D2.3.2 Monitoring Add-Ons and Visualization (Final Report)
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

SSYC in 1990?
South Shore Yacht Club SOUTH SHORE PARK MILWAUKEE, WIS. PHONE 481-2331 July 10, 1985 Randa selected for Nickel award by Bill Dreher Joining the ranks of outstanding recipients is the 1985 Al and Erv Nickel Memorial Award winner, John "Pat" Randa. The award was presented by Past Commodore Reckard at the Review of the Fleet celebration, May 8. Pat has served on numerous commit• tees at SSYC over the years and has been especially active on the House Committee in recent years. Many of the continuing improvements to our facility are a direct result of Pat's efforts. The walls and trophy case at SSYC are adorned with many awards won in power and sail competition. Unique among these awards, however, is the Nickel award which is given annually to a club Pat Randa receives congratulations on receiving tlie Nickel Award: (I to r) Rear Commodore Roger ^,.''^-^ember who has distinguished himself Petit, Past Commodore Marshall Reckard, Commodore Jim Putney and Vice Commodore Jim y contributing time, talent and energy StOllenwerk. Jim Morrill photo to SSYC. Since its inception in 1972, the award's list has become a "Who's Who" of truly dedicated members. Strube resigns Schmuhlis Junior Advisor It is members such as Pat who allow us Roger Strube has resigned his SSYC John Schmuhl will fill the Board va• to enjoy the quality club we sometines Board position and as Advisor of the cancy due to Roger Strube's resignation take for granted. Thanks Pat, for a job Junior Program effective July 1. He has until Nov. -

Austrian Trot Racing Service Linzer Gastrenntag Mit Amateurpremiere 2021 Und Insgesamt Acht Gut Besetzten Bewerben
Nr. 14/2021 – Sonntag, 02.05.2021 (Linz in Wels) Rennbeginn: 15:00 Austrian Trot Racing Service Linzer Gastrenntag mit Amateurpremiere 2021 und insgesamt acht gut besetzten Bewerben Im Internationalen des Tages profitierte Lord Brodde (Nr. 8 mit Christoph Fischer) vom späten Fehler seines schwedischen „Landsmanns“ Angle of Attack (Nr. 9 mit Gerhard Mayr) Trotz dieses Missgeschicks zum Abschluss durfte sich Champion Gerhard Mayr über ein Triple freuen führte er doch Don’t Worry zum ersten Lebenserfolg während er heuer schon mit Kiwi’s Rascal zum vierten und mit Power BMG zum dritten Jahressieg fuhr WETT-HIGHLIGHTS DES TAGES Sonntag – 02.05.2021, Wels Dreierwette-Jackpot (2.Rennen) EURO 145,00 (BRUTTO) Dreierwette-Auszahlungsgarantie (4.Rennen) EURO 350,00 (NETTO) Dreierwette-Jackpot (7.Rennen) EURO 210,00 (BRUTTO) Einleitung Liebe Newsletter-Leser, herzlich Willkommen zur 14. Ausgabe der Austrian Trot Racing Service. Der Linzer Traberzucht- und Rennverein gastiert heuer erstmals in der Welser Messestadt und hat ebenso wie die Welser selbst wieder eine acht Rennen umfassende Tageskarte auf die Beine gestellt. Erstmals heuer findet ein Amateurbewerb statt, da diese Gruppe von der Regierung als Leistungs- bzw. Spitzensport angesehen wird. Wie üblich enthalten sind der Wett-Teil mit den Bahnspezialisten sowie die Statistiken zum Renntag. Ich wünsche viel Spaß beim Ausarbeiten und Lesen dieser Ausgabe. Euer Alex Sokol 1.Rennen – 2100 Meter (Autostart) – Startzeit: 15:00 Startet Kiwi’s Take Five gleich siegreich in seine Karriere? Kiwi’s Take Five (6) legte eine flotte Zeit im Probelauf hin und kann gleich beim Lebensdebüt zu Siegerehren gelangen. Isaac Mo (5) präsentierte sich beim Lebensdebüt mit Rang vier von guter Seite und sollte durch dieses Rennen gefördert diesmal unter den ersten Drei zu finden sein. -

Rebel Industries Incorpora Ted Means Unvarying High Standards In
REBEL INDUSTRIES - INCORPORA TED MANUFACTURERS OF REBEL 16 RASCAL 14 SLIPPER 12 SURF SAILER 14 DISTR IBUTORS FOR PORTAGER22 BLUE STAR 16 Rebel Industries apologizes for the lack of pretty girls ... sparkling waves ... and billowing sails in these pictures. It was late fall 1974 whEmwe acquired Ray Greene Co. and bathing suit weather was long gone. This brochure will only show hull and cock pit line s and point out special features of each design in the Rebel Industires line. We will take the pretty . pictures this summer. REBEL INDUSTRIES INC. 3506 SCHEELE DRIVE JACKSON, MICHIGAN 49202 517·783·2317 Rebel Industries is a new company owned and operated by seasoned sailors and manufacturers. The owner - management - director team of Rebel Industires represents an aggregate of 89 years of small boat racing and a cumula• tive 127 years of successful business and manufacturing expe rie nce . PRESIDENT HARRY MElliNG REBEL SA IlOR VICE PRESIDENT JOHN P. CAMPBEll REBEL SAilOR PASTCOMMODORE OF NATIONAL REBEL ASSOCIATION SECRETARY MELVIN SKUTT C.P.A. TREASURER ROBERT D. SMITH REBEL SAilOR GENERAL MANAGER J 1M JORDON REBEL SAilOR PRODUCTION MANAGER DON ROBINSON REBEL SAilOR SALES MANAGER GEORGE CARR REBEL SAilOR THREE TIME NATIONAL CHAMPION We offer you a complete line of fiberglas sailboats all of which are built to racing standards ... which is to say: We build our boats first for the water• and second for the showroom (a close second). Our products are sport boats. The whole reason for their existance is enjoyment - fun - sport • joy - thrills - the general good of body and soul on the sparkling water. -

Centerboard Classes NAPY D-PN Wind HC
Centerboard Classes NAPY D-PN Wind HC For Handicap Range Code 0-1 2-3 4 5-9 14 (Int.) 14 85.3 86.9 85.4 84.2 84.1 29er 29 84.5 (85.8) 84.7 83.9 (78.9) 405 (Int.) 405 89.9 (89.2) 420 (Int. or Club) 420 97.6 103.4 100.0 95.0 90.8 470 (Int.) 470 86.3 91.4 88.4 85.0 82.1 49er (Int.) 49 68.2 69.6 505 (Int.) 505 79.8 82.1 80.9 79.6 78.0 A Scow A-SC 61.3 [63.2] 62.0 [56.0] Akroyd AKR 99.3 (97.7) 99.4 [102.8] Albacore (15') ALBA 90.3 94.5 92.5 88.7 85.8 Alpha ALPH 110.4 (105.5) 110.3 110.3 Alpha One ALPHO 89.5 90.3 90.0 [90.5] Alpha Pro ALPRO (97.3) (98.3) American 14.6 AM-146 96.1 96.5 American 16 AM-16 103.6 (110.2) 105.0 American 18 AM-18 [102.0] Apollo C/B (15'9") APOL 92.4 96.6 94.4 (90.0) (89.1) Aqua Finn AQFN 106.3 106.4 Arrow 15 ARO15 (96.7) (96.4) B14 B14 (81.0) (83.9) Bandit (Canadian) BNDT 98.2 (100.2) Bandit 15 BND15 97.9 100.7 98.8 96.7 [96.7] Bandit 17 BND17 (97.0) [101.6] (99.5) Banshee BNSH 93.7 95.9 94.5 92.5 [90.6] Barnegat 17 BG-17 100.3 100.9 Barnegat Bay Sneakbox B16F 110.6 110.5 [107.4] Barracuda BAR (102.0) (100.0) Beetle Cat (12'4", Cat Rig) BEE-C 120.6 (121.7) 119.5 118.8 Blue Jay BJ 108.6 110.1 109.5 107.2 (106.7) Bombardier 4.8 BOM4.8 94.9 [97.1] 96.1 Bonito BNTO 122.3 (128.5) (122.5) Boss w/spi BOS 74.5 75.1 Buccaneer 18' spi (SWN18) BCN 86.9 89.2 87.0 86.3 85.4 Butterfly BUT 108.3 110.1 109.4 106.9 106.7 Buzz BUZ 80.5 81.4 Byte BYTE 97.4 97.7 97.4 96.3 [95.3] Byte CII BYTE2 (91.4) [91.7] [91.6] [90.4] [89.6] C Scow C-SC 79.1 81.4 80.1 78.1 77.6 Canoe (Int.) I-CAN 79.1 [81.6] 79.4 (79.0) Canoe 4 Mtr 4-CAN 121.0 121.6 -

2018 Charity Boat Auction Inventory Thank You for Your Generous
Thank you for your generous support of the Chesapeake Bay Maritime Museum ! 2018 Charity Boat Auction Inventory INV # DESCRIPTION TYPE MACGREGOR 26. 1987. Iconic trailerable weekender w/ 9.9 hp Honda 4 stroke o/b motor and good tandem axle 5009 untitled storage trailer. Fantastic bay and inland cruiser for most anywhere you can haul and launch her. Sea Sail of Cortez anyone ? Untitled storage trailer included. MD 6620 CH. CURRENT DESIGNS FITNESS KAYAK. Freedom model. 18 ft. long and 21 3/4 beam. Only 33 lbs. ! Kevlar 5019 construction with rudder and adjustable seat. As new condition . No paddle. Untitled, unregistered smallcraft not Paddle intended for motorization. AMF SUNFISH. 1969 Original owner boat used exclusively on fresh water lake in PA. Green stripe and splash 5031 guard. Well cared for and complete boat ready for more fun. Everyone loves a Sunfish. Why not treat yourself or Sail your kids to one. Untitled, unregistered smallcraft not intended for motorization. MISTRAL WINDSURFER. Really nice condition! Mast, boom, two sails (one brand new!), and sailbag included. 5038 Sail Untitled, unregistered smallcraft. BOMBARDIER SEADOO CHALLENGER 1800. 1997 twin Rotax water jet sport boat with bimini top. Motors need 5045 attention / replacement, jet pumps appear sound. Good project / parts boat, or buy it for the very nice galvanized, Power titled Sea Doo trailer. MD 3421 BJ. CAPE COD SENIOR KNOCKABOUT. Beautiful 23 ft. Spaulding Dunbar design built by Cape Cod Shipbuilding 1940's. Graceful c/b sloop with large cockpit and simple rig. Quite similiar to a Sakonnet 23 with a counter stern, W Class 22, Hodgon 21, etc.. -

Addendum to Rfp Documents
Town of Davie, Florida Purchasing Division (954) 797-1016 ADDENDUM TO RFP DOCUMENTS SOLICITATION RFP No. RM-20-96 Solid Waste and Recycling Collection 2:00 PM EST ADDENDUM No. 5 RFP DUE DATE ON 10/16/2020 TODAY’S DATE 9/25/2020 To All Proposers: This addendum is issued to modify the previously issued solicitation documents and/or given for informational purposes and is hereby made a part of the solicitation documents. Please attach this addendum to the documents in your possession and acknowledge receipt of this addendum in the space provided. A. Page Replacement: Page 65 “Town of Davie Proposal Bond” is hereby replaced as Page 65(a) and is available in this addendum. Proposers shall use page 65(a) in their proposal packages. B. Attachments available in this addendum: Davie Customer Commercial List 09.16.2020 Davie Customer Roll Off List 09.16.2020 C. RFI responses are listed below. Reviewed by: -------------------------------------- Procurement Coordinator Purchasing Division 6591 Orange Drive Davie, FL 33314 954-797-1016 [email protected] Town of Davie RFP# RM-20-96 TOWN OF DAVIE PROPOSAL BOND KNOW ALL MEN BY THESE PRESENTS, that we: _______________________________________________________________ (the ”Principal”), and ______________________________________________________________(the “Surety”), a corporation authorized to do business as a surety in the State of Florida, bind ourselves, our heirs, executors, administrators, successors and assigns, jointly and severally and firmly by these presents in the full and just sum of _________________________________________ Dollars ($ _______________) good and lawful money of the United States of America, to be paid upon demand of the Town of Davie, Florida. -
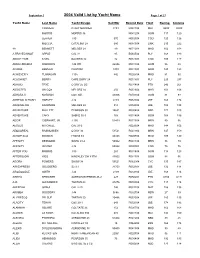
Valid List by Yacht Name Page 1 of 27
September 26, 2004 2004 Valid List by Yacht Name Page 1 of 27 Yacht Name Last Name Yacht Design Sail Nbr Record Date Fleet Racing Cruising CORREIA O DAY MARINER 3181 R041104 MAT U294 U300 MORRIS MORRIS 36 N041204 GOM 117 120 LEAVER J 80 670 N052304 COD 120 126 MOCCIA CATALINA 28 680 N081504 LWK 210 222 49 BENNETT MELGES 24 49 N071204 MHD 102 108 A FRAYED KNOT APPLE CAL 31 85 B060504 PLY 168 183 ABOUT TIME KIVEL BAVARIS 42 42 R051604 COD 105 117 ABRACADABRA KNOWLES J 44 WK 42846 R081504 GOM 36 48 ACADIA KEENAN CUSTOM 1001 R041304 GOM 123 123 ACHIEVER V FLANAGAN J 105 442 R020704 MHD 81 90 ACUSHNET BERRY CAPE DORY 28 R051604 PLY 225 237 ADAGIO FRYE O DAY 25 CB R031404 PTS 246 261 ADDICTED WILCOX MELGES 24 456 R051604 MHD 102 108 ADHARA II NORMAN C&C 34R 43006 R050304 GOM 81 93 ADRENALIN RUSH HARVEY J 24 4139 R052304 JBE 168 174 ADRENALINE KOOPMAN MELGES 24 514 R052304 JBE 102 108 ADVENTURE MALLETT PEARSON 30 14681 R030404 NBD 171 183 ADVENTURE CARY SABRE 30-3 168 R031404 GOM 168 186 AEGIR GIERHART, JR. J 105 51439 R071804 MRN 90 96 AEOLUS MITCHELL CAL 33-2 R022304 MHD 144 156 AEQUOREAL RASMUSSEN O DAY 34 51521 R041904 MRN 147 159 AEROPHILIA BENNER FRERS 33 42328 R020704 MHD 108 120 AFFINITY DESMOND SWAN 48-2 50922 R041104 MRN 36 39 AFFINITY IACONO J 42 50922 R080904 COD 75 75 AFTER YOU MORRIS J 80 261 R031404 GOM 114 123 AFTERGLOW WEG HINCKLEY SW 43TM 43602 R041304 GOM 84 96 AGORA POWERS SHOW 34 50521 R062004 CYC 135 147 AIR EXPRESS GOLDBERG S2 9.1 31753 R052304 JBE 132 144 AIRODOODLE SMITH J 24 2109 R052304 JBE 168 174 AIRTHA SPIECKER -

Fasig-Tipton
Hip No. Consigned by Monhill Farm LLC, Agent II 1 Chestnut Colt Raise a Native Mr. Prospector . { Gold Digger Dance Brightly . Danzig { Dance Smartly . { Classy ’n Smart Chestnut Colt . Northern Dancer March 31, 2003 Imperial Fling . { Royal Dilemma {Obsession for Gold . Nodouble (1990) { No Gold Lace . { Dynamator By DANCE BRIGHTLY (1995), black type-placed wnr. Sire of 3 crops, including 2-year-olds of 2004, 81 winners, $3,321,132, including Tuff Justice (2 wins in 4 starts at 2, 2004, $46,500, Winnipeg Fut- urity S., etc.), black type-pld Mr. Whitestone (to 4, 2004, $254,- 784), Samantha B. (to 4, 2004, $190,445), Dance Engagement, etc. 1st dam Obsession for Gold, by Imperial Fling. 12 wins, 2 to 7, $145,094, 2nd Clasico Santiago Iglesias Pantin. Dam of 4 foals of racing age, including a 2-year-old of 2004, three to race, 2 winners-- Manny’s Gold Maker (f. by Gone for Real). 2 wins at 2, $58,200, 3rd Kindergarten S. [L] (PHA, $8,250). How Long (c. by Jules). Winner in 2 starts at 3, 2004, $24,737. 2nd dam NO GOLD LACE, by Nodouble. Placed at 3. Dam of 3 foals, 2 winners-- Obsession for Gold (f. by Imperial Fling). Black type-placed winner, see above. Linda’s Gold. 8 wins, 2 to 6, $39,735. 3rd dam DYNAMATOR, by Decimator. Placed at 2. Dam of 4 foals, 3 winners, incl.-- Etoile de Feu. 13 wins, 4 to 8, $151,073, 2nd Atlantic City Sprint S. [L] (ATL, $10,000), Rosenna S. (DEL, $6,750), 3rd Park Heights H. -

2013 Benefit Auction List of Donated Items
2013 Benefit Auction List of Donated Items Key: A: Antiques D: Decorative Items E: Electronics FB: Fashion & Beauty GC: Gift Certificates H: Household HC: Handcrafted Items M: Miscellaneous O: Office R: Restaurant SR: Sports & Recreation TLG: Tools, Lawn & Last Updated: Garden August 19th, 2013 V: Vehicles & Care Code Item Donated By A Treadle Sewing Machine A 3 Cases Coke Bottles A Small Antique Dresser A Antique Jenny Lind 3/4 Bed A 2 Antique Gold Chairs A Antique Ironing Board A Antique Red Bed Frame & Boards A Antique Rod Iron Table with Glass Top A 45's Records D Wall Hanging "In His Light" D 7 Piece Christmas Village D 24 piece Crystal Dishes D Goldware serving pieces D Shirley Temple - "Heidi" Doll, Plate & Figurine D Shirley Temple - "The Little Colonel" Plate & Figurine D Shirley Temple - "Baby Take a Bow" Plate & Figurine D Shirley Temple - "Wee Willie Winkie" Plate & Figurine D S. T. - "Rebecca of Sunnybrook Farm" Plate & Figurine D Shirley Temple - "Bright Eyes" - Plate & Figurine D Shirley Temple - "Little Miss Marker" - Plate & Figurine D Shirley Temple - "Curly Top" - Plate & Figurine D Shirley Temple - "Glad Rags to Riches" - Doll D Shirley Temple - "Captain Jane" - Plate & Figurine D Fall Wreath Designs by Vogts D Heart Shaped Floral Arrangement ($75 value) Chicago Pike Florist D 503 bottles of hot sauce D Christmas Trees D Home Interior Pictures D Entire Christmas Village Dept 57 D Christmas Musical Turn Table - Nativity D Shirley Temple"Stand Up & Cheer" Doll, Plate & Figurine D Shirley Temple "Poor Little Rich Girl" -
Mainsail Insignia Guide - Page 1
Mainsail Insignia Guide - Page 1 210 420 470 505 Abbott 22 Able 20 Aero B Alajuela 33 Albacore Alberg 22 Alberg 30 Alberg Daystar Albin Albin Alpha Albin Ballard Alb Express Alb Vega Alden 100 Allegra Allied 3X Allmand 23 Aloha Alpha Cat Alpha Sailboard Amazon Pilot Mainsail Insignia Guide - Page 2 Ansa Aphrodite 101 Apollo Appledore Pod Aqua Cat Aquarius 21 Aquarius Pilot Arpege Artena 33 Atlantic City Atlantic Sloop Avance Baba 30 Bahama Sandpiper Balboa 20 Banshee Barbarian Barberis Show Bay Hen Bay Tiger Bayfield BB 10-Meter Beachcomber Beetle Cat Beneteau Mainsail Insignia Guide - Page 3 Benford 30 Beverly BIC Dufour Birchminster 27 Blackwatch Block Island 40 Blue Jay Bluejacket 23 BlueNose Blue Ocean 42 Bombay Bowman Bristol 19 Bristol Channel Buccaneer Cutter Buccaneer Bulls Eye Buttercup Butterfly C Scow Chrysler Cabo Rico Cal 20 Cal 36 Caliber Camelot Mainsail Insignia Guide - Page 4 Cape Cod Cape Dory 25 Cape Dory Capri 14 Catalina Cat Typhoon Capri 22 Carib Dory Cascade Catalina 25 Catfisher Cay Celebrity Celere Celestial Challenger 32 Cheetah Cat Cherubini 44 Chien Yu Christina 46 Chrysler 20 CL 11 Clark 31 Clipper MK21 CMS 41 Columbia Comanche Mainsail Insignia Guide - Page 5 Comet Comfort 34 Comfort 36 Com-Pac 27 Compis Concordia Contessa Contessa 26 Contest 36 Corbin 39 Yawl Cormorant Cornish Cornish Coronado Cove Crabber MKII Shrimper Crealock 34 Crealock 37 Creekmore 23 Cross Cruising World Trimarans Offshore Crystal Cat CS CSY CT Curtis Hawk Mainsail Insignia Guide - Page 6 Cyclone Cygnet 48 Cygnus Dana 24 D and M Dawson -

North American Portsmouth Yardstick Table of Pre-Calculated Classes
North American Portsmouth Yardstick Table of Pre-Calculated Classes A service to sailors from PRECALCULATED D-PN HANDICAPS CENTERBOARD CLASSES Boat Class Code DPN DPN1 DPN2 DPN3 DPN4 4.45 Centerboard 4.45 (97.20) (97.30) 360 Centerboard 360 (102.00) 14 (Int.) Centerboard 14 85.30 86.90 85.40 84.20 84.10 29er Centerboard 29 84.50 (85.80) 84.70 83.90 (78.90) 405 (Int.) Centerboard 405 89.90 (89.20) 420 (Int. or Club) Centerboard 420 97.60 103.40 100.00 95.00 90.80 470 (Int.) Centerboard 470 86.30 91.40 88.40 85.00 82.10 49er (Int.) Centerboard 49 68.20 69.60 505 (Int.) Centerboard 505 79.80 82.10 80.90 79.60 78.00 747 Cat Rig (SA=75) Centerboard 747 (97.60) (102.50) (98.50) 747 Sloop (SA=116) Centerboard 747SL 96.90 (97.70) 97.10 A Scow Centerboard A-SC 61.30 [63.2] 62.00 [56.0] Akroyd Centerboard AKR 99.30 (97.70) 99.40 [102.8] Albacore (15') Centerboard ALBA 90.30 94.50 92.50 88.70 85.80 Alpha Centerboard ALPH 110.40 (105.50) 110.30 110.30 Alpha One Centerboard ALPHO 89.50 90.30 90.00 [90.5] Alpha Pro Centerboard ALPRO (97.30) (98.30) American 14.6 Centerboard AM-146 96.10 96.50 American 16 Centerboard AM-16 103.60 (110.20) 105.00 American 17 Centerboard AM-17 [105.5] American 18 Centerboard AM-18 [102.0] Apache Centerboard APC (113.80) (116.10) Apollo C/B (15'9") Centerboard APOL 92.40 96.60 94.40 (90.00) (89.10) Aqua Finn Centerboard AQFN 106.30 106.40 Arrow 15 Centerboard ARO15 (96.70) (96.40) B14 Centerboard B14 (81.00) (83.90) Balboa 13 Centerboard BLB13 [91.4] Bandit (Canadian) Centerboard BNDT 98.20 (100.20) Bandit 15 Centerboard -

Page 1 by BANKER's GOLD (1994), $461,420, Tom Fool H. [G2
Hip No. Consigned by Leprechaun Racing, Agent 1 Gray or Roan Colt Mr. Prospector Forty Niner . { File Banker’s Gold . Nijinsky II { Banker’s Lady . Gray or Roan Colt { Impetuous Gal Majestic Prince April 21, 2001 Majestic Light . { Irradiate {I Love Jazz . Northern Jove (1997) { Northern Jazz . { Just Jazz By BANKER’S GOLD (1994), $461,420, Tom Fool H. [G2], Peter Pan S. [G2], 2nd Metropolitan H. [G1], etc. His first foals are 3-year-olds of 2003. Sire of 14 winners, $656,697, including Mr. Decatur (to 3, 2003, $139,375, Borderland Derby, etc.), Jenny’s Prospector ($87,855, Hoosier Debutante S., etc.), black type-placed Sockitaway ($48,964). 1st dam I LOVE JAZZ, by Majestic Light. Placed at 2. Sister to Majestic Jazz. This is her first foal. 2nd dam NORTHERN JAZZ, by Northern Jove. 3 wins at 3, $38,704, Sardonyx S., 2nd Landaluce Visitation S., Imp Visitation S.-R, 3rd Florida Oaks-L. Dam of 5 winners, including-- Majestic Jazz (g. by Majestic Light). 13 wins, 2 to 7, $211,136, 2nd Royal Glint S. (HAW, $8,273), 3rd Garden State S. (GS, $4,400). Newport Jazz. Winner at 2, $31,510. Freddie’s Day. 2 wins at 3, $25,274. Tuscan Tune. Placed at 2 and 3, $11,335. Dam of 4 winners, including-- ITSARAHYTUNE (g. by Rahy). 9 wins, 3 to 5, placed at 7, 2002 in Hong Kong, Centenary Cup twice, 2nd Centenary Sprint Cup, etc. Wopping (f. by Prenup). 3 wins at 2 and 3, 2002, $147,425, 2nd Nassau County Breeders’ Cup S.