Open Tawandist.Pdf
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

D3.3 Initial Technical & Logical Architecture and Future Work
D3.3 Initial Technical & Logical Architecture and future work recommendations ECP 2008 DILI 558001 Europeana v1.0 D3.3 Initial Technical & Logical Architecture and future work recommendations Deliverable number D3.3 Dissemination level Public Delivery date 30 July 2010 Status Final Makx Dekkers, Stefan Gradmann, Jan Author(s) Molendijk eContentplus This project is funded under the eContentplus programme1, a multiannual Community programme to make digital content in Europe more accessible, usable and exploitable. 1 OJ L 79, 24.3.2005, p. 1. 1/14 D3.3 Initial Technical & Logical Architecture and future work recommendations 1. Introduction This deliverable has two tasks: To characterise the technical and logical architecture of Europeana as a system in its 1.0 state (that is to say by the time of the ‘Rhine’ release To outline the future work recommendations that can reasonably be made at that moment. This also provides a straightforward and logical structure to the document: characterisation comes first followed by the recommendations for future work. 2. Technical and Logical Architecture From a high-level architectural point of view, Europeana.eu is best characterized as a search engine and a database. It loads metadata delivered by providers and aggregators into a database, and uses that database to allow users to search for cultural heritage objects, and to find links to those objects. Various methods of searching and browsing the objects are offered, including a simple and an advanced search form, a timeline, and an openSearch API. It is also important to describe what Europeana.eu does not do, even though people sometimes expect it to. -

A Knowledge Discovery Approach
Semantic XML Tagging of Domain-Specific Text Archives: A Knowledge Discovery Approach Dissertation zur Erlangung des akademisches Grades Doktoringenieur (Dr.-Ing.) angenommen durch die Fakult¨at fur¨ Informatik der Otto-von-Guericke-Universit¨at Magdeburg von Diplom-Kaufmann Peter Karsten Winkler, geboren am 1. Oktober 1971 in Berlin Gutachterinnen und Gutachter: Prof. Dr. Myra Spiliopoulou Prof. Dr. Gunter Saake Prof. Dr. Stefan Conrad Ort und Datum des Promotionskolloquiums: Magdeburg, 22. Januar 2009 Karsten Winkler. Semantic XML Tagging of Domain-Specific Text Archives: A Knowl- edge Discovery Approach. Dissertation, Faculty of Computer Science, Otto von Guericke University Magdeburg, Magdeburg, Germany, January 2009. Contents List of Figures v List of Tables vii List of Algorithms xi Abstract xiii Zusammenfassung xv Acknowledgments xvii 1 Introduction 1 1.1 TheAbundanceofText ............................ 1 1.2 Defining Semantic XML Markup . 3 1.3 BenefitsofSemanticXMLMarkup . 9 1.4 ResearchQuestions ............................... 12 1.5 ResearchMethodology ............................. 14 1.6 Outline...................................... 16 2 Literature Review 19 2.1 Storage, Retrieval, and Analysis of Textual Data . ....... 19 2.1.1 Knowledge Discovery in Textual Databases . 19 2.1.2 Information Storage and Retrieval . 23 2.1.3 InformationExtraction. 25 2.2 Discovering Concepts in Textual Data . 26 2.2.1 Topic Discovery in Text Documents . 27 2.2.2 Extracting Relational Tuples from Text . 31 2.2.3 Learning Taxonomies, Thesauri, and Ontologies . 35 2.3 Semantic Annotation of Text Documents . 39 2.3.1 Manual Semantic Text Annotation . 40 2.3.2 Semi-Automated Semantic Text Annotation . 43 2.3.3 Automated Semantic Text Annotation . 47 2.4 Schema Discovery in Marked-Up Text Documents . -
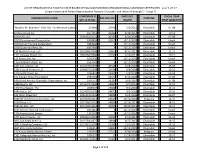
(BOE) Organizational Clearance Certificates- As of 1-27-17
LIST OF ORGANIZATIONS HOLDING STATE BOARD OF EQUALIZATION (BOE) ORGANIZATIONAL CLEARANCE CERTIFICATES - as of 1-27-17 (Organizations with Names Beginning with Numeric Characters and Letters A through C - Group 1) CORPORATE D DATE OCC FISCAL YEAR ORGANIZATION NAME BOE OCC NO. PURPOSE OR LLC ID NO. ISSUED FIRST QUALIFIED "Stephen M. Brammer" Post 705 The American Legion 233960 22442 3/2/2012 Charitable 07-08 10 Acre Ranch,Inc. 1977055 22209 4/30/2012 Charitable 10-11 1010 CAV, LLC 200615210122 20333 6/30/2008 Charitable 07-08 1010 Development Corporation 1800904 16010 12/11/2003 Charitable Unavl 1010 Senior Housing Corporation 1854046 3 12/11/2003 Charitable Unavl 1010 South Van Ness, Inc. 1897980 4 12/11/2003 Charitable Unavl 110 North D Street, LLC 201034810048 22857 9/15/2011 Charitable 11-12 1111 Chapala Street, LLC 200916810080 22240 2/24/2011 Charitable 10-11 112 Alves Lane, Inc. 1895430 5 12/11/2003 Charitable Unavl 1150 Webster Street, Inc. 1967344 6 12/11/2003 Charitable Unavl 11th and Jackson, LLC 201107610196 26318 12/8/2016 Charitable 15-16 12010 South Vermont LLC 200902710209 21434 9/9/2009 Charitable 10-11 1210 Scott Street, Inc. 2566810 19065 4/5/2006 Charitable 03-04 131 Steuart Street Foundation 2759782 20377 6/13/2008 Charitable 07-08 1420 Third Avenue Charitable Organization, Inc. 1950751 19787 10/3/2007 Charitable 07-08 1440 DevCo, LLC 201407210249 24869 9/1/2016 Charitable 15-16 1440 Foundation, The 2009237 24868 9/1/2016 Charitable 14-15 1440 OpCo, LLC 201405510392 24870 9/1/2016 Charitable 15-16 145 Ninth Street LLC -

“Ablueprintforbuildingonesandiego”
“A Blueprint for Building One San Diego” Mayor Kevin L. Faulconer 1 TRANSITION ADVISORY COMMITTEE RECOMMENDATIONS June 12, 2014 The Office of the Mayor would like to thank the following members of the One San Diego Transition Advisory Committee for volunteering their time to reviewing materials, attending meetings and providing valuable input for this report. ONE SAN DIEGO TRANSITION ADVISORY COMMITTEE CHAIRS Stephen Cushman Tony Young MEMBERS Susie Baumann Ben Katz Faith Bautista Leslie Kilpatrick Sam Bedwell Ure Kretowicz Blanca Lopez Brown Pastor Rick Laster Mark Cafferty Elyse Lowe Dr. Constance M. Carroll Lani Lutar Father Joe Carroll William D. Lynch Sharon Cloward Tony Manolatos Byeong Dae Kim Cindy Marten Aimee Faucett Brian Marvel Randy Frisch Vincent E. Mudd Ronne Froman Nicole Murray-Ramirez Gary Gallegos Bob Nelson Rick Gentry Joseph D. Panetta Bill Geppert Dan Stoneman Robert Gleason Russ Thurman Jeff Graham Rick Valencia Abdur-Rahim Hameed Kristen Victor Dan Hom Reverend Walter G. Wells Jennifer Jacobs Faye Wilson Tracy Jarman Christopher Yanov Susan Jester Barbara Ybarra Jeff Johnson Michael Zucchet 2 ONE SAN DIEGO TRANSITION ADVISORY COMMITTEE Table of Contents Executive Summary .................................................................................. 4 Subcommittee Reports ............................................................................. 7 Education & Youth Opportunity ............................................................ 7 Homeless & Housing Affordability ................................................... -

GROUNDCOVER NEWS and SOLUTIONS from the GROUND up FEBRUARY 2019 VOLUME 10 ISSUE 2 Your Donation Directly Benefits the Vendors
GROUNDCOVER NEWS AND SOLUTIONS FROM THE GROUND UP FEBRUARY 2019 VOLUME 10 ISSUE 2 Your donation directly benefits the vendors. INSIDE Please buy only from badged$2 vendors. Groundcover 2 transforms lives Letters to the Editor 2 Valentine of wonder 3 and discovery Malik Hall, high 4 achiever Trespass order 4 reform HCV Eviction 6 Prevention Program Black History Month 7 Cannabis 8 legalization Rising out of 8 depression Puzzles 9 Irish for a day 10 10 local adventures 11 for under $10 Free music concerts 11 in town Vendor Week Wheatberry Waldorf 12 2019 salad p. 5 www.GroundcoverNews.org 2 Groundcover News Groundcover News 3 February 2019 – Vol. 10, Issue 2 OPINION LOOKING WITHIN February 2019 – Vol. 10, Issue 2 Selling Groundcover News is work that transforms lives and working norms A valentine of wonder and discovery being sober and polite. We wear badges for an article running in the February He connects with his customers and them together with red on the bottom, cemetery of what had been a small illuminated medieval manuscripts, but pink in the middle and white on top, I women’s religious community in the they lacked the proof for this hunch. that identify us, and we have permits to issue of the Ann Arbor Observer. They becomes friends with them. He experi- by Rev Dr. by Susan Beckett sell. reminded me why this project of ours is ences success when he makes a differ- Martha Brunell only apply the glue to the middle fold Middle Ages. Beyond the graves and a And so the dominant image of male line and carefully align the fold lines few foundation stones, there was almost medieval monks as scribes has almost Publisher so important. -

The Michigan Review
THE MICHIGAN REviEW THE JOUR NAL OF CAMPUS AF FAirS AT THE UNivERSitY OF MICHIGAN 03.20.07 VOLUME XXV, ISSUE 10 Task Force Holds Features Final Meeting on Examining substance abuse at Day Before Michigan Spring Break P. 3 BY ADAM PAUL, ‘08 HE DIVERSITY BluEPRINTS Task A look at campus TForce, whose creation was announced the bars: why some fail day before winter break, held its final public fo- while others flourish rum the day before spring break. “This is not the ideal day as many have al- ready left for spring break,” said Provost and P. 12 Executive Vice President for Academic Affairs Teresa Sullivan to kick off the event. She ran the event with fellow Diversity Blueprints co- chair, Senior Vice Provost for Academic Af- News fairs Lester Monts. “Even though the last forum was on Feb- While Michigan ruary 23, the day before the break, we had a Barricades close off Washington Street for the Arena’s annual St. Patrick’s Day celebration. full list of speakers and a substantial audience,” bans preferences in The local bar faced opposition from the Ann Arbor City Council while planning for this said Sullivan, stressing that each of the four fo- admissions, year’s event. rums was held in an attempt to accommodate Wisconsin goes the greatest number of participants. holisitc with “I don’t see a lot of students here. It’s kind Councilmember, of disappointing; I guess they all left for Spring applications Break,” stated engineering student Darshan Karwat. Karwat explained that he had attended P. -

(FILED: March 17, 2021) CLUTCH CITY SPORTS
STATE OF RHODE ISLAND PROVIDENCE, SC. SUPERIOR COURT (FILED: March 17, 2021) CLUTCH CITY SPORTS & : ENTERTAINMENT, L.P. (d/b/a : TOYOTA CENTER) and ROCKET : BALL, LTD., : Plaintiffs, : : v. : C.A. No. PC-2020-05137 : AFFILIATED FM INSURANCE : COMPANY, : Defendant. : DECISION STERN, J. Before the Court is Defendant Affiliated FM Insurance Company’s Motion to Sever and Stay Discovery on Plaintiffs’ Bad Faith Claims, pursuant to Rule 42(b) of the Superior Court Rules of Civil Procedure. Plaintiffs object to the motion. Jurisdiction is pursuant to G.L. 1956 § 8-2-14. I Facts and Travel Plaintiffs operate the Toyota Center in downtown Houston, Texas, where they host fans and guests for various events. (Compl. ¶¶ 8-9.) Plaintiffs purchased an insurance policy (Policy) from Defendant Affiliated FM Insurance Company (AFMI) with coverage for property against “all risks of physical loss or damage, except as . [otherwise] excluded [in the Policy].” (Compl. ¶ 10; Compl. Ex. A (Policy), at Page 1 of 44.) The Policy included “Business Interruption Coverage[.]” (Policy, at Page 19 of 44.) When the presence of Covid-19 was discovered in the United States, federal, state, and local governments issued various orders restricting businesses, and by March 24, 2020, Toyota Center was closed to the public. (Compl. ¶¶ 25, 40-52.) Plaintiffs filed a claim with AFMI for business interruption coverage and alleged that Covid-19 caused physical loss and physical damage to their property. Id. ¶¶ 67, 70. After AFMI denied the claim, Plaintiffs filed this action alleging that AFMI breached various provisions of the Policy and the covenant of good faith and fair dealing and violated various laws by denying coverage. -
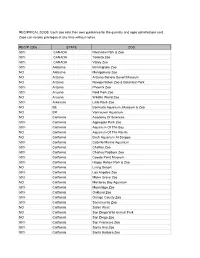
2006 Reciprocal List
RECIPRICAL ZOOS. Each zoo sets their own guidelines for the quantity and ages admitted per card. Zoos can revoke privileges at any time without notice. RECIP 2006 STATE ZOO 50% CANADA Riverview Park & Zoo 50% CANADA Toronto Zoo 50% CANADA Valley Zoo 50% Alabama Birmingham Zoo NO Alabama Montgomery Zoo NO Arizona Arizona-Sonora Desert Museum NO Arizona Navajo Nation Zoo & Botanical Park 50% Arizona Phoenix Zoo 50% Arizona Reid Park Zoo NO Arizona Wildlife World Zoo 50% Arkansas Little Rock Zoo NO BE Bermuda Aquarium, Museum & Zoo NO BR Vancouver Aquarium NO California Academy Of Sciences 50% California Applegate Park Zoo 50% California Aquarium Of The Bay NO California Aquarium Of The Pacific NO California Birch Aquarium At Scripps 50% California Cabrillo Marine Aquarium 50% California Chaffee Zoo 50% California Charles Paddock Zoo 50% California Coyote Point Museum 50% California Happy Hollow Park & Zoo NO California Living Desert 50% California Los Angeles Zoo 50% California Micke Grove Zoo NO California Monterey Bay Aquarium 50% California Moonridge Zoo 50% California Oakland Zoo 50% California Orange County Zoo 50% California Sacramento Zoo NO California Safari West NO California San Diego Wild Animal Park NO California San Diego Zoo 50% California San Francisco Zoo 50% California Santa Ana Zoo 50% California Santa Barbara Zoo NO California Seaworld San Diego 50% California Sequoia Park Zoo NO California Six Flags Marine World NO California Steinhart Aquarium NO CANADA Calgary Zoo 50% Colorado Butterfly Pavilion NO Colorado Cheyenne -

Corporate Social Responsibility in Professional Sports: an Analysis of the NBA, NFL, and MLB
Corporate Social Responsibility in Professional Sports: An Analysis of the NBA, NFL, and MLB Richard A. McGowan, S.J. John F. Mahon Boston College University of Maine Chestnut Hill, MA, USA Orono, Maine, USA [email protected] [email protected] Abstract Corporate Social Responsibility (CSR) is an area of organizational study with the potential to dramatically change lives and improve communities across the globe. CSR is a topic with extensive research in regards to traditional corporations; yet, little has been conducted in relation to the professional sports industry. Although most researchers and professionals have accepted CSR has a necessary component in evaluating a firm‟s performance, there is a great deal of variation in how it should be applied and by whom. Professional sports franchises are particularly interesting, because unlike most corporations, their financial success depends almost entirely on community support for the team. This paper employs a mixed-methods approach for examining CSR through the lens of the professional sports industry. The study explores how three professional sports leagues, the National Basketball Association (NBA), the National Football Association (NFL), and Major League Baseball (MLB), engage in CSR activities and evaluates the factors that influence their involvement. Quantitative statistical analysis will include and qualitative interviews, polls, and surveys are the basis for the conclusions drawn. Some of the hypotheses that will be tested include: Main Research Question/Focus: How do sports franchises -

An Analysis of the American Outdoor Sport Facility: Developing an Ideal Type on the Evolution of Professional Baseball and Football Structures
AN ANALYSIS OF THE AMERICAN OUTDOOR SPORT FACILITY: DEVELOPING AN IDEAL TYPE ON THE EVOLUTION OF PROFESSIONAL BASEBALL AND FOOTBALL STRUCTURES DISSERTATION Presented in Partial Fulfillment of the Requirements for the Degree Doctor of Philosophy in the Graduate School of The Ohio State University By Chad S. Seifried, B.S., M.Ed. * * * * * The Ohio State University 2005 Dissertation Committee: Approved by Professor Donna Pastore, Advisor Professor Melvin Adelman _________________________________ Professor Janet Fink Advisor College of Education Copyright by Chad Seifried 2005 ABSTRACT The purpose of this study is to analyze the physical layout of the American baseball and football professional sport facility from 1850 to present and design an ideal-type appropriate for its evolution. Specifically, this study attempts to establish a logical expansion and adaptation of Bale’s Four-Stage Ideal-type on the Evolution of the Modern English Soccer Stadium appropriate for the history of professional baseball and football and that predicts future changes in American sport facilities. In essence, it is the author’s intention to provide a more coherent and comprehensive account of the evolving professional baseball and football sport facility and where it appears to be headed. This investigation concludes eight stages exist concerning the evolution of the professional baseball and football sport facility. Stages one through four primarily appeared before the beginning of the 20th century and existed as temporary structures which were small and cheaply built. Stages five and six materialize as the first permanent professional baseball and football facilities. Stage seven surfaces as a multi-purpose facility which attempted to accommodate both professional football and baseball equally. -

The Life Cycle of Upper-Level Troughs and Ridges: a Novel Detection Method, Climatologies and Lagrangian Characteristics
Weather Clim. Dynam., 1, 459–479, 2020 https://doi.org/10.5194/wcd-1-459-2020 © Author(s) 2020. This work is distributed under the Creative Commons Attribution 4.0 License. The life cycle of upper-level troughs and ridges: a novel detection method, climatologies and Lagrangian characteristics Sebastian Schemm, Stefan Rüdisühli, and Michael Sprenger Institute for Atmospheric and Climate Science, ETH Zurich, Zurich, Switzerland Correspondence: Sebastian Schemm ([email protected]) Received: 12 March 2020 – Discussion started: 3 April 2020 Revised: 4 August 2020 – Accepted: 26 August 2020 – Published: 10 September 2020 Abstract. A novel method is introduced to identify and track diagnostics such as E vectors. During La Niña, the situa- the life cycle of upper-level troughs and ridges. The aim is tion is essentially reversed. The orientation of troughs and to close the existing gap between methods that detect the ridges also depends on the jet position. For example, dur- initiation phase of upper-level Rossby wave development ing midwinter over the Pacific, when the subtropical jet is and methods that detect Rossby wave breaking and decay- strongest and located farthest equatorward, cyclonically ori- ing waves. The presented method quantifies the horizontal ented troughs and ridges dominate the climatology. Finally, trough and ridge orientation and identifies the correspond- the identified troughs and ridges are used as starting points ing trough and ridge axes. These allow us to study the dy- for 24 h backward parcel trajectories, and a discussion of the namics of pre- and post-trough–ridge regions separately. The distribution of pressure, potential temperature and potential method is based on the curvature of the geopotential height vorticity changes along the trajectories is provided to give in- at a given isobaric surface and is computationally efficient. -

Brand Management Strategy for Korean Professional Football Teams
Brand Management Strategy for Korean Professional Football Teams : A Model for Understanding the Relationships between Team Brand Identity, Fans’ Identification with Football Teams, and Team Brand Loyalty A thesis submitted for the degree of Doctor of Philosophy By Ja Joon Koo School of Engineering and Design Brunel University March 2009 ACKNOWLEDGEMENTS I wish to thank many individuals without whom the completion of this dissertation would not have been possible. In particular, I would like to express my sincere appreciation to my supervisor Dr. Ray Holland who has supported my research with valuable advice and assistance. I also wish to extend express thankfulness for my college Gwang Jin Na. His valuable comments were much appreciated to conduct LISREL. In addition, my special thanks go to all respondents who completed my survey. Finally, but definitely not least, I would like to give my special appreciation to my family. To my parent, thank you for their endless love and support. I thank my brother, Ja Eun for his patience and encouragement throughout this process. Especially, my lovely wife, Mee Sun and son, Bon Ho born during my project have encouraged me to complete this dissertation not to give up. I am eternally grateful to all of you. i ABSTRACT This research recommends a new approach to brand strategy for Korean professional football teams, focusing on the relationships between team brand identity as the basic element of sports team branding, team brand loyalty as the most desirable goal, and identification between fans and teams as the mediator between identity and loyalty. Nowadays, professional football teams are no longer merely sporting organisations, but organisational brands with multi-million pound revenues.