Adversarial Synthesis of Drum Sounds
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Percussion Family 1 Table of Contents
THE CLEVELAND ORCHESTRA WHAT IS AN ORCHESTRA? Student Learning Lab for The Percussion Family 1 Table of Contents PART 1: Let’s Meet the Percussion Family ...................... 3 PART 2: Let’s Listen to Nagoya Marimbas ...................... 6 PART 3: Music Learning Lab ................................................ 8 2 PART 1: Let’s Meet the Percussion Family An orchestra consists of musicians organized by instrument “family” groups. The four instrument families are: strings, woodwinds, brass and percussion. Today we are going to explore the percussion family. Get your tapping fingers and toes ready! The percussion family includes all of the instruments that are “struck” in some way. We have no official records of when humans first used percussion instruments, but from ancient times, drums have been used for tribal dances and for communications of all kinds. Today, there are more instruments in the percussion family than in any other. They can be grouped into two types: 1. Percussion instruments that make just one pitch. These include: Snare drum, bass drum, cymbals, tambourine, triangle, wood block, gong, maracas and castanets Triangle Castanets Tambourine Snare Drum Wood Block Gong Maracas Bass Drum Cymbals 3 2. Percussion instruments that play different pitches, even a melody. These include: Kettle drums (also called timpani), the xylophone (and marimba), orchestra bells, the celesta and the piano Piano Celesta Orchestra Bells Xylophone Kettle Drum How percussion instruments work There are several ways to get a percussion instrument to make a sound. You can strike some percussion instruments with a stick or mallet (snare drum, bass drum, kettle drum, triangle, xylophone); or with your hand (tambourine). -

Quantum Leap Stormdrum 3 Manual
Quantum Leap Stormdrum 3 Virtual Instrument Users’ Manual QUANTUM LEAP STORMDRUM 3 VIRTUAL INSTRUMENT The information in this document is subject to change without notice and does not rep- resent a commitment on the part of East West Sounds, Inc. The software and sounds described in this document are subject to License Agreements and may not be copied to other media. No part of this publication may be copied, reproduced or otherwise transmitted or recorded, for any purpose, without prior written permission by East West Sounds, Inc. All product and company names are ™ or ® trademarks of their respective owners. Solid State Logic (SSL) Channel Strip, Transient Shaper, and Stereo Compressor licensed from Solid State Logic. SSL and Solid State Logic are registered trademarks of Red Lion 49 Ltd. © East West Sounds, Inc., 2013. All rights reserved. East West Sounds, Inc. 6000 Sunset Blvd. Hollywood, CA 90028 USA 1-323-957-6969 voice 1-323-957-6966 fax For questions about licensing of products: [email protected] For more general information about products: [email protected] http://support.soundsonline.com ii QUANTUM LEAP STORMDRUM 3 VIRTUAL INSTRUMENT 1. Welcome 2 About EastWest and Quantum Leap 3 Producer: Nick Phoenix 4 Percussionist: Mickey Hart 5 Credits 6 How to Use This and the Other Manuals 7 Online Documentation and Other Resources Click on this text to open the Master Navigation Document 1 QUANTUM LEAP STORMDRUM 3 VIRTUAL INSTRUMENT Welcome About EastWest and Quantum Leap Founder and producer Doug Rogers has over 35 years experience in the audio industry and is the recipient of many recording industry awards including “Recording Engineer of the Year.” In 2005, “The Art of Digital Music” named him one of “56 Visionary Artists & Insiders” in the book of the same name. -

African Drumming in Drum Circles by Robert J
African Drumming in Drum Circles By Robert J. Damm Although there is a clear distinction between African drum ensembles that learn a repertoire of traditional dance rhythms of West Africa and a drum circle that plays primarily freestyle, in-the-moment music, there are times when it might be valuable to share African drumming concepts in a drum circle. In his 2011 Percussive Notes article “Interactive Drumming: Using the power of rhythm to unite and inspire,” Kalani defined drum circles, drum ensembles, and drum classes. Drum circles are “improvisational experiences, aimed at having fun in an inclusive setting. They don’t require of the participants any specific musical knowledge or skills, and the music is co-created in the moment. The main idea is that anyone is free to join and express himself or herself in any way that positively contributes to the music.” By contrast, drum classes are “a means to learn musical skills. The goal is to develop one’s drumming skills in order to enhance one’s enjoyment and appreciation of music. Students often start with classes and then move on to join ensembles, thereby further developing their skills.” Drum ensembles are “often organized around specific musical genres, such as contemporary or folkloric music of a specific culture” (Kalani, p. 72). Robert Damm: It may be beneficial for a drum circle facilitator to introduce elements of African music for the sake of enhancing the musical skills, cultural knowledge, and social experience of the participants. PERCUSSIVE NOTES 8 JULY 2017 PERCUSSIVE NOTES 9 JULY 2017 cknowledging these distinctions, it may be beneficial for a drum circle facilitator to introduce elements of African music (culturally specific rhythms, processes, and concepts) for the sake of enhancing the musi- cal skills, cultural knowledge, and social experience Aof the participants in a drum circle. -

Basic Snare Drum Tuning
Basic Snare Drum Tuning by Tom Freer Please follow these simple and basic instructions for tuning and adjusting your Pearl snare drum. In order for you to get and maintain the best possible sound out of your instrument, it will be important to save this sheet so that you can "tune up" the drum as the heads become broken in, and replace heads when necessary. YOU WILL NEED THE FOLLOWING TOOLS TO PROCEED: 1. DRUM KEY 2. RULER STEP ONE: Loosen the top head completely. Place the drum on a flat surface and unscrew all the tension rods so that there is no tension on the top head. You don't need to take them out, just loosen them all the way. Next, begin to tighten down each rod just until they touch the counter hoop (or rim) WITHOUT PULLING IT DOWN. Just screw the tension rod down until it just touches. Go across the drum and do the same to the opposite tension rod and repeat, always working across the drum head in opposites, this keeps the head very even. When all the tension rods are seated and just touching the counter hoop, take your ruler and beginning with the tension rod directly beside the strainer, measure the distance from underneath the counter hoop to the top of the lug. Repeat this process with the lug directly across the drum and repeat until all measurements are the same. Remember we are not concerned with how tight the head is right now, just how even the tension is. Now that the head is evenly tensioned, bring the top head up to pitch. -

2006 Adams Timpani and Mallet Catalog
Adams Soft Cases & Accessories Trust the safety of your prized instruments to the feature 8 soft bags sets, the 4.3 octave marimbas bags feature company that knows them best, Adams. Each cover 6 soft bag sets, and the 4.0 or 3.5 octave xylophone bags and bag is designed to fit perfectly and securely to feature 3 soft bags sets. These bags are the perfect ensure years of service. Our Marimba soft bags instrument compliment and enable the performer to protect compliment the unique breakdown design of all Adams their instrument during transport. Voyager Frames. The 5.0 and 4.6 octave marimba bags Timpani and Mallet Instruments Long Timpani Cover Short Timpani Cover PM-100 Timpani Key MLBK Chime Mallet Universal Timpani Soft Bag Marimba Soft Bags Product and specifications are subject to change without notice. ©Copyright 2006. Printed in the U.S. Adams Percussion Instruments are proudly distributed in the U.S. by Pearl Corporation. For more information contact any Pearl Educational Percussion Dealer, or write to Pearl Corporation, 549 Metroplex Drive, Nashville, TN 37211. Adams Percussion Instruments can also be found on the web at www.pearldrum.com ITEM # ADM106 THE SOUND OF QUALITY Philharmonic Light Timpani Cloyd Duff Model Dresden Style Original Berlin Style Philharmonic Light Timpani Philharmonic Light Timpani dams Philharmonic Light Timpani represent the ultimate expression of quality in timpani sound and design. Two he classic European style of the Adams Frame, in combination with the latest computer aided machine technology, distinct models are available, distinguished by a choice between our original Berlin style pedal, or our Cloyd results in timpani frame construction that is unmatched in precision, quality and attention to detail. -

MP-Price-List-2020-EUR.Pdf
PRICE LIST 2020 EURO Model Description Price PICKUP PICKUP INSTRUMENTS NEW MPDS1 digital percussion stomp box 199,00 € NEW MPS1 analog percussion stomp box 89,00 € NEW MPSM stomp box mount 49,90 € FX10 fx pedal 169,00 € PBASSBOX pickup bassbox 129,00 € PSNAREBOX pickup snarebox 119,00 € NEW MIC-PERC percussion microphone 24,90 € KA9P-AB pickup kalimba, african brown 99,90 € PICKUP CAJONS NEW PAESLDOB artisan edition pickup cajon, solea line 299,00 € PWCP100MB pickup cajon, woodcraft professional, makah-burl frontplate 199,00 € PSC100B pickup cajon, snarecraft, baltic birch frontplate 149,00 € PSUBCAJ6B pickup vertical subwoofer cajon, baltic birch 249,00 € PTOPCAJ2WN pickup slaptop cajon, turbo, walnut playing surface 189,00 € PTOPCAJ4MH-M pickup slaptop cajon, mahogany playing surface 149,00 € NEW PBASSCAJ-KIT cocktail cajon kit 499,00 € NEW PBASSCAJ cocktail cajon 169,90 € NEW PBC1B pickup bongo cajon 79,90 € NEW PCST pickup cajon snare tap 74,90 € NEW PCTT pickup cajon tom tap 69,90 € NEW MMCS mini cajon speaker 59,90 € PA-CAJ cajon preamp 99,00 € NEW CMS cajon microphone stand 9,90 € CAJONS ARTISAN EDITION CAJONS AEMLBI martinete line, brazilian ironwood with ukola woodframe frontplate 1.199,00 € AEFLIH fandango line, indian heartwood frontplate 699,00 € AESELIH seguiriya line, indian heartwood frontplate 469,00 € AESELCB seguiriya line, canyon-burl frontplate 469,00 € AECLWN cantina line, walnut frontplate 499,00 € AEBLLB buleria line, lava-burl frontplate 299,00 € AEBLMY buleria line, mongoy frontplate 299,00 € AESLEYB soleà line, -

Instrument: Tabla, Classical Kettledrums for Meditation Country
ROOTS OF RHYTHM - CHAPTER 14: THE TABLA FROM INDIA Instrument: Tabla, classical kettledrums for meditation Country: India Flag: The flag has three equal horizontal bands with saffron, a subdued orange, on the top, white in the middle, and green at the bottom. A blue chakra (sha-krah) or 24-spoked wheel is centered in the white band. Size and Population: The country has an area of 179,744 square miles with 1,858,243 square miles of land surface and 196,500 square miles of water. India has 4375 miles of coastline and is slightly more than one- third the size of the US. The population of India is estimated at 1,220,800,359 as of July 2013; ranked 2nd in the world. Geography and Climate: India’s landscape contains great variety including a desert, tropical forests, lowlands, mighty rivers, fertile plains and the world’s highest mountain ranges, the Himalayas. With the enormous wall of the Himalayas on the north, the triangular-shaped subcontinent of India borders the Bay of Bengal to the east, the Arabian Sea to the west, and the India Ocean to the south. From the Chinese border on the north, India extends 2000 miles to its southern tip, where the island nation of Sri Lanka is located. Going northeast of the Himalaya mountain range, India’s borders constrict to a small channel that passes between Nepal, Tibet, Bangladesh, and Bhutan, then spreads out again to meet Burma in an area called the “eastern triangle.” India’s western border is with Pakistan. India has three main land regions: the Himalaya, the Northern Plains, and the Deccan or Southern Plateau. -

Reason Drum Kits Operation Manual
REASON DRUM KITS OPERATION MANUAL The information in this document is subject to change without notice and does not represent a commitment on the part of Propellerhead Software AB. The software described herein is subject to a License Agreement and may not be copied to any other media except as specifically allowed in the License Agreement. No part of this publication may be copied, reproduced or otherwise transmitted or recorded, for any purpose, without prior written permission by Propellerhead Software AB. ©2019 Propellerhead Software and its licensors. All specifications subject to change without notice. Reason, Reason Intro, Reason Lite and Rack Extension are trademarks of Propellerhead Software. All other commercial symbols are protected trademarks and trade names of their respective holders. All rights reserved. Reason Drum Kits Introduction The Reason Drum Kits instrument is a Rack Extension version of the mighty popular Reason Drum Kits ReFill. Anyone with experience in professional studio work will tell you that recording drums is the most difficult and demanding part of any project. Hands down. Drum recording is a craft which takes decades to learn, yet never gets any easier. It's exhausting. It's expensive. It can make or break an entire production. Due to these challenging demands, the means for capturing the ultimate drum sound have always been out of reach for everyone except those who never get cold sweats from the tick tock of the studio clock. Until now. We took care of the hard part, and the result is Reason Drum Kits - a powerful and versatile drum tool that tears down the last barrier between the virtual studio workspace and the real drum recording studio, and closes the quality gap between “merely” professional and world class! Be the drummer - and the engineer! Traditionally, the structure of computer based drum tools has been dictated by the anatomy of the drum kit. -
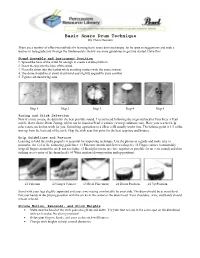
Basic Snare Drum Technique by Thom Hannum
Basic Snare Drum Technique By Thom Hannum There are a number of effective methods for learning basic snare drum technique. So be open to suggestions and seek a teacher to help guide you through the fundamentals. Below are some guidelines to get you started. Have fun! Stand Assembly and Instrument Position 1. Spread the base of the stand far enough to create a stable platform. 2. Insert the top into the base of the stand. 3. Place the drum into the basket while avoiding contact with the snare strainer. 4. The drum should be at about waist level and slightly angled for your comfort. 5. Tighten all stand wing nuts. Step 1 Step 2 Step 3 Step 4 Step 5 Tuning and Stick Selection Now it’s time to tune the drum for the best possible sound. I recommend following the steps outlined in Tom Freer’s Pearl article, Basic Snare Drum Tuning, which can be found at Pearl’s website (www.pearldrum.com). Have your teacher help select snare sticks that work for you. Something equivalent to a 2B or a 5B usually works fine. The balance point is 1/3 of the way up from the butt end of the stick. Grip the stick near this point for the best response and bounce. Grip Guidelines and Posture Learning to hold the sticks properly is essential for improving technique. Use the photos as a guide and make sure to memorize the feel of the following guidelines: #1 Fulcrum (thumb and first two fingers), #2 Finger contact (comfortably wrap all fingers around the stick; not too tight), #3 Bead placement (as close together as possible for an even sound) and then striking area (center of the drum head), #4 Wrist motion (down position and up position). -

Pandeiro 1 Pandeiro
Pandeiro 1 Pandeiro Pandeiro Other names Pandeiro, drums Classification hand percussion Playing range High sound of jingles, plus some have a skin with a lower sound. Related instruments Riq, Buben, Dayereh, Daf, Kanjira, Frame drum The pandeiro (Portuguese pronunciation: [pɐ̃ˈdejɾu]) is a type of hand frame drum. There are two important distinctions between a pandeiro and the common tambourine. The tension of the head on the pandeiro can be tuned, allowing the player a choice of high and low notes. Also, the metal jingles (called platinelas in Portuguese) are cupped, creating a crisper, drier and less sustained tone on the pandeiro than on the tambourine. This provides clarity when swift, complex rhythms are played. It is held in one hand, and struck on the head by the other hand to produce the sound. Typical pandeiro patterns are played by alternating the thumb, fingertips, heel, and palm of the hand. A pandeiro can also be shaken to make sound, or one can run a finger along the head to create a "rasp" noise. The pandeiro is used in a number of Brazilian music forms, such as Samba, Choro, Coco, and Capoeira music (see Capoeira songs). The Brazilian pandeiro derives from the pandeireta or pandereta of Spain and Portugal. Some of the best-known pandeiro players today are Paulinho Da Costa, Airto Moreira, Marcos Suzano, Cyro Baptista, and Carlinhos Pandeiro de Ouro. Artists such as Stanton Moore use it non-traditionally by tuning it low to sound like a floor tom with jingles, mounting it on a stand and integrating it into the modern drum kit. -

Relationship with Percussion Instruments
Multimedia Figure X. Building a Relationship with Percussion Instruments Bill Matney, Kalani Das, & Michael Marcionetti Materials used with permission by Sarsen Publishing and Kalani Das, 2017 Building a relationship with percussion instruments Going somewhere new can be exciting; it might also be a little intimidating or cause some anxiety. If I go to a party where I don’t know anybody except the person who invited me, how do I get to know anyone else? My host will probably be gracious enough to introduce me to others at the party. I will get to know their name, where they are from, and what they commonly do for work and play. In turn, they will get to know the same about me. We may decide to continue our relationship by learning more about each other and doing things together. As music therapy students, we develop relationships with music instruments. We begin by learning instrument names, and by getting to know a little about the instrument. We continue our relationship by learning technique and by playing music with them! Through our experiences and growth, we will be able to help clients develop their own relationships with instruments and music, and therefore be able to 1 strengthen the therapeutic process. Building a relationship with percussion instruments Recognize the Know what the instrument is Know where the Learn about what the instrument by made out of (materials), and instrument instrument is or was common name. its shape. originated traditionally used for. We begin by learning instrument names, and by getting to know a little about the instrument. -

Triangle & Tambourine
○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○ ○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○ 1 Triangle & 2001 Tambourine Rich Holly NASHVILLE NOVEMBER 14–17 ○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○ Playing percussion accessories may be some of the most gratifying performance experiences you will have. Why? Because you can be creative! Although there are time-honored traditions on how to play these instru- ments, in the last 30+ years we have seen and heard several variations on playing techniques and available sounds. Percussionists from around the world, in classical, pop, jazz, studio, and world music settings have been discovering and utilizing these other techniques with great success. It is important that you know and understand the basic playing techniques and available sounds first. These will serve you quite well in concert band, wind ensemble, and orchestral settings. Many of you will have the opportunity to play percussion in a jazz ensemble or perhaps in a band of your own. That’s where these performance variations will really come into play. These variations are based on the performance techniques of similar instruments from cultures around the world, and today’s orchestral players are finding many of these quite useful, too. The most important thing is to have fun! Try these only as a starting point – there is no limit to the use of your own creativity. Triangle When holding the triangle in a clip in the standard fashion, it is possible and often desirable to muffle the sound of the triangle with the heel and/or the fingers of the hand that is holding the clip. The following ex- ample is one way to attain a useful pattern using this technique.