Developing Rust on Bare-Metal
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
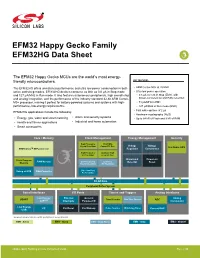
EFM32 Happy Gecko Family EFM32HG Data Sheet
EFM32 Happy Gecko Family EFM32HG Data Sheet The EFM32 Happy Gecko MCUs are the world’s most energy- friendly microcontrollers. KEY FEATURES The EFM32HG offers unmatched performance and ultra low power consumption in both • ARM Cortex-M0+ at 25 MHz active and sleep modes. EFM32HG devices consume as little as 0.6 μA in Stop mode • Ultra low power operation and 127 μA/MHz in Run mode. It also features autonomous peripherals, high overall chip • 0.6 μA current in Stop (EM3), with and analog integration, and the performance of the industry standard 32-bit ARM Cortex- brown-out detection and RAM retention M0+ processor, making it perfect for battery-powered systems and systems with high- • 51 μA/MHz in EM1 performance, low-energy requirements. • 127 μA/MHz in Run mode (EM0) • Fast wake-up time of 2 µs EFM32HG applications include the following: • Hardware cryptography (AES) • Energy, gas, water and smart metering • Alarm and security systems • Up to 64 kB of Flash and 8 kB of RAM • Health and fitness applications • Industrial and home automation • Smart accessories Core / Memory Clock Management Energy Management Security High Frequency 48/24 MHz Voltage Voltage Crystal Oscillator Comm. RC Osc. Hardware AES ARM CortexTM M0+ processor Regulator Comparator High Frequency Auxiliary High RC Oscillator Freq. RC Osc. Brown-out Power-on Flash Program RAM Memory Low Frequency Low Freq. Detector Reset Memory Crystal Oscillator RC Oscillator Debug w/ MTB DMA Controller Ultra Low Freq. RC Oscillator 32-bit bus Peripheral Reflex System Serial Interfaces I/O Ports Timers and Triggers Analog Interfaces Low Energy External General Analog USART Timer/Counter Real Time Counter ADC UARTTM Interrupts Purpose I/O Comparator Low Energy I2C Pin Reset Pin Wakeup Pulse Counter Watchdog Timer Current DAC USB Lowest power mode with peripheral operational: EM0 - Active EM1 - Sleep EM2 – Deep Sleep EM3 - Stop EM4 - Shutoff silabs.com | Building a more connected world. -

Silicon Labs to Acquire Energy Micro, a Leader in Low Power ARM Cortex-Based Microcontrollers and Radios
June 7, 2013 Silicon Labs to Acquire Energy Micro, a Leader in Low Power ARM Cortex-Based Microcontrollers and Radios Companies' Combined Portfolios Enable the Internet of Things, Smart Energy and Portable Electronics AUSTIN, Texas & OSLO, Norway--(BUSINESS WIRE)-- Silicon Labs (Nasdaq: SLAB), a leader in high-performance, analog- intensive, mixed-signal ICs, today announced that it has signed a definitive agreement to acquire Energy Micro AS. Based in Oslo, Norway, the late-stage privately held company offers the industry's most power-efficient portfolio of 32-bit microcontrollers (MCUs) and is developing multi-protocol wireless RF solutions based on the industry-leading ARM® Cortex-M architecture. Energy Micro's energy-friendly MCU and radio solutions are designed to enable a broad range of power-sensitive applications for the Internet of Things (IoT), smart energy, home automation, security and portable electronics markets. This strategic acquisition accelerates Silicon Labs' growth opportunities and positions the company as the foremost innovator in energy-friendly embedded solutions. The growth of the IoT market, coupled with continued deployment of smart grid and smart energy infrastructure, is driving strong demand for energy-efficient processing and wireless connectivity technology to enable connected devices in which low-power capabilities are increasingly important. Industry experts predict that the number of connected devices for the IoT will top 15 billion nodes by 2015 and reach 50 billion nodes by 2020. Energy Micro's portfolio complements Silicon Labs' 32-bit Precision32™ MCU, Ember® ZigBee® and sub-GHz wireless products and targets a growing embedded market. The acquisition greatly expands Silicon Labs' MCU portfolio, adding nearly 250 ARM- based EFM32 Gecko MCU products ranging from extreme-low-power, small-footprint MCUs based on the ARM Cortex-M0+ core to higher-performance, energy-friendly MCUs powered by the Cortex-M4 core capable of DSP and floating-point operations. -

Embedded Market Study, 2013
2013 EMBEDDED MARKET STUDY Essential to Engineers DATASHEETS.COM | DESIGNCON | DESIGN EAST & DESIGN WEST | EBN | EDN | EE TIMES | EMBEDDED | PLANET ANALOG | TECHONLINE | TEST & MEASUREMENT WORLD 2013 Embedded Market Study 2 UBM Tech Electronics’ Brands Unparalleled Reach & Experience UBM Tech Electronics is the media and marketing services solution for the design engineering and electronics industry. Our audience of over 2,358,928 (as of March 5, 2013) are the executives and engineers worldwide who design, develop, and commercialize technology. We provide them with the essentials they need to succeed: news and analysis, design and technology, product data, education, and fun. Copyright © 2013 by UBM. All rights reserved. 2013 Embedded Market Study 5 Purpose and Methodology • Purpose: To profile the findings of the 2013 results of EE Times Group annual comprehensive survey of the embedded systems markets worldwide. Findings include types of technology used, all aspects of the embedded development process, tools used, work environment, applications, methods and processes, operating systems used, reasons for using and not using chips and technology, and brands and chips currently used by or being considered by embedded developers. Many questions in this survey have been trended over two to five years. • Methodology: A web-based online survey instrument based on the previous year’s survey was developed and implemented by independent research company Wilson Research Group from January 18, 2013 to February 13, 2013 by email invitation • Sample: E-mail invitations were sent to subscribers to UBM/EE Times Group Embedded Brands with one reminder invitation. Each invitation included a link to the survey. • Returns: 2,098 valid respondents for an overall confidence of 95% +/- 2.13%. -

SEGGER Microcontroller Embedded Software Suite to Support Energy Micro’S Cortex-M3 Gecko Microcontrollers
Company news Reference: EM0063 SEGGER Microcontroller embedded software suite to support Energy Micro’s Cortex-M3 Gecko microcontrollers Hilden, Germany and Oslo, Norway, December 7 2011 – SEGGER Microcontroller, a leading provider of software solutions for embedded applications, and Energy Micro, the energy friendly microcontroller and radio company, have announced that SEGGER’s high-performance embedded middleware suite now supports Energy Micro’s range of ultra low energy ARM® Cortex™-M3 based EFM32 Gecko microcontrollers. The comprehensive feature-rich and high-performance software suite from SEGGER delivers an easy-to-use environment for embedded systems development, offering exceptionally low memory requirements, which minimizes Bill-of-Materials costs and enables significantly reduced power consumption overall. The middleware’s high performance also enables lower clock speed to further reduce system power consumption. Specific tools from SEGGER supporting the Energy Micro EFM32 Gecko MCUs include: the real-time operating system "embOS" which offers multitasking with minimal resources and true zero interrupt latency; the embedded file system "emFile" which is optimized for minimum RAM memory consumption supporting SD-card, NAND and NOR flash memory with wear levelling; and the efficient "emWin" user interface, an LCD controller-independent graphical user interface (GUI) for applications requiring a graphics display. The high-quality graphical software, which runs with any display or any MCU, delivers flicker-free animation, optimized drawing routines with optional anti-aliasing, and a GUI builder for Window Objects (Widgets). Thanks to the long-term partnership between the two companies, all Energy Micro development and starter kits are supplied with SEGGER’s J-Link emulation technology, and the latest Leopard and Giant Gecko development kits also include SEGGER´s advanced J-Trace. -

Behavioral Subtyping, Specification Inheritance, and Modular Reasoning Gary T
Computer Science Technical Reports Computer Science 9-3-2006 Behavioral Subtyping, Specification Inheritance, and Modular Reasoning Gary T. Leavens Iowa State University David A. Naumann Iowa State University Follow this and additional works at: http://lib.dr.iastate.edu/cs_techreports Part of the Software Engineering Commons Recommended Citation Leavens, Gary T. and Naumann, David A., "Behavioral Subtyping, Specification Inheritance, and Modular Reasoning" (2006). Computer Science Technical Reports. 269. http://lib.dr.iastate.edu/cs_techreports/269 This Article is brought to you for free and open access by the Computer Science at Iowa State University Digital Repository. It has been accepted for inclusion in Computer Science Technical Reports by an authorized administrator of Iowa State University Digital Repository. For more information, please contact [email protected]. Behavioral Subtyping, Specification Inheritance, and Modular Reasoning Abstract Behavioral subtyping is an established idea that enables modular reasoning about behavioral properties of object-oriented programs. It requires that syntactic subtypes are behavioral refinements. It validates reasoning about a dynamically-dispatched method call, say E.m(), using the specification associated with the static type of the receiver expression E. For languages with references and mutable objects the idea of behavioral subtyping has not been rigorously formalized as such, the standard informal notion has inadequacies, and exact definitions are not obvious. This paper formalizes behavioral subtyping and supertype abstraction for a Java-like sequential language with classes, interfaces, exceptions, mutable heap objects, references, and recursive types. Behavioral subtyping is proved sound and semantically complete for reasoning with supertype abstraction. Specification inheritance, as used in the specification language JML, is formalized and proved to entail behavioral subtyping. -

QSG166: WF200 Wi-Fi Development Kit Quick Start Guide
QSG166: WF200 Wi-Fi Development Kit Quick Start Guide The WF200 Wi-Fi Development Kit is an excellent way to get star- ted with WF200 Wi-Fi transceiver IC to achieve performance eval- KEY CONTENTS uation and software development. • Expansion Board with the WF200 Wi-Fi transceiver IC onboard. It supports various hardware and software use cases, as described below. • Direct connection to Silicon Labs EFM32 and EFR32 hosts (20 pin EXP) Two versions of devkits are available: • Direct connection to Raspberry Pi for the • SLEXP8022A contains WF200 development board (BRD8022A), that can be connec- Linux use case ted to Silicon Labs EFM32 or EFR32 Starter kits or to a Raspberry Pi for the Linux • Support of 3rd party MCUs case. It also contains a micro-SD card allowing fast startup with a Raspberry Pi. • Selectable SPI or SDIO host interface • SLEXP8022B is a superset of SLEXP8022A with a Raspberry Pi 2 model V1.2 inclu- ded. This document described the first steps to get a Wi-Fi connection for the Linux case (Raspberry Pi), Silicon Labs MCUs, as well as a case with a 3rd party MCU. Note: Refer to UG379 for more details about the board. silabs.com | Building a more connected world. Rev. 0.2 Table of Contents 1. Getting Started with Raspberry Pi and Linux ...................3 1.1 Requirements ..............................3 1.1.1 Hardware ..............................3 1.1.2 Software ..............................3 1.2 Hardware Setup .............................3 1.3 SSH Connection .............................4 1.4 Wi-Fi Demos...............................4 1.4.1 Station Demo .............................4 1.4.2 Access Point Demo ...........................5 1.5 Update SD Card .............................5 1.6 Software Repositories ...........................5 2. -

Advances in Programming Languages Lecture 18: Concurrency and More in Rust
Advances in Programming Languages Lecture 18: Concurrency and More in Rust Ian Stark School of Informatics The University of Edinburgh Friday 24 November 2016 Semester 1 Week 10 https://blog.inf.ed.ac.uk/apl16 Topic: Programming for Memory Safety The final block of lectures cover features used in the Rust programming language. Introduction: Zero-Cost Abstractions (and their cost) Control of Memory: Ownership Concurrency and more This section of the course is entirely new — Rust itself is not that old — and I apologise for any consequent lack of polish. Ian Stark Advances in Programming Languages / Lecture 18: Concurrency and More in Rust 2016-11-24 The Rust Programming Language The Rust language is intended as a tool for safe systems programming. Three key objectives contribute to this. Zero-cost abstractions Basic References Memory safety https://www.rust-lang.org https://blog.rust-lang.org Safe concurrency The “systems programming” motivation resonates with that for imperative C/C++. The “safe” part draws extensively on techniques developed for functional Haskell and OCaml. Sometimes these align more closely than you might expect, often by overlap between two aims: Precise control for the programmer; Precise information for the compiler. Ian Stark Advances in Programming Languages / Lecture 18: Concurrency and More in Rust 2016-11-24 Previous Homework Watch This Peter O’Hearn: Reasoning with Big Code https://is.gd/reasoning_big_code Talk at the Alan Turing Institute about how Facebook is using automatic verification at scale to check code and give feedback to programmers. Ian Stark Advances in Programming Languages / Lecture 18: Concurrency and More in Rust 2016-11-24 Guest Speaker ! Probabilistic Programming: What is it and how do we make it better? Maria Gorinova University of Edinburgh 3.10pm Tuesday 29 November 2016 Ian Stark Advances in Programming Languages / Lecture 18: Concurrency and More in Rust 2016-11-24 Optional: Review and Exam Preparation ! The final lecture will be an exam review, principally for single-semester visiting students. -

Xtend User Guide
Xtend User Guide September 10, 2013 Contents I. Getting Started 5 1. Introduction 6 2. Hello World 7 3. The Movies Example 9 3.1. The Data . .9 3.2. Parsing The Data . 10 3.3. Answering Some Questions . 11 3.3.1. Question 1 : What Is The Number Of Action Movies? . 11 3.3.2. Question 2 : What Is The Year The Best Movie From The 80's Was Released? . 12 3.3.3. Question 3 : What Is The The Sum Of All Votes Of The Top Two Movies?................................. 13 II. Reference Documentation 14 4. Java Interoperability 15 4.1. Type Inference . 15 4.2. Conversion Rules . 15 4.3. Interoperability with Java . 16 5. Classes and Members 17 5.1. Package Declaration . 17 5.2. Imports . 17 5.3. Class Declaration . 18 5.4. Constructors . 19 5.5. Fields . 19 5.6. Methods . 20 5.6.1. Abstract Methods . 20 5.6.2. Overriding Methods . 21 5.6.3. Declared Exceptions . 21 5.6.4. Inferred Return Types . 21 5.6.5. Generic Methods . 22 2 5.6.6. Dispatch Methods . 22 5.7. Annotations . 26 5.8. Extension Methods . 26 5.8.1. Extensions from the Library . 27 5.8.2. Local Extension Methods . 28 5.8.3. Extension Imports . 28 5.8.4. Extension Provider . 29 5.9. Interface Declaration . 29 5.10. Annotation Type Declaration . 30 5.11. Enum Type Declaration . 30 6. Expressions 31 6.1. Literals . 31 6.1.1. String Literals . 31 6.1.2. Character Literals . 32 6.1.3. Number Literals . -

The Rust Programming Language
The Rust Programming Language The Rust Team 2016-10-01 2 Contents 1 Introduction 11 Contributing ...................................... 11 2 Getting Started 13 Installing Rust ..................................... 13 Hello, world! ...................................... 16 Hello, Cargo! ...................................... 19 Closing Thoughts .................................... 23 3 Tutorial: Guessing Game 25 Set up .......................................... 25 Processing a Guess ................................... 26 Generating a secret number .............................. 30 Comparing guesses ................................... 33 Looping ......................................... 37 Complete! ........................................ 41 4 Syntax and Semantics 43 Variable Bindings ....................................... 43 Patterns ......................................... 43 Type annotations .................................... 44 Mutability ........................................ 44 Initializing bindings .................................. 45 Scope and shadowing .................................. 46 Functions ........................................... 48 Primitive Types ........................................ 53 Booleans ......................................... 53 4 CONTENTS char ........................................... 53 Numeric types ..................................... 54 Arrays .......................................... 55 Slices ........................................... 56 str ........................................... -

UG416: EFM32 Gecko Starter Kit User's Guide
UG416: EFM32G Gecko Starter Kit User's Guide The EFM32-G8XX-STK Starter Kit is an excellent starting point to become familiar with the EFM32G™ Gecko Microcontroller. TARGET DEVICE The Starter Kit contains sensors and peripherals demonstrating some of the Gecko's • EFM32G Gecko Microcontroller (EFM32G890F128G-E-BGA112R) many capabilities. The kit provides all necessary tools for developing an EFM32G Gecko application. • CPU: 32-bit ARM® Cortex-M3 • Memory: 128 kB flash and 16 kB RAM KIT FEATURES • USB connectivity • Advanced Energy Monitor (AEM) • SEGGER J-Link on-board debugger • Debug Multiplexer supporting external hardware as well as on-board MCU • User LEDs / Pushbuttons • 160 segment LCD • 4-segment capacitive touch slider and touch button • 20-pin 2.54 mm header for expansion boards • Breakout pads for direct access to I/O pins • Power sources include USB and CR2032 coin cell battery. SOFTWARE SUPPORT • Simplicity Studio™ • IAR Embedded Workbench silabs.com | Building a more connected world. Rev. 2.00 Table of Contents 1. Introduction ................................3 1.1 Description ...............................3 1.2 Features ................................3 1.3 Getting Started ..............................3 2. Kit Block Diagram .............................4 3. Kit Hardware Layout ............................5 4. Connectors ................................6 4.1 Breakout Pads ..............................6 4.2 Expansion Header .............................8 4.3 Debug Connector (DBG) ..........................10 4.4 Simplicity Connector ............................11 5. Power Supply and Reset ..........................12 5.1 MCU Power Selection ...........................12 5.2 Board Controller Power ...........................12 5.3 EFM32G Reset ..............................13 6. Peripherals ...............................14 6.1 Push Buttons and LEDs ...........................14 6.2 LCD .................................15 6.3 Capacitive Touch Slider ...........................15 6.4 Virtual COM Port .............................16 7. -

COMP322 - Introduction to C++
COMP322 - Introduction to C++ Lecture 09 - Inheritance continued Robert D. Vincent School of Computer Science 10 March 2010 Recall from last time I Inheritance describes the creation of derived classes from base classes. I Derived classes inherit all data and functions from their base classes, while certain functions such as constructors are handled specially. I Polymorphism is a product of the combination of virtual functions and C++ assignment compatibility rules. I We can create abstract types which contain “pure” functions that may have no implementation. We can’t actually create objects from these types, but we can create references or pointers to abstract types. Static dispatch If a member function is not virtual, the choice of function to call is made at compile time: class A{ int f(); }; class B: public A{ int f(); }; int main() { B b; A *pa = &b; pa->f(); // Calls A::f() because pa is of type 'A *' } This is called either “static dispatch” or “static binding”, and it is the default behavior in C++. Dynamic dispatch If a member function is virtual, the choice of function to call is made at run time: class A{ virtual int f(); }; class B: public A{ int f(); }; int main() { B b; A *pa = &b; pa->f(); // Calls B::f() because pa points to a 'B *' } Called either “dynamic dispatch” or “run-time binding”, this is both more useful and less efficient than static dispatch. Dynamic dispatch internals I Dynamic dispatch is implemented by adding a layer of indirection to a function call. I Any object with dynamic dispatch contains an automatically-generated pointer to a vtable. -

Portable ISP Programmer for Field-Service and Production Applications
Supporting FLASH microcontrollers Portable ISP Programmer for Field-Service and Production applications ARM Devices Supported... The EPSILON5-MK4(ARM) programmer being used in Standalone Mode STM32 F1 STM32 F2 STM32 F4 STM32 L1 Mainstream MCUs High-performance MCUs High-performance MCUs Ultra-low-power MCUs The EPSILON5-MK4(ARM) is a high-speed portable programmer with DSP and FPU designed for field-service and production In-System Programming Support coming soon for... (ISP) applications. It supports programming of many popular ARM FLASH microcontroller devices via the ARM JTAG Debug Interface. The programmer is capable of operating in ‘Standalone Mode’ (without PC) ZERO TINY GECKO Cortex-M0+ Zero Gecko Cortex-M3 Tiny Gecko Cortex-M3 Gecko Cortex® - M0+ Cortex® - M3 Cortex® - M3 allowing an operator to program a single project only. For field / production Microcontroller Microcontroller Microcontroller LEOPARD GIANT WONDER Cortex-M3 Leopard Gecko Cortex-M4 Giant Gecko Cortex-M3 Wonder Gecko Cortex® - M3 Cortex® - M4 Cortex® - M3 applications the unit is designed to operate in ‘Standalone Mode’. A Microcontroller Microcontroller Microcontroller ‘Standalone Programming Project’ can be recalled from the on-board non-volatile FLASH memory and programmed into a Target System by pressing a single key. All the popular ARM ISP connection headers are catered for. ● STM32 F0 STM32 F3 STM32 W Portable In-System (ISP) Programmer Entry level MCUs Mixed-signal MCUs Wireless MCUs, ● Ideal for Field-service or low-volume Production programming with