Direct Universal Access: Making Data Center Resources Available to FPGA
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
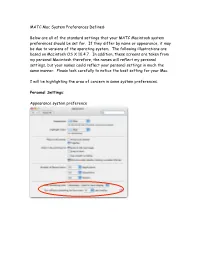
MATC Mac System Preferences Defined
MATC Mac System Preferences Defined: Below are all of the standard settings that your MATC Macintosh system preferences should be set for. If they differ by name or appearance, it may be due to versions of the operating system. The following illustrations are based on Macintosh OS X 10.4.7. In addition, these screens are taken from my personal Macintosh therefore, the names will reflect my personal settings, but your names could reflect your personal settings in much the same manner. Please look carefully to notice the best setting for your Mac. I will be highlighting the area of concern in some system preferences. Personal Settings: Appearance system preference MATC Macintosh Standard System Preferences Dashboard and Expose Desktop and Screen Saver Page 2 MATC Macintosh Standard System Preferences Dock International See edit list on the next page. Page 3 MATC Macintosh Standard System Preferences Edit list for the language list. Please keep English checked and active. Formats Page 4 MATC Macintosh Standard System Preferences Input Menu. This is where the keyboard viewer is located. Security-No Master Password! Page 5 MATC Macintosh Standard System Preferences Spotlight Page 6 MATC Macintosh Standard System Preferences Hardware Settings Bluetooth Settings Bluetooth Devices Page 7 MATC Macintosh Standard System Preferences Bluetooth Sharing CD’s and DVD’s Displays Show displays in menu bar for easy access to changing the display resolutions. Page 8 MATC Macintosh Standard System Preferences Energy Saver. Set the computer to never sleep everywhere! Energy Saver-Laptop Battery Settings Page 9 MATC Macintosh Standard System Preferences Keyboard and Mouse Trackpad-for Laptop users Notice the new feature for new Macintosh Laptop Users! Page 10 MATC Macintosh Standard System Preferences Mouse-Mighty Mouse users Bluetooth Settings Page 11 MATC Macintosh Standard System Preferences Keyboard Shortcuts Print and Fax Main The printers will be personalized for each person and each Mac. -

Digital Infrastructure Moonshot for Africa
Connecting Africa Through Broadband A strategy for doubling connectivity by 2021 and reaching universal access by 2030 Running footer 1 Connecting Africa Through Broadband A strategy for doubling connectivity by 2021 and reaching universal access by 2030 Broadband Commission Working Group on Broadband for All: A “Digital Infrastructure Moonshot” for Africa October 2019 Table of Contents Foreword .............................................................................................................................................8 Acknowledgements ........................................................................................................................ 12 Executive Summary ........................................................................................................................ 14 Abbreviations ....................................................................................................................................22 1. Introduction ...............................................................................................................................24 2. Snapshot of Africa’s Digital Infrastructure ...........................................................................34 3. Mission, Vision, and Principles for Digital Transformation in Africa ...............................46 4. Investment Requirements for 2021 and 2030 Digital Infrastructure Targets ..............56 5. Policy and Regulatory Frameworks to Enable Digital Transformation ..........................68 6. Digital Skills -

Mac OS X Support Essentials V10.6
APPLE CERTIFIED SUPPORT PROFESSIONAL V10.6 MASSARIC AT GMAIL DOT COM NOTEBOOK PAGE 1 OF 43 APPLE CERTIFIED SUPPORT PROFESSIONAL V10.6 MASSARIC AT GMAIL DOT COM Apple Certified Support Professional v10.6 9 Disclaimer 9 Installation and Initial Setup 10 1. What Utilities are available when booted from the Mac OS X Install DVD? 10 2. What are the minimum hardware requirement for installing Mac OS X v10.6? 10 3. What four preparation steps must you take before installing Mac OS X? 10 4. What are the advantages and disadvantages of using a single-partition drive with Mac OS X? How about a multiple-partition drive? 11 5. Which packages are installed by default when installing Mac OS X? 11 6. Where can you locate the System Version Number, Build Number, Serial Number? What is the significance of these numbers? 11 7. How do the four System Preferences categories differ? 12 8. How do you ensure that you have the latest Apple Software? 12 User Accounts 13 9. What are the five types of user accounts in Mac OS X? How are they different? 13 10. What are account attributes 13 11. How can you limit a user account? 14 12. What are some security risks associated with each type of user account? 14 13. What default folders make up a user’s home folder 15 14. What three types of resources contention can occur when fast use switching is enabled? 15 15. What security risk can occur when fast user switching is enabled? 15 16. What does a keychain do? 15 17. -

Ubiquitous Client Side Customization of Web Applications
PONTIFICIA UNIVERSIDAD CATOLICA DE CHILE SCHOOL OF ENGINEERING UBIQUITOUS CLIENT SIDE CUSTOMIZATION OF WEB APPLICATIONS. RAÚL MONTES TRONCOSO Thesis submitted to the Office of Research and Graduate Studies in partial fulfillment of the requirements for the degree of Master of Science in Engineering Advisor: JAIME NAVÓN C. Santiago de Chile, January 2010 c MMIX, RAÚL MONTES TRONCOSO c MMIX, RAÚL MONTES TRONCOSO Se autoriza la reproducción total o parcial, con fines académicos, por cualquier medio o procedimiento, incluyendo la cita bibliográfica que acredita al trabajo y a su autor. PONTIFICIA UNIVERSIDAD CATOLICA DE CHILE SCHOOL OF ENGINEERING UBIQUITOUS CLIENT SIDE CUSTOMIZATION OF WEB APPLICATIONS. RAÚL MONTES TRONCOSO Members of the Committee: JAIME NAVÓN C. JENS HARDINGS LUIS GUERRERO JUAN DE DIOS RIVERA Thesis submitted to the Office of Research and Graduate Studies in partial fulfillment of the requirements for the degree of Master of Science in Engineering Santiago de Chile, January 2010 c MMIX, RAÚL MONTES TRONCOSO Para Mariela. ACKNOWLEDGEMENTS There are many people I would like to thank because, directly or indirectly, they were helpful or they routed me in the right direction. But I want to give special thanks to some of them who were of huge importance in finishing this thesis. I thank Mariela for her unconditional love and constant support and encouragement to complete this thesis. I also thank my parents because they understood and supported me in professional and academic decisions sometimes not so easy to understand. I want to thank Professor Jaime Navón for his guidance, help, trust and also for putting pressure on me to finish this when I needed it. -

Mac OS X Desktop.Pdf
Apple Training Series Mac OS X Support Essentials v10.6 Kevin M. White Apple Training Series: Mac OS X Support Essentials v10.6 Kevin M. White Copyright © 2010 by Apple Inc. Published by Peachpit Press. For information on Peachpit Press books, contact: Peachpit Press 1249 Eighth Street Berkeley, CA 94710 510/524-2178 510/524-2221 (fax) www.peachpit.com To report errors, please send a note to [email protected]. Peachpit Press is a division of Pearson Education. Apple Training Series Editor: Rebecca Freed Production Editors: Danielle Foster, Becky Winter Copyeditor: Peggy Nauts Tech Editor: Gordon Davisson Apple Editor: Shane Ross Proofreader: Suzie Nasol Compositor: Danielle Foster Indexer: Valerie Perry Cover design: Mimi Heft Cover illustrator: Kent Oberheu Notice of Rights All rights reserved. No part of this book may be reproduced or transmitted in any form by any means, electronic, mechanical, photocopying, recording, or otherwise, without the prior written permission of the publisher. For infor- mation on getting permission for reprints and excerpts, contact [email protected]. Notice of Liability The information in this book is distributed on an “As Is” basis without warranty. While every precaution has been taken in the preparation of the book, neither the author nor Peachpit shall have any liability to any person or entity with respect to any loss or damage caused or alleged to be caused directly or indirectly by the instructions contained in this book or by the computer software and hardware products described in it. Trademarks Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. -

Copyrighted Material
Index A Apple Software License Agreement (SLA), 319, 327 Acceptance Delay slider, Universal Access preference Apple Support Downloads, 142–143 pane, 266 Apple TV, 109, 123 Account name text fi eld, Accounts preference pane, 78, Apple web site, 44–45 80 AppleScript, 239 Account Name text fi eld, Network preference pane, Application Windows mode, Exposé, 69–70 149 Application Windows option, Activate Screen Corners Account pane, MobileMe preference pane, 249 menus, 230 Account Type drop-down menu, Incoming Mail Server applications window, 270 active, 26 accounts. See user accounts compatibility with Snow Leopard, 317 Accounts preference pane, 257–258 drag-and-drop, installing, 331–332 Accounts Preferences, Mail, 271–272 installing with installer, 332–334 Activate Screen Corners section, Exposé & Spaces Applications folder, 11–12 preference pane, 230 arrow buttons, toolbar, 14 active applications, 26 Assist me button, Network preference pane, 252 Active Screen Corners section, Exposé & Spaces attachments, Mail, 274 preference pane, 71 audio chat, iChat, 286–287 Add a printer dialog, 191 audio recording, 104 Add Folder of Pictures option, Desktop & Screen Saver Automatic Login, disabling, 87–88 preference pane, 45, 226 Automatic login drop-down menu, Accounts Add MobileMe Gallery option, Desktop & Screen preference pane, 88 Saver preference pane, 45, 226 automatic updates, 142 Add Printer window, 203 Add RSS Feed option, Desktop & Screen Saver preference pane, 45, 226 B Address bar, Safari, 155–156 Back to My Mac pane, MobileMe preference -

Mac OS X Server User Management for Version 10.4 Or Later Second Edition
Mac OS X Server User Management For Version 10.4 or Later Second Edition K Apple Computer, Inc. Apple, the Apple logo, AirPort, AppleShare, AppleTalk, © 2006 Apple Computer, Inc. All rights reserved. FireWire, iBook, Keychain, LaserWriter, Mac, Mac OS, Macintosh, PowerBook, and QuickTime are trademarks The owner or authorized user of a valid copy of of Apple Computer, Inc., registered in the U.S. and other Mac OS X Server software may reproduce this countries. Extensions Manager, Finder, and SuperDrive publication for the purpose of learning to use such are trademarks of Apple Computer, Inc. software. No part of this publication may be reproduced or transmitted for commercial purposes, such as selling Adobe and PostScript are trademarks of Adobe Systems copies of this publication or for providing paid-for Incorporated. support services. Java and all Java-based trademarks and logos are Every effort has been made to ensure that the trademarks or registered trademarks of Sun information in this manual is accurate. Apple Computer, Microsystems, Inc. in the U.S. and other countries. Inc., is not responsible for printing or clerical errors. UNIX is a registered trademark in the United States and Apple other countries, licensed exclusively through X/Open 1 Infinite Loop Company, Ltd. Cupertino, CA 95014-2084 408-996-1010 Other company and product names mentioned herein www.apple.com are trademarks of their respective companies. Mention of third-party products is for informational purposes Use of the “keyboard” Apple logo (Option-Shift-K) for only and constitutes neither an endorsement nor a commercial purposes without the prior written consent recommendation. -

VPAT™ for Apple Itunes 12 for OS X
VPAT™ for Apple iTunes 12 for OS X The following Voluntary Product Accessibility information refers to the Apple iTunes 12 for OS X. For more information on the accessibility features of this product and to learn more about this product’s features, visit www.apple.com/itunes and www.apple.com/accessibility VPAT™ Voluntary Product Accessibility Template Summary Table Criteria Supporting Features Remarks and Explanations Section 1194.21 Software Applications and Please refer to the attached VPAT Please refer to the attached VPAT Operating Systems Section 1194.22 Web-based Internet Information Please refer to the attached VPAT Please refer to the attached VPAT and Applications Section 1194.23 Telecommunications Products Not Applicable Not Applicable Section 1194.24 Video and Multi-media Products Not Applicable Not Applicable Section 1194.25 Self-Contained, Closed Products Not Applicable Not Applicable Section 1194.26 Desktop and Portable Computers Not Applicable Not Applicable Section 1194.31 Functional Performance Criteria Please refer to the attached VPAT Please refer to the attached VPAT Section 1194.41 Information, Documentation and Please refer to the attached VPAT Please refer to the attached VPAT Support VPAT™ for Apple iTunes 12 for OS X Page !1 of !7 Section 1194.21 Software Applications and Operating Systems – Detail Criteria Supporting Features Remarks and Explanations (a) When software is designed to run on a system Supported iTunes is accessible to keyboard-only users. that has a keyboard, product functions shall be executable from a keyboard where the function iTunes features are accessible to the blind and itself or the result of performing a function can be visually impaired using VoiceOver, including discerned textually. -

CHAPTER 7: the Wireless Revolution and Universal Access
Trends in Telecommunications Reform 2003 CHAPTER 7: The Wireless Revolution and Universal Access Author: Michael L. Best, Program in Internet & Telecom Convergence, Massachusetts Institute of Technology We need to think of ways to bring Wireless Fidelity (Wi-Fi) applications to the developing world, so as to make use of unlicensed radio spectrum to deliver cheap and fast Internet access -- United Nations Secretary General Kofi Annan1 7.1 Introduction Kofi Annan recently added his voice to a growing community of technologists, public policy officials and telecommunications practitioners who foresee a revolution in rural universal access. This revolution will be founded on a new suite of wireless technologies, matched by supportive public policies and business approaches, that can provide Internet access and voice service cheaply to rural and under-served communities. One basic approach looks something like this: small entrepreneurs provide Internet and voice services within their own communities by purchasing inexpensive basic radio equipment and transmitting on unlicensed frequencies. Collections of these local operators, collaborating (and interconnecting) with larger Internet and basic service operators, begin to weave together a patchwork of universal access where little or no telecommunications services existed before. This access patchwork would be cheap, robust, and extremely responsive to innovation. While more has to be done to prove this model will be sustainable, recent experiments in India and elsewhere have been demonstrating that the basic approach is sound. New and creative enterprises can make rural and poor markets profitable, affordable, sustainable and served in ways that meet national and local development objectives. But this requires innovation, advanced technology and creative business and public policies. -

Mac OS X Snow Leopard for Dummies Free
FREE MAC OS X SNOW LEOPARD FOR DUMMIES PDF Bob Levitus | 456 pages | 15 Sep 2009 | John Wiley and Sons Ltd | 9780470435434 | English | Chichester, United Kingdom Mac OS X Snow Leopard For Dummies Cheat Sheet - dummies Time has passed and there are simply dozens of titles appearing each year covering every topic imaginable. The Mac series of Dummy books goes back to the OS 7 time period and continues to this day. Written with his normal sense of humor present throughout the book, LeVitus takes the new user through the steps of learning to use Snow Leopard. LeVitus breaks Snow Leopard learning down into six separate sections for the reader. Simple things that experienced Mac users may skip over but that a new user may not be familiar with, such as desktop pictures, widgets, sound effects, the Dock and the Finder are covered within the first part of the book. In Part 2, LeVitus gets Mac OS X Snow Leopard For Dummies to explaining how to organize files and folders, the use of disks and how to organize your life on your Mac. Part 4 of the book explains printing, hooking up your printer of choice, networks, permissions and some of the items that even some seasoned Mac users are not into, such as Automator, AppleScript, Universal Access and Boot Camp. Part 5 goes into a very important part of being a Mac user, Backing Up what you have on your computer. LeVitus covers Time Machine, using the old drag and drop method to a CD, DVD and actually burning your important items to the disk, plus the use of available software, be it freeware or commercially available. -

Uniquely Equipped to Let Every Student Succeed Built-In Solutions That Break Down Barriers to Learning
Apple Technology: Uniquely Equipped to Let Every Student Succeed Built-in solutions that break down barriers to learning. For more than 25 years, Apple has been dedicated to developing features that engage all students, enhance their studies, and inspire them to achieve their best—regardless of physical or learning disability. The Mac, iPod, and iPhone come packed with assistive technologies, so students everywhere can compensate for learning differences using today’s resources and tools. No hidden costs. Every new Mac comes with Mac OS X Snow Leopard, complete with dozens of innovations that accommodate special-needs students. A built-in screen reader supports students with learning disabilities, as well as blind and low-vision students. Speech recognition, text-to-speech, Quick- Time closed captioning, screen magnification, keyboard navigation, and more are all included at no additional cost. In fact, a MacBook with all those accessible applications and the VoiceOver Literacy and learning 1 screen reader is comparable in price to a single copy of a traditional screen reader for Windows. A range of tools that help students get organized, stay focused, and New ways to learn. improve reading comprehension. Digital media tools integrated into the Mac and into iPod and iPhone devices build confidence Vision and comfort in and out of the classroom. Students who have difficulty with traditional forms of Built-in tools and technologies to classroom communication can express themselves using iLife software—through slide shows, help blind and low-vision students. movies, audio presentations, and music. Hearing-impaired students can use sign language Hearing 2 to communicate over video iChat. -

Simulation of Fusion Plasmas: Current Status and Future Direction
Plasma Science and Technology, Vol.9, No.3, Jun. 2007 Simulation of Fusion Plasmas: Current Status and Future Direction D.A. Batchelor1,M.Beck2, A. Becoulet3,R.V.Budny4, C.S. Chang5, P.H. Diamond6,J.Q.Dong7,G.Y.Fu∗4, A. Fukuyama8,T.S.Hahm4, D.E. Keyes9,Y.Kishimoto10,S.Klasky1,L.L.Lao11,K.Li12,Z.Lin∗13, B. Ludaescher14,J.Manickam4,N.Nakajima15, T. Ozeki16,N.Podhorszki14, W.M. Tang4,M.A.Vouk17,R.E.Waltz11,S.J.Wang18, H.R. Wilson19,X.Q.Xu20, M. Yagi21,F.Zonca22 1 Oak Ridge National Laboratory, Oak Ridge, TN 37831, USA 2 1122 Volunteer Blvd, Suite 203, Knoxville, TN 37996-3450, USA 3 Association EURATOM-CEA sur la Fusion Contrˆol´ee, CEA Cadarache, 13108 Saint Paul lez Durance Cedex, France 4 Princeton Plasma Physics Laboratory, Princeton University, Princeton, NJ 08543, USA 5 Courant Institute of Mathematical Sciences, New York University, 251 Mercer Street, New York, NY 10012, USA 6 University of California at San Diego, Dept. of Physics and Center for Astrophysics and Space Sciences, La Jolla, CA 92093, USA 7 Southwestern Institute of Physics, Chengdu 610041, China 8 Department of Nuclear Engineering, Kyoto University, Kyoto 606-8501, Japan 9 Columbia University, Department of Applied Physics and Applied Mathematics, MC 4701, New York, NY 10027, USA 10 Department of Fundamental Energy Science, Graduate School of Energy Science, Kyoto University, Gokasho, Uji, Kyoto 611-0011, Japan 11 General Atomics, P.O. Box 85608, San Diego, CA 92186, USA 12 Department of Computer Science, Princeton University Princeton, NJ 08544, USA 13 Department of