Audio Processing Laboratory
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Speech Signal Basics
Speech Signal Basics Nimrod Peleg Updated: Feb. 2010 Course Objectives • To get familiar with: – Speech coding in general – Speech coding for communication (military, cellular) • Means: – Introduction the basics of speech processing – Presenting an overview of speech production and hearing systems – Focusing on speech coding: LPC codecs: • Basic principles • Discussing of related standards • Listening and reviewing different codecs. הנחיות לשימוש נכון בטלפון, פלשתינה-א"י, 1925 What is Speech ??? • Meaning: Text, Identity, Punctuation, Emotion –prosody: rhythm, pitch, intensity • Statistics: sampled speech is a string of numbers – Distribution (Gamma, Laplace) Quantization • Information Theory: statistical redundancy – ZIP, ARJ, compress, Shorten, Entropy coding… ...1001100010100110010... • Perceptual redundancy – Temporal masking , frequency masking (mp3, Dolby) • Speech production Model – Physical system: Linear Prediction The Speech Signal • Created at the Vocal cords, Travels through the Vocal tract, and Produced at speakers mouth • Gets to the listeners ear as a pressure wave • Non-Stationary, but can be divided to sound segments which have some common acoustic properties for a short time interval • Two Major classes: Vowels and Consonants Speech Production • A sound source excites a (vocal tract) filter – Voiced: Periodic source, created by vocal cords – UnVoiced: Aperiodic and noisy source •The Pitch is the fundamental frequency of the vocal cords vibration (also called F0) followed by 4-5 Formants (F1 -F5) at higher frequencies. -

Bernoulli-Gaussian Distribution with Memory As a Model for Power Line Communication Noise Victor Fernandes, Weiler A
XXXV SIMPOSIO´ BRASILEIRO DE TELECOMUNICAC¸ OES˜ E PROCESSAMENTO DE SINAIS - SBrT2017, 3-6 DE SETEMBRO DE 2017, SAO˜ PEDRO, SP Bernoulli-Gaussian Distribution with Memory as a Model for Power Line Communication Noise Victor Fernandes, Weiler A. Finamore, Mois´es V. Ribeiro, Ninoslav Marina, and Jovan Karamachoski Abstract— The adoption of Additive Bernoulli-Gaussian Noise very useful to come up with a as simple as possible models (ABGN) as an additive noise model for Power Line Commu- of PLC noise, similar to the additive white Gaussian noise nication (PLC) systems is the subject of this paper. ABGN is a (AWGN) model. model that for a fraction of time is a low power noise and for the remaining time is a high power (impulsive) noise. In this context, In this regard, we introduce the definition of a simple and we investigate the usefulness of the ABGN as a model for the useful mathematical model for the noise perturbing the data additive noise in PLC systems, using samples of noise registered transmission over PLC channel that would be a helpful tool. during a measurement campaign. A general procedure to find the With this goal in mind, an investigation of the usefulness of model parameters, namely, the noise power and the impulsiveness what we call additive Bernoulli-Gaussian noise (ABGN) as a factor is presented. A strategy to assess the noise memory, using LDPC codes, is also examined and we came to the conclusion that model for the noise perturbing the digital communication over ABGN with memory is a consistent model that can be used as for PLC channel is discussed. -

Benchmarking Audio Signal Representation Techniques for Classification with Convolutional Neural Networks
sensors Article Benchmarking Audio Signal Representation Techniques for Classification with Convolutional Neural Networks Roneel V. Sharan * , Hao Xiong and Shlomo Berkovsky Australian Institute of Health Innovation, Macquarie University, Sydney, NSW 2109, Australia; [email protected] (H.X.); [email protected] (S.B.) * Correspondence: [email protected] Abstract: Audio signal classification finds various applications in detecting and monitoring health conditions in healthcare. Convolutional neural networks (CNN) have produced state-of-the-art results in image classification and are being increasingly used in other tasks, including signal classification. However, audio signal classification using CNN presents various challenges. In image classification tasks, raw images of equal dimensions can be used as a direct input to CNN. Raw time- domain signals, on the other hand, can be of varying dimensions. In addition, the temporal signal often has to be transformed to frequency-domain to reveal unique spectral characteristics, therefore requiring signal transformation. In this work, we overview and benchmark various audio signal representation techniques for classification using CNN, including approaches that deal with signals of different lengths and combine multiple representations to improve the classification accuracy. Hence, this work surfaces important empirical evidence that may guide future works deploying CNN for audio signal classification purposes. Citation: Sharan, R.V.; Xiong, H.; Berkovsky, S. Benchmarking Audio Keywords: convolutional neural networks; fusion; interpolation; machine learning; spectrogram; Signal Representation Techniques for time-frequency image Classification with Convolutional Neural Networks. Sensors 2021, 21, 3434. https://doi.org/10.3390/ s21103434 1. Introduction Sensing technologies find applications in detecting and monitoring health conditions. -
EP Signal to Noise in Emp 2
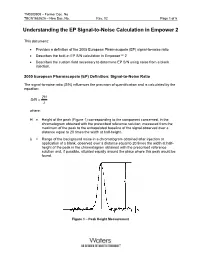
TN0000909 – Former Doc. No. TECN1852625 – New Doc. No. Rev. 02 Page 1 of 5 Understanding the EP Signal-to-Noise Calculation in Empower 2 This document: • Provides a definition of the 2005 European Pharmacopeia (EP) signal-to-noise ratio • Describes the built-in EP S/N calculation in Empower™ 2 • Describes the custom field necessary to determine EP S/N using noise from a blank injection. 2005 European Pharmacopeia (EP) Definition: Signal-to-Noise Ratio The signal-to-noise ratio (S/N) influences the precision of quantification and is calculated by the equation: 2H S/N = λ where: H = Height of the peak (Figure 1) corresponding to the component concerned, in the chromatogram obtained with the prescribed reference solution, measured from the maximum of the peak to the extrapolated baseline of the signal observed over a distance equal to 20 times the width at half-height. λ = Range of the background noise in a chromatogram obtained after injection or application of a blank, observed over a distance equal to 20 times the width at half- height of the peak in the chromatogram obtained with the prescribed reference solution and, if possible, situated equally around the place where this peak would be found. Figure 1 – Peak Height Measurement TN0000909 – Former Doc. No. TECN1852625 – New Doc. No. Rev. 02 Page 2 of 5 In Empower 2 software, the EP Signal-to-Noise (EP S/N) is determined in an automated fashion and does not require a blank injection. The intention of this calculation is to preserve the sense of the EP calculation without requiring a separate blank injection. -

Measurement and Estimation of the Mode Partition Coefficient K
Measurement and Estimation of the Mode Partition Coefficient k Rick Pimpinella and Jose Castro IEEE P802.3bm 40 Gb/s and 100 Gb/s Fiber Optic Task Force November 2012, San Antonio, TX Background & Objective Background: Mode Partition Noise in MMF channel links is caused by pulse-to-pulse power fluctuations among VCSEL modes and differential delay due to dispersion in the fiber (Power independent penalty) “k” is an index used to describe the degree of mode fluctuations and takes on a value between 0 and 1, called the mode partition coefficient [1,2] Currently the IEEE link model assumes k = 0.3 It has been discussed that a new link model requires validation of k The measurement & estimation of k is challenging due to several conditions: Low sensitivity of detectors at 850nm The presence of additional noise components in VCSEL-MMF channels (RIN, MN, Jitter – intensity fluctuations, reflection noise, thermal noise, …) Differences in VCSEL designs Objective: Provide an experimental estimate of the value of k for VCSELs Additional work in progress 2 MPN Theory Originally derived for Fabry-Perot lasers and SMF [3] Assumptions: Total power of all modes carried by each pulse is constant Power fluctuations among modes are anti-correlated Mechanism: When modes (different wavelengths) travel at the same speed their fluctuations remain anti-correlated and the resultant pulse-to-pulse noise is zero. When modes travel in a dispersive medium the modes undergo different delays resulting in pulse distortions and a noise penalty. Example: Two VCSEL modes transmitted in a SMF undergoing chromatic dispersion: START END Optical Waveform @ Detector START t END With mode power fluctuations Decision Region Shorter Wavelength Time (arrival) t slope DL Time (arrival) Longer Wavelength Time (arrival) 3 Example of Intensity Fluctuation among VCSEL modes MPN can be observed using an Optical Spectrum Analyzer (OSA). -

Introduction to Noise Measurements on Business Machines (Bo0125)
BO 0125-11 Introduction to Noise Measurements on Business Machines by Roger Upton, B.Sc. Introduction In recent years, manufacturers of DIN 45 635 pt.19 ization committees in the pursuit of business machines, that is computing ANSI Si.29, (soon to be superced- harmonization, meaning that the stan- and office machines, have come under ed by ANSI S12.10) dards agree with each other in the increasing pressure to provide noise ECMA 74 bulk of their requirements. This appli- data on their products. For instance, it ISO/DIS 7779 cation note first discusses some acous- is becoming increasingly common to tic measurement parameters, and then see noise levels advertised, particular- With four separate standards in ex- the measurements required by the ly for printers. A number of standards istence, one might expect some con- various standards. Finally, it describes have been written governing how such siderable divergence in their require- some Briiel & Kjaer measurement sys- noise measurements should be made, ments. However, there has been close terns capable of making the required namely: contact between the various standard- measurements. Introduction to Noise Measurement Parameters The standards referred to in the previous section call for measure• ments of sound power and sound pres• sure. These measurements can then be used in a variety of ways, such as noise labelling, prediction of installation noise levels, comparison of noise emis• sions of products, and production con• trol. Sound power and sound pressure are fundamentally different quanti• ties. Sound power is a measure of the ability of a device to make noise. It is independent of the acoustic environ• ment. -

Designing Speech and Multimodal Interactions for Mobile, Wearable, and Pervasive Applications
Designing Speech and Multimodal Interactions for Mobile, Wearable, and Pervasive Applications Cosmin Munteanu Nikhil Sharma Abstract University of Toronto Google, Inc. Traditional interfaces are continuously being replaced Mississauga [email protected] by mobile, wearable, or pervasive interfaces. Yet when [email protected] Frank Rudzicz it comes to the input and output modalities enabling Pourang Irani Toronto Rehabilitation Institute our interactions, we have yet to fully embrace some of University of Manitoba University of Toronto the most natural forms of communication and [email protected] [email protected] information processing that humans possess: speech, Sharon Oviatt Randy Gomez language, gestures, thoughts. Very little HCI attention Incaa Designs Honda Research Institute has been dedicated to designing and developing spoken [email protected] [email protected] language and multimodal interaction techniques, Matthew Aylett Keisuke Nakamura especially for mobile and wearable devices. In addition CereProc Honda Research Institute to the enormous, recent engineering progress in [email protected] [email protected] processing such modalities, there is now sufficient Gerald Penn Kazuhiro Nakadai evidence that many real-life applications do not require University of Toronto Honda Research Institute 100% accuracy of processing multimodal input to be [email protected] [email protected] useful, particularly if such modalities complement each Shimei Pan other. This multidisciplinary, two-day workshop -

Background Noise, Noise Sensitivity, and Attitudes Towards Neighbours, and a Subjective Experiment Using a Rubber Ball Impact Sound
International Journal of Environmental Research and Public Health Article Background Noise, Noise Sensitivity, and Attitudes towards Neighbours, and a Subjective Experiment Using a Rubber Ball Impact Sound Jeongho Jeong Fire Insurers Laboratories of Korea, 1030 Gyeongchungdae-ro, Yeoju-si 12661, Korea; [email protected]; Tel.: +82-31-887-6737 Abstract: When children run and jump or adults walk indoors, the impact sounds conveyed to neighbouring households have relatively high energy in low-frequency bands. The experience of and response to low-frequency floor impact sounds can differ depending on factors such as the duration of exposure, the listener’s noise sensitivity, and the level of background noise in housing complexes. In order to study responses to actual floor impact sounds, it is necessary to investigate how the response is affected by changes in the background noise and differences in the response when focusing on other tasks. In this study, the author presented subjects with a rubber ball impact sound recorded from different apartment buildings and housings and investigated the subjects’ responses to varying levels of background noise and when they were assigned tasks to change their level of attention on the presented sound. The subjects’ noise sensitivity and response to their neighbours were also compared. The results of the subjective experiment showed differences in the subjective responses depending on the level of background noise, and high intensity rubber ball impact sounds were associated with larger subjective responses. In addition, when subjects were performing a Citation: Jeong, J. Background Noise, task like browsing the internet, they attended less to the rubber ball impact sound, showing a less Noise Sensitivity, and Attitudes towards Neighbours, and a Subjective sensitive response to the same intensity of impact sound. -

Introduction to Digital Speech Processing Schafer Rabiner and Ronald W
SIGv1n1-2.qxd 11/20/2007 3:02 PM Page 1 FnT SIG 1:1-2 Foundations and Trends® in Signal Processing Introduction to Digital Speech Processing Processing to Digital Speech Introduction R. Lawrence W. Rabiner and Ronald Schafer 1:1-2 (2007) Lawrence R. Rabiner and Ronald W. Schafer Introduction to Digital Speech Processing highlights the central role of DSP techniques in modern speech communication research and applications. It presents a comprehensive overview of digital speech processing that ranges from the basic nature of the speech signal, through a variety of methods of representing speech in digital form, to applications in voice communication and automatic synthesis and recognition of speech. Introduction to Digital Introduction to Digital Speech Processing provides the reader with a practical introduction to Speech Processing the wide range of important concepts that comprise the field of digital speech processing. It serves as an invaluable reference for students embarking on speech research as well as the experienced researcher already working in the field, who can utilize the book as a Lawrence R. Rabiner and Ronald W. Schafer reference guide. This book is originally published as Foundations and Trends® in Signal Processing Volume 1 Issue 1-2 (2007), ISSN: 1932-8346. now now the essence of knowledge Introduction to Digital Speech Processing Introduction to Digital Speech Processing Lawrence R. Rabiner Rutgers University and University of California Santa Barbara USA [email protected] Ronald W. Schafer Hewlett-Packard Laboratories Palo Alto, CA USA Boston – Delft Foundations and Trends R in Signal Processing Published, sold and distributed by: now Publishers Inc. -

The Effects of Background Noise on Distortion Product Otoacoustic Emissions and Hearing Screenings Amy E
Louisiana Tech University Louisiana Tech Digital Commons Doctoral Dissertations Graduate School Spring 2012 The effects of background noise on distortion product otoacoustic emissions and hearing screenings Amy E. Hollowell Louisiana Tech University Follow this and additional works at: https://digitalcommons.latech.edu/dissertations Part of the Speech Pathology and Audiology Commons Recommended Citation Hollowell, Amy E., "" (2012). Dissertation. 348. https://digitalcommons.latech.edu/dissertations/348 This Dissertation is brought to you for free and open access by the Graduate School at Louisiana Tech Digital Commons. It has been accepted for inclusion in Doctoral Dissertations by an authorized administrator of Louisiana Tech Digital Commons. For more information, please contact [email protected]. THE EFFECTS OF BACKGROUND NOISE ON DISTORTION PRODUCT OTOACOUSTIC EMISSIONS AND HEARING SCREENINGS by Amy E. Hollowell, B.S. A Dissertation Presented in Partial Fulfillment of the Requirements of the Degree Doctor of Audiology COLLEGE OF LIBERAL ARTS LOUISIANA TECH UNIVERSITY May 2012 UMI Number: 3515927 All rights reserved INFORMATION TO ALL USERS The quality of this reproduction is dependent upon the quality of the copy submitted. In the unlikely event that the author did not send a complete manuscript and there are missing pages, these will be noted. Also, if material had to be removed, a note will indicate the deletion. DiygrMution UMI 3515927 Published by ProQuest LLC 2012. Copyright in the Dissertation held by the Author. Microform Edition © ProQuest LLC. All rights reserved. This work is protected against unauthorized copying under Title 17, United States Code. ProQuest LLC 789 East Eisenhower Parkway P.O. Box 1346 Ann Arbor, Ml 48106-1346 LOUISIANA TECH UNIVERSITY THE GRADUATE SCHOOL 2/27/2012 Date We hereby recommend that the dissertation prepared under our supervision by Amy E. -

Effects of Aircraft Noise Exposure on Heart Rate During Sleep in the Population Living Near Airports
International Journal of Environmental Research and Public Health Article Effects of Aircraft Noise Exposure on Heart Rate during Sleep in the Population Living Near Airports Ali-Mohamed Nassur 1,*, Damien Léger 2, Marie Lefèvre 1, Maxime Elbaz 2, Fanny Mietlicki 3, Philippe Nguyen 3, Carlos Ribeiro 3, Matthieu Sineau 3, Bernard Laumon 4 and Anne-Sophie Evrard 1 1 Université Lyon, Université Claude Bernard Lyon1, IFSTTAR, UMRESTTE, UMR T_9405, F-69675 Bron, France; [email protected] (M.L.); [email protected] (A.-S.E.) 2 Université Paris Descartes, APHP, Hôtel-Dieu de Paris, Centre du Sommeil et de la Vigilance et EA 7330 VIFASOM, 75004 Paris, France; [email protected] (D.L.); [email protected] (M.E.) 3 Bruitparif, the Center for Technical Assessment of the Noise Environment in the Île-de-France Region of France, 93200 Saint-Denis, France; [email protected] (F.M.); [email protected] (P.N.); [email protected] (C.R.); [email protected] (M.S.) 4 IFSTTAR, Transport, Health and Safety Department, F-69675 Bron, France; [email protected] * Correspondence: [email protected] Received: 30 October 2018; Accepted: 15 January 2019; Published: 18 January 2019 Abstract: Background Noise in the vicinity of airports is a public health problem. Many laboratory studies have shown that heart rate is altered during sleep after exposure to road or railway noise. Fewer studies have looked at the effects of exposure to aircraft noise on heart rate during sleep in populations living near airports. Objective The aim of this study was to investigate the relationship between the sound pressure level (SPL) of aircraft noise and heart rate during sleep in populations living near airports in France. -

Models of Speech Synthesis ROLF CARLSON Department of Speech Communication and Music Acoustics, Royal Institute of Technology, S-100 44 Stockholm, Sweden
Proc. Natl. Acad. Sci. USA Vol. 92, pp. 9932-9937, October 1995 Colloquium Paper This paper was presented at a colloquium entitled "Human-Machine Communication by Voice," organized by Lawrence R. Rabiner, held by the National Academy of Sciences at The Arnold and Mabel Beckman Center in Irvine, CA, February 8-9,1993. Models of speech synthesis ROLF CARLSON Department of Speech Communication and Music Acoustics, Royal Institute of Technology, S-100 44 Stockholm, Sweden ABSTRACT The term "speech synthesis" has been used need large amounts of speech data. Models working close to for diverse technical approaches. In this paper, some of the the waveform are now typically making use of increased unit approaches used to generate synthetic speech in a text-to- sizes while still modeling prosody by rule. In the middle of the speech system are reviewed, and some of the basic motivations scale, "formant synthesis" is moving toward the articulatory for choosing one method over another are discussed. It is models by looking for "higher-level parameters" or to larger important to keep in mind, however, that speech synthesis prestored units. Articulatory synthesis, hampered by lack of models are needed not just for speech generation but to help data, still has some way to go but is yielding improved quality, us understand how speech is created, or even how articulation due mostly to advanced analysis-synthesis techniques. can explain language structure. General issues such as the synthesis of different voices, accents, and multiple languages Flexibility and Technical Dimensions are discussed as special challenges facing the speech synthesis community.