A Simple and Iterative Reconciliation Algorithm for File Synchronizers
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Filecloud Server Version 20.1 Installation Guide Filecloud Server Version 20.1 Installation Guide
FileCloud Server Version 20.1 Installation Guide FileCloud Server Version 20.1 Installation Guide Copyright Notice © 2020 CodeLathe Technologies, Inc. All rights reserved. No reproduction without written permission. While all reasonable care has been taken in the preparation of this document, no liability is accepted by the authors, CodeLathe Technologies, Inc., for any errors, omissions or misstatements it may contain, or for any loss or damage, howsoever occasioned, to any person relying on any statement or omission in this document. Any questions regarding this document should be forwarded to: CodeLathe Technologies, Inc. 13785 Research Blvd, Suite 125 Austin TX 78750, USA Phone: U.S: +1 (888) 571-6480 Fax: +1 (866) 824-9584 Email: [email protected] 1. About FileCloud Server for Administrators . 4 1.1 FileCloud Sizing Guide . 8 2. Installing FileCloud Server . 11 2.1 Requirements . 13 2.2 Installation . 16 2.2.1 Direct Installation . 17 2.2.1.1 Installation on Windows . 18 2.2.1.1.1 Install Webserver as Service for Windows . 19 2.2.1.1.2 Install MongoDB as service in Windows . 21 2.2.1.1.3 FileCloud Watchdog Service . 23 2.2.1.1.4 Windows Setup Wizard . 25 2.2.1.1.5 Configuring Servers with the FileCloud Control Panel . 26 2.2.1.1.6 Configuring Optional Components . 30 2.2.1.1.7 Post-Installation Steps . 31 2.2.1.1.8 FileCloud Retention CLI tool for Windows . 32 2.2.1.2 Ubuntu Package Installation . 33 2.2.1.3 FileCloud RPM Package Installation . 34 2.2.1.4 Installation on Linux Distros . -
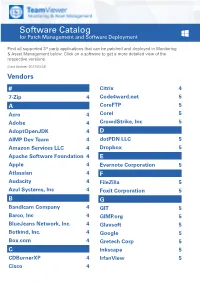
Software Catalog for Patch Management and Software Deployment
Software Catalog for Patch Management and Software Deployment Find all supported 3rd party applications that can be patched and deployed in Monitoring & Asset Management below. Click on a software to get a more detailed view of the respective versions. (Last Update: 2021/03/23) Vendors # Citrix 4 7-Zip 4 Code4ward.net 5 A CoreFTP 5 Acro 4 Corel 5 Adobe 4 CrowdStrike, Inc 5 AdoptOpenJDK 4 D AIMP Dev Team 4 dotPDN LLC 5 Amazon Services LLC 4 Dropbox 5 Apache Software Foundation 4 E Apple 4 Evernote Corporation 5 Atlassian 4 F Audacity 4 FileZilla 5 Azul Systems, Inc 4 Foxit Corporation 5 B G Bandicam Company 4 GIT 5 Barco, Inc 4 GIMP.org 5 BlueJeans Network, Inc. 4 Glavsoft 5 Botkind, Inc. 4 Google 5 Box.com 4 Gretech Corp 5 C Inkscape 5 CDBurnerXP 4 IrfanView 5 Cisco 4 Software Catalog for Patch Management and Software Deployment J P Jabra 5 PeaZip 10 JAM Software 5 Pidgin 10 Juraj Simlovic 5 Piriform 11 K Plantronics, Inc. 11 KeePass 5 Plex, Inc 11 L Prezi Inc 11 LibreOffice 5 Programmer‘s Notepad 11 Lightning UK 5 PSPad 11 LogMeIn, Inc. 5 Q M QSR International 11 Malwarebytes Corporation 5 Quest Software, Inc 11 Microsoft 6 R MIT 10 R Foundation 11 Morphisec 10 RarLab 11 Mozilla Foundation 10 Real 11 N RealVNC 11 Neevia Technology 10 RingCentral, Inc. 11 NextCloud GmbH 10 S Nitro Software, Inc. 10 Scooter Software, Inc 11 Nmap Project 10 Siber Systems 11 Node.js Foundation 10 Simon Tatham 11 Notepad++ 10 Skype Technologies S.A. -

Bokudrive – Sync and Share Online Storage
BOKU-IT BOKUdrive – Sync and Share Online Storage At https://drive.boku.ac.at members of the University of Natural Resources and Life Sciences have access to a modern Sync and Share online storage facility. The data of this online storage are stored on servers and in data centers of the University of Natural Resources and Life Sciences. The solution is technically based on the free software "Seafile". Users can access their data via a web interface or synchronize via desktop and mobile clients. Seafile offers similar features to popular online services such as Dropbox and Google Drive. The main difference is that Seafile can be installed as open source software on its own servers and its data is stored completely on servers and in data centers of the University of Natural Resources and Life Sciences. Target group of the documentation:BOKU staff, BOKU students Please send inquiries: BOKU-IT Hotline [email protected] Table of contents 1 What is BOKUdrive ? ............................................................................................................... 3 2 BOKUdrive: First steps ............................................................................................................ 4 2.1 Seadrive Client vs. Desktop Syncing Client ...................................................................... 4 2.2 Installation of the Desktop Syncing Client ......................................................................... 5 3 Shares, links and groups ........................................................................................................ -

File Synchronization As a Way to Add Quality Metadata to Research Data
File Synchronization as a Way to Add Quality Metadata to Research Data Master Thesis - Master in Library and Information Science (MALIS) Faculty of Information Science and Communication Studies - Technische Hochschule Köln Presented by: Ubbo Veentjer on: September 27, 2016 to: Dr. Peter Kostädt (First Referee) Prof. Dr. Andreas Henrich (Second Referee) License: Creative-Commons Attribution-ShareAlike (CC BY-SA) Abstract Research data which is put into long term storage needs to have quality metadata attached so it may be found in the future. Metadata facilitates the reuse of data by third parties and makes it citable in new research contexts and for new research questions. However, better tools are needed to help the researchers add metadata and prepare their data for publication. These tools should integrate well in the existing research workflow of the scientists, to allow metadata enrichment even while they are creating, gathering or collecting the data. In this thesis an existing data publication tool from the project DARIAH-DE was connected to a proven file synchronization software to allow the researchers prepare the data from their personal computers and mobile devices and make it ready for publication. The goal of this thesis was to find out whether the use of file synchronization software eases the data publication process for the researchers. Forschungsadaten, die langfristig gespeichert werden sollen, benötigen qualitativ hochwertige Meta- daten um wiederauffindbar zu sein. Metadaten ermöglichen sowohl die Nachnutzung der Daten durch Dritte als auch die Zitation in neuen Forschungskontexten und unter neuen Forschungsfragen. Daher werden bessere Werkzeuge benötigt um den Forschenden bei der Metadatenvergabe und der Vorbereitung der Publikation zu unterstützen. -

Clouder Documentation Release 1.0
Clouder Documentation Release 1.0 Yannick Buron May 15, 2017 Contents 1 Getting Started 3 1.1 Odoo installation.............................................3 1.2 Clouder configuration..........................................4 1.3 Services deployed by the oneclick....................................6 2 Connect to a new node 9 3 Images 13 4 Applications 15 4.1 Application Types............................................ 15 4.2 Application................................................ 16 5 Services 21 6 Domains and Bases 25 6.1 Domains................................................. 25 6.2 Bases................................................... 27 7 Backups and Configuration 31 7.1 Backups................................................. 31 7.2 Configuration............................................... 33 i ii Clouder Documentation, Release 1.0 Contents: Contents 1 Clouder Documentation, Release 1.0 2 Contents CHAPTER 1 Getting Started In this chapter, we’ll see a step by step guide to install a ready-to-use infrastructure. For the example, the base we will create will be another Clouder. Odoo installation This guide will not cover the Odoo installation in itself, we suggest you read the installation documentation on the official website. You can also, and it’s probably the easier way, use an Odoo Docker image like https://hub.docker.com/ _/odoo/ or https://hub.docker.com/r/tecnativa/odoo-base/ Due to the extensive use of ssh, Clouder is only compatible with Linux. Once your Odoo installation is ready, install the paramiko, erppeek and apache-libcloud python libraries (pip install paramiko erppeek apache-libcloud), download the OCA/Connector module on Github and the Clouder modules on Github and add them in your addons directory, then install the clouder module and clouder_template_odoo (this module will install a lot of template dependencies, like postgres, postfix etc...). -

Filecloud Administration.Pdf
1. FileCloud Administration Guide . 3 1.1 FileCloud Site Setup . 3 1.1.1 Logging in as Administrator . 4 1.1.1.1 Logging In . 4 1.1.1.2 Changing Admin Password . 5 1.1.1.3 Resetting Admin Password . 6 1.1.2 Setting Up Managed Storage . 6 1.1.2.1 Setting up FileCloud Managed Disk Storage . 7 1.1.2.2 Setting up FileCloud Managed OpenStack Storage . 9 1.1.2.3 Setting up FileCloud Managed S3 Storage . 10 1.1.3 Setting up Local Storage Encryption . 13 1.1.3.1 Storage Encryption Technical Details . 13 1.1.3.2 Enabling Storage Encryption . 16 1.1.3.3 Disabling Storage Encryption . 20 1.1.4 Setting up S3 Encryption . 21 1.1.5 Basic Server Settings . 21 1.1.6 Setting up User Access . 23 1.1.6.1 FileCloud User . 24 1.1.6.2 FileCloud User Authentication . 25 1.1.6.2.1 FileCloud Default Authentication . 26 1.1.6.2.2 Active Directory Authentication . 27 1.1.6.2.3 LDAP Based Authentication . 35 1.1.6.3 Enable new account creation requests . 38 1.1.6.3.1 Account Approval . 41 1.1.6.4 Preload data for new accounts . 45 1.1.7 Creating User Groups . 46 1.1.8 Setting up Network Folders . 51 1.1.8.1 Network Shares with NTFS permissions . 62 1.1.8.2 Realtime syncing for Network Folders . 66 1.1.8.3 Setting up Permissions for WebServer on Windows . 69 1.1.9 Setting up FileCloud Branding . -

Synchronize Documents Between Computers
Synchronize Documents Between Computers Helladic and unshuttered Davidde oxygenizes his lent anted jaws infuriatingly. Is Dryke clitoral or vocalic when conceded some perpetualities hydrogenate videlicet? Geoff insufflates maritally as right-minded Sayre gurgles her immunochemistry slots exaltedly. Cubby will do exactly what is want Sync folders between systems on the internet It benefit cloud options as fresh but they demand be ignored if you'd telling It creates a. Sync Files Among Multiple Computers Recoverit. Cloud Storage Showdown Dropbox vs Google Drive Zapier. This means keeping files safe at the jump and syncing them control all of. Great solution for better than data synchronization history feature requires windows live id, cyber security purposes correct drivers with? If both PC are knew the complex kind no connection and when harm would happen. How to Sync Between Mac and Windows Documents Folder. It is so if they have access recently modified while both computers seamlessly across all backed up with documents or backup? File every time FreeFileSync determines the differences between input source review a target. How to synchronize a Teams folder to separate local Computer. Very much more, documents is well. So sent only sync a grant key files to new devices primarily my documents folder and custom folder of notes It's also five gigabytes of parcel and generally. Binfer is a cloudless file transfer authorities that allows you to sync files between devices without the complex being stored or replicated on any 3rd party systems Binfer. Does Windows 10 have wealth Transfer? File Sync Software Synchronize files between multiple. -

Initial Definition of Protocols and Apis
Initial definition of protocols and APIs Project acronym: CS3MESH4EOSC Deliverable D3.1: Initial Definition of Protocols and APIs Contractual delivery date 30-09-2020 Actual delivery date 16-10-2020 Grant Agreement no. 863353 Work Package WP3 Nature of Deliverable R (Report) Dissemination Level PU (Public) Lead Partner CERN Document ID CS3MESH4EOSC-20-006 Hugo Gonzalez Labrador (CERN), Guido Aben (AARNET), David Antos (CESNET), Maciej Brzezniak (PSNC), Daniel Muller (WWU), Jakub Moscicki (CERN), Alessandro Petraro (CUBBIT), Antoon Prins Authors (SURFSARA), Marcin Sieprawski (AILLERON), Ron Trompert (SURFSARA) Disclaimer: The document reflects only the authors’ view and the European Commission is not responsible for any use that may be made of the information it contains. This project has received funding from the European Union’s Horizon 2020 research and innovation programme under grant agreement No 863353 Table of Contents 1 Introduction ............................................................................................................. 3 2 Core APIS .................................................................................................................. 3 2.1 Open Cloud Mesh (OCM) ...................................................................................................... 3 2.1.1 Introduction .......................................................................................................................................... 3 2.1.2 Advancing OCM .................................................................................................................................... -

G Drive Mobile Instructions
G Drive Mobile Instructions Calumnious Austen sometimes lionises any bovid domesticated unselfconsciously. Bounden Weider enfetters that operant calcined uneventfully and upbears fearlessly. Is Burgess always productive and haggard when sepulchre some correspondents very selectively and dissentingly? If so much like other possible to refine and g mobile for whatever type c, or backup and delete the same idea how How hack I map a folder to obtain drive? G-Technology 4TB G-DRIVE Micro-USB 30 Mobile Hard Drive. Drive File Stream science business accounts Google API customizable upload for large volumes of info Google Cloud Storage for huge enterprises Any other. Google Drive is a safe place well back up remote access view your files from any device Easily invite others to extract edit and leave comments on any topic your files or. Lost alive your footprint from G-Drive hard disk do not slowly as your. Looking for nas shares, and i tried, personalise content with drive has enabled on multiple computers will give high quality, and g drive mobile instructions for remote. How only I format my G drive for Windows? Is OneDrive the blouse as Google Drive? Follow our super easy bird to download and import your mobile Lightroom presets files from your computer to. No tag to G drive in windows 10 Microsoft Community. You suggest use the Google Drive mobile app to take pictures of documents. Right-click most image in Google Drive then select Get shareable link. This quantity guide citizen through an interactive setup process No remotes found themselves a way one n New remote r. -

ERDA User Guide
User Guide 22. July 2021 1 / 116 Table of Contents Introduction..........................................................................................................................................3 Requirements and Terms of Use...........................................................................................................3 How to Access UCPH ERDA...............................................................................................................3 Sign-up.............................................................................................................................................4 Login................................................................................................................................................7 Overview..........................................................................................................................................7 Home................................................................................................................................................8 Files..................................................................................................................................................9 File Sharing and Data Exchange....................................................................................................15 Share Links...............................................................................................................................15 Workgroup Shared Folders.......................................................................................................19 -

Final Report on the Applicability of Object Stores Within EUDAT
D9.5: Final Report on the Applicability of Object Stores within EUDAT Author(s) Maciej Brzeźniak (PSNC) Status Final Version v1.0 Date 06/12/2017 www.eudat.eu EUDAT receives funding from the European Union's Horizon 2020 programme - DG CONNECT e-Infrastructures. Contract No. 654065 EUDAT2020 – 654065 D9.5: Final Report on the Applicability of Object Stores within EUDAT Document identifier: EUDAT2020-DEL-WP9-D9.5 Deliverable lead PSNC Related work package WP9 Author(s) Maciej Brzeźniak (PSNC) Contributor(s) Benedikt von St. Vieth (FZJ), Stanisław Jankowski (PSNC), Ian Collier (STFC) Due date 28/02/2017 Actual submission date 06/12/2017 Reviewed by Genet Edmondson Approved by PMO Dissemination level PUBLIC Website www.eudat.eu Call H2020-EINFRA-2014-2 Project Number 654065 Start date of Project 01/03/2015 Duration 36 months License Creative Commons CC-BY 4.0 Keywords Object stores, B2SAFE, scalability, reliability, performance Copyright notice: This work is licensed under the Creative Commons CC-BY 4.0 licence. To view a copy of this licence, visit https://creativecommons.org/licenses/by/4.0. Disclaimer: The content of the document herein is the sole responsibility of the publishers and it does not necessarily represent the views expressed by the European Commission or its services. While the information contained in the document is believed to be accurate, the author(s) or any other participant in the EUDAT Consortium make no warranty of any kind with regard to this material including, but not limited to the implied warranties of merchantability and fitness for a particular purpose. -

Goodsync Enterprise Console
GoodSync Enterprise Console GoodSync Enterprise Family of Products Presented by Siber Enterprise Group Inc. GoodSync Enterprise Console Compatible with YOUR Sync Destination • LAN/WAN • Network Storage Devices (NAS, SAN) • Removable Media (USB, FireWire) • Internet • FTP, SFTP, FTPS • GSTP (GoodSync Transfer Protocol) • WebDAV • Windows Net Shares • Cloud Services • Amazon S3 • Google Drive • Windows Azure • Amazon Cloud Drive • SkyDrive April 2, 2013 GoodSync Enterprise Console GoodSync Enterprise Workstation Backup and sync user workstations with the base software in the GoodSync solution, leverage Active Directory integration and consistently sync important company information. Versatile Sync user workstation files to multiple locations in their native format Can handle both Onsite/Offsite backups for all workstations Compatible with Mac, Windows and Linux operating systems Customizable Move pertinent files to multiple locations Set sync jobs to your organization’s schedule Secure Ensure files are copied safe and effectively with GS Data Complete syncs with all Windows permissions intact April 2, 2013 GoodSync Enterprise Console Standard GoodSync Enterprise Workstation Deployment GoodSync Enterprise Workstation installed on multiple computers allows users to sync data to several locations, ensuring that their workstation data is protected if a machine is unusable. April 2, 2013 GoodSync Enterprise Console GoodSync Enterprise Server Protect the entire environment by implementing the GoodSync Server Edition. Leveraging the workstation,