Anonymity, Unobservability, Pseudonymity, and Identity Management – a Proposal for Terminology
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

1 Introduction
1 Introduction I. THE PROBLEM OF ANONYMITY NONYMOUS WRITING IS both an old and a new phenomenon. Before the Renaissance most writing was anonymous; many of the Aearly poems in anthologies are ascribed to ‘ Anon ’ . The medieval auctor (the term from which the word ‘ author ’ derives) was generally little more than a scribe, transcribing earlier texts. The name of the writer was irrelevant to the readers of a text, so it was immaterial that generally he was anonymous. 1 The identifi cation or naming of authors has been associated with the development of printing, and then subsequently with the role of copyright in ascribing property rights to them and the birth of the Romantic Author as a heroic fi gure at the end of the eighteenth century. 2 But even then a high proportion of novels were anonymous; between 1770 and 1800 over 70 per cent of novels were published without a named author, and during the 1820s the proportion rose to nearly 80 per cent. 3 There has certainly been a marked decline in anonymous writing in the late nineteenth and twentieth centuries, though some notable writers in this period have always, or sometimes, used pseudonyms (see section IV of this chapter and chapter 2 , section II), among them George Orwell (the pseudonym of Eric Blair), Sylvia Plath and Doris Lessing. The Internet is responsible for the revival of anonymous writing and indeed for many of the problems now associated with it. Many blogs are written under a pseudonym, though often the identity of the author is well known, as with Paul Staines, the author of the Guido Fawkes political blog. -

Lapp 1 the Victorian Pseudonym and Female Agency Research Thesis
Lapp 1 The Victorian Pseudonym and Female Agency Research Thesis Presented in partial fulfillment of the requirements for graduation with research distinction in English in the undergraduate colleges of The Ohio State University by Anna Lapp The Ohio State University April 2015 Project Advisor: Professor Robyn Warhol, Department of English Lapp 2 Chapter One: The History of the Pseudonym Anonymity disguises information. For authors, disguised or changed names shrouds their circumstance and background. Pseudonyms, or pen names, have been famously used to disguise one’s identity. The word’s origin—pseudṓnymon—means “false name”. The nom de plume allows authors to conduct themselves without judgment attached to their name. Due to an author’s sex, personal livelihood, privacy, or a combination of the three, the pen name achieves agency through its protection. To consider the overall protection of the pseudonym, I will break down the components of a novel’s voice. A text is written by a flesh-and-blood, or actual, author. Second, an implied author or omnipresent figure of agency is present throughout the text. Finally, the narrator relates the story to the readers. The pseudonym offers freedom for the actual author because the author becomes two-fold—the pseudonym and the real person, the implied author and the actual author. The pseudonym can take the place of the implied author by acting as the dominant force of the text without revealing the personal information of the flesh-and-blood author. Carmela Ciuraru, author of Nom de Plume: A (Secret) History of Pseudonyms, claims, “If the authorial persona is a construct, never wholly authentic (now matter how autobiographical the material), then the pseudonymous writer takes this notion to yet another level, inventing a construct of a construct” (xiii-xiv). -

Why Do People Seek Anonymity on the Internet?
Why Do People Seek Anonymity on the Internet? Informing Policy and Design Ruogu Kang1, Stephanie Brown2, Sara Kiesler1 Human Computer Interaction Institute1 Department of Psychology2 Carnegie Mellon University 5000 Forbes Ave., Pittsburgh, PA 15213 [email protected], [email protected], [email protected] ABSTRACT literature that exists mainly derives from studies of one or a In this research we set out to discover why and how people few online communities or activities (e.g., the study of seek anonymity in their online interactions. Our goal is to 4chan in [5]). We lack a full understanding of the real life inform policy and the design of future Internet architecture circumstances surrounding people’s experiences of seeking and applications. We interviewed 44 people from America, anonymity and their feelings about the tradeoffs between Asia, Europe, and Africa who had sought anonymity and anonymity and identifiability. A main purpose of the asked them about their experiences. A key finding of our research reported here was to learn more about how people research is the very large variation in interviewees’ past think about online anonymity and why they seek it. More experiences and life situations leading them to seek specifically, we wanted to capture a broad slice of user anonymity, and how they tried to achieve it. Our results activities and experiences from people who have actually suggest implications for the design of online communities, sought anonymity, to investigate their experiences, and to challenges for policy, and ways to improve anonymity tools understand their attitudes about anonymous and identified and educate users about the different routes and threats to communication. -

Freedom of Expression, Encryption, and Anonymity: Civil Society and Private Sector Perceptions
Freedom of Expression, Encryption, and Anonymity: Civil Society and Private Sector Perceptions Joint collaboration to inform the work of the UN Special Rapporteur on the promotion and protection of the right to freedom of opinion and expression Research Team World Wide Web Foundation Renata Avila Centre for Internet and Human Rights at European University Viadrina Ben Wagner Thomas Behrndt Oficina Antivigilância at the Institute for Technology and Society - ITS Rio Joana Varon Lucas Teixeira Derechos Digitales Paz Peña Juan Carlos Lara 2 About the Research In order to swiftly provide regional input for the consultation of the United Nations Special Rapporteur on the protection and promotion of the right to opinion and expression, the World Wide Web Foundation1, in partnership with the Centre for Internet and Human Rights at European University Viadrina, Oficina Antivigilância2 at the Institute for Technology and Society - ITS Rio3 in Brazil, and Derechos Digitales4 in Latin America, have conducted collaborative research on the use of encryption and anonymity in digital communications. The main goal of this initiative was to collect cases to highlight regional peculiarities from Latin America and a few other countries from the Global South, while debating the relationships within encryption, anonymity, and freedom of expression. This research was supported by Bertha Foundation.5 The core of the research was based on two different surveys focused on two target groups. The first was a series of interviews among digital and human rights organizations as well as potential users of the technologies to determine the level of awareness about both the anonymity and encryption technologies, to collect perceptions about the importance of these technologies to protect freedom of expression, and to have a brief overview of the legal framework and corporate practices in their respective jurisdictions. -

Names in Toni Morrison's Novels: Connections
INFORMATION TO USERS This manuscript has been reproduced from the microfilm master. UMI films the text directly from the original or copy submitted. Thus, some thesis and dissertation copies are in typewriter face, while others may be from any type of computer printer. The quality or this reproduction is dependent upon the quaUty or the copy submitted. Broken or indistinct print, colored or poor quality illustrations and photographs, print bleedthrough, substandard margins, and improper alignment can adversely affect reproduction. In the unlikely. event that the author did not send UMI a complete manuscript and there are missing pages, these will be noted. Also, if unauthorized copyright material had to be removed, a note will indicate the deletion. Oversize materials (e.g., maps, drawings, charts) are reproduced by sectioning the original, beginning at the upper left-hand comer and continuing from left to right in equal sections with small overlaps. Each original is also photographed in one exposure and is included in reduced form at the back of the book. Photographs included in the original manuscript have been reproduced xerographically in this copy. Higher quality 6" x 9" black and white photographic prints are available for any photographs or illustrations appearing in this copy for an additional charge. Contact UMI directly to order. UMI A. Bell & Howell Information Company 300 North Zeeb Road. Ann Arbor. Ml48106·1346 USA 313!761·4700 8001521·0600 .. -------------------- ----- Order Number 9520522 Names in Toni Morrison's novels: Connections Clayton, Jane Burris, Ph.D. The University of North Carolina at Greensboro, 1994 Copyright @1994 by Clayton, Jane Burris. -

The Anonymity Heuristic: How Surnames Stop Identifying People When They Become Trademarks
Volume 124 Issue 2 Winter 2019 The Anonymity Heuristic: How Surnames Stop Identifying People When They Become Trademarks Russell W. Jacobs Follow this and additional works at: https://ideas.dickinsonlaw.psu.edu/dlr Part of the Behavioral Economics Commons, Civil Law Commons, Comparative and Foreign Law Commons, Economic Theory Commons, Intellectual Property Law Commons, Law and Economics Commons, Law and Psychology Commons, Legal Writing and Research Commons, Legislation Commons, Other Law Commons, Phonetics and Phonology Commons, Psychiatry and Psychology Commons, Psycholinguistics and Neurolinguistics Commons, and the Semantics and Pragmatics Commons Recommended Citation Russell W. Jacobs, The Anonymity Heuristic: How Surnames Stop Identifying People When They Become Trademarks, 124 DICK. L. REV. 319 (2020). Available at: https://ideas.dickinsonlaw.psu.edu/dlr/vol124/iss2/3 This Article is brought to you for free and open access by the Law Reviews at Dickinson Law IDEAS. It has been accepted for inclusion in Dickinson Law Review by an authorized editor of Dickinson Law IDEAS. For more information, please contact [email protected]. \\jciprod01\productn\D\DIK\124-2\DIK202.txt unknown Seq: 1 28-JAN-20 14:56 The Anonymity Heuristic: How Surnames Stop Identifying People When They Become Trademarks Russell Jacobs ABSTRACT This Article explores the following question central to trade- mark law: if a homograph has both a surname and a trademark interpretation will consumers consider those interpretations as intrinsically overlapping or the surname and trademark as com- pletely separate and unrelated words? While trademark jurispru- dence typically has approached this question from a legal perspective or with assumptions about consumer behavior, this Article builds on the Law and Behavioral Science approach to legal scholarship by drawing from the fields of psychology, lin- guistics, economics, anthropology, sociology, and marketing. -

Issues in the Linguistics of Onomastics
Journal of Lexicography and Terminology, Volume 1, Issue 2 Issues in the Linguistics of Onomastics By Vincent M. Chanda School of Humanities and Social Science University of Zambia Email: mchanda@@gmail.com Abstract Names, also called proper names or proper nouns, are very important to mankind that there is no human language without names and, for some types of names, there are written or unwritten naming conventions. The social importance of names is also the reason why onomastics, the study of names, is a multidisciplinary field. After briefly discussing the multidisciplinary nature of onomastics, the article proves the following view stated and proved by many a scholar: proper names have a grammar that includes some grammatical features of common nouns. In so doing, the article shows that, like common nouns, proper names show cross linguistic differences. To prove that names do have a grammar which in some aspects differs from the grammar of common nouns, the article often compares proper names and common nouns. Furthermore, the article uses data from several languages in addition to English. After a bief discussion of orthographic differences between proper names and common nouns, the article focuses on the morphology, both inflectional and lexical, and the syntax of proper names. Key words: Name, common noun, onomastics, multidisciplinary, naming convention, typology of names, anthroponym, inflectional morphology, lexical morphology, derivation, compounding, syntac. 67 Journal of Lexicography and Terminology, Volume 1, Issue 2 1. Introduction Onomastics or onomatology, is the study of proper names. Proper names are terms used as a means of identification of particular unique beings. -

COPYRIGHT in PSEUDONYMOUS and ANONYMOUS WORKS Ronan Deazley and Kerry Patterson
COPYRIGHT IN PSEUDONYMOUS AND ANONYMOUS WORKS Ronan Deazley and Kerry Patterson 1. Introduction The use of pseudonyms has a long-standing tradition in newspaper and magazine publishing. The Economist, for example, operates a well-established practice of editorial anonymity in that all of their columnists publish under pseudonyms such as Bagehot, Lexington and Schumpeter.1 This Guidance explains what is stated in the law about the authorship of works made under a pseudonym, and about the ownership of copyright in works created both anonymously and under a pseudonym, and considers the implications these presumptions have for rights clearance projects. 2. In Practice If the name of the publisher appears How is the work credited? on the work, the publisher is It is anonymous presumed to be the owner of the copyright until there is evidence to the contrary. A pseudonym is used No The author is presumed to be the owner of the copyright – ownership Is the author commonly of copyright depends on relationship Yes known by this pseudonym? between author and publisher Ask the publisher for information on Don’t Know the author, but if they cannot provide this information, the publisher is presumed to be the copyright owner. Within the pages of the Edwin Morgan Scrapbooks examined as part of this research project, there is one letter, cut from a newspaper letters page, which has been published under a pseudonym: Navigator. In it, the writer relates the experience of seeing a mysterious ‘aircraft’/UFO over Glasgow. So, what do the legal presumptions -
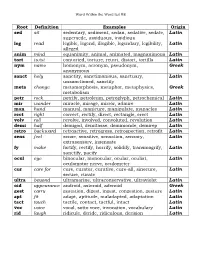
Root Definition Examples Origin Sed Sit Sedentary, Sediment, Sedan
Word Within the Word List #8 Root Definition Examples Origin sed sit sedentary, sediment, sedan, sedative, sedate, Latin supersede, assiduous, insidious leg read legible, legend, illegible, legendary, legibility, Latin alleged anim mind equanimity, animal, animated, magnanimous Latin tort twist contorted, torture, retort, distort, tortilla Latin nym name homonym, acronym, pseudonym, Greek anonymous sanct holy sanctity, sanctimonious, sanctuary, Latin unsanctioned, sanctify meta change metamorphosis, metaphor, metaphysics, Greek metabolism petr rock petrify, petroleum, petroglyph, petrochemical Latin mir wonder miracle, mirage, mirror, admire Latin man hand manual, manicure, manipulate, manacles Latin rect right correct, rectify, direct, rectangle, erect Latin volv roll revolve, involved, convoluted, revolution Latin demi half demigod, demitasse, demimonde, demirep Latin retro backward retroactive, retrogress, retrospection, retrofit Latin sens feel sense, sensitive, sensation, sensory, Latin extrasensory, insensate fy make fortify, rectify, horrify, solidify, transmogrify, Latin sanctify, pacify ocul eye binocular, monocular, ocular, oculist, Latin oculomotor nerve, oculometer cur care for cure, curator, curative, cure-all, sinecure, Latin secure, curate ultra beyond ultramarine, ultraconservative, ultraviolet Latin oid appearance android, asteroid, adenoid Greek gest carry gestation, digest, ingest, congestion, gesture Latin apt fit adapt, aptitude, maladapted, adaptation Latin tact touch tactile, contact, tactful, intact Latin voc voice vocal, sotto voce, invocation, vocabulary Latin rid laugh ridicule, deride, ridiculous, derision Latin Word Within the Word List #8 Using the context clues from the sentence and your understanding of the root, define the underlined words in the following sentences. 1. His sedentary job left him weak and out of shape. 2. The college student’s handwriting was illegible. 3. The bitter animosity made him lose his equanimity. -

Presenting Your Research: NLP Conference Submissions
Anonymity Overview Review forms Author responses Venues My assessment Titles Abstracts Style sheets Camera-ready Presenting your research: NLP conference submissions Christopher Potts Stanford Linguistics CS224u: Natural language understanding 1 / 11 Anonymity Overview Review forms Author responses Venues My assessment Titles Abstracts Style sheets Camera-ready The ACL anonymity period 1. The ACL conferences have adopted a uniform policy that submitted papers cannot be uploaded to repositories like arXiv (or made public in any way) starting one month from the submission deadline and extending through the time when decisions go out. 2. For specific conferences, check their sites for the precise date when this embargo goes into effect. 3. The policy is an attempt to balance the benefits of free and fast distribution of new ideas against the benefits of double-blind peer review. 4. For more on the policy and its rationale, see this ACL policy page. 2 / 11 Anonymity Overview Review forms Author responses Venues My assessment Titles Abstracts Style sheets Camera-ready Typical NLP conference set-up 1. You submit your paper, along with area keywords that help determine which committee gets your paper. 2. Reviewers scan a long list of titles and abstracts and then bid on which ones they want to do. The title is probably the primary factor in bidding decisions. 3. The program chairs assign reviewers their papers, presumably based in large part on their bids. 4. Reviewers read the papers, write comments, supply ratings. 5. Authors are allowed to respond briefly to the reviews. 6. The program/area chair might stimulate discussion among the reviewers about conflicts, the author response, etc. -

Defining “Anonymity” in Networked Communication, Version 1
Defining “Anonymity” in Networked Communication, version 1 Joan Feigenbaum1 Technical Report YALEU/DCS/TR-1448 December 2011 Support for anonymous communication in hostile environments is the main goal of DARPA’s “Safer Warfighter Communications” program (DARPA-BAA-10-69: SAFER). Despite the fact that the word is regularly encountered in common parlance, “anonymity” is actually a subtle concept – one that the computer-science community has worked hard (and not yet completely successfully) to define precisely. This briefing paper explains the concept of anonymity in the context of the SAFER program; it is intended for a general audience rather than for one with professional expertise in computer science and data networking. Approved for public release: distribution unlimited Keywords: Anonymity, blocking, disruption, observability, pseudonymity 1 This material is based upon work supported by the Defense Advanced Research Agency (DARPA) and SPAWAR Systems Center Pacific, Contract No. N66001- 11-C-4018. Any opinions, findings and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the Defense Advanced Research Agency (DARPA) and SPAWAR Systems Center Pacific. Defining “Anonymity” in Networked Communication Joan Feigenbaum http://www.cs.yale.edu/homes/jf/ Version 1, December 2011 Support for anonymous communication in hostile environments is the main goal of DARPA’s “Safer Warfighter Communications” program (DARPA-BAA-10-69: SAFER). Despite the fact that the word is regularly encountered in common parlance, “anonymity” is actually a subtle concept – one that the computer-science community has worked hard (and not yet completely successfully) to define precisely. -

Deliberation and Identity Rules : the Effect of Anonymity, Pseudonyms and Real-Name Requirements on the Cognitive Complexity of Online News Comments
This is a repository copy of Deliberation and Identity Rules : The Effect of Anonymity, Pseudonyms and Real-Name Requirements on the Cognitive Complexity of Online News Comments. White Rose Research Online URL for this paper: http://eprints.whiterose.ac.uk/153279/ Version: Accepted Version Article: Moore, Alfred James orcid.org/0000-0002-7252-5039, Fredheim, Rolf, Wyss, Dominik et al. (1 more author) (2020) Deliberation and Identity Rules : The Effect of Anonymity, Pseudonyms and Real-Name Requirements on the Cognitive Complexity of Online News Comments. Political Studies. pp. 1-21. ISSN 0032-3217 https://doi.org/10.1177/0032321719891385 Reuse Items deposited in White Rose Research Online are protected by copyright, with all rights reserved unless indicated otherwise. They may be downloaded and/or printed for private study, or other acts as permitted by national copyright laws. The publisher or other rights holders may allow further reproduction and re-use of the full text version. This is indicated by the licence information on the White Rose Research Online record for the item. Takedown If you consider content in White Rose Research Online to be in breach of UK law, please notify us by emailing [email protected] including the URL of the record and the reason for the withdrawal request. [email protected] https://eprints.whiterose.ac.uk/ Deliberation and Identity Rules: The Effect of Anonymity, Pseudonyms, and Real-name Requirements on the Cognitive Complexity of Online News Comments Alfred Moore, Politics, University of York Rolf E. Fredheim, NATO Strategic Communications Centre of Excellence, Riga Dominik Wyss, Politikwissenschaft, University of Stuttgart Simon Beste, Social Sciences, Goethe University, Frankfurt [Version accepted for publication by Political Studies on 6 Nov 2019.] Introduction Does anonymity — the ability to act publicly while concealing one’s identity — promote or undermine public deliberation online? There are two general and opposed responses to this question.