A Method and Its Application to the Human Mitotic Kinetochore
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

PARSANA-DISSERTATION-2020.Pdf
DECIPHERING TRANSCRIPTIONAL PATTERNS OF GENE REGULATION: A COMPUTATIONAL APPROACH by Princy Parsana A dissertation submitted to The Johns Hopkins University in conformity with the requirements for the degree of Doctor of Philosophy Baltimore, Maryland July, 2020 © 2020 Princy Parsana All rights reserved Abstract With rapid advancements in sequencing technology, we now have the ability to sequence the entire human genome, and to quantify expression of tens of thousands of genes from hundreds of individuals. This provides an extraordinary opportunity to learn phenotype relevant genomic patterns that can improve our understanding of molecular and cellular processes underlying a trait. The high dimensional nature of genomic data presents a range of computational and statistical challenges. This dissertation presents a compilation of projects that were driven by the motivation to efficiently capture gene regulatory patterns in the human transcriptome, while addressing statistical and computational challenges that accompany this data. We attempt to address two major difficulties in this domain: a) artifacts and noise in transcriptomic data, andb) limited statistical power. First, we present our work on investigating the effect of artifactual variation in gene expression data and its impact on trans-eQTL discovery. Here we performed an in-depth analysis of diverse pre-recorded covariates and latent confounders to understand their contribution to heterogeneity in gene expression measurements. Next, we discovered 673 trans-eQTLs across 16 human tissues using v6 data from the Genotype Tissue Expression (GTEx) project. Finally, we characterized two trait-associated trans-eQTLs; one in Skeletal Muscle and another in Thyroid. Second, we present a principal component based residualization method to correct gene expression measurements prior to reconstruction of co-expression networks. -

CENPT (NM 025082) Human 3' UTR Clone – SC200995 | Origene
OriGene Technologies, Inc. 9620 Medical Center Drive, Ste 200 Rockville, MD 20850, US Phone: +1-888-267-4436 [email protected] EU: [email protected] CN: [email protected] Product datasheet for SC200995 CENPT (NM_025082) Human 3' UTR Clone Product data: Product Type: 3' UTR Clones Product Name: CENPT (NM_025082) Human 3' UTR Clone Vector: pMirTarget (PS100062) Symbol: CENPT Synonyms: C16orf56; CENP-T; SSMGA ACCN: NM_025082 Insert Size: 140 bp Insert Sequence: >SC200995 3’UTR clone of NM_025082 The sequence shown below is from the reference sequence of NM_025082. The complete sequence of this clone may contain minor differences, such as SNPs. Blue=Stop Codon Red=Cloning site GGCAAGTTGGACGCCCGCAAGATCCGCGAGATTCTCATTAAGGCCAAGAAGGGCGGAAAGATCGCCGTG TAACAATTGGCAGAGCTCAGAATTCAAGCGATCGCC AGTGGCAACTCTGTCTTCCCTGCCCAGTAGTGGCCAGGCTTCAACACTTTCCCTGTCCCCACCTGGGGA CTCTTGCCCCCACATATTTCTCCAGGTCTCCTCCCCACCCCCCCAGCATCAATAAAGTGTCATAAACAG AA ACGCGTAAGCGGCCGCGGCATCTAGATTCGAAGAAAATGACCGACCAAGCGACGCCCAACCTGCCATCA CGAGATTTCGATTCCACCGCCGCCTTCTATGAAAGG Restriction Sites: SgfI-MluI OTI Disclaimer: Our molecular clone sequence data has been matched to the sequence identifier above as a point of reference. Note that the complete sequence of this clone is largely the same as the reference sequence but may contain minor differences , e.g., single nucleotide polymorphisms (SNPs). RefSeq: NM_025082.4 Summary: The centromere is a specialized chromatin domain, present throughout the cell cycle, that acts as a platform on which the transient assembly of the kinetochore occurs during mitosis. All active centromeres are characterized by the presence of long arrays of nucleosomes in which CENPA (MIM 117139) replaces histone H3 (see MIM 601128). CENPT is an additional factor required for centromere assembly (Foltz et al., 2006 [PubMed 16622419]).[supplied by OMIM, Mar 2008] Locus ID: 80152 This product is to be used for laboratory only. Not for diagnostic or therapeutic use. -

View the Poster.Pdf
Identifying Novel Associations for Iron-Related Genes in High-Grade Ovarian Cancer Abigail Descoteaux*1, José W. Velázquez*2, Anna Konstorum3, Reinhard Laubenbacher3,4 1Vassar College, 2University of Puerto Rico at Cayey, 3Center for Quantitative Medicine, UConn Health, 4The Jackson Laboratory for Genomic Medicine *These authors contributed equally to this work Introduction Methods Testable Hypothesis § Iron can gain and lose electrons, making it enzymatically Microarray gene expression Adjacency matrix Community detection in a weighted, KEGG pathways Tumor cells promote an inflammatory microenvironment via [1] data from HGSOC clinical • Top 10,000 most variable genes undirected network • Manually curated biological pathways useful in cell replication, metabolism, and growth • Bicor derived from Pearson but • ORA: ask whether any known pathways • Order Statistics Local Optimization Method (OSLOM) recruitment of tumor-associated macrophages, that in turn samples less sensitive to outliers are significantly over-represented in the • Assembled unsupervised with respect to biology by locally § Cancer cells sequester iron by altering the expression of • The Cancer Genome Atlas (TCGA) • Correlation cut-off at 0.45 genes within the community secrete IL4 and CCL4 to promote an iron-influx phenotype in optimizing the statistical significance of clusters and using [1] • Affymetrix HGU133A (n=488) (FDR corrected, α=0.01) Pathway 2 several regulators of iron metabolism (Figure 1) • Tothill et al. [2] this as a fitness score ovarian cancer tumor cells. • • HGU133plus2 (n=217) Accounts for edge weight, overlapping communities, and Pathway 1 hierarchies a. Normal epithelial cell Fe3+ Fe3+ Pathway 3 Tumor-associated 3+ 3+ Tumor cells Fe Fe macrophages Hepcidin (HAMP) samples genes Biweight midcorrelation Over-representation (bicor) Hypothesis CSF1R Ferroportin OSLOM analysis (ORA) CCR1[8] (SLC40A1) generation and [7] genes genes 1. -

Gene Knockdown of CENPA Reduces Sphere Forming Ability and Stemness of Glioblastoma Initiating Cells
Neuroepigenetics 7 (2016) 6–18 Contents lists available at ScienceDirect Neuroepigenetics journal homepage: www.elsevier.com/locate/nepig Gene knockdown of CENPA reduces sphere forming ability and stemness of glioblastoma initiating cells Jinan Behnan a,1, Zanina Grieg b,c,1, Mrinal Joel b,c, Ingunn Ramsness c, Biljana Stangeland a,b,⁎ a Department of Molecular Medicine, Institute of Basic Medical Sciences, The Medical Faculty, University of Oslo, Oslo, Norway b Norwegian Center for Stem Cell Research, Department of Immunology and Transfusion Medicine, Oslo University Hospital, Oslo, Norway c Vilhelm Magnus Laboratory for Neurosurgical Research, Institute for Surgical Research and Department of Neurosurgery, Oslo University Hospital, Oslo, Norway article info abstract Article history: CENPA is a centromere-associated variant of histone H3 implicated in numerous malignancies. However, the Received 20 May 2016 role of this protein in glioblastoma (GBM) has not been demonstrated. GBM is one of the most aggressive Received in revised form 23 July 2016 human cancers. GBM initiating cells (GICs), contained within these tumors are deemed to convey Accepted 2 August 2016 characteristics such as invasiveness and resistance to therapy. Therefore, there is a strong rationale for targeting these cells. We investigated the expression of CENPA and other centromeric proteins (CENPs) in Keywords: fi CENPA GICs, GBM and variety of other cell types and tissues. Bioinformatics analysis identi ed the gene signature: fi Centromeric proteins high_CENP(AEFNM)/low_CENP(BCTQ) whose expression correlated with signi cantly worse GBM patient Glioblastoma survival. GBM Knockdown of CENPA reduced sphere forming ability, proliferation and cell viability of GICs. We also Brain tumor detected significant reduction in the expression of stemness marker SOX2 and the proliferation marker Glioblastoma initiating cells and therapeutic Ki67. -

PDF Output of CLIC (Clustering by Inferred Co-Expression)
PDF Output of CLIC (clustering by inferred co-expression) Dataset: Num of genes in input gene set: 13 Total number of genes: 16493 CLIC PDF output has three sections: 1) Overview of Co-Expression Modules (CEMs) Heatmap shows pairwise correlations between all genes in the input query gene set. Red lines shows the partition of input genes into CEMs, ordered by CEM strength. Each row shows one gene, and the brightness of squares indicates its correlations with other genes. Gene symbols are shown at left side and on the top of the heatmap. 2) Details of each CEM and its expansion CEM+ Top panel shows the posterior selection probability (dataset weights) for top GEO series datasets. Bottom panel shows the CEM genes (blue rows) as well as expanded CEM+ genes (green rows). Each column is one GEO series dataset, sorted by their posterior probability of being selected. The brightness of squares indicates the gene's correlations with CEM genes in the corresponding dataset. CEM+ includes genes that co-express with CEM genes in high-weight datasets, measured by LLR score. 3) Details of each GEO series dataset and its expression profile: Top panel shows the detailed information (e.g. title, summary) for the GEO series dataset. Bottom panel shows the background distribution and the expression profile for CEM genes in this dataset. Overview of Co-Expression Modules (CEMs) with Dataset Weighting Scale of average Pearson correlations Num of Genes in Query Geneset: 13. Num of CEMs: 1. 0.0 0.2 0.4 0.6 0.8 1.0 Cenpk Cenph Cenpp Cenpu Cenpn Cenpq Cenpl Apitd1 -

The MIS12 Complex Is a Protein Interaction Hub for Outer Kinetochore Assembly
JCB: Article The MIS12 complex is a protein interaction hub for outer kinetochore assembly Arsen Petrovic,1 Sebastiano Pasqualato,1 Prakash Dube,3 Veronica Krenn,1 Stefano Santaguida,1 Davide Cittaro,4 Silvia Monzani,1 Lucia Massimiliano,1 Jenny Keller,1 Aldo Tarricone,1 Alessio Maiolica,1 Holger Stark,3 and Andrea Musacchio1,2 1Department of Experimental Oncology, European Institute of Oncology (IEO) and 2Research Unit of the Italian Institute of Technology, Italian Foundation for Cancer Research Institute of Molecular Oncology–IEO Campus, I-20139 Milan, Italy 33D Electron Cryomicroscopy Group, Max Planck Institute for Biophysical Chemistry, and Göttingen Center for Microbiology, University of Göttingen, 37077 Göttingen, Germany 4Consortium for Genomic Technologies, I-20139 Milan, Italy inetochores are nucleoprotein assemblies responsi axis of 22 nm. Through biochemical analysis, cross- ble for the attachment of chromosomes to spindle linking–based methods, and negative-stain electron mi K microtubules during mitosis. The KMN network, croscopy, we investigated the reciprocal organization of a crucial constituent of the outer kinetochore, creates an the subunits of the MIS12 complex and their contacts with interface that connects microtubules to centromeric chro the rest of the KMN network. A highlight of our findings matin. The NDC80, MIS12, and KNL1 complexes form the is the identification of the NSL1 subunit as a scaffold core of the KMN network. We recently reported the struc supporting interactions of the MIS12 complex with the tural organization of the human NDC80 complex. In this NDC80 and KNL1 complexes. Our analysis has important study, we extend our analysis to the human MIS12 com implications for understanding kinetochore organization in plex and show that it has an elongated structure with a long different organisms. -

IL21R Expressing CD14+CD16+ Monocytes Expand in Multiple
Plasma Cell Disorders SUPPLEMENTARY APPENDIX IL21R expressing CD14 +CD16 + monocytes expand in multiple myeloma patients leading to increased osteoclasts Marina Bolzoni, 1 Domenica Ronchetti, 2,3 Paola Storti, 1,4 Gaetano Donofrio, 5 Valentina Marchica, 1,4 Federica Costa, 1 Luca Agnelli, 2,3 Denise Toscani, 1 Rosanna Vescovini, 1 Katia Todoerti, 6 Sabrina Bonomini, 7 Gabriella Sammarelli, 1,7 Andrea Vecchi, 8 Daniela Guasco, 1 Fabrizio Accardi, 1,7 Benedetta Dalla Palma, 1,7 Barbara Gamberi, 9 Carlo Ferrari, 8 Antonino Neri, 2,3 Franco Aversa 1,4,7 and Nicola Giuliani 1,4,7 1Myeloma Unit, Dept. of Medicine and Surgery, University of Parma; 2Dept. of Oncology and Hemato-Oncology, University of Milan; 3Hematology Unit, “Fondazione IRCCS Ca’ Granda”, Ospedale Maggiore Policlinico, Milan; 4CoreLab, University Hospital of Parma; 5Dept. of Medical-Veterinary Science, University of Parma; 6Laboratory of Pre-clinical and Translational Research, IRCCS-CROB, Referral Cancer Center of Basilicata, Rionero in Vulture; 7Hematology and BMT Center, University Hospital of Parma; 8Infectious Disease Unit, University Hospital of Parma and 9“Dip. Oncologico e Tecnologie Avanzate”, IRCCS Arcispedale Santa Maria Nuova, Reggio Emilia, Italy ©2017 Ferrata Storti Foundation. This is an open-access paper. doi:10.3324/haematol. 2016.153841 Received: August 5, 2016. Accepted: December 23, 2016. Pre-published: January 5, 2017. Correspondence: [email protected] SUPPLEMENTAL METHODS Immunophenotype of BM CD14+ in patients with monoclonal gammopathies. Briefly, 100 μl of total BM aspirate was incubated in the dark with anti-human HLA-DR-PE (clone L243; BD), anti-human CD14-PerCP-Cy 5.5, anti-human CD16-PE-Cy7 (clone B73.1; BD) and anti-human CD45-APC-H 7 (clone 2D1; BD) for 20 min. -
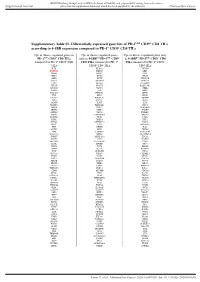
Supplementary Table S5. Differentially Expressed Gene Lists of PD-1High CD39+ CD8 Tils According to 4-1BB Expression Compared to PD-1+ CD39- CD8 Tils
BMJ Publishing Group Limited (BMJ) disclaims all liability and responsibility arising from any reliance Supplemental material placed on this supplemental material which has been supplied by the author(s) J Immunother Cancer Supplementary Table S5. Differentially expressed gene lists of PD-1high CD39+ CD8 TILs according to 4-1BB expression compared to PD-1+ CD39- CD8 TILs Up- or down- regulated genes in Up- or down- regulated genes Up- or down- regulated genes only PD-1high CD39+ CD8 TILs only in 4-1BBneg PD-1high CD39+ in 4-1BBpos PD-1high CD39+ CD8 compared to PD-1+ CD39- CD8 CD8 TILs compared to PD-1+ TILs compared to PD-1+ CD39- TILs CD39- CD8 TILs CD8 TILs IL7R KLRG1 TNFSF4 ENTPD1 DHRS3 LEF1 ITGA5 MKI67 PZP KLF3 RYR2 SIK1B ANK3 LYST PPP1R3B ETV1 ADAM28 H2AC13 CCR7 GFOD1 RASGRP2 ITGAX MAST4 RAD51AP1 MYO1E CLCF1 NEBL S1PR5 VCL MPP7 MS4A6A PHLDB1 GFPT2 TNF RPL3 SPRY4 VCAM1 B4GALT5 TIPARP TNS3 PDCD1 POLQ AKAP5 IL6ST LY9 PLXND1 PLEKHA1 NEU1 DGKH SPRY2 PLEKHG3 IKZF4 MTX3 PARK7 ATP8B4 SYT11 PTGER4 SORL1 RAB11FIP5 BRCA1 MAP4K3 NCR1 CCR4 S1PR1 PDE8A IFIT2 EPHA4 ARHGEF12 PAICS PELI2 LAT2 GPRASP1 TTN RPLP0 IL4I1 AUTS2 RPS3 CDCA3 NHS LONRF2 CDC42EP3 SLCO3A1 RRM2 ADAMTSL4 INPP5F ARHGAP31 ESCO2 ADRB2 CSF1 WDHD1 GOLIM4 CDK5RAP1 CD69 GLUL HJURP SHC4 GNLY TTC9 HELLS DPP4 IL23A PITPNC1 TOX ARHGEF9 EXO1 SLC4A4 CKAP4 CARMIL3 NHSL2 DZIP3 GINS1 FUT8 UBASH3B CDCA5 PDE7B SOGA1 CDC45 NR3C2 TRIB1 KIF14 TRAF5 LIMS1 PPP1R2C TNFRSF9 KLRC2 POLA1 CD80 ATP10D CDCA8 SETD7 IER2 PATL2 CCDC141 CD84 HSPA6 CYB561 MPHOSPH9 CLSPN KLRC1 PTMS SCML4 ZBTB10 CCL3 CA5B PIP5K1B WNT9A CCNH GEM IL18RAP GGH SARDH B3GNT7 C13orf46 SBF2 IKZF3 ZMAT1 TCF7 NECTIN1 H3C7 FOS PAG1 HECA SLC4A10 SLC35G2 PER1 P2RY1 NFKBIA WDR76 PLAUR KDM1A H1-5 TSHZ2 FAM102B HMMR GPR132 CCRL2 PARP8 A2M ST8SIA1 NUF2 IL5RA RBPMS UBE2T USP53 EEF1A1 PLAC8 LGR6 TMEM123 NEK2 SNAP47 PTGIS SH2B3 P2RY8 S100PBP PLEKHA7 CLNK CRIM1 MGAT5 YBX3 TP53INP1 DTL CFH FEZ1 MYB FRMD4B TSPAN5 STIL ITGA2 GOLGA6L10 MYBL2 AHI1 CAND2 GZMB RBPJ PELI1 HSPA1B KCNK5 GOLGA6L9 TICRR TPRG1 UBE2C AURKA Leem G, et al. -

Research Article the Oncogenic Role of CENPA in Hepatocellular Carcinoma Development: Evidence from Bioinformatic Analysis
Hindawi BioMed Research International Volume 2020, Article ID 3040839, 8 pages https://doi.org/10.1155/2020/3040839 Research Article The Oncogenic Role of CENPA in Hepatocellular Carcinoma Development: Evidence from Bioinformatic Analysis Yuan Zhang ,1 Lei Yang ,2 Jia Shi ,1 Yunfei Lu ,1 Xiaorong Chen ,1 and Zongguo Yang 1 1Department of Integrative Medicine, Shanghai Public Health Clinical Center, Fudan University, Shanghai 201508, China 2Department of Acupuncture and Moxibustion, Dongzhimen Hospital, Beijing University of Chinese Medicine, Beijing 100007, China Correspondence should be addressed to Xiaorong Chen; [email protected] and Zongguo Yang; [email protected] Received 27 September 2019; Revised 14 March 2020; Accepted 20 March 2020; Published 8 April 2020 Academic Editor: Ali A. Khraibi Copyright © 2020 Yuan Zhang et al. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. Objective. This study is aimed at investigating the predictive value of CENPA in hepatocellular carcinoma (HCC) development. Methods. Using integrated bioinformatic analysis, we evaluated the CENPA mRNA expression in tumor and adjacent tissues and correlated it with HCC survival and clinicopathological features. A Cox regression hazard model was also performed. Results. CENPA mRNA was significantly upregulated in tumor tissues compared with that in adjacent tissues, which were validated in The Cancer Genome Atlas (TCGA) and Gene Expression Omnibus (GEO) series (all P <0:01). In the Kaplan-Meier plotter platform, the high level of CENPA mRNA was significantly correlated with overall survival (OS), disease-free survival (DFS), recurrence-free survival (RFS), and progression-free survival (PFS) in HCC patients (all log rank P <0:01). -

1 AGING Supplementary Table 2
SUPPLEMENTARY TABLES Supplementary Table 1. Details of the eight domain chains of KIAA0101. Serial IDENTITY MAX IN COMP- INTERFACE ID POSITION RESOLUTION EXPERIMENT TYPE number START STOP SCORE IDENTITY LEX WITH CAVITY A 4D2G_D 52 - 69 52 69 100 100 2.65 Å PCNA X-RAY DIFFRACTION √ B 4D2G_E 52 - 69 52 69 100 100 2.65 Å PCNA X-RAY DIFFRACTION √ C 6EHT_D 52 - 71 52 71 100 100 3.2Å PCNA X-RAY DIFFRACTION √ D 6EHT_E 52 - 71 52 71 100 100 3.2Å PCNA X-RAY DIFFRACTION √ E 6GWS_D 41-72 41 72 100 100 3.2Å PCNA X-RAY DIFFRACTION √ F 6GWS_E 41-72 41 72 100 100 2.9Å PCNA X-RAY DIFFRACTION √ G 6GWS_F 41-72 41 72 100 100 2.9Å PCNA X-RAY DIFFRACTION √ H 6IIW_B 2-11 2 11 100 100 1.699Å UHRF1 X-RAY DIFFRACTION √ www.aging-us.com 1 AGING Supplementary Table 2. Significantly enriched gene ontology (GO) annotations (cellular components) of KIAA0101 in lung adenocarcinoma (LinkedOmics). Leading Description FDR Leading Edge Gene EdgeNum RAD51, SPC25, CCNB1, BIRC5, NCAPG, ZWINT, MAD2L1, SKA3, NUF2, BUB1B, CENPA, SKA1, AURKB, NEK2, CENPW, HJURP, NDC80, CDCA5, NCAPH, BUB1, ZWILCH, CENPK, KIF2C, AURKA, CENPN, TOP2A, CENPM, PLK1, ERCC6L, CDT1, CHEK1, SPAG5, CENPH, condensed 66 0 SPC24, NUP37, BLM, CENPE, BUB3, CDK2, FANCD2, CENPO, CENPF, BRCA1, DSN1, chromosome MKI67, NCAPG2, H2AFX, HMGB2, SUV39H1, CBX3, TUBG1, KNTC1, PPP1CC, SMC2, BANF1, NCAPD2, SKA2, NUP107, BRCA2, NUP85, ITGB3BP, SYCE2, TOPBP1, DMC1, SMC4, INCENP. RAD51, OIP5, CDK1, SPC25, CCNB1, BIRC5, NCAPG, ZWINT, MAD2L1, SKA3, NUF2, BUB1B, CENPA, SKA1, AURKB, NEK2, ESCO2, CENPW, HJURP, TTK, NDC80, CDCA5, BUB1, ZWILCH, CENPK, KIF2C, AURKA, DSCC1, CENPN, CDCA8, CENPM, PLK1, MCM6, ERCC6L, CDT1, HELLS, CHEK1, SPAG5, CENPH, PCNA, SPC24, CENPI, NUP37, FEN1, chromosomal 94 0 CENPL, BLM, KIF18A, CENPE, MCM4, BUB3, SUV39H2, MCM2, CDK2, PIF1, DNA2, region CENPO, CENPF, CHEK2, DSN1, H2AFX, MCM7, SUV39H1, MTBP, CBX3, RECQL4, KNTC1, PPP1CC, CENPP, CENPQ, PTGES3, NCAPD2, DYNLL1, SKA2, HAT1, NUP107, MCM5, MCM3, MSH2, BRCA2, NUP85, SSB, ITGB3BP, DMC1, INCENP, THOC3, XPO1, APEX1, XRCC5, KIF22, DCLRE1A, SEH1L, XRCC3, NSMCE2, RAD21. -

Real-Time Dynamics of Plasmodium NDC80 Reveals Unusual Modes of Chromosome Segregation During Parasite Proliferation Mohammad Zeeshan1,*, Rajan Pandey1,*, David J
© 2020. Published by The Company of Biologists Ltd | Journal of Cell Science (2021) 134, jcs245753. doi:10.1242/jcs.245753 RESEARCH ARTICLE SPECIAL ISSUE: CELL BIOLOGY OF HOST–PATHOGEN INTERACTIONS Real-time dynamics of Plasmodium NDC80 reveals unusual modes of chromosome segregation during parasite proliferation Mohammad Zeeshan1,*, Rajan Pandey1,*, David J. P. Ferguson2,3, Eelco C. Tromer4, Robert Markus1, Steven Abel5, Declan Brady1, Emilie Daniel1, Rebecca Limenitakis6, Andrew R. Bottrill7, Karine G. Le Roch5, Anthony A. Holder8, Ross F. Waller4, David S. Guttery9 and Rita Tewari1,‡ ABSTRACT eukaryotic organisms to proliferate, propagate and survive. During Eukaryotic cell proliferation requires chromosome replication and these processes, microtubular spindles form to facilitate an equal precise segregation to ensure daughter cells have identical genomic segregation of duplicated chromosomes to the spindle poles. copies. Species of the genus Plasmodium, the causative agents of Chromosome attachment to spindle microtubules (MTs) is malaria, display remarkable aspects of nuclear division throughout their mediated by kinetochores, which are large multiprotein complexes life cycle to meet some peculiar and unique challenges to DNA assembled on centromeres located at the constriction point of sister replication and chromosome segregation. The parasite undergoes chromatids (Cheeseman, 2014; McKinley and Cheeseman, 2016; atypical endomitosis and endoreduplication with an intact nuclear Musacchio and Desai, 2017; Vader and Musacchio, 2017). Each membrane and intranuclear mitotic spindle. To understand these diverse sister chromatid has its own kinetochore, oriented to facilitate modes of Plasmodium cell division, we have studied the behaviour movement to opposite poles of the spindle apparatus. During and composition of the outer kinetochore NDC80 complex, a key part of anaphase, the spindle elongates and the sister chromatids separate, the mitotic apparatus that attaches the centromere of chromosomes to resulting in segregation of the two genomes during telophase. -

Supplemental Information
Supplemental information Dissection of the genomic structure of the miR-183/96/182 gene. Previously, we showed that the miR-183/96/182 cluster is an intergenic miRNA cluster, located in a ~60-kb interval between the genes encoding nuclear respiratory factor-1 (Nrf1) and ubiquitin-conjugating enzyme E2H (Ube2h) on mouse chr6qA3.3 (1). To start to uncover the genomic structure of the miR- 183/96/182 gene, we first studied genomic features around miR-183/96/182 in the UCSC genome browser (http://genome.UCSC.edu/), and identified two CpG islands 3.4-6.5 kb 5’ of pre-miR-183, the most 5’ miRNA of the cluster (Fig. 1A; Fig. S1 and Seq. S1). A cDNA clone, AK044220, located at 3.2-4.6 kb 5’ to pre-miR-183, encompasses the second CpG island (Fig. 1A; Fig. S1). We hypothesized that this cDNA clone was derived from 5’ exon(s) of the primary transcript of the miR-183/96/182 gene, as CpG islands are often associated with promoters (2). Supporting this hypothesis, multiple expressed sequences detected by gene-trap clones, including clone D016D06 (3, 4), were co-localized with the cDNA clone AK044220 (Fig. 1A; Fig. S1). Clone D016D06, deposited by the German GeneTrap Consortium (GGTC) (http://tikus.gsf.de) (3, 4), was derived from insertion of a retroviral construct, rFlpROSAβgeo in 129S2 ES cells (Fig. 1A and C). The rFlpROSAβgeo construct carries a promoterless reporter gene, the β−geo cassette - an in-frame fusion of the β-galactosidase and neomycin resistance (Neor) gene (5), with a splicing acceptor (SA) immediately upstream, and a polyA signal downstream of the β−geo cassette (Fig.