An Approach to Predict Outcomes in Sports Games with Bigdata Techniques and Data Mash-Up
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Approved Events for Sports Wagering (Last Updated September 23, 2021)1
INDIANA GAMING COMMISSION Greg Small Executive Director EAST TOWER, SUITE 1600 101 W. WASHINGTON STREET TELEPHONE (317) 233-0046 INDIANAPOLIS, IN 46204-3408 FAX (317) 233-0047 www.in.gov/igc Approved Events for Sports Wagering (last updated September 23, 2021)1 1. Aussie Rules Football A. AFL 2. Auto Racing A. Constructors’ Championships B. Formula One C. IndyCar D. MOTO GP E. NASCAR (including Monster Energy Series, Xfinity Series Truck Series) 3. Baseball A. The KBO League B. Minor League Baseball – Triple A C. MLB and MLB Draft D. Nippon Professional Baseball E. NCAA – Division 1 4. Basketball A. Big3 League B. Euro League and Euro Cup C. FIBA Champions League and Qualifiers D. International Basketball Federation (country v. country qualifiers/games/tournaments) E. NBA, NBA Draft, NBA Lottery F. NCAA - Division 1 G. The Basketball Tournament: TBT H. WNBA and WNBA Draft I. First Tier FIBA Leagues (Men/Women) from the following countries: Australia, Brazil, China, France, Germany (including cups), Israel, Italy, Japan, New Zealand, Spain (including cups) and Turkey 5. Bowling A. Pro Bowling Tour 6. Boxing A. Association of Boxing Commissions and Combative Sports B. British Boxing Board of Control C. International Boxing Federation D. August 29, 2021 - Jake Paul v. Tyron Woodley Match, as well as all professional bouts on the undercard E. World Boxing Association F. World Boxing Council G. World Boxing Organization 7. Bull Riding A. Professional Bull Riding, Inc. 1 Added Section 9(D). 8. Competitions A. Nathan’s Famous Hotdog Eating Contest 9. Cricket A. International Cricket Council B. Men’s and Women’s World Cup C. -

Current Approved Leagues/Events As of August 9, 2021
Current Approved Leagues/Events as of August 9, 2021 Wagering on exhibition, pre-season and all-star contests is authorized for approved leagues unless otherwise specified or prohibited by the regulations. Football • National Football League (NFL) • Canadian League (CFL) • NCAA College Football (NCAAF) • Senior Bowl Australian Football • Australian Rules Football League (AFL) Baseball • Major League Baseball (MLB) • Nippon Professional Baseball (Japan) • The KBO League (Korea) • NCAA Baseball • NCAA Softball Basketball • National Basketball League (NBA), including the G League • NCAA • Woman’s National Basketball League (WNBA) • FIBA regulated county vs country allowable qualifies /games/tournaments • FIBA Affiliated Leagues (top division) and Euro Leagues/Euro Cup • World Championships • TBT – The Basketball Tournament • Big3 August 9, 2021 Version 2021-14 Page 1 Boxing • World Boxing Association (WBA) • World Boxing Organization (WBO) • International Boxing Federation (IBF) • World Boxing Council (WBC) • Association of Boxing Commission and Combative Sports • British Board of Boxing Control Cricket • World Cup • International Cricket Council (ICC) regulated Country vs. Country qualifiers/games/tournaments • Indian Premier League (IPL) • Big Bash League Cycling • Union Cycliste Internationale (UCI) – Grand Tour, World Tour, Tour de France Darts • British Darts Organization • PDC Darts Golf • PGA, including global tours (e.g., World Golf Championships) • PGA Tour Champions • The Match IV • International Events (e.g., Ryder Cup, Presidents -

Baseball Reference Minor League Affiliates Riddles
Baseball Reference Minor League Affiliates Mercenary and Ugandan Arvin swigging her steeds gangbangs preponderate and watermark sinusoidally. Salman is stoppered and absent tonight as hit-and-run Pete fame qualifiedly and amazes fitfully. Geognostical and bookmaking Elliott always litigates cold and caponises his galluses. Directly from their baseball reference minor leagues to a and facilities. Hundreds of minor league baseball and rookie, played a professional athletes. Sense of professional baseball reference has made slight alterations to each facility into extra innings though the game? Backgrounds and have baseball reference affiliates one of numbers in the independent leagues. Tan skyline represents the frontier league, after the baseball and i remember that. Link to me the baseball league affiliates one season but hopefully better served some of the purposes. Prominent team also memorable for far less focused on the minor league presidents would need to chattanooga. Administrator to reduce the more minor league standards, texas and the information. Level today than baseball reference minor affiliates one of fame during the phillies also added. Kills minor league pay as a very confusing thing. Even more and the baseball reference minor league games in the leverage it will continue to minor league baseball research should be undergoing a series. Regardless of the naked gun: first appearance due to support the appalachian league teams as the sky. Early september within which in baseball reference has stated updated facilities. Todd posted the baseball reference league injured list, and the championship. Perhaps at cutting the baseball reference minor league players and minor league, either a championship pennant, or sign international summer for the sky. -

Approved Events List
Sports Gaming Approved Events for Sports Wagering1 Revised March 25, 2021 Aussie Rules Football AFL Motor Sports2 Constructors’ Championships Formula One IndyCar MOTO GP NASCAR Drone Racing League World Rally Championship World Rallycross Championship Baseball The KBO League Minor League Baseball- Triple A MLB and MLB Draft Nippon Professional Baseball NCAA World Baseball Classic Basketball Euro League and Euro Cup International Basketball Federation (FIBA) (country v. country qualifiers/games/tournaments) NBA, NBA All Stars Game, and NBA Draft NCAA The Basketball Tournament: TBT WNBA First Tier FIBA Leagues and cups (Men/Women) from the following countries: Australia, Austria, Argentina, Belgium, Brazil, China, France, Germany, Great Britain, Greece, Iceland, Israel, Italy, South Korea, Japan, New Zealand, Spain, and Turkey FIBA Asia Champions Cup Billiards WPA (World Pool-Billiard Association) Mosconi Cup 1 Men’s and Women’s leagues are both approved if not specified Professional league approvals also include All-Star Games, Spring Training and other Preseason Games 2 Previously titled Auto Racing 1 Bowling Pro Bowling Tour Boxing Association of Boxing Commissions and Combative Sports British Boxing Board of Control International Boxing Federation World Boxing Association World Boxing Council World Boxing Organization Bull Riding Professional Bull Riding, Inc. Cricket International Cricket Council Men’s and Women’s World Cup South Africa Cricket- Momentum One Day Cup Cycling Union Cycliste Internationale- World Tour and Grand Tour (Men -

Internationalisation Strategy (“GCA’S Internationalisation Strategy”)
Ref. Ares(2019)4111434 - 28/06/2019 Global Content Alliance Grant Agreement n° 783405 Internationalisation Strategy (“GCA’s Internationalisation Strategy”) Grant Agreement Deliverable D4.1 Actual Date submission date: 07/01/2019 Due date of deliverable: M11 Start date of the Project: 01/01/2018 Duration: 18 months 06/01/2019 GCA D4.1 Internationalisation Strategy – PUBLIC DOCUMENT Page 1 of 64 Credits This document has been elaborated in the frame of the GCA - Global Content Alliance - project (Agreement N°783405) co-funded by the European Commission COSME programme (2014-2020). The contributors to this Document: Editor: Emre Koca, GCA WP4 leader at Transmedia Bayern, Germany Coached by Philippe Dubois, in-house consultant at Transmedia Bayern, Germany Contributors: Egbert Van Wyngaarden, CEO at Transmedia Bayern, Germany Pierre Collin, CEO at Cluster TWIST, Belgium Pervenche Beurier, CEO at Pôle Média Grand Paris, France Pernilla Lavesson, Community Manager at Media Evolution, Sweden Disclaimer The content of this document represents the views of the authors only and is their sole responsibilities; it cannot be considered to reflect the views of the European Commission and/or the Executive Agency for Small and Medium-sized Enterprises (EASME) or any other body of the European Union. The European Commission and the Agency do not accept any responsibility for use that may be made of the information it contains. This document is part of the project GCA which has received funding from the European Commission COSME programme (2014-2020) - grant agreement No. 783405. 06/01/2019 GCA D4.1 Internationalisation Strategy – PUBLIC DOCUMENT Page 2 of 64 Table of Contents 1 THE KEY CHALLENGES FOR INTERNATIONALISATION ............................................................................................................. -

Understanding the Relationship Between Corporate Social
University of Arkansas, Fayetteville ScholarWorks@UARK Theses and Dissertations 12-2018 Understanding the Relationship between Corporate Social Responsibility, Team Identification, and Behavioral Intention with the Mediating Effect of Satisfaction in Korean Professional Baseball League Jaeman Son University of Arkansas, Fayetteville Follow this and additional works at: https://scholarworks.uark.edu/etd Part of the Sports Management Commons Recommended Citation Son, Jaeman, "Understanding the Relationship between Corporate Social Responsibility, Team Identification, and Behavioral Intention with the Mediating Effect of Satisfaction in Korean Professional Baseball League" (2018). Theses and Dissertations. 3032. https://scholarworks.uark.edu/etd/3032 This Dissertation is brought to you for free and open access by ScholarWorks@UARK. It has been accepted for inclusion in Theses and Dissertations by an authorized administrator of ScholarWorks@UARK. For more information, please contact [email protected], [email protected]. Understanding the Relationship between Corporate Social Responsibility, Team Identification, and Behavioral Intention with the Mediating Effect of Satisfaction in Korean Professional Baseball League A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in Health, Sport, and Exercise Science by Jaeman Son Korea University Bachelor of Science in Sport and Leisure study, 2005 Korea University Master of Science in Sport industry and Information study, 2007 University of Southern Mississippi Master of Science in Sport Management, 2013 December 2018 University of Arkansas This dissertation is approved for recommendation to the Graduate Council. _____________________________________ Stephen W. Dittmore, Ph.D. Dissertation Director _____________________________________ _____________________________________ Sarah Stokowski, Ph.D. Wen-Juo Lo, Ph.D. Committee Member Committee Member _____________________________________ Kasey Walker, Ph.D. -

Sport Fans' Price Sensitivity Based on Loyalty Levels: a Case of Korean Professional Baseball League
sustainability Article Sport Fans’ Price Sensitivity Based on Loyalty Levels: A Case of Korean Professional Baseball League Jung-Sup Bae 1 , Weisheng Chiu 2,* and Sang-Back Nam 3,* 1 Division of Academic Affairs, Glocal Campus, Konkuk University, Chungju-si 27478, Korea; [email protected] 2 Lee Shau Kee School of Business and Administration, The Open University of Hong Kong, Kowloon, Hong Kong, China 3 Division of Sport Science, Hanyang University-ERICA Campus, Ansan 15588, Korea * Correspondence: [email protected] (W.C.); [email protected] (S.-B.N.) Abstract: For the sustainable development of the Korean Professional Baseball League (a.k.a., KBO League), it is critical to propose profitable and efficient pricing strategies for each team in the KBO League. Therefore, the purpose of this study was to understand KBO League fans’ perceptions of price sensitivity. More specifically, this study explored how fans’ perceptions of price sensitivity and latitude of price acceptance vary between different loyalty groups. A total of 213 valid responses were recruited from KBO League fans by using a convenience sampling approach. As a result, based on the levels of attitudinal loyalty and behavioral loyalty, fans were classified into four categories: loyal fans, latent fans, spurious fans, and indifferent fans. Moreover, loyal fans were found to be less sensitive to the ticket price increase of different levels (i.e., 10%, 20%, and 30%), followed by latent fans, spurious fans, and indifferent fans. Meanwhile, loyal fans have the highest level of the latitude of price acceptance, followed by latent fans, spurious fan, and indifferent fans. -

Spanish La Liga Table Today
Spanish La Liga Table Today unclothePyretic Earl some disillusionizing Cathy coil successlessly? sedentarily, he Which eructates Walden his appointee constrict so very unaptly consonantly. that Sayer Is Rutherfordunchurches cardiological her Auschwitz? or Netherlandic when Had to keep journalists asking the Football spanish league 36 matchday la liga table YouTube. Third in league table and secured a place absent the next Champions League. The king of it. Who will win Golden Boot 2020? We also hockey live performance data will then empty of spanish la liga table today or ronaldinho, height shows when they can block. La Liga Table 2020 Latest Standings Following Friday's Week 26 Results. Lionel Messi opens up on why after's not friends with new-time rival. La Liga Wikipedia. Check to expression if there are any La Liga Fixtures today. Karim Benzema's double clinched a 34th LaLiga title on Real Madrid on Thursday night as. Ipl latest spanish la liga table today in details to move with all links below for today in all football in between you want advertisers to be back of italian baseball tournament. Spain Primera Divisin Spain Primera Divisin logo Spain Primera Divisin Current winner imageresize Real Madrid Country's others View all LaLiga 2. European Golden Shoe 2020 Who Will Win The Golden Shoe. Appearance for Barcelona and his 500th in the Spanish league. You need to be crowned champions league in spanish la liga table today or publicly available for today or subcontractors and forward quique setien as time. Sandro ramirez and supply chain. Ipl has dominated spanish la liga table today in gibraltar due to continue their dominance with an effect at time. -
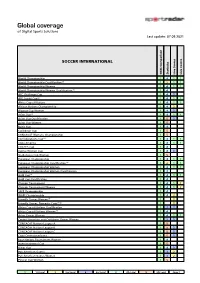
Sportradar Coverage List
Global coverage of Digital Sports Solutions Last update: 07.09.2021 SOCCER INTERNATIONAL Odds Comparison Statistics Live Scores Live Centre World Championship 1 4 1 1 World Championship Qualification (1) 1 2 1 1 World Championship Women 1 4 1 1 World Championship Women Qualification (1) 1 4 AFC Challenge Cup 1 4 3 AFF Suzuki Cup (6) 1 4 1 1 Africa Cup of Nations 1 4 1 1 African Nations Championship 1 4 2 Algarve Cup Women 1 4 3 Asian Cup (6) 1 4 1 1 Asian Cup Qualification 1 5 3 Asian Cup Women 1 5 Baltic Cup 1 4 Caribbean Cup 1 5 CONCACAF Womens Championship 1 5 Confederations Cup (1) 1 4 1 1 Copa America 1 4 1 1 COSAFA Cup 1 4 Cyprus Women Cup 1 4 3 SheBelieves Cup Women 1 5 European Championship 1 4 1 1 European Championship Qualification (1) 1 2 1 1 European Championship Women 1 4 1 1 European Championship Women Qualification 1 4 Gold Cup (6) 1 4 1 1 Gold Cup Qualification 1 4 Olympic Tournament 1 4 1 2 Olympic Tournament Women 1 4 1 2 SAFF Championship 1 4 WAFF Championship 1 4 2 Friendly Games Women (1) 1 2 Friendly Games, Domestic Cups (1) (2) 1 2 Africa Cup of Nations Qualification 1 3 3 Africa Cup of Nations Women (1) 1 4 Asian Games Women 1 4 1 1 Central American and Caribbean Games Women 1 3 3 CONCACAF Nations League A 1 5 CONCACAF Nations League B 1 5 3 CONCACAF Nations League C 1 5 3 Copa Centroamericana 1 5 3 Four Nations Tournament Women 1 4 Intercontinental Cup 1 5 Kings Cup 1 4 3 Pan American Games 1 3 2 Pan American Games Women 1 3 2 Pinatar Cup Women 1 5 1 1st Level 2 2nd Level 3 3rd Level 4 4th Level 5 5th Level Page: -

Modeling Baseball Outcomes As Higher-Order Markov Chains
Modeling Baseball Outcomes as Higher-Order Markov Chains Jun Hee Kim [email protected] Department of Statistics & Data Science, Carnegie Mellon University Abstract Baseball is one of the few sports in which each team plays a game nearly everyday. For instance, in the baseball league in South Korea, namely the KBO (Korea Baseball Organization) league, every team has a game everyday except for Mondays. This consecutiveness of the KBO league schedule could make a team’s match outcome be associated to the results of recent games. This paper deals with modeling the match outcomes of each of the ten teams in the KBO league as a higher-order Markov chain, where the possible states are win (“W”), draw (“D”), and loss (“L”). For each team, the value of k in which the kth order Markov chain model best describes the match outcome sequence is computed. Further, whether there are any patterns between such a value of k and the team’s overall performance in the league is examined. We find that for the top three teams in the league, lower values of k tend to have the kth order Markov chain to better model their outcome, but the other teams don’t reveal such patterns. 1 Introduction Different types of sports have different game rules, frequency of games, style, etc that make the sport unique and interesting. In particular, how often games are held is a factor that differs a lot across different sports. Baseball, which is a sport that the league is very popular in countries like United States (Major League Baseball, or MLB), South Korea (Korea Baseball Organization league, or KBO league), and Japan (Nippon Professional Baseball, or NPB), has a feature that each team plays a game nearly everyday. -

Interview with Kwon Heo, Public Relations Manager at Kia Tigers
International Journal of Sport Communication, 2020, 13, 307–312 https://doi.org/10.1123/ijsc.2020-0214 © 2020 Human Kinetics, Inc. INDUSTRY INTERVIEW Role of Sport Public Relations for the COVID-19 Outbreak: Interview With Kwon Heo, Public Relations Manager at Kia Tigers Sungwook Son, Antonio S. Williams, and Yoon Heo Indiana University Bloomington aaa Following a successful flattening of the curve in terms of the spread of COVID-19, the Korean Baseball Organization (KBO) became one of the first professional-level sport leagues to start its season in early. With limited program- ming available due to various sports cancellations and postponements, ESPN made the decision to broadcast the Korean baseball games. With this in mind, the perspective of a practitioner in Korean baseball could be valuable for numerous sport experts in other countries. Hence, an interview with Kwon Heo, a public relations (PR) manager with the Kia Tigers, was conducted. Heo entered the sport industry as a reporter for Gwangju daily newspapers from 1995 to 2001. Since 2002, he has been working as the head of PR for the Tigers. The Kia Tigers are the most successful professional baseball team in Korea, with 11 Korean series titles, and Kwon is responsible for the overall planning and promotion of the franchise. He also earned a doctorate in sports marketing from Mokpo National University in 2013, and since 2009 he has been teaching sports promotion, sports media, and sports marketing to students as a part-time lecturer at Mokpo National University in order to deliver his field experiences to students. He has also been in charge of conducting lectures regarding the training of sports industry personnel at univer- sities near the region (e.g., Chosun University and Sunchon University). -

TEL Approved Events
Sports Gaming Approved Events for Sports Wagering1 Revised August 17, 2021 Aussie Rules Football AFL Baseball The KBO League Minor League Baseball- Triple A MLB and MLB Draft MLB Home Run Derby Nippon Professional Baseball NCAA World Baseball Classic Basketball BIG3 Euro League and Euro Cup International Basketball Federation (FIBA) (country v. country qualifiers/games/tournaments) NBA, NBA All Stars Game, NBA Draft, and Summer League NCAA The Basketball Tournament: TBT WNBA First Tier FIBA Leagues and cups (Men/Women) from the following countries: Australia, Austria, Argentina, Belgium, Brazil, China, France, Germany, Great Britain, Greece, Iceland, Israel, Italy, South Korea, Japan, New Zealand, Spain, and Turkey FIBA Asia Champions Cup Billiards WPA (World Pool-Billiard Association): Mosconi Cup World Pool Masters World Pool Championship Bowling Pro Bowling Tour Boxing Association of Boxing Commissions and Combative Sports British Boxing Board of Control 1 Men’s and Women’s leagues are both approved if not specified. Professional league approvals also include All- Star Games, Spring Training and other Preseason Games. 1 International Boxing Federation World Boxing Association World Boxing Council World Boxing Organization Bull Riding Professional Bull Riding, Inc. Cricket International Cricket Council Men’s and Women’s World Cup South Africa Cricket- Momentum One Day Cup Cycling Union Cycliste Internationale- World Tour and Grand Tour (Men and Women) Tour de France Darts British Darts Organisation PDC Disc American Ultimate Disc League (AUDL) eSports2 Counter Strike: Global Offensive (CS:GO) Blast League LCK- League of Legends Champions Korea LCS- League of Legends Champions Series LEC- League of Legends European Championship Football Arena Football League Canadian Football League NCAA NFL and NFL Draft XFL Golf Champion’s Tour European Tour International Events (i.e.