Abusing Performance Counters on the Arm and X86 Architectures
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Binary Counter
Systems I: Computer Organization and Architecture Lecture 8: Registers and Counters Registers • A register is a group of flip-flops. – Each flip-flop stores one bit of data; n flip-flops are required to store n bits of data. – There are several different types of registers available commercially. – The simplest design is a register consisting only of flip- flops, with no other gates in the circuit. • Loading the register – transfer of new data into the register. • The flip-flops share a common clock pulse (frequently using a buffer to reduce power requirements). • Output could be sampled at any time. • Clearing the flip-flop (placing zeroes in all its bit) can be done through a special terminal on the flip-flop. 1 4-bit Register I0 D Q A0 Clock C I1 D Q A1 C I D Q 2 A2 C D Q A I3 3 C Clear Registers With Parallel Load • The clock usually provides a steady stream of pulses which are applied to all flip-flops in the system. • A separate control system is needed to determine when to load a particular register. • The Register with Parallel Load has a separate load input. – When it is cleared, the register receives it output as input. – When it is set, it received the load input. 2 4-bit Register With Parallel Load Load D Q A0 I0 C D Q A1 C I1 D Q A2 I2 C D Q A3 I3 C Clock Shift Registers • A shift register is a register which can shift its data in one or both directions. -

GPU Developments 2018
GPU Developments 2018 2018 GPU Developments 2018 © Copyright Jon Peddie Research 2019. All rights reserved. Reproduction in whole or in part is prohibited without written permission from Jon Peddie Research. This report is the property of Jon Peddie Research (JPR) and made available to a restricted number of clients only upon these terms and conditions. Agreement not to copy or disclose. This report and all future reports or other materials provided by JPR pursuant to this subscription (collectively, “Reports”) are protected by: (i) federal copyright, pursuant to the Copyright Act of 1976; and (ii) the nondisclosure provisions set forth immediately following. License, exclusive use, and agreement not to disclose. Reports are the trade secret property exclusively of JPR and are made available to a restricted number of clients, for their exclusive use and only upon the following terms and conditions. JPR grants site-wide license to read and utilize the information in the Reports, exclusively to the initial subscriber to the Reports, its subsidiaries, divisions, and employees (collectively, “Subscriber”). The Reports shall, at all times, be treated by Subscriber as proprietary and confidential documents, for internal use only. Subscriber agrees that it will not reproduce for or share any of the material in the Reports (“Material”) with any entity or individual other than Subscriber (“Shared Third Party”) (collectively, “Share” or “Sharing”), without the advance written permission of JPR. Subscriber shall be liable for any breach of this agreement and shall be subject to cancellation of its subscription to Reports. Without limiting this liability, Subscriber shall be liable for any damages suffered by JPR as a result of any Sharing of any Material, without advance written permission of JPR. -

An Emerging Architecture in Smart Phones
International Journal of Electronic Engineering and Computer Science Vol. 3, No. 2, 2018, pp. 29-38 http://www.aiscience.org/journal/ijeecs ARM Processor Architecture: An Emerging Architecture in Smart Phones Naseer Ahmad, Muhammad Waqas Boota * Department of Computer Science, Virtual University of Pakistan, Lahore, Pakistan Abstract ARM is a 32-bit RISC processor architecture. It is develop and licenses by British company ARM holdings. ARM holding does not manufacture and sell the CPU devices. ARM holding only licenses the processor architecture to interested parties. There are two main types of licences implementation licenses and architecture licenses. ARM processors have a unique combination of feature such as ARM core is very simple as compare to general purpose processors. ARM chip has several peripheral controller, a digital signal processor and ARM core. ARM processor consumes less power but provide the high performance. Now a day, ARM Cortex series is very popular in Smartphone devices. We will also see the important characteristics of cortex series. We discuss the ARM processor and system on a chip (SOC) which includes the Qualcomm, Snapdragon, nVidia Tegra, and Apple system on chips. In this paper, we discuss the features of ARM processor and Intel atom processor and see which processor is best. Finally, we will discuss the future of ARM processor in Smartphone devices. Keywords RISC, ISA, ARM Core, System on a Chip (SoC) Received: May 6, 2018 / Accepted: June 15, 2018 / Published online: July 26, 2018 @ 2018 The Authors. Published by American Institute of Science. This Open Access article is under the CC BY license. -

Cross Architectural Power Modelling
Cross Architectural Power Modelling Kai Chen1, Peter Kilpatrick1, Dimitrios S. Nikolopoulos2, and Blesson Varghese1 1Queen’s University Belfast, UK; 2Virginia Tech, USA E-mail: [email protected]; [email protected]; [email protected]; [email protected] Abstract—Existing power modelling research focuses on the processor are extensively explored using a cumbersome trial model rather than the process for developing models. An auto- and error approach after which a suitable few are selected [7]. mated power modelling process that can be deployed on different Such an approach does not easily scale for various processor processors for developing power models with high accuracy is developed. For this, (i) an automated hardware performance architectures since a different set of hardware counters will be counter selection method that selects counters best correlated to required to model power for each processor. power on both ARM and Intel processors, (ii) a noise filter based Currently, there is little research that develops automated on clustering that can reduce the mean error in power models, and (iii) a two stage power model that surmounts challenges in methods for selecting hardware counters to capture proces- using existing power models across multiple architectures are sor power over multiple processor architectures. Automated proposed and developed. The key results are: (i) the automated methods are required for easily building power models for a hardware performance counter selection method achieves compa- collection of heterogeneous processors as seen in traditional rable selection to the manual method reported in the literature, data centers that host multiple generations of server proces- (ii) the noise filter reduces the mean error in power models by up to 55%, and (iii) the two stage power model can predict sors, or in emerging distributed computing environments like dynamic power with less than 8% error on both ARM and Intel fog/edge computing [8] and mobile cloud computing (in these processors, which is an improvement over classic models. -

Experiment No
1 LIST OF EXPERIMENTS 1. Study of logic gates. 2. Design and implementation of adders and subtractors using logic gates. 3. Design and implementation of code converters using logic gates. 4. Design and implementation of 4-bit binary adder/subtractor and BCD adder using IC 7483. 5. Design and implementation of 2-bit magnitude comparator using logic gates, 8- bit magnitude comparator using IC 7485. 6. Design and implementation of 16-bit odd/even parity checker/ generator using IC 74180. 7. Design and implementation of multiplexer and demultiplexer using logic gates and study of IC 74150 and IC 74154. 8. Design and implementation of encoder and decoder using logic gates and study of IC 7445 and IC 74147. 9. Construction and verification of 4-bit ripple counter and Mod-10/Mod-12 ripple counter. 10. Design and implementation of 3-bit synchronous up/down counter. 11. Implementation of SISO, SIPO, PISO and PIPO shift registers using flip-flops. KCTCET/2016-17/Odd/3rd/ETE/CSE/LM 2 EXPERIMENT NO. 01 STUDY OF LOGIC GATES AIM: To study about logic gates and verify their truth tables. APPARATUS REQUIRED: SL No. COMPONENT SPECIFICATION QTY 1. AND GATE IC 7408 1 2. OR GATE IC 7432 1 3. NOT GATE IC 7404 1 4. NAND GATE 2 I/P IC 7400 1 5. NOR GATE IC 7402 1 6. X-OR GATE IC 7486 1 7. NAND GATE 3 I/P IC 7410 1 8. IC TRAINER KIT - 1 9. PATCH CORD - 14 THEORY: Circuit that takes the logical decision and the process are called logic gates. -
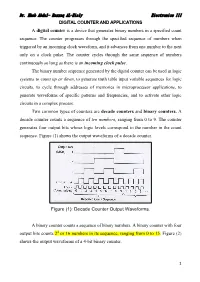
1 DIGITAL COUNTER and APPLICATIONS a Digital Counter Is
Dr. Ehab Abdul- Razzaq AL-Hialy Electronics III DIGITAL COUNTER AND APPLICATIONS A digital counter is a device that generates binary numbers in a specified count sequence. The counter progresses through the specified sequence of numbers when triggered by an incoming clock waveform, and it advances from one number to the next only on a clock pulse. The counter cycles through the same sequence of numbers continuously so long as there is an incoming clock pulse. The binary number sequence generated by the digital counter can be used in logic systems to count up or down, to generate truth table input variable sequences for logic circuits, to cycle through addresses of memories in microprocessor applications, to generate waveforms of specific patterns and frequencies, and to activate other logic circuits in a complex process. Two common types of counters are decade counters and binary counters. A decade counter counts a sequence of ten numbers, ranging from 0 to 9. The counter generates four output bits whose logic levels correspond to the number in the count sequence. Figure (1) shows the output waveforms of a decade counter. Figure (1): Decade Counter Output Waveforms. A binary counter counts a sequence of binary numbers. A binary counter with four output bits counts 24 or 16 numbers in its sequence, ranging from 0 to 15. Figure (2) shows-the output waveforms of a 4-bit binary counter. 1 Dr. Ehab Abdul- Razzaq AL-Hialy Electronics III Figure (2): Binary Counter Output Waveforms. EXAMPLE (1): Decade Counter. Problem: Determine the 4-bit decade counter output that corresponds to the waveforms shown in Figure (1). -

Developer Guide
Red Hat Enterprise Linux 6 Developer Guide An introduction to application development tools in Red Hat Enterprise Linux 6 Last Updated: 2017-10-20 Red Hat Enterprise Linux 6 Developer Guide An introduction to application development tools in Red Hat Enterprise Linux 6 Robert Krátký Red Hat Customer Content Services [email protected] Don Domingo Red Hat Customer Content Services Jacquelynn East Red Hat Customer Content Services Legal Notice Copyright © 2016 Red Hat, Inc. and others. This document is licensed by Red Hat under the Creative Commons Attribution-ShareAlike 3.0 Unported License. If you distribute this document, or a modified version of it, you must provide attribution to Red Hat, Inc. and provide a link to the original. If the document is modified, all Red Hat trademarks must be removed. Red Hat, as the licensor of this document, waives the right to enforce, and agrees not to assert, Section 4d of CC-BY-SA to the fullest extent permitted by applicable law. Red Hat, Red Hat Enterprise Linux, the Shadowman logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries. Linux ® is the registered trademark of Linus Torvalds in the United States and other countries. Java ® is a registered trademark of Oracle and/or its affiliates. XFS ® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries. MySQL ® is a registered trademark of MySQL AB in the United States, the European Union and other countries. Node.js ® is an official trademark of Joyent. -

Design and Implementation of High Speed Counters Using “MUX Based Full Adder (MFA)”
IOSR Journal of Electronics and Communication Engineering (IOSR-JECE) e-ISSN: 2278-2834,p- ISSN: 2278-8735.Volume 14, Issue 4, Ser. I (Jul.-Aug. 2019), PP 57-64 www.iosrjournals.org Design and Implementation of High speed counters using “MUX based Full Adder (MFA)” K.V.Jyothi1, G.P.S. Prashanti2, 1Student, 2Assistant Professor 1,2,(Department of Electronics and Communication Engineering, Gayatri Vidya Parishad College of Engineering For Women,Visakhapatnam, Andhra Pradesh, India) Corresponding Author: K.V.Jyothi Abstract: In this brief, a new binary counter design is proposed. Counters are used to determine how many number of inputs are active (in the logic ONE state) for multi input circuits. In the existing systems 6:3 and 7:3 Counters are designed with full and half adders, parallel counters, stacking circuits. It uses 3-bit stacking and 6-bit stacking circuits which group all the “1” bits together and then stacks are converted into binary counts. This leads to increase in delay and area. To overcome this problem “MUX based Full adder (MFA)” 6:3 and 7:3 counters are proposed. The backend counter simulations are achieved by using MENTOR GRAPHICS in 130nm technology and frontend simulations are done by using XILINX. This MFA counter is faster than existing stacking counters and also consumesless area. Additionally, using this counters in Wallace tree multiplier architectures reduces latency for 64 and 128-bit multipliers. Keywords: stacking circuits, parallel counters,High speed counters, MUX based full adder (MFA) counter,Mentor graphics,Xilinx,SPARTAN-6 FPGA. ----------------------------------------------------------------------------------------------------------------------------- ---------- Date of Submission: 28-07-2019 Date of acceptance: 13-08-2019 ----------------------------------------------------------------------------------------------------------------------------- ---------- I. -

Analysing CMS Software Performance Using Igprof, Oprofile and Callgrind
Analysing CMS software performance using IgProf, OPro¯le and callgrind L Tuura1, V Innocente2, G Eulisse1 1 Northeastern University, Boston, MA, USA 2 CERN, Geneva, Switzerland Abstract. The CMS experiment at LHC has a very large body of software of its own and uses extensively software from outside the experiment. Understanding the performance of such a complex system is a very challenging task, not the least because there are extremely few developer tools capable of pro¯ling software systems of this scale, or producing useful reports. CMS has mainly used IgProf, valgrind, callgrind and OPro¯le for analysing the performance and memory usage patterns of our software. We describe the challenges, at times rather extreme ones, faced as we've analysed the performance of our software and how we've developed an understanding of the performance features. We outline the key lessons learnt so far and the actions taken to make improvements. We describe why an in-house general pro¯ler tool still ends up besting a number of renowned open-source tools, and the improvements we've made to it in the recent year. 1. The performance optimisation issue The Compact Muon Solenoid (CMS) experiment on the Large Hadron Collider at CERN [1] is expected to start running within a year. The computing requirements for the experiment are immense. For the ¯rst year of operation, 2008, we budget 32.5M SI2k (SPECint 2000) computing capacity. This corresponds to some 2650 servers if translated into the most capable computers currently available to us.1 It is critical CMS on the one hand acquires the resources needed for the planned physics analyses, and on the other hand optimises the software to complete the task with the resources available. -

Sensors and Data Encryption, Two Aspects of Electronics That Used to Be Two Worlds Apart and That Are Now Often Tightly Integrated, One Relying on the Other
www.eenewseurope.com January 2019 electronics europe News News e-skin beats human touch Swedish startup beats e-Ink on low-power Special Focus: Power Sources european business press November 2011 Electronic Engineering Times Europe1 181231_8-3_Mill_EENE_EU_Snipe.indd 1 12/14/18 3:59 PM 181231_QualR_EENE_EU.indd 1 12/14/18 3:53 PM CONTENTS JANUARY 2019 Dear readers, www.eenewseurope.com January 2019 The Consumer Electronics Show has just closed its doors in Las Vegas, yet the show has opened the mind of many designers, some returning home with new electronics europe News News ideas and possibly new companies to be founded. All the electronic devices unveiled at CES share in common the need for a cheap power source and a lot of research goes into making power sources more sus- tainable. While lithium-ion batteries are commercially mature, their long-term viability is often questioned and new battery chemistries are being investigated for their simpler material sourcing, lower cost and sometime increased energy density. Energy harvesting is another feature that is more and more often inte- e-skin beats human touch grated into wearables but also at grid-level. Our Power Sources feature will give you a market insight and reviews some of the latest findings. Other topics covered in our January edition are Sensors and Data Encryption, two aspects of electronics that used to be two worlds apart and that are now often tightly integrated, one relying on the other. Swedish startup beats e-Ink on low-power With this first edition of 2019, let me wish you all an excellent year and plenty Special Focus: Power Sources of new business opportunities, whether you are designing the future for a european business press startup or working for a well-established company. -

NVIDIA Tegra 4 Family CPU Architecture 4-PLUS-1 Quad Core
Whitepaper NVIDIA Tegra 4 Family CPU Architecture 4-PLUS-1 Quad core 1 Table of Contents ...................................................................................................................................................................... 1 Introduction .............................................................................................................................................. 3 NVIDIA Tegra 4 Family of Mobile Processors ............................................................................................ 3 Benchmarking CPU Performance .............................................................................................................. 4 Tegra 4 Family CPUs Architected for High Performance and Power Efficiency ......................................... 6 Wider Issue Execution Units for Higher Throughput ............................................................................ 6 Better Memory Level Parallelism from a Larger Instruction Window for Out-of-Order Execution ...... 7 Fast Load-To-Use Logic allows larger L1 Data Cache ............................................................................. 8 Enhanced branch prediction for higher efficiency .............................................................................. 10 Advanced Prefetcher for higher MLP and lower latency .................................................................... 10 Large Unified L2 Cache ....................................................................................................................... -

Hardware-Assisted Rootkits: Abusing Performance Counters on the ARM and X86 Architectures
Hardware-Assisted Rootkits: Abusing Performance Counters on the ARM and x86 Architectures Matt Spisak Endgame, Inc. [email protected] Abstract the OS. With KPP in place, attackers are often forced to move malicious code to less privileged user-mode, to ele- In this paper, a novel hardware-assisted rootkit is intro- vate privileges enabling a hypervisor or TrustZone based duced, which leverages the performance monitoring unit rootkit, or to become more creative in their approach to (PMU) of a CPU. By configuring hardware performance achieving a kernel mode rootkit. counters to count specific architectural events, this re- Early advances in rootkit design focused on low-level search effort proves it is possible to transparently trap hooks to system calls and interrupts within the kernel. system calls and other interrupts driven entirely by the With the introduction of hardware virtualization exten- PMU. This offers an attacker the opportunity to redirect sions, hypervisor based rootkits became a popular area control flow to malicious code without requiring modifi- of study allowing malicious code to run underneath a cations to a kernel image. guest operating system [4, 5]. Another class of OS ag- The approach is demonstrated as a kernel-mode nostic rootkits also emerged that run in System Manage- rootkit on both the ARM and Intel x86-64 architectures ment Mode (SMM) on x86 [6] or within ARM Trust- that is capable of intercepting system calls while evad- Zone [7]. The latter two categories, which leverage vir- ing current kernel patch protection implementations such tualization extensions, SMM on x86, and security exten- as PatchGuard.