Middle-Down Proteomics Reveals Dense Sites of Methylation and Phosphorylation in Arginine-Rich RNA-Binding Proteins
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Hypopituitarism May Be an Additional Feature of SIM1 and POU3F2 Containing 6Q16 Deletions in Children with Early Onset Obesity
Open Access Journal of Pediatric Endocrinology Case Report Hypopituitarism may be an Additional Feature of SIM1 and POU3F2 Containing 6q16 Deletions in Children with Early Onset Obesity Rutteman B1, De Rademaeker M2, Gies I1, Van den Bogaert A2, Zeevaert R1, Vanbesien J1 and De Abstract Schepper J1* Over the past decades, 6q16 deletions have become recognized as a 1Department of Pediatric Endocrinology, UZ Brussel, frequent cause of the Prader-Willi-like syndrome. Involvement of SIM1 in the Belgium deletion has been linked to the development of obesity. Although SIM1 together 2Department of Genetics, UZ Brussel, Belgium with POU3F2, which is located close to the SIM1 locus, are involved in pituitary *Corresponding author: De Schepper J, Department development and function, pituitary dysfunction has not been reported frequently of Pediatric Endocrinology, UZ Brussel, Belgium in cases of 6q16.1q16.3 deletion involving both genes. Here we report on a case of a girl with typical Prader-Willi-like symptoms including early-onset Received: December 23, 2016; Accepted: February 21, hyperphagic obesity, hypotonia, short hands and feet and neuro-psychomotor 2017; Published: February 22, 2017 development delay. Furthermore, she suffered from central diabetes insipidus, central hypothyroidism and hypocortisolism. Her genetic defect is a 6q16.1q16.3 deletion, including SIM1 and POU3F2. We recommend searching for a 6q16 deletion in children with early onset hyperphagic obesity associated with biological signs of hypopituitarism and/or polyuria-polydipsia syndrome. The finding of a combined SIM1 and POU3F2 deletion should prompt monitoring for the development of hypopituitarism, if not already present at diagnosis. Keywords: 6q16 deletion; SIM1; POU3F2; Prader-Willi-like syndrome; Hypopituitarism Introduction insipidus and of some specific pituitary hormone deficiencies in children with a combined SIM1 and POU3F2 deficiency. -

Análise Integrativa De Perfis Transcricionais De Pacientes Com
UNIVERSIDADE DE SÃO PAULO FACULDADE DE MEDICINA DE RIBEIRÃO PRETO PROGRAMA DE PÓS-GRADUAÇÃO EM GENÉTICA ADRIANE FEIJÓ EVANGELISTA Análise integrativa de perfis transcricionais de pacientes com diabetes mellitus tipo 1, tipo 2 e gestacional, comparando-os com manifestações demográficas, clínicas, laboratoriais, fisiopatológicas e terapêuticas Ribeirão Preto – 2012 ADRIANE FEIJÓ EVANGELISTA Análise integrativa de perfis transcricionais de pacientes com diabetes mellitus tipo 1, tipo 2 e gestacional, comparando-os com manifestações demográficas, clínicas, laboratoriais, fisiopatológicas e terapêuticas Tese apresentada à Faculdade de Medicina de Ribeirão Preto da Universidade de São Paulo para obtenção do título de Doutor em Ciências. Área de Concentração: Genética Orientador: Prof. Dr. Eduardo Antonio Donadi Co-orientador: Prof. Dr. Geraldo A. S. Passos Ribeirão Preto – 2012 AUTORIZO A REPRODUÇÃO E DIVULGAÇÃO TOTAL OU PARCIAL DESTE TRABALHO, POR QUALQUER MEIO CONVENCIONAL OU ELETRÔNICO, PARA FINS DE ESTUDO E PESQUISA, DESDE QUE CITADA A FONTE. FICHA CATALOGRÁFICA Evangelista, Adriane Feijó Análise integrativa de perfis transcricionais de pacientes com diabetes mellitus tipo 1, tipo 2 e gestacional, comparando-os com manifestações demográficas, clínicas, laboratoriais, fisiopatológicas e terapêuticas. Ribeirão Preto, 2012 192p. Tese de Doutorado apresentada à Faculdade de Medicina de Ribeirão Preto da Universidade de São Paulo. Área de Concentração: Genética. Orientador: Donadi, Eduardo Antonio Co-orientador: Passos, Geraldo A. 1. Expressão gênica – microarrays 2. Análise bioinformática por module maps 3. Diabetes mellitus tipo 1 4. Diabetes mellitus tipo 2 5. Diabetes mellitus gestacional FOLHA DE APROVAÇÃO ADRIANE FEIJÓ EVANGELISTA Análise integrativa de perfis transcricionais de pacientes com diabetes mellitus tipo 1, tipo 2 e gestacional, comparando-os com manifestações demográficas, clínicas, laboratoriais, fisiopatológicas e terapêuticas. -

Imputation of Exome Sequence Variants Into Population- Based Samples and Blood-Cell-Trait-Associated Loci in African Americans: NHLBI GO Exome Sequencing Project
ARTICLE Imputation of Exome Sequence Variants into Population- Based Samples and Blood-Cell-Trait-Associated Loci in African Americans: NHLBI GO Exome Sequencing Project Paul L. Auer,1,17 Jill M. Johnsen,2,3,17 Andrew D. Johnson,4,17 Benjamin A. Logsdon,1,17 Leslie A. Lange,5,17 Michael A. Nalls,6 Guosheng Zhang,5 Nora Franceschini,5 Keolu Fox,3 Ethan M. Lange,5 Stephen S. Rich,7 Christopher J. O’Donnell,4 Rebecca D. Jackson,8 Robert B. Wallace,9 Zhao Chen,10 Timothy A. Graubert,11 James G. Wilson,12 Hua Tang,13,17 Guillaume Lettre,14,17 Alex P. Reiner,1,6,17,* Santhi K. Ganesh,15,17 and Yun Li5,16,17,* Researchers have successfully applied exome sequencing to discover causal variants in selected individuals with familial, highly pene- trant disorders. We demonstrate the utility of exome sequencing followed by imputation for discovering low-frequency variants asso- ciated with complex quantitative traits. We performed exome sequencing in a reference panel of 761 African Americans and then imputed newly discovered variants into a larger sample of more than 13,000 African Americans for association testing with the blood cell traits hemoglobin, hematocrit, white blood count, and platelet count. First, we illustrate the feasibility of our approach by demon- strating genome-wide-significant associations for variants that are not covered by conventional genotyping arrays; for example, one such association is that between higher platelet count and an MPL c.117G>T (p.Lys39Asn) variant encoding a p.Lys39Asn amino À acid substitution of the thrombpoietin receptor gene (p ¼ 1.5 3 10 11). -

Appendix 2. Significantly Differentially Regulated Genes in Term Compared with Second Trimester Amniotic Fluid Supernatant
Appendix 2. Significantly Differentially Regulated Genes in Term Compared With Second Trimester Amniotic Fluid Supernatant Fold Change in term vs second trimester Amniotic Affymetrix Duplicate Fluid Probe ID probes Symbol Entrez Gene Name 1019.9 217059_at D MUC7 mucin 7, secreted 424.5 211735_x_at D SFTPC surfactant protein C 416.2 206835_at STATH statherin 363.4 214387_x_at D SFTPC surfactant protein C 295.5 205982_x_at D SFTPC surfactant protein C 288.7 1553454_at RPTN repetin solute carrier family 34 (sodium 251.3 204124_at SLC34A2 phosphate), member 2 238.9 206786_at HTN3 histatin 3 161.5 220191_at GKN1 gastrokine 1 152.7 223678_s_at D SFTPA2 surfactant protein A2 130.9 207430_s_at D MSMB microseminoprotein, beta- 99.0 214199_at SFTPD surfactant protein D major histocompatibility complex, class II, 96.5 210982_s_at D HLA-DRA DR alpha 96.5 221133_s_at D CLDN18 claudin 18 94.4 238222_at GKN2 gastrokine 2 93.7 1557961_s_at D LOC100127983 uncharacterized LOC100127983 93.1 229584_at LRRK2 leucine-rich repeat kinase 2 HOXD cluster antisense RNA 1 (non- 88.6 242042_s_at D HOXD-AS1 protein coding) 86.0 205569_at LAMP3 lysosomal-associated membrane protein 3 85.4 232698_at BPIFB2 BPI fold containing family B, member 2 84.4 205979_at SCGB2A1 secretoglobin, family 2A, member 1 84.3 230469_at RTKN2 rhotekin 2 82.2 204130_at HSD11B2 hydroxysteroid (11-beta) dehydrogenase 2 81.9 222242_s_at KLK5 kallikrein-related peptidase 5 77.0 237281_at AKAP14 A kinase (PRKA) anchor protein 14 76.7 1553602_at MUCL1 mucin-like 1 76.3 216359_at D MUC7 mucin 7, -

Functional Analysis of Structural Variation in the 2D and 3D Human Genome
FUNCTIONAL ANALYSIS OF STRUCTURAL VARIATION IN THE 2D AND 3D HUMAN GENOME by Conor Mitchell Liam Nodzak A dissertation submitted to the faculty of The University of North Carolina at Charlotte in partial fulfillment of the requirements for the degree of Doctor of Philosophy in Bioinformatics and Computational Biology Charlotte 2019 Approved by: Dr. Xinghua Mindy Shi Dr. Rebekah Rogers Dr. Jun-tao Guo Dr. Adam Reitzel ii c 2019 Conor Mitchell Liam Nodzak ALL RIGHTS RESERVED iii ABSTRACT CONOR MITCHELL LIAM NODZAK. Functional analysis of structural variation in the 2D and 3D human genome. (Under the direction of DR. XINGHUA MINDY SHI) The human genome consists of over 3 billion nucleotides that have an average distance of 3.4 Angstroms between each base, which equates to over two meters of DNA contained within the 125 µm3 volume diploid cell nuclei. The dense compaction of chromatin by the supercoiling of DNA forms distinct architectural modules called topologically associated domains (TADs), which keep protein-coding genes, noncoding RNAs and epigenetic regulatory elements in close nuclear space. It has recently been shown that these conserved chromatin structures may contribute to tissue-specific gene expression through the encapsulation of genes and cis-regulatory elements, and mutations that affect TADs can lead to developmental disorders and some forms of cancer. At the population-level, genomic structural variation contributes more to cumulative genetic difference than any other class of mutation, yet much remains to be studied as to how structural variation affects TADs. Here, we study the func- tional effects of structural variants (SVs) through the analysis of chromatin topology and gene activity for three trio families sampled from genetically diverse popula- tions from the Human Genome Structural Variation Consortium. -

Karla Alejandra Vizcarra Zevallos Análise Da Função De Genes
Karla Alejandra Vizcarra Zevallos Análise da função de genes candidatos à manutenção da inativação do cromossomo X em humanos Dissertação apresentada ao Pro- grama de Pós‐Graduação Inter- unidades em Biotecnologia USP/ Instituto Butantan/ IPT, para obtenção do Título de Mestre em Ciências. São Paulo 2017 Karla Alejandra Vizcarra Zevallos Análise da função de genes candidatos à manutenção da inativação do cromossomo X em humanos Dissertação apresentada ao Pro- grama de Pós‐Graduação Inter- unidades em Biotecnologia do Instituto de Ciências Biomédicas USP/ Instituto Butantan/ IPT, para obtenção do Título de Mestre em Ciências. Área de concentração: Biotecnologia Orientadora: Profa. Dra. Lygia da Veiga Pereira Carramaschi Versão corrigida. A versão original eletrônica encontra-se disponível tanto na Biblioteca do ICB quanto na Biblioteca Digital de Teses e Dissertações da USP (BDTD) São Paulo 2017 UNIVERSIDADE DE SÃO PAULO Programa de Pós-Graduação Interunidades em Biotecnologia Universidade de São Paulo, Instituto Butantan, Instituto de Pesquisas Tecnológicas Candidato(a): Karla Alejandra Vizcarra Zevallos Título da Dissertação: Análise da função de genes candidatos à manutenção da inativação do cromossomo X em humanos Orientador: Profa. Dra. Lygia da Veiga Pereira Carramaschi A Comissão Julgadora dos trabalhos de Defesa da Dissertação de Mestrado, em sessão pública realizada a ........./......../.........., considerou o(a) candidato(a): ( ) Aprovado(a) ( ) Reprovado(a) Examinador(a): Assinatura: .............................................................................. -

Improving the Detection of Genomic Rearrangements in Short Read Sequencing Data
Improving the detection of genomic rearrangements in short read sequencing data Daniel Lee Cameron orcid.org/0000-0002-0951-7116 Doctor of Philosophy July 2017 Department of Medical Biology, University of Melbourne Bioinformatics Division, Walter and Eliza Hall Institute of Medical Research Submitted in total fulfilment of the requirements of the degree of Doctor of Philosophy Produced on archival quality paper Page i Abstract Genomic rearrangements, also known as structural variants, play a significant role in the development of cancer and in genetic disorders. With the bulk of genetic studies focusing on single nucleotide variants and small insertions and deletions, structural variants are often overlooked. In part this is due to the increased complexity of analysis required, but is also due to the increased difficulty of detection. The identification of genomic rearrangements using massively parallel sequencing remains a major challenge. To address this, I have developed the Genome Rearrangement Identification Software Suite (GRIDSS). In this thesis, I show that high sensitivity and specificity can be achieved by performing reference-guided assembly prior to variant calling and incorporating the results of this assembly into the variant calling process itself. Utilising a novel genome-wide break-end assembly approach, GRIDSS halves the false discovery rate compared to other recent methods on human cell line data. A comparison of assembly approaches reveals that incorporating read alignment information into a positional de Bruijn graph improves assembly quality compared to traditional de Bruijn graph assembly. To characterise the performance of structural variant calling software, I have performed the most comprehensive benchmarking of structural variant calling software to date. -

RNA Splicing Regulated by RBFOX1 Is Essential for Cardiac Function in Zebrafish Karen S
© 2015. Published by The Company of Biologists Ltd | Journal of Cell Science (2015) 128, 3030-3040 doi:10.1242/jcs.166850 RESEARCH ARTICLE RNA splicing regulated by RBFOX1 is essential for cardiac function in zebrafish Karen S. Frese1,2,*, Benjamin Meder1,2,*, Andreas Keller3,4, Steffen Just5, Jan Haas1,2, Britta Vogel1,2, Simon Fischer1,2, Christina Backes4, Mark Matzas6, Doreen Köhler1, Vladimir Benes7, Hugo A. Katus1,2 and Wolfgang Rottbauer5,‡ ABSTRACT U2, U4, U5 and U6) and several hundred associated regulator Alternative splicing is one of the major mechanisms through which proteins (Wahl et al., 2009). Some of the best-characterized the proteomic and functional diversity of eukaryotes is achieved. splicing regulators include the serine-arginine (SR)-rich family, However, the complex nature of the splicing machinery, its associated heterogeneous nuclear ribonucleoproteins (hnRNPs) proteins, and splicing regulators and the functional implications of alternatively the Nova1 and Nova2, and the PTB and nPTB (also known as spliced transcripts are only poorly understood. Here, we investigated PTBP1 and PTBP2) families (David and Manley, 2008; Gabut et al., the functional role of the splicing regulator rbfox1 in vivo using the 2008; Li et al., 2007; Matlin et al., 2005). The diversity in splicing is zebrafish as a model system. We found that loss of rbfox1 led to further increased by the location and nucleotide sequence of pre- progressive cardiac contractile dysfunction and heart failure. By using mRNA enhancer and silencer motifs that either promote or inhibit deep-transcriptome sequencing and quantitative real-time PCR, we splicing by the different regulators. Adding to this complexity, show that depletion of rbfox1 in zebrafish results in an altered isoform regulating motifs are very common throughout the genome, but are expression of several crucial target genes, such as actn3a and hug. -

A Catalogue of Stress Granules' Components
Catarina Rodrigues Nunes A Catalogue of Stress Granules’ Components: Implications for Neurodegeneration UNIVERSIDADE DO ALGARVE Departamento de Ciências Biomédicas e Medicina 2019 Catarina Rodrigues Nunes A Catalogue of Stress Granules’ Components: Implications for Neurodegeneration Master in Oncobiology – Molecular Mechanisms of Cancer This work was done under the supervision of: Clévio Nóbrega, Ph.D UNIVERSIDADE DO ALGARVE Departamento de Ciências Biomédicas e Medicina 2019 i ii A catalogue of Stress Granules’ Components: Implications for neurodegeneration Declaração de autoria de trabalho Declaro ser a autora deste trabalho, que é original e inédito. Autores e trabalhos consultados estão devidamente citados no texto e constam na listagem de referências incluída. I declare that I am the author of this work, that is original and unpublished. Authors and works consulted are properly cited in the text and included in the list of references. _______________________________ (Catarina Nunes) iii Copyright © 2019 Catarina Nunes A Universidade do Algarve reserva para si o direito, em conformidade com o disposto no Código do Direito de Autor e dos Direitos Conexos, de arquivar, reproduzir e publicar a obra, independentemente do meio utilizado, bem como de a divulgar através de repositórios científicos e de admitir a sua cópia e distribuição para fins meramente educacionais ou de investigação e não comerciais, conquanto seja dado o devido crédito ao autor e editor respetivos. iv Part of the results of this thesis were published in Nunes,C.; Mestre,I.; Marcelo,A. et al. MSGP: the first database of the protein components of the mammalian stress granules. Database (2019) Vol. 2019. (In annex A). v vi ACKNOWLEDGEMENTS A realização desta tese marca o final de uma etapa académica muito especial e que jamais irei esquecer. -

Mrna Editing, Processing and Quality Control in Caenorhabditis Elegans
| WORMBOOK mRNA Editing, Processing and Quality Control in Caenorhabditis elegans Joshua A. Arribere,*,1 Hidehito Kuroyanagi,†,1 and Heather A. Hundley‡,1 *Department of MCD Biology, UC Santa Cruz, California 95064, †Laboratory of Gene Expression, Medical Research Institute, Tokyo Medical and Dental University, Tokyo 113-8510, Japan, and ‡Medical Sciences Program, Indiana University School of Medicine-Bloomington, Indiana 47405 ABSTRACT While DNA serves as the blueprint of life, the distinct functions of each cell are determined by the dynamic expression of genes from the static genome. The amount and specific sequences of RNAs expressed in a given cell involves a number of regulated processes including RNA synthesis (transcription), processing, splicing, modification, polyadenylation, stability, translation, and degradation. As errors during mRNA production can create gene products that are deleterious to the organism, quality control mechanisms exist to survey and remove errors in mRNA expression and processing. Here, we will provide an overview of mRNA processing and quality control mechanisms that occur in Caenorhabditis elegans, with a focus on those that occur on protein-coding genes after transcription initiation. In addition, we will describe the genetic and technical approaches that have allowed studies in C. elegans to reveal important mechanistic insight into these processes. KEYWORDS Caenorhabditis elegans; splicing; RNA editing; RNA modification; polyadenylation; quality control; WormBook TABLE OF CONTENTS Abstract 531 RNA Editing and Modification 533 Adenosine-to-inosine RNA editing 533 The C. elegans A-to-I editing machinery 534 RNA editing in space and time 535 ADARs regulate the levels and fates of endogenous dsRNA 537 Are other modifications present in C. -

Metabolites OH
H OH metabolites OH Article Metabolite Genome-Wide Association Study (mGWAS) and Gene-Metabolite Interaction Network Analysis Reveal Potential Biomarkers for Feed Efficiency in Pigs Xiao Wang and Haja N. Kadarmideen * Quantitative Genomics, Bioinformatics and Computational Biology Group, Department of Applied Mathematics and Computer Science, Technical University of Denmark, Richard Petersens Plads, Building 324, 2800 Kongens Lyngby, Denmark; [email protected] * Correspondence: [email protected] Received: 1 April 2020; Accepted: 11 May 2020; Published: 15 May 2020 Abstract: Metabolites represent the ultimate response of biological systems, so metabolomics is considered the link between genotypes and phenotypes. Feed efficiency is one of the most important phenotypes in sustainable pig production and is the main breeding goal trait. We utilized metabolic and genomic datasets from a total of 108 pigs from our own previously published studies that involved 59 Duroc and 49 Landrace pigs with data on feed efficiency (residual feed intake (RFI)), genotype (PorcineSNP80 BeadChip) data, and metabolomic data (45 final metabolite datasets derived from LC-MS system). Utilizing these datasets, our main aim was to identify genetic variants (single-nucleotide polymorphisms (SNPs)) that affect 45 different metabolite concentrations in plasma collected at the start and end of the performance testing of pigs categorized as high or low in their feed efficiency (based on RFI values). Genome-wide significant genetic variants could be then used as potential genetic or biomarkers in breeding programs for feed efficiency. The other objective was to reveal the biochemical mechanisms underlying genetic variation for pigs’ feed efficiency. In order to achieve these objectives, we firstly conducted a metabolite genome-wide association study (mGWAS) based on mixed linear models and found 152 genome-wide significant SNPs (p-value < 1.06 10 6) in association with 17 metabolites that included 90 significant SNPs annotated × − to 52 genes. -
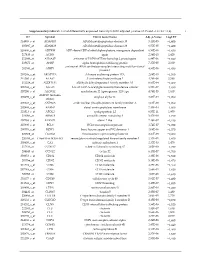
Supplementary Table S1. List of Differentially Expressed
Supplementary table S1. List of differentially expressed transcripts (FDR adjusted p‐value < 0.05 and −1.4 ≤ FC ≥1.4). 1 ID Symbol Entrez Gene Name Adj. p‐Value Log2 FC 214895_s_at ADAM10 ADAM metallopeptidase domain 10 3,11E‐05 −1,400 205997_at ADAM28 ADAM metallopeptidase domain 28 6,57E‐05 −1,400 220606_s_at ADPRM ADP‐ribose/CDP‐alcohol diphosphatase, manganese dependent 6,50E‐06 −1,430 217410_at AGRN agrin 2,34E‐10 1,420 212980_at AHSA2P activator of HSP90 ATPase homolog 2, pseudogene 6,44E‐06 −1,920 219672_at AHSP alpha hemoglobin stabilizing protein 7,27E‐05 2,330 aminoacyl tRNA synthetase complex interacting multifunctional 202541_at AIMP1 4,91E‐06 −1,830 protein 1 210269_s_at AKAP17A A‐kinase anchoring protein 17A 2,64E‐10 −1,560 211560_s_at ALAS2 5ʹ‐aminolevulinate synthase 2 4,28E‐06 3,560 212224_at ALDH1A1 aldehyde dehydrogenase 1 family member A1 8,93E‐04 −1,400 205583_s_at ALG13 ALG13 UDP‐N‐acetylglucosaminyltransferase subunit 9,50E‐07 −1,430 207206_s_at ALOX12 arachidonate 12‐lipoxygenase, 12S type 4,76E‐05 1,630 AMY1C (includes 208498_s_at amylase alpha 1C 3,83E‐05 −1,700 others) 201043_s_at ANP32A acidic nuclear phosphoprotein 32 family member A 5,61E‐09 −1,760 202888_s_at ANPEP alanyl aminopeptidase, membrane 7,40E‐04 −1,600 221013_s_at APOL2 apolipoprotein L2 6,57E‐11 1,600 219094_at ARMC8 armadillo repeat containing 8 3,47E‐08 −1,710 207798_s_at ATXN2L ataxin 2 like 2,16E‐07 −1,410 215990_s_at BCL6 BCL6 transcription repressor 1,74E‐07 −1,700 200776_s_at BZW1 basic leucine zipper and W2 domains 1 1,09E‐06 −1,570 222309_at