocal source component is independently handled without considering the entire speech To alleviate this problem, we propose an LP-WaveNet, production process; where it is inevitable to come up with a which enables to jointly train the complicated interactions mismatch between vocal source and vocal tract filter.