Peter J. Cobb. Collaborative Online Bibliography for Archaeology. a Master's Paper for the M.S. in I.S Degree. July, 2008. 39
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Comparison of Researcher's Reference Management Software
Journal of Economics and Behavioral Studies Vol. 6, No. 7, pp. 561-568, July 2014 (ISSN: 2220-6140) A Comparison of Researcher’s Reference Management Software: Refworks, Mendeley, and EndNote Sujit Kumar Basak Durban University of Technology, South Africa [email protected] Abstract: This paper aimed to present a comparison of researcher’s reference management software such as RefWorks, Mendeley, and EndNote. This aim was achieved by comparing three software. The main results of this paper were concluded by comparing three software based on the experiment. The novelty of this paper is the comparison of researcher’s reference management software and it has showed that Mendeley reference management software can import more data from the Google Scholar for researchers. This finding could help to know researchers to use the reference management software. Keywords: Reference management software, comparison and researchers 1. Introduction Reference management software maintains a database to references and creates bibliographies and the reference lists for the written works. It makes easy to read and to record the elements for the reference comprises such as the author’s name, year of publication, and the title of an article, etc. (Reiss & Reiss, 2002). Reference Management Software is usually used by researchers, technologists, scientists, and authors, etc. to keep their records and utilize the bibliographic citations; hence it is one of the most complicated aspects among researchers. Formatting references as a matter of fact depends on a variety of citation styles which have been made the citation manager very essential for researchers at all levels (Gilmour & Cobus-Kuo, 2011). Reference management software is popularly known as bibliographic software, citation management software or personal bibliographic file managers (Nashelsky & Earley, 1991). -

Studies and Analysis of Reference Management Software: a Literature Review
Studies and analysis of reference management software: a literature review Jesús Tramullas Ana Sánchez-Casabón {jesus,asanchez}@unizar.es Dept .of Library & Information Science, University of Zaragoza Piedad Garrido-Picazo [email protected] Dept. of Computer and Software Engineering, University of Zaragoza Abstract: Reference management software is a well-known tool for scientific research work. Since the 1980s, it has been the subject of reviews and evaluations in library and information science literature. This paper presents a systematic review of published studies that evaluate reference management software with a comparative approach. The objective is to identify the types, models, and evaluation criteria that authors have adopted, in order to determine whether the methods used provide adequate methodological rigor and useful contributions to the field of study. Keywords: reference management software, evaluation methods, bibliography. 1. Introduction and background Reference management software has been a useful tool for researchers since the 1980s. In those early years, tools were made ad-hoc, and some were based on the dBase II/III database management system (Bertrand and Bader, 1980; Kunin, 1985). In a short period of time a market was created and commercial products were developed to provide support to this type of information resources. The need of researchers to systematize scientific literature in both group and personal contexts, and to integrate mechanisms into scientific production environments in order to facilitate and expedite the process of writing and publishing research results, requires that these types of applications receive almost constant attention in specialized library and information science literature. The result of this interest is reflected, in bibliographical terms, in the publication of numerous articles almost exclusively devoted to describing, analyzing, and comparing the characteristics of several reference management software products (Norman, 2010). -

Studying Social Tagging and Folksonomy: a Review and Framework
Studying Social Tagging and Folksonomy: A Review and Framework Item Type Journal Article (On-line/Unpaginated) Authors Trant, Jennifer Citation Studying Social Tagging and Folksonomy: A Review and Framework 2009-01, 10(1) Journal of Digital Information Journal Journal of Digital Information Download date 02/10/2021 03:25:18 Link to Item http://hdl.handle.net/10150/105375 Trant, Jennifer (2009) Studying Social Tagging and Folksonomy: A Review and Framework. Journal of Digital Information 10(1). Studying Social Tagging and Folksonomy: A Review and Framework J. Trant, University of Toronto / Archives & Museum Informatics 158 Lee Ave, Toronto, ON Canada M4E 2P3 jtrant [at] archimuse.com Abstract This paper reviews research into social tagging and folksonomy (as reflected in about 180 sources published through December 2007). Methods of researching the contribution of social tagging and folksonomy are described, and outstanding research questions are presented. This is a new area of research, where theoretical perspectives and relevant research methods are only now being defined. This paper provides a framework for the study of folksonomy, tagging and social tagging systems. Three broad approaches are identified, focusing first, on the folksonomy itself (and the role of tags in indexing and retrieval); secondly, on tagging (and the behaviour of users); and thirdly, on the nature of social tagging systems (as socio-technical frameworks). Keywords: Social tagging, folksonomy, tagging, literature review, research review 1. Introduction User-generated keywords – tags – have been suggested as a lightweight way of enhancing descriptions of on-line information resources, and improving their access through broader indexing. “Social Tagging” refers to the practice of publicly labeling or categorizing resources in a shared, on-line environment. -
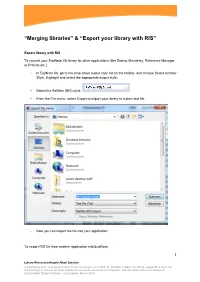
“Merging Libraries” & “Export Your Library with RIS”
“Merging libraries” & “Export your library with RIS” Export library with RIS To convert your EndNote X6 library for other applications (like Zotero, Mendeley, Reference Manager or ProCite etc.): - In EndNote X6, go to the drop-down output style list on the toolbar, and choose Select Another Style. Highlight and select the appropriate output style: - Select the RefMan (RIS) style. - From the File menu, select Export to export your library to a plain text file. - Now you can import the file into your application To import RIS file from another application into EndNote: 1 Library Wissenschaftspark Albert Einstein A joint library of the German Research Centre for Geosciences GFZ, the Potsdam Institute for Climate Impact Research, the Alfred Wegener Institute for Polar and Marine Research, Research Unit Potsdam, and the IASS Institute for Advanced Sustainability Studies Potsdam (Last update: March 2013) - Got to “File” and “Import” - Choose your file in RIS format - Use the RIS import option. - Set your preferences - Import the references 2 Library Wissenschaftspark Albert Einstein A joint library of the German Research Centre for Geosciences GFZ, the Potsdam Institute for Climate Impact Research, the Alfred Wegener Institute for Polar and Marine Research, Research Unit Potsdam, and the IASS Institute for Advanced Sustainability Studies Potsdam (Last update: March 2013) Merging libraries There are three ways to merge libraries: import one library into another, copy references from one library to another, or drag-and-drop. - (Optional) If you want to import only a subset of references from a library, first open that library and show only the references you wish to copy. -

What Makes a Good Reference Manager? A
1 What Makes A Good Reference Manager? 2 Quantitative Analysis of Bibliography Management Applications 3 4 5 ∗ 6 ANONYMOUS AUTHOR(S) 7 Reference managers have been widely used by researchers and students. While previous performed qualitative analysis for reference 8 managers, it is unclear how to asses these tools quantitatively. In this paper, we attempted to quantify the physical and mental effort to 9 10 use a reference manager. Specifically, we use a keystroke and mouse move logger, RUI, to record and analyze the user’s activities and 11 approximate the physical and mental effort. We also use pre- and post-study surveys to keep track of the participant’s preferences and 12 experiences with reference managers, and also their self-reported task load (NASA TLX Index.) In this pilot work, we first collected 69 13 pre-study surveys from graduate students to understand their experience with reference managers, and then conducted user study 14 with 12 voluntary participants. Four common reference managers, Mendeley, Zotero, EndNote, and RefWorks, were included in our 15 study. The results show, for the same task, different software might require different levels of effort, and users generally preferthe 16 tools that require less effort. We also observe that although these reference managers share similar features, the differences intheir 17 18 presentation and organization matter. Factors such as pricing, cloud sync and accuracy of bibliography generation also influence the 19 preference of users. We conclude this work by providing a set of guidelines for users and developers. 20 CCS Concepts: • Human-centered computing ! Usability testing; Activity centered design. -

Getting Started with Vetsrev
Getting started with VetSRev Authors: Douglas Grindlay, Rachel Dean & Marnie Brennan, 21 August 2013 VetSRev (www.nottingham.ac.uk/cevm/vetsrev) is a database of veterinary systematic reviews. VetSrev is produced using Refbase, an open source database for managing scientific literature & citations. This introductory guide, Getting started with VetSRev, provides a brief overview of the functions of the database to help new users. For more information about VetSRev, please see About VetSRev. Detailed instructions for using Refbase (not specific to VetSRev) can be found in the online Refbase documentation—see in particular the section on “Usage”: http://www.refbase.net/index.php/Documentation If you have any queries about using VetSRev that are not answered by this guide, please contact us at [email protected]. Contents: Page 1. The VetSRev Home Page 2 2. How do I view all the records in the database? 3 3. How do I do a quick search? 3 4. How do I view records in the results display? 4 5. How do I change the results display to a different view? 5 6. How do I view the original publication for a citation? 5 7. How do I view an individual record for a citation? 6 8. How does the database perform a search? 7 9. How do I search for citations on a specific animal species? 7 10. How do I search for citations on a specific topic? 7 11. What does the Simple Search do? 8 12. How do I use the Advanced Search? 8 13. How do I combine search terms? 9 14. -

Mendeley Reader Counts for US Computer Science Conference
1 Mendeley Reader Counts for US Computer Science Conference Papers and Journal articles1 Mike Thelwall, Statistical Cybermetrics Research Group, University of Wolverhampton, UK. Although bibliometrics are normally applied to journal articles when used to support research evaluations, conference papers are at least as important in fast-moving computing- related fields. It is therefore important to assess the relative advantages of citations and altmetrics for computing conference papers to make an informed decision about which, if any, to use. This paper compares Scopus citations with Mendeley reader counts for conference papers and journal articles that were published between 1996 and 2018 in 11 computing fields and had at least one US author. The data showed high correlations between Scopus citation counts and Mendeley reader counts in all fields and most years, but with few Mendeley readers for older conference papers and few Scopus citations for new conference papers and journal articles. The results therefore suggest that Mendeley reader counts have a substantial advantage over citation counts for recently-published conference papers due to their greater speed, but are unsuitable for older conference papers. Keywords: Altmetrics; Mendeley; Scientometrics; Computer Science; Computing; Conference papers 1 Introduction Altmetrics, social media indicators for the impact of academic research derived from the web (Priem, Taraborelli, Groth, & Neylon, 2010), are now widely available to help assess academic outputs. Altmetric.com, for example, collects a range of data about online mentions of academic documents, supplying it to journal publishers to display in article pages, to institutions to help them analyse their work and to researchers to track the impact of their publications (Adie & Roe, 2013; Liu & Adie, 2013). -

Aigaion: a Web-Based Open Source Software for Managing the Bibliographic References
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by E-LIS repository Aigaion: A Web-based Open Source Software for Managing the Bibliographic References Sanjo Jose ([email protected]) Francis Jayakanth ([email protected]) National Centre for Science Information, Indian Institute of Science, Bangalore – 560 012 Abstract Publishing research papers is an integral part of a researcher's professional life. Every research article will invariably provide large number of citations/bibliographic references of the papers that are being cited in that article. All such citations are to be rendered in the citation style specified by a publisher and they should be accurate. Researchers, over a period of time, accumulate a large number of bibliographic references that are relevant to their research and cite relevant references in their own publications. Efficient management of bibliographic references is therefore an important task for every researcher and it will save considerable amount of researchers' time in locating the required citations and in the correct rendering of citation details. In this paper, we are reporting the features of Aigaion, a web-based, open-source software for reference management. 1. Introduction A citation or bibliographic citation is a reference to a book, article, web page, or any other published item. The reference will contain adequate details to facilitate the readers to locate the publication. Different citation systems and styles are being used in different disciplines like science, social science, humanities, etc. Referencing is also a standardised method of acknowledging the original source of information or idea. -

Exportación a Otros Pgb
EXPORTACIÓN A OTROS PGB CÓMO EXPORTAR DE ZOTERO A ENDNOTE En Zotero una colección concreta -> botón derecho del ratón , exportar y guardar en formato RIS o Refer/BibIX En EndNote: File -> Import -> Reference Manager (RIS) o Refer/BibIX ENDNOTEWEB En Zotero guardar como .RIS En EndNoteweb importar con el filtro RefMan (RIS) PROCITE En Zotero guardar en formato RIS En Procite, Tools -> Import Text file -> Open Import file -> Nombre: Mi biblioteca.ris. Tipo ->All files REFERENCE MANAGER En Zotero guardar Mi biblioteca como .ris En Reference Manager- en File New Database u Open Database -> En File -> Import Text file->el que queremos “Mi biblioteca.ris”->Filter RIS REFWORK En Zotero guardar como .ris En RefWorks-> Importar-> Filtro RIS UTF-8 CÓMO EXPORTAR DE ENDNOTE A ZOTERO En EndNote -> File -> Export -> My EndNote Library -> en .txt. Output Style - > RefMan (RIS) En Zotero -> importar -> Tipo RIS ENDNOTEWEB En EndNote -> Tools-> Connect EndNote Web PROCITE En Procite Tools -> Convert file->elegir el archivo de EndNote y guardar con otro nombre REFERENCE MANAGER En EndNote File Export filtro refinan (RIS) export, como archivo .txt En Reference Manager, File Import Text file REFWORK De EndNote v.8 o superior exportación directa. Si falla en otras versiones ver Ayuda de RefWorks CÓMO EXPORTAR DE ENDNOTEWEB A ENDNOTE ZOTERO PROCITE REFERENCE MANAGER REFWORK Elegir exportar como RIS y seleccionar esta opción al importar a los progrmas CÓMO EXPORTAR DE PROCITE A ENDNOTE En Procite guardar cualquier archivo en Procite. En EndNote File -> Open library elegir el archivo de Procite-> File of type -> Procite ZOTERO En Procite, si no tenemos el filtro EndNote-RIS importarlo de www.procite.com . -

Module Five - Management of Information
Module Five - Management of Information Introduction “Where did I read this information?”, “I know that I printed a copy of this article, but I don't remember where I kept it.” These are very common situations among researchers, students or anybody whose works involve using documents. In the course of learning, teaching and research, information accessed from diverse sources accumulates. Without a proper information management practice; such information may be difficult to find and later locate. In certain instance some people may print the same documents again and again, or search for the same information every time they need it. As a consequence there is a need for this information to be organized so that it becomes easily accessible. Managing this information properly will save time, energy and lead to increased productivity. This module discusses tools and techniques for collecting, storing, organizing and using information. Special attention will be given to the management of the following categories of information: bibliographic references, primary documents such as books or articles, user’s notes and manuscripts. Learning Objectives In this module we will: • Explain the benefits of good organization of information, • Present referenced management tools, • present bookmark management tools, • Discuss information management techniques. Learning Outcomes At the end of the module, one should be able to: • Understand the importance of managing information, • Use a reference management software for storing bibliographic references, • -

Convert Ris To
Convert ris to Continue This website uses its own and third-party cookies to develop statistical information, to personalize your experience, and to view user ads through viewing analysis, sharing it with our partners. Using Online-Convert, you agree to use cookies. RefWorks has a feature that allows you to download the EndNote library for versions 8 to 10 directly to RefWorks. For all other versions, export records from EndNote and import them to RefWorks (see instructions at the end of this section). Go to RefWorks and from the Links menu select Imports. Expand the From EndNote database section. Browse and select EndNote (.enl). Only the EndNote 8 version and the higher databases can be imported. There is a 25MB import limit the size of your EndNote library. Make sure the .enl file isn't open on your computer. Additionally, specify the folder you want to import your records into. Click Import at the bottom of the import window. Progress is measured for each imported handbook. RefWorks will notify you when the import is complete. Your entries should automatically appear in the Last Import folder. It is recommended that you import no more than 2,500 records (or 3MB files) at a time. In EndNote, under the Edit menu, choose weekend styles. From the release style list, select RefMan (RIS) Export. If you can't see this format, open Style Manager and check the RefMan (RIS) export format. Close the style manager and repeat the steps 1 and 2. Choose the links you want to export. In the Help menu, select Show Selected (or show everything if you want to export the entire database). -

Research Methodology Series
Research Methodology Series Referencing Made Easy: Reference Management Softwares ROMIT SAXENA,1 JAYA SHANKAR KAUSHIK2 From Departments of Pediatrics, 1Maulana Azad Medical College, New Delhi; 2Post Graduate Institute of Medical Sciences, Rohtak, Haryana. Correspondence to: Dr Romit Saxena, Department of Pediatrics, Maulana Azad Medical College, Bahadur Shah Zafar Marg, New Delhi. [email protected] PII: S097475591600363 Note: This early-online version of the article is an unedited manuscript that has been accepted for publication. It has been posted to the website for making it available to readers, ahead of its publication in print. This version will undergo copy-editing, typesetting, and proofreading, before final publication; and the text may undergo minor changes in the final version. INDIAN PEDIATRICS 1 SEPTEMBER 04, 2021 [E-PUB AHEAD OF PRINT] ROMIT SAXENA AND JAYA SHANKAR KAUSHIK REFERENCE MANAGEMENT SOFTWARES ABSTRACT Reference management softwares are a powerful tool in the researchers’ armamentarium. They primarily help in resequencing, re-styling and reformatting of the citation content in the research manuscripts. They also enable multi-user collaboration on research and allow the researcher to manage database searches and digital libraries. Using these softwares allows synchronization of cloud based digital libraries on multiple electronic devices enabling remote access, and also allows for management of online portfolios. We, herein, describe the basic principles, functions, and limitations of various reference management sofares. Keywords: Bibliography, Citation, Metadata, Research. Researchers often use existing medical literature as books, journal articles, monographs and internet sites, as a base for new research articles. The researcher duly acknowledges and gives credit to the previous researcher for their contribution by citing the referenced literature sources at the end of one’s article.