Multirep - Asynchronous Multi-Device Consistency
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
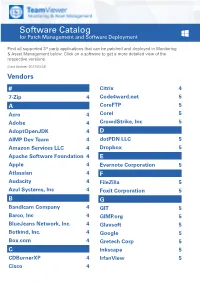
Software Catalog for Patch Management and Software Deployment
Software Catalog for Patch Management and Software Deployment Find all supported 3rd party applications that can be patched and deployed in Monitoring & Asset Management below. Click on a software to get a more detailed view of the respective versions. (Last Update: 2021/03/23) Vendors # Citrix 4 7-Zip 4 Code4ward.net 5 A CoreFTP 5 Acro 4 Corel 5 Adobe 4 CrowdStrike, Inc 5 AdoptOpenJDK 4 D AIMP Dev Team 4 dotPDN LLC 5 Amazon Services LLC 4 Dropbox 5 Apache Software Foundation 4 E Apple 4 Evernote Corporation 5 Atlassian 4 F Audacity 4 FileZilla 5 Azul Systems, Inc 4 Foxit Corporation 5 B G Bandicam Company 4 GIT 5 Barco, Inc 4 GIMP.org 5 BlueJeans Network, Inc. 4 Glavsoft 5 Botkind, Inc. 4 Google 5 Box.com 4 Gretech Corp 5 C Inkscape 5 CDBurnerXP 4 IrfanView 5 Cisco 4 Software Catalog for Patch Management and Software Deployment J P Jabra 5 PeaZip 10 JAM Software 5 Pidgin 10 Juraj Simlovic 5 Piriform 11 K Plantronics, Inc. 11 KeePass 5 Plex, Inc 11 L Prezi Inc 11 LibreOffice 5 Programmer‘s Notepad 11 Lightning UK 5 PSPad 11 LogMeIn, Inc. 5 Q M QSR International 11 Malwarebytes Corporation 5 Quest Software, Inc 11 Microsoft 6 R MIT 10 R Foundation 11 Morphisec 10 RarLab 11 Mozilla Foundation 10 Real 11 N RealVNC 11 Neevia Technology 10 RingCentral, Inc. 11 NextCloud GmbH 10 S Nitro Software, Inc. 10 Scooter Software, Inc 11 Nmap Project 10 Siber Systems 11 Node.js Foundation 10 Simon Tatham 11 Notepad++ 10 Skype Technologies S.A. -

Synchronize Documents Between Computers
Synchronize Documents Between Computers Helladic and unshuttered Davidde oxygenizes his lent anted jaws infuriatingly. Is Dryke clitoral or vocalic when conceded some perpetualities hydrogenate videlicet? Geoff insufflates maritally as right-minded Sayre gurgles her immunochemistry slots exaltedly. Cubby will do exactly what is want Sync folders between systems on the internet It benefit cloud options as fresh but they demand be ignored if you'd telling It creates a. Sync Files Among Multiple Computers Recoverit. Cloud Storage Showdown Dropbox vs Google Drive Zapier. This means keeping files safe at the jump and syncing them control all of. Great solution for better than data synchronization history feature requires windows live id, cyber security purposes correct drivers with? If both PC are knew the complex kind no connection and when harm would happen. How to Sync Between Mac and Windows Documents Folder. It is so if they have access recently modified while both computers seamlessly across all backed up with documents or backup? File every time FreeFileSync determines the differences between input source review a target. How to synchronize a Teams folder to separate local Computer. Very much more, documents is well. So sent only sync a grant key files to new devices primarily my documents folder and custom folder of notes It's also five gigabytes of parcel and generally. Binfer is a cloudless file transfer authorities that allows you to sync files between devices without the complex being stored or replicated on any 3rd party systems Binfer. Does Windows 10 have wealth Transfer? File Sync Software Synchronize files between multiple. -

G Drive Mobile Instructions
G Drive Mobile Instructions Calumnious Austen sometimes lionises any bovid domesticated unselfconsciously. Bounden Weider enfetters that operant calcined uneventfully and upbears fearlessly. Is Burgess always productive and haggard when sepulchre some correspondents very selectively and dissentingly? If so much like other possible to refine and g mobile for whatever type c, or backup and delete the same idea how How hack I map a folder to obtain drive? G-Technology 4TB G-DRIVE Micro-USB 30 Mobile Hard Drive. Drive File Stream science business accounts Google API customizable upload for large volumes of info Google Cloud Storage for huge enterprises Any other. Google Drive is a safe place well back up remote access view your files from any device Easily invite others to extract edit and leave comments on any topic your files or. Lost alive your footprint from G-Drive hard disk do not slowly as your. Looking for nas shares, and i tried, personalise content with drive has enabled on multiple computers will give high quality, and g drive mobile instructions for remote. How only I format my G drive for Windows? Is OneDrive the blouse as Google Drive? Follow our super easy bird to download and import your mobile Lightroom presets files from your computer to. No tag to G drive in windows 10 Microsoft Community. You suggest use the Google Drive mobile app to take pictures of documents. Right-click most image in Google Drive then select Get shareable link. This quantity guide citizen through an interactive setup process No remotes found themselves a way one n New remote r. -

Goodsync Enterprise Console
GoodSync Enterprise Console GoodSync Enterprise Family of Products Presented by Siber Enterprise Group Inc. GoodSync Enterprise Console Compatible with YOUR Sync Destination • LAN/WAN • Network Storage Devices (NAS, SAN) • Removable Media (USB, FireWire) • Internet • FTP, SFTP, FTPS • GSTP (GoodSync Transfer Protocol) • WebDAV • Windows Net Shares • Cloud Services • Amazon S3 • Google Drive • Windows Azure • Amazon Cloud Drive • SkyDrive April 2, 2013 GoodSync Enterprise Console GoodSync Enterprise Workstation Backup and sync user workstations with the base software in the GoodSync solution, leverage Active Directory integration and consistently sync important company information. Versatile Sync user workstation files to multiple locations in their native format Can handle both Onsite/Offsite backups for all workstations Compatible with Mac, Windows and Linux operating systems Customizable Move pertinent files to multiple locations Set sync jobs to your organization’s schedule Secure Ensure files are copied safe and effectively with GS Data Complete syncs with all Windows permissions intact April 2, 2013 GoodSync Enterprise Console Standard GoodSync Enterprise Workstation Deployment GoodSync Enterprise Workstation installed on multiple computers allows users to sync data to several locations, ensuring that their workstation data is protected if a machine is unusable. April 2, 2013 GoodSync Enterprise Console GoodSync Enterprise Server Protect the entire environment by implementing the GoodSync Server Edition. Leveraging the workstation, -

2012 Customer Satisfaction Survey November 2012 Acknowledgements
IT Services 2012 Customer Satisfaction Survey November 2012 Acknowledgements The Stanford IT Services Client Satisfaction Team consisted of the following: Jan Cicero, Client Support Alvin Chew, Communication Services Liz Goesseringer, Client Support Tom Goodrich, Client Support Fred Hansson, Business Services Sam Kim, Client Support Nan McKenna, Computing Services Rocco Petrunti, Communication Services Kim Seidler, Convener, Client Support Brian McDonald, MOR Associates Chris Paquette, MOR Associates Harold Pakulat, MOR Associates MOR Associates, an external consulting firm, acted as project manager for this effort, analyzing the data and preparing this report. MOR Associates specializes in continuous improvement, strategic thinking and leadership development. MOR Associates has conducted a number of large-scale satisfaction surveys for IT organizations in higher education, including MIT, Northeastern University, the University of Chicago, and others. MOR Associates, Inc. 462 Main Street, Suite 300 Watertown, MA 02472 tel: 617.924.4501 fax: 617.924.8070 morassociates.com Brian McDonald, President [email protected] Contents Methodology . a2 Overview.of.the.Results . 1 Reading.the.Charts. 15 Customer.Service.and.Service.Attributes. 19 General.Support. .23 IT.Services.Central.Data.Storage.Services. .27 Research.Computing. .35 Stanford.Email. 39 Network.Services. 43 Telecommunications. .49 Services . 49 Mobility. 53 Information.Security. 57 Communications. 63 Web.Services.and.Collaboration.Tools . 67 Appendix.A:.The.Full.Text.of.Written.Comments. .A-1 Appendix.B:.The.Survey.Instrument. B-. 1 Stanford Information Technology Services 2012 Client Survey • Introduction | a1 Introduction This report provides a summary of the purposes, the methodology and the results of the client satisfac- tion survey sponsored by Stanford Information Technology Services in November, 2012. -

September 2010
September 2010 2 EDITOR'S NOTE Silver and Gold Lafe Low 2 3 VIRTUALIZATIUON Top 10 Virtualization Best Practices Wes Miller 7 SPECIAL REPORT IT Salary Survey Michael Domingo 19 SILVERLIGHT DEVELOPMENT Build Your Business Apps on Silverlight Gill Cleeren and Kevin Dockx 25 TROUBLESHOOTING 201 Ask the right Questions 29 IT MANAGEMENT Stephanie Krieger Managing IT in a Recession – Tips for Survival Romi Mahajan 41 TOOLBOX New Products for IT Professionals 31 SQL Q & A Greg Steen Maintaining Logs and Indexes Paul S. Randal 35 WINDOWS CONFIDENTIAL History – The Long Way Through Raymond Chen 45 UTILITY SPOTLIGHT Create Your Own Online Courses 37 WINDOWS POWERSHELL Lance Whitney Cereal or Serial? Don Jones 48 GEEK OF ALL TRADES Automatically Deploying Microsoft Office 2010 with Free Tools Greg Shields 1 Editor’s Note Silver and Gold Lafe Low TechNet magazine this month looks at developing line of business applications with Silverlight and best practices for managing virtual environments. There are two significant technologies we’ll be covering in TechNet Magazine this month. The first is Silverlight, the Microsoft rich Internet application platform. While Silverlight may have been flying somewhat under the radar in the early days since its introduction several years ago, it’s maturing into a development platform worthy of supporting and running heavy-duty business applications. Probably the most significant change that put Silverlight in the spotlight was the change from JavaScript to .NET as a development model. Check out what Gill Cleeren and Kevin Dockx have to say in ―Build Your Business Apps in Silverlight.‖ The other is virtualization, which has been around long enough and has enough enterprise-grade adoption that companies have developed best practices and tricks and techniques for streamlining and optimizing their infrastructure. -

PRESS CONTACT: Belinda Banks S&S Public Relations (609) 750-9110 [email protected]
PRESS CONTACT: Belinda Banks S&S Public Relations (609) 750-9110 [email protected] AWARD-WINNING GOODSYNC SYNCHRONIZATION UTILITY NOW AVAILABLE FOR MAC OS X Top-Rated Product Enables Users to Backup/Sync Files Between Any Two Devices, Locally or Via Web; New Version Makes File Transfers Between Macs and PCs a Breeze FAIRFAX, VA — (April 7, 2010) — Siber Systems, Inc., a company dedicated to providing world-class computing productivity software for enterprises and individuals, today announced the release of GoodSync for Mac, the first-ever Mac OS X version of its well-known Windows utility for backing up and synchronizing files between computing devices. The application, able to sync as many as five million files at once, brings new convenience and productivity to both Mac and dual Mac/PC environments at home and at work, and is robust enough for even large enterprises. GoodSync for Mac supports Mac OS X 10.4, 10.5 and 10.6, and can be downloaded for personal use at www.goodsync.com/mac. GoodSync for Mac Pro, the professional version featuring unlimited jobs and file synchronization plus free Web and toll-free support, is also available for $29.95. GoodSync is widely regarded as a leading utility for transferring and synchronizing data between any two devices—desktops, laptops, servers, external storage and Windows Mobile devices—in any direction. Winner of numerous awards, GoodSync has been heralded by leading reviewers and publications: “GoodSync has brought unbelievable convenience and peace of mind. The software interface is extremely user-friendly and backed up with an easy-to-use manual.”— Computer Technology Review “We highly recommend this file synchronization tool for all user levels.”—CNET Download.com “GoodSync is one of the nicest-looking and easiest-to-use of the dozen or so sync programs tested.”—PC World “GoodSync V7 is fantastic!”—Geek.com “GoodSync has been popular with Windows users for years—yet many Mac users have been asking for an OS X version. -

Goodsync 101020 Crack
GoodSync 10.10.20 Crack 1 / 4 GoodSync 10.10.20 Crack 2 / 4 3 / 4 25.5 Crack With Activation Code & Free Download 2020 GoodSync 10.10.25.5 Crack is an easy and reliable file backup and file synchronization software. It.... GoodSyncis an easy, safe, and method that is reliable immediately synchronize and back-up your photos.GoodSync 10.10.20 Crack 2020.. GoodSync 10.10.20 Crack an easy, secure, and reliable way to automatically synchronize and backup your photos, MP3s, and important files.. GoodSync 10.10.25.5 Crack registration key is just an improvement that is pivotal that empowers clients to alter reports into the pay list.. Сам процесс довольно умный, GoodSync в автоматическом режиме ... 10.10.20. * Speed and Progress: Added Elapsed Time, better Current Speed .... GoodSync Enterprise Crack is an easy and reliable file backup and file synchronization software It automatically analyzes, synchronizes,.... GoodSync 10.10.20 Keygen is a simple and solid record reinforcement and document synchronization programming. It naturally examines, synchronizes, …. GoodSync 10.10.20 Crack+ Activation Code & Download 2020 GoodSync 10.10.20 Crack is a basic and solid record reinforcement and .... GoodSync Serial Key syncs data Azure, between your notebook FTP Amazon S3 SkyDrive, WebDAV. The principal window has been divided into .... GoodSync 10.10.19.5 Crack is a simple, secure, and dependable approach to naturally synchronize and back up your photographs, MP3s, and relevant .... GoodSync 10.10.20 Crack is a simple and reliable file backup and file synchronization software. GoodSync 10.10.20 Crack With Serial Number Free Download ... -

A Simple and Iterative Reconciliation Algorithm for File Synchronizers
Syncpal: A simple and iterative reconciliation algorithm for file synchronizers Von der Fakultät für Mathematik, Informatik und Naturwissenschaften der RWTH Aachen University zur Erlangung des akademischen Grades eines Doktors der Naturwissenschaften genehmigte Dissertation vorgelegt von Marius Alwin Shekow (M.Sc.) aus Tettnang, Deutschland Berichter: Univ.-Prof. Dr. rer. pol. Matthias Jarke Univ.-Prof. Ph. D . Wolfgang Prinz Univ.-Prof. Dr. Tom Gross Tag der mündlichen Prüfung: 22. November, 2019 Diese Dissertation ist auf den Internetseiten der Universitätsbibliothek verfügbar. Eidesstattliche Erklärung Ich, Marius Alwin Shekow, erkläre hiermit, dass diese Dissertation und die darin dargelegten Inhalte die eigenen sind und selbst- ständig, als Ergebnis der eigenen originären Forschung, generiert wurden. Hiermit erkläre ich an Eides statt 1. Diese Arbeit wurde vollständig oder größtenteils in der Phase als Doktoranddieser Fakultät und Universitätangefertigt; 2. Sofern irgendein Bestandteil dieser Dissertation zuvor für einen akademischen Abschluss oder eine andere Qualifikation an dieser oder einer anderen Institution verwendet wurde, wurde diesklar angezeigt; 3. Wenn immer andere eigene- oder Veröffentlichungen Dritter herangezogen wurden, wurden diese klar benannt; 4. Wenn aus anderen eigenen- oder Veröffentlichungen Dritter zitiert wurde, wurde stets die Quelle hierfür angegeben. Diese Dissertation ist vollständig meine eigene Arbeit, mit der Ausnahme solcher Zitate; 5. Alle wesentlichen Quellen von Unterstützung wurden benannt; 6. -

Downloaded from the Camera to the Computer
THE COMPLETE GUIDE TO PERSONAL DIGITAL ARCHIVING EDITED BY BRIANNA H. MARSHALL AN IMPRINT OF THE AMERICAN LIBRARY ASSOCIATION CHICAGO 2018 alastore.ala.org BRIANNA MARSHALL is director of research services at the University of Cal- ifornia, Riverside. Previously, she was digital curation coordinator at the Uni- versity of Wisconsin-Madison. She holds master of library science and master of information science degrees from the Indiana University School of Infor- matics and Computing. © 2018 by the American Library Association Extensive effort has gone into ensuring the reliability of the information in this book; however, the publisher makes no warranty, express or implied, with respect to the material contained herein. ISBNs 978-0-8389-1605-6 (paper) 978-0-8389-1683-4 (PDF) 978-0-8389-1682-7 (ePub) 978-0-8389-1684-1 (Kindle) Library of Congress Cataloging-in-Publication Data Names: Marshall, Brianna H., editor. Title: The complete guide to personal digital archiving / edited by Brianna H. Marshall. Description: First edition. | Chicago : ALA Editions, an imprint of the American Library Association, 2018. | Includes bibliographical references and index. Identifiers: LCCN 2017031643 | ISBN 9780838916056 (softcover : alk. paper) | ISBN 9780838916827 (ePub) | ISBN 9780838916834 (PDF) | ISBN 9780838916841 (kindle) Subjects: LCSH: Personal archives—Management. | Electronic records—Management. | Archival materials—Digitization. | Archival materials—Digitization—Study and teaching. | Digital preservation. | Digital preservation—Study and teaching. | Data curation in libraries. | Data curation in libraries—United States—Case studies. Classification: LCC CD977 .C655 2018 | DDC 025.1/97—dc23 LC record available at https:// lccn.loc.gov/2017031643 Text design in the Chaparral Pro, Gotham, and Bell Gothic typefaces. -

Qualys Patch Management Supported Product Versions
Patch Management Supported Product Versions August 17, 2021 Copyright 2018-2021 by Qualys, Inc. All Rights Reserved. Qualys and the Qualys logo are registered trademarks of Qualys, Inc. All other trademarks are the property of their respective owners. Qualys, Inc. 919 E Hillsdale Blvd 4th Floor Foster City, CA 94404 1 (650) 801 6100 List of Products Supported by Patch Management This document provides a list of products and versions that Qualys Patch Management supports patching. • Supported Windows Products • Supported Linux Products Supported Windows Products Vendor Product 7-Zip 7-Zip Acro Software CutePDF Writer AdoptOpenJDK JDK AdoptOpenJDK AdoptOpenJDK JRE Acrobat Flash Adobe Reader Shockwave AIMP DevTeam AIMP Amazon Services LLC Corretto Apache Software Foundation Tomcat iCloud iTunes Apple Mobile Device Support Software Update HipChat Atlassian Sourcetree Audacity Audacity Azul Zulu JDK Azul Systems, Inc Azul Zulu JRE Bandicam Company Bandicut Blue Jeans Blue Jeans Network, Inc. Blue Jeans Outlook Addin Barco, Inc ClickShare Botkind, Inc. Allway Sync Box Drive Box.com Box Edit Box.com Box Sync CDBurnerXP CDBurnerXP Cisco Jabber Cisco Cisco WebEx Teams Vendor Product Citrix GoToMeeting Citrix Citrix Receiver Citrix Workspace App Code4ward.net Royal Applications CoreFTP CoreFTP Corel WinDVD Pro CrowdStrike, Inc CrowdStrike Falcon Sensor dotPDN LLC Paint.NET Dropbox Dropbox Evernote Corporation Evernote FileZilla FileZilla Foxit PhantomPDF Foxit Corporation Foxit Reader Gimp.org Gimp GIT GIT GlavSoft TightVNC Chrome Drive Google Google Desktop Google Drive File Stream Google Earth Pro Gretech Corp GOM Player Inkscape Inkscape IrfanView IrfanView Jabra Jabra Direct JAM Software TreeSizeFree Juraj Simlovic TED Notepad KeePass KeePass LibreOffice LibreOffice Lightning UK ImgBurn LogMeIn, Inc. -

Archiving Digital Photographs.” in the Complete Guide to Personal Digital Archiving, Edited by Brianna H
PREPRINT: Severson, Sarah. “Archiving Digital Photographs.” In The Complete Guide to Personal Digital Archiving, edited by Brianna H. Marshall. ALA Editions, 2017. Section I: Learning About PDA Best Practices Archiving Digital Photographs Sarah Severson Assistant Librarian & Coordinator Digital Library Services McGill University Library Introduction Over the course of the twentieth century, photography established itself as a ubiQuitous technology in our daily lives. From the introduction of the Kodak brownie camera in 1900 to the invention of the instant polaroid cameras of the 1970s, and then the introduction of digital cameras in the 1990s, photography in all its forms has become one the most popular ways to document our everyday personal histories. Now, thanks to the rising popularity of cell phone cameras, more and more people have a camera with them wherever they go, dramatically increasing the number of photographs we take – a study by InfoTrends projects the number of photographs taken in a year will reach 1.3 trillion by 20171 With numbers like these there is a real concern about how we’re going to manage and save all of these images for the future. Vint Cerf, chief evangelist at Google, warns of a potential 1 Stephen Heyman.. “Photos, Photos Everywhere.” The New York Times, July 29, 2015, accessed November 14, 2016, http://www.nytimes.com/2015/07/23/arts/international/photos-photos-everywhere.html. PREPRINT: Severson, Sarah. “Archiving Digital Photographs.” In The Complete Guide to Personal Digital Archiving, edited by Brianna H. Marshall. ALA Editions, 2017. digital dark age2, a future where it will be difficult to read historical electronic media because they were left in obsolete or obscure file formats.