Principles of Compiler Design Lecture Notes
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Syntax-Directed Translation, Parse Trees, Abstract Syntax Trees
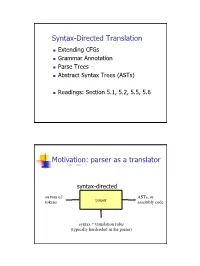
Syntax-Directed Translation Extending CFGs Grammar Annotation Parse Trees Abstract Syntax Trees (ASTs) Readings: Section 5.1, 5.2, 5.5, 5.6 Motivation: parser as a translator syntax-directed translation stream of ASTs, or tokens parser assembly code syntax + translation rules (typically hardcoded in the parser) 1 Mechanism of syntax-directed translation syntax-directed translation is done by extending the CFG a translation rule is defined for each production given X Æ d A B c the translation of X is defined in terms of translation of nonterminals A, B values of attributes of terminals d, c constants To translate an input string: 1. Build the parse tree. 2. Working bottom-up • Use the translation rules to compute the translation of each nonterminal in the tree Result: the translation of the string is the translation of the parse tree's root nonterminal Why bottom up? a nonterminal's value may depend on the value of the symbols on the right-hand side, so translate a non-terminal node only after children translations are available 2 Example 1: arith expr to its value Syntax-directed translation: the CFG translation rules E Æ E + T E1.trans = E2.trans + T.trans E Æ T E.trans = T.trans T Æ T * F T1.trans = T2.trans * F.trans T Æ F T.trans = F.trans F Æ int F.trans = int.value F Æ ( E ) F.trans = E.trans Example 1 (cont) E (18) Input: 2 * (4 + 5) T (18) T (2) * F (9) F (2) ( E (9) ) int (2) E (4) * T (5) Annotated Parse Tree T (4) F (5) F (4) int (5) int (4) 3 Example 2: Compute type of expr E -> E + E if ((E2.trans == INT) and (E3.trans == INT) then E1.trans = INT else E1.trans = ERROR E -> E and E if ((E2.trans == BOOL) and (E3.trans == BOOL) then E1.trans = BOOL else E1.trans = ERROR E -> E == E if ((E2.trans == E3.trans) and (E2.trans != ERROR)) then E1.trans = BOOL else E1.trans = ERROR E -> true E.trans = BOOL E -> false E.trans = BOOL E -> int E.trans = INT E -> ( E ) E1.trans = E2.trans Example 2 (cont) Input: (2 + 2) == 4 1. -

Metaheuristics1
METAHEURISTICS1 Kenneth Sörensen University of Antwerp, Belgium Fred Glover University of Colorado and OptTek Systems, Inc., USA 1 Definition A metaheuristic is a high-level problem-independent algorithmic framework that provides a set of guidelines or strategies to develop heuristic optimization algorithms (Sörensen and Glover, To appear). Notable examples of metaheuristics include genetic/evolutionary algorithms, tabu search, simulated annealing, and ant colony optimization, although many more exist. A problem-specific implementation of a heuristic optimization algorithm according to the guidelines expressed in a metaheuristic framework is also referred to as a metaheuristic. The term was coined by Glover (1986) and combines the Greek prefix meta- (metá, beyond in the sense of high-level) with heuristic (from the Greek heuriskein or euriskein, to search). Metaheuristic algorithms, i.e., optimization methods designed according to the strategies laid out in a metaheuristic framework, are — as the name suggests — always heuristic in nature. This fact distinguishes them from exact methods, that do come with a proof that the optimal solution will be found in a finite (although often prohibitively large) amount of time. Metaheuristics are therefore developed specifically to find a solution that is “good enough” in a computing time that is “small enough”. As a result, they are not subject to combinatorial explosion – the phenomenon where the computing time required to find the optimal solution of NP- hard problems increases as an exponential function of the problem size. Metaheuristics have been demonstrated by the scientific community to be a viable, and often superior, alternative to more traditional (exact) methods of mixed- integer optimization such as branch and bound and dynamic programming. -

Derivatives of Parsing Expression Grammars
Derivatives of Parsing Expression Grammars Aaron Moss Cheriton School of Computer Science University of Waterloo Waterloo, Ontario, Canada [email protected] This paper introduces a new derivative parsing algorithm for recognition of parsing expression gram- mars. Derivative parsing is shown to have a polynomial worst-case time bound, an improvement on the exponential bound of the recursive descent algorithm. This work also introduces asymptotic analysis based on inputs with a constant bound on both grammar nesting depth and number of back- tracking choices; derivative and recursive descent parsing are shown to run in linear time and constant space on this useful class of inputs, with both the theoretical bounds and the reasonability of the in- put class validated empirically. This common-case constant memory usage of derivative parsing is an improvement on the linear space required by the packrat algorithm. 1 Introduction Parsing expression grammars (PEGs) are a parsing formalism introduced by Ford [6]. Any LR(k) lan- guage can be represented as a PEG [7], but there are some non-context-free languages that may also be represented as PEGs (e.g. anbncn [7]). Unlike context-free grammars (CFGs), PEGs are unambiguous, admitting no more than one parse tree for any grammar and input. PEGs are a formalization of recursive descent parsers allowing limited backtracking and infinite lookahead; a string in the language of a PEG can be recognized in exponential time and linear space using a recursive descent algorithm, or linear time and space using the memoized packrat algorithm [6]. PEGs are formally defined and these algo- rithms outlined in Section 3. -

Lecture 4 Dynamic Programming
1/17 Lecture 4 Dynamic Programming Last update: Jan 19, 2021 References: Algorithms, Jeff Erickson, Chapter 3. Algorithms, Gopal Pandurangan, Chapter 6. Dynamic Programming 2/17 Backtracking is incredible powerful in solving all kinds of hard prob- lems, but it can often be very slow; usually exponential. Example: Fibonacci numbers is defined as recurrence: 0 if n = 0 Fn =8 1 if n = 1 > Fn 1 + Fn 2 otherwise < ¡ ¡ > A direct translation in:to recursive program to compute Fibonacci number is RecFib(n): if n=0 return 0 if n=1 return 1 return RecFib(n-1) + RecFib(n-2) Fibonacci Number 3/17 The recursive program has horrible time complexity. How bad? Let's try to compute. Denote T(n) as the time complexity of computing RecFib(n). Based on the recursion, we have the recurrence: T(n) = T(n 1) + T(n 2) + 1; T(0) = T(1) = 1 ¡ ¡ Solving this recurrence, we get p5 + 1 T(n) = O(n); = 1.618 2 So the RecFib(n) program runs at exponential time complexity. RecFib Recursion Tree 4/17 Intuitively, why RecFib() runs exponentially slow. Problem: redun- dant computation! How about memorize the intermediate computa- tion result to avoid recomputation? Fib: Memoization 5/17 To optimize the performance of RecFib, we can memorize the inter- mediate Fn into some kind of cache, and look it up when we need it again. MemFib(n): if n = 0 n = 1 retujrjn n if F[n] is undefined F[n] MemFib(n-1)+MemFib(n-2) retur n F[n] How much does it improve upon RecFib()? Assuming accessing F[n] takes constant time, then at most n additions will be performed (we never recompute). -

About ILE C/C++ Compiler Reference
IBM i 7.3 Programming IBM Rational Development Studio for i ILE C/C++ Compiler Reference IBM SC09-4816-07 Note Before using this information and the product it supports, read the information in “Notices” on page 121. This edition applies to IBM® Rational® Development Studio for i (product number 5770-WDS) and to all subsequent releases and modifications until otherwise indicated in new editions. This version does not run on all reduced instruction set computer (RISC) models nor does it run on CISC models. This document may contain references to Licensed Internal Code. Licensed Internal Code is Machine Code and is licensed to you under the terms of the IBM License Agreement for Machine Code. © Copyright International Business Machines Corporation 1993, 2015. US Government Users Restricted Rights – Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents ILE C/C++ Compiler Reference............................................................................... 1 What is new for IBM i 7.3.............................................................................................................................3 PDF file for ILE C/C++ Compiler Reference.................................................................................................5 About ILE C/C++ Compiler Reference......................................................................................................... 7 Prerequisite and Related Information.................................................................................................. -

Exhaustive Recursion and Backtracking
CS106B Handout #19 J Zelenski Feb 1, 2008 Exhaustive recursion and backtracking In some recursive functions, such as binary search or reversing a file, each recursive call makes just one recursive call. The "tree" of calls forms a linear line from the initial call down to the base case. In such cases, the performance of the overall algorithm is dependent on how deep the function stack gets, which is determined by how quickly we progress to the base case. For reverse file, the stack depth is equal to the size of the input file, since we move one closer to the empty file base case at each level. For binary search, it more quickly bottoms out by dividing the remaining input in half at each level of the recursion. Both of these can be done relatively efficiently. Now consider a recursive function such as subsets or permutation that makes not just one recursive call, but several. The tree of function calls has multiple branches at each level, which in turn have further branches, and so on down to the base case. Because of the multiplicative factors being carried down the tree, the number of calls can grow dramatically as the recursion goes deeper. Thus, these exhaustive recursion algorithms have the potential to be very expensive. Often the different recursive calls made at each level represent a decision point, where we have choices such as what letter to choose next or what turn to make when reading a map. Might there be situations where we can save some time by focusing on the most promising options, without committing to exploring them all? In some contexts, we have no choice but to exhaustively examine all possibilities, such as when trying to find some globally optimal result, But what if we are interested in finding any solution, whichever one that works out first? At each decision point, we can choose one of the available options, and sally forth, hoping it works out. -

Compiler Error Messages Considered Unhelpful: the Landscape of Text-Based Programming Error Message Research
Working Group Report ITiCSE-WGR ’19, July 15–17, 2019, Aberdeen, Scotland Uk Compiler Error Messages Considered Unhelpful: The Landscape of Text-Based Programming Error Message Research Brett A. Becker∗ Paul Denny∗ Raymond Pettit∗ University College Dublin University of Auckland University of Virginia Dublin, Ireland Auckland, New Zealand Charlottesville, Virginia, USA [email protected] [email protected] [email protected] Durell Bouchard Dennis J. Bouvier Brian Harrington Roanoke College Southern Illinois University Edwardsville University of Toronto Scarborough Roanoke, Virgina, USA Edwardsville, Illinois, USA Scarborough, Ontario, Canada [email protected] [email protected] [email protected] Amir Kamil Amey Karkare Chris McDonald University of Michigan Indian Institute of Technology Kanpur University of Western Australia Ann Arbor, Michigan, USA Kanpur, India Perth, Australia [email protected] [email protected] [email protected] Peter-Michael Osera Janice L. Pearce James Prather Grinnell College Berea College Abilene Christian University Grinnell, Iowa, USA Berea, Kentucky, USA Abilene, Texas, USA [email protected] [email protected] [email protected] ABSTRACT of evidence supporting each one (historical, anecdotal, and empiri- Diagnostic messages generated by compilers and interpreters such cal). This work can serve as a starting point for those who wish to as syntax error messages have been researched for over half of a conduct research on compiler error messages, runtime errors, and century. Unfortunately, these messages which include error, warn- warnings. We also make the bibtex file of our 300+ reference corpus ing, and run-time messages, present substantial difficulty and could publicly available. -

Dynamic Programming Via Static Incrementalization 1 Introduction
Dynamic Programming via Static Incrementalization Yanhong A. Liu and Scott D. Stoller Abstract Dynamic programming is an imp ortant algorithm design technique. It is used for solving problems whose solutions involve recursively solving subproblems that share subsubproblems. While a straightforward recursive program solves common subsubproblems rep eatedly and of- ten takes exp onential time, a dynamic programming algorithm solves every subsubproblem just once, saves the result, reuses it when the subsubproblem is encountered again, and takes p oly- nomial time. This pap er describ es a systematic metho d for transforming programs written as straightforward recursions into programs that use dynamic programming. The metho d extends the original program to cache all p ossibly computed values, incrementalizes the extended pro- gram with resp ect to an input increment to use and maintain all cached results, prunes out cached results that are not used in the incremental computation, and uses the resulting in- cremental program to form an optimized new program. Incrementalization statically exploits semantics of b oth control structures and data structures and maintains as invariants equalities characterizing cached results. The principle underlying incrementalization is general for achiev- ing drastic program sp eedups. Compared with previous metho ds that p erform memoization or tabulation, the metho d based on incrementalization is more powerful and systematic. It has b een implemented and applied to numerous problems and succeeded on all of them. 1 Intro duction Dynamic programming is an imp ortant technique for designing ecient algorithms [2, 44 , 13 ]. It is used for problems whose solutions involve recursively solving subproblems that overlap. -

ROSE Tutorial: a Tool for Building Source-To-Source Translators Draft Tutorial (Version 0.9.11.115)
ROSE Tutorial: A Tool for Building Source-to-Source Translators Draft Tutorial (version 0.9.11.115) Daniel Quinlan, Markus Schordan, Richard Vuduc, Qing Yi Thomas Panas, Chunhua Liao, and Jeremiah J. Willcock Lawrence Livermore National Laboratory Livermore, CA 94550 925-423-2668 (office) 925-422-6278 (fax) fdquinlan,panas2,[email protected] [email protected] [email protected] [email protected] [email protected] Project Web Page: www.rosecompiler.org UCRL Number for ROSE User Manual: UCRL-SM-210137-DRAFT UCRL Number for ROSE Tutorial: UCRL-SM-210032-DRAFT UCRL Number for ROSE Source Code: UCRL-CODE-155962 ROSE User Manual (pdf) ROSE Tutorial (pdf) ROSE HTML Reference (html only) September 12, 2019 ii September 12, 2019 Contents 1 Introduction 1 1.1 What is ROSE.....................................1 1.2 Why you should be interested in ROSE.......................2 1.3 Problems that ROSE can address...........................2 1.4 Examples in this ROSE Tutorial...........................3 1.5 ROSE Documentation and Where To Find It.................... 10 1.6 Using the Tutorial................................... 11 1.7 Required Makefile for Tutorial Examples....................... 11 I Working with the ROSE AST 13 2 Identity Translator 15 3 Simple AST Graph Generator 19 4 AST Whole Graph Generator 23 5 Advanced AST Graph Generation 29 6 AST PDF Generator 31 7 Introduction to AST Traversals 35 7.1 Input For Example Traversals............................. 35 7.2 Traversals of the AST Structure............................ 36 7.2.1 Classic Object-Oriented Visitor Pattern for the AST............ 37 7.2.2 Simple Traversal (no attributes)....................... 37 7.2.3 Simple Pre- and Postorder Traversal.................... -

Backtrack Parsing Context-Free Grammar Context-Free Grammar
Context-free Grammar Problems with Regular Context-free Grammar Language and Is English a regular language? Bad question! We do not even know what English is! Two eggs and bacon make(s) a big breakfast Backtrack Parsing Can you slide me the salt? He didn't ought to do that But—No! Martin Kay I put the wine you brought in the fridge I put the wine you brought for Sandy in the fridge Should we bring the wine you put in the fridge out Stanford University now? and University of the Saarland You said you thought nobody had the right to claim that they were above the law Martin Kay Context-free Grammar 1 Martin Kay Context-free Grammar 2 Problems with Regular Problems with Regular Language Language You said you thought nobody had the right to claim [You said you thought [nobody had the right [to claim that they were above the law that [they were above the law]]]] Martin Kay Context-free Grammar 3 Martin Kay Context-free Grammar 4 Problems with Regular Context-free Grammar Language Nonterminal symbols ~ grammatical categories Is English mophology a regular language? Bad question! We do not even know what English Terminal Symbols ~ words morphology is! They sell collectables of all sorts Productions ~ (unordered) (rewriting) rules This concerns unredecontaminatability Distinguished Symbol This really is an untiable knot. But—Probably! (Not sure about Swahili, though) Not all that important • Terminals and nonterminals are disjoint • Distinguished symbol Martin Kay Context-free Grammar 5 Martin Kay Context-free Grammar 6 Context-free Grammar Context-free -

Adaptive LL(*) Parsing: the Power of Dynamic Analysis
Adaptive LL(*) Parsing: The Power of Dynamic Analysis Terence Parr Sam Harwell Kathleen Fisher University of San Francisco University of Texas at Austin Tufts University [email protected] [email protected] kfi[email protected] Abstract PEGs are unambiguous by definition but have a quirk where Despite the advances made by modern parsing strategies such rule A ! a j ab (meaning “A matches either a or ab”) can never as PEG, LL(*), GLR, and GLL, parsing is not a solved prob- match ab since PEGs choose the first alternative that matches lem. Existing approaches suffer from a number of weaknesses, a prefix of the remaining input. Nested backtracking makes de- including difficulties supporting side-effecting embedded ac- bugging PEGs difficult. tions, slow and/or unpredictable performance, and counter- Second, side-effecting programmer-supplied actions (muta- intuitive matching strategies. This paper introduces the ALL(*) tors) like print statements should be avoided in any strategy that parsing strategy that combines the simplicity, efficiency, and continuously speculates (PEG) or supports multiple interpreta- predictability of conventional top-down LL(k) parsers with the tions of the input (GLL and GLR) because such actions may power of a GLR-like mechanism to make parsing decisions. never really take place [17]. (Though DParser [24] supports The critical innovation is to move grammar analysis to parse- “final” actions when the programmer is certain a reduction is time, which lets ALL(*) handle any non-left-recursive context- part of an unambiguous final parse.) Without side effects, ac- free grammar. ALL(*) is O(n4) in theory but consistently per- tions must buffer data for all interpretations in immutable data forms linearly on grammars used in practice, outperforming structures or provide undo actions. -

9. Optimization
9. Optimization Marcus Denker Optimization Roadmap > Introduction > Optimizations in the Back-end > The Optimizer > SSA Optimizations > Advanced Optimizations © Marcus Denker 2 Optimization Roadmap > Introduction > Optimizations in the Back-end > The Optimizer > SSA Optimizations > Advanced Optimizations © Marcus Denker 3 Optimization Optimization: The Idea > Transform the program to improve efficiency > Performance: faster execution > Size: smaller executable, smaller memory footprint Tradeoffs: 1) Performance vs. Size 2) Compilation speed and memory © Marcus Denker 4 Optimization No Magic Bullet! > There is no perfect optimizer > Example: optimize for simplicity Opt(P): Smallest Program Q: Program with no output, does not stop Opt(Q)? © Marcus Denker 5 Optimization No Magic Bullet! > There is no perfect optimizer > Example: optimize for simplicity Opt(P): Smallest Program Q: Program with no output, does not stop Opt(Q)? L1 goto L1 © Marcus Denker 6 Optimization No Magic Bullet! > There is no perfect optimizer > Example: optimize for simplicity Opt(P): Smallest ProgramQ: Program with no output, does not stop Opt(Q)? L1 goto L1 Halting problem! © Marcus Denker 7 Optimization Another way to look at it... > Rice (1953): For every compiler there is a modified compiler that generates shorter code. > Proof: Assume there is a compiler U that generates the shortest optimized program Opt(P) for all P. — Assume P to be a program that does not stop and has no output — Opt(P) will be L1 goto L1 — Halting problem. Thus: U does not exist. > There will