The Effect of Leaded Gasoline on Elderly Mortality
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Race Breakdown
Race Breakdown Event Date Track Fast Qualifier First Second Third 1 4/26/1997 Anderson Speedway (IN) Biff George Brian Ross Bill Baird J.R. Roahrig 2 5/4/1997 Salem Speedway (IN) Brian Ross Kenny Tweedy Brian Rievley J.R. Roahrig 3 6/20/1997 Lucas Oil Raceway (IN) Kenny Tweedy Kenny Tweedy J.R. Roahrig Josh Clemons 4 7/18/1997 Lucas Oil Raceway (IN) Kenny Tweedy Brian Ross Chet Fillip Jim Crabtree Jr. 5 8/15/1997 Anderson Speedway (IN) Ray Skillman Brian Ross Brian Rievley Kenny Tweedy 6 9/1/1997 Winchester Speedway (IN) Todd Oliver Brian Rievley Kenny Tweedy Rick Turner 7 9/20/1997 Anderson Speedway (IN) Brian Ross Brian Ross Kenny Tweedy Chet Fillip 8 10/12/1997 Salem Speedway (IN) Kenny Tweedy Chet Fillip Ray Skillman Royce Mason 9 4/25/1998 Anderson Speedway (IN) Kenny Tweedy Ken Weaver Bobby Blount Brian Rievley 10 5/3/1998 Salem Speedway (IN) Ken Weaver Kenny Tweedy Brian Rievley Brian Ross 11 5/16/1998 Anderson Speedway (IN) Jim Cooper Jim Cooper Bobby Blount Matt Hagans 12 6/7/1998 Salem Speedway (IN) Brian Ross Dave Jackson Matt Hagans Tony Johnson 13 6/13/1998 Anderson Speedway (IN) Ray Skillman Jim Cooper Scott Neal Bobby Blount 14 6/27/1998 Winchester Speedway (IN) Chet Fillip Chet Fillip Scott Neal Kenny Tweedy 15 7/5/1998 Salem Speedway (IN) Ray Skillman Jim Cooper Matt Hagans Scott Neal 16 7/11/1998 Angola Motorsport Speedway (IN) Larry Zent Bobby Blount Scott Hantz Brian Rievley 17 8/1/1998 Anderson Speedway (IN) Jim Crabtree Jr. -
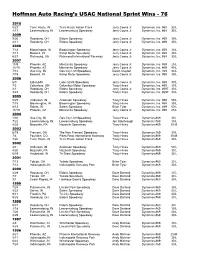
Hoffman Auto Racing's USAC National Sprint Wins
Hoffman Auto Racing’s USAC National Sprint Wins - 76 2010 5/27 Terre Haute, IN Terre Haute Action Track Jerry Coons Jr. Dynamics, Inc. #60 30 L 4/17 Lawrenceburg, IN Lawrenceburg Speedway Jerry Coons Jr. Dynamics, Inc. #69 30 L 2009 9/26 Rossburg, OH Eldora Speedway Jerry Coons Jr. Dynamics, Inc. #69 30 L 4/11 Rossburg, OH Eldora Speedway Jerry Coons Jr. Dynamics, Inc. #69 30 L 2008 7/18 Bloomington, IN Bloomington Speedway Jerry Coons Jr. Dynamics, Inc. #69 30 L 7/17 Boswell, IN Kamp Motor Speedway Jerry Coons Jr. Dynamics, Inc. #69 30 L 6/27 Richmond, VA Richmond International Raceway Jerry Coons Jr. Dynamics, Inc. #69 30 L 2007 11/9 Phoenix, AZ Manzanita Speedway Jerry Coons Jr. Dynamics, Inc. #69 25 L 11/10 Phoenix, AZ Manzanita Speedway Jerry Coons Jr. Dynamics, Inc. #69 40 L 7/13 Gas City, IN Gas City I-69 Speedway Daron Clayton Dynamics, Inc. #69 30 L 7/19 Boswell, IN Kamp Motor Speedway Jerry Coons Jr. Dynamics, Inc. #69 30 L 2006 6/9 Eldon,MO Lake Ozark Speedway Jerry Coons Jr. Dynamics, Inc. #69 30 L 7/5 Columbus, OH Columbus Motor Speedway Tracy Hines Dynamics, Inc. #69 30 L 4/1 Rossburg, OH Eldora Speedway Jerry Coons Jr. Dynamics, Inc. #69T 30 L 9/23 Rossburg, OH Eldora Speedway Tracy Hines Dynamics, Inc. #69T 30 L 2005 5/25 Anderson, IN Anderson Speedway Tracy Hines Dynamics, Inc. #69 50 L 7/15 Bloomington, IN Bloomington Speedway Tracy Hines Dynamics, Inc. #69 30 L 8/13 Salem, IN Salem Speedway Brian Tyler Dynamics, Inc. -

Professional Race Driver Resume
Professional Race Driver Resume [email protected] www.ZacharyTinkle.com Tinkle Family Racing 8926 N Greenwood Ave #153 Niles, IL 60714 513-300-8331 IntroductionIntroduction My name is Zachary Tinkle. I’m an up and coming pro race car driver from Park Ridge, IL and currently race a pro late model with Lorz Motorsports in the JEGS/ CRA All-Stars Tour series. I finished my 2017 season by running more the 2,000 laps at five different tracks to train in the late model while competing and winning the 2017 Central States Region Super Cups Championship along with the Fastest Qualifier for the Year award. I also competed in two late model races to prepare for my move up in 2018 to a full time season in the late model. My ultimate goal is to race the NASCAR Monster Energy Series with a top level team. What sets me apart from other racers is my YouTube channel with a loyal fan base. We also have a great email list of people from over 30 states and several countries that sign up for hero cards on my website. I’m passionate about all aspects of racing… history, trivia, video games, and of course, suiting up and going out on the track to race. PersonalPersonal InfoInfo Age: 15 Height: 5’1” Weight: 125 Hometown: Park Ridge, IL Hobbies: Collecting die cast cars, racing history buff, video games: iRacing, Roblox, etc. Years Racing: Entering 6th year (2018) Current Ride(s): Lorz Motorsports #53 Late Model Current Tracks (2018): Auto City Speedway, Baer Field Motorsports Park, Berlin Raceway, Bristol Motor Speedway, Dixie Motor Speedway, Kil-Kare Speedway, Lebanon I-11 Speedway, Lucas Oil Raceway, Owosso Speedway, Salem Speedway, Winchester Speedway Current Series: Champion Racing Association: JEGS/CRA Late Model All-Stars Tour Charities: Pet Rescue, Reading Programs, Cancer Research, Drive To End Hunger/Feeding America Interesting Facts: I’m a racing history buff. -

30 YEARS of NASCAR at EVERGREEN, and the FRED BUTLER - JOHN GAY “MEMORIAL” HALL of FAME by Program Co-Editor Benson Chandler
30 YEARS OF NASCAR AT EVERGREEN, AND THE FRED BUTLER - JOHN GAY “MEMORIAL” HALL OF FAME By Program Co-Editor Benson Chandler Evergreen Speedway celebrates 50 years of (what I like to call) “the modern era” of Saturday night racing, in 2015. It was 1965 when Figure-8 and Mini-stock racers were officially organized, and the two racing “clubs”, F.E.A.R. and F.S.C.R.A., were formed. It was 30 years ago that NASCAR came aboard, and this Evergreen Speedway “Hall of Fame” finally created! “For outstanding dedication and contributions to auto racing” …was sometimes printed on the annual award, and always on the header in the program each season. The Hall of Fame was created by (then) Promoter Mickey Beadle in 1985, and with that goal in mind, the “Hall” has consistently inducted special people, most of them exceptional racers, or long time employees. Several exceptional supporters of our track have also been inducted over the years. In fact, the Hall of Fame was re-dedicated in 1988, after the tragic double loss of super supporter Fred Butler, and Super-stock racer, John Gay. Both were inducted into the Hall that year posthumously, and their names added to the top of the Hall of Fame “Memorial” header here and in the Program, so both might remain in our hearts, forever. The latest Hall of Fame inductees were Ron Daggett and Don Scriver. Learn about them both under the year 2014, the same year we lost 3 other Hall of Fame members, Mick Tomlin, Gordy Stewart and Don Perry, as we continue through our second quarter-century of NASCAR at Evergreen Speedway, guided now by Doug and Traci Hobbs, and Highroad Promotions Co. -

Current Version: June 9, 2021 2021 Race Event and Year-End Awards Guide Introduction Current February 24, 2021
Current Version: June 9, 2021 2021 Race Event and Year-End Awards Guide Introduction Current February 24, 2021 With this presentation, you will be introduced to the ARCA Corporate Partners and Participating Manufacturers Contingency Awards Program. The 2021 Corporate Partners and Participating Manufacturers Contingency Program is the Series Prize Money and Decal Program, the contingency program which allows sponsors to support the drivers, team members, and car owners with per race and year end awards. The 2021 Corporate Partners and Participating Manufacturers Contingency Program rewards teams and drivers for displaying sponsor decals, and for utilizing sponsor products and services. Sponsor representation includes display of decal, and presence in victory lane, plus the opportunity to integrate components into the core of the sport. All Posted Awards and Point Fund earnings won by any team member (driver, crew chief, etc.) shall be paid by ARCA (or Sponsoring Entity), to the registered/entered team owner via ACH transfer of funds. Any participant earning points or winning specific awards as a team member for more than one team/owner in a single season shall have all awards payable to team owner(s) based on the number of race points/awards earned per team. The team owner, and not ARCA, shall be solely responsible for the distribution of such Posted Awards to the respective team member. This shall also apply to Year-End and Point Fund Awards unless otherwise specified. 1 Eligibility requirements for Owner Point Fund are: • Display ARCA MENARDS SERIES, ARCA, Menards, Bounty, Richmond, Reese's, Sunoco, K&N Filters, Sioux Chief and Valvoline decal on both sides of car • General Tire Decal above front wheel wells, both sides of car, rear of spoiler and front of car, both sides (see page 7). -

Zachary Tinkle
Introduction I’m Zachary Tinkle - a pro late model race car driver from Speedway, Indiana currently racing in the JEGS/ CRA All-Stars Tour (Champion Racing Association) with my family team, Tinkle Family racing. In my 2019 season, I won the CRA Late Model Sportsman Championship along with the Anderson Speedway Late Model Championship while also getting Rookie of the Year honors. In my 2018 CRA rookie late model season, I finished 5th in the CRA Late Model Sportsman championship and also received the Sportsman of the Year (voted by officials) and Most Popular Driver (voted by fans) awards. To prepare for my first late model season, I ran over 2,600 test session laps and two races while competing for and winning the CSR MiniCup Championship in 2017. Outside of the race car, I support pet causes, encourage people to become racing fans, and promote literacy. My ultimate goal is to compete in the upper echelons of racing with a top level team. What sets me apart from other racers is my marketing that has created an extensive and loyal fan base that rivals what drivers are doing in much higher series. I’m passionate about all aspects of racing… history, trivia, video games, and of course, suiting up and going out on the track to race. Personal Info Age: 17 Height: 5’7” Weight: 140 Hometown: Speedway, IN Hobbies: Collecting die cast cars, racing history buff, iRacing Years Racing: 8th year (2020) Current Ride(s): #53 Pro Late Model Current Tracks (2020): Anderson Speedway, Berlin Raceway, Birch Run, I-44 Lebanon Speedway, Lucas Oil Raceway, Jennerstown Speedway, Nashville Fairgrounds Speedway, Winchester Speedway Current Series: Champion Racing Association: JEGS/ CRA Pro Late Model All-Stars Tour Charities: Pet Rescue, Reading Programs, Cancer Research, Feeding America, Racing Museums Interesting Facts: I’m a racing history buff. -

2015 National Qualifier Dates
2015 National Qualifier Dates Asphalt Legend Qualifier Dates: Speedway (State) Date Texas Motor Speedway, TX – April 11th Irwindale Speedway, CA – April 11th Wiscasset Speedway, ME – May 16th Charlotte Motor Speedway, NC – May 21st Hawkeye Downs, IA – May 22nd Sunny South Raceway, AL – May 23rd Evergreen Speedway, WA – May 23rd Evergreen Speedway, WA – May 24th Stockton 99 Speedway, CA – June 6th Texas Motor Speedway, TX – June 6th Seekonk Speedway, MA – June 12th Tucson Speedway, AZ – June 20th Colorado National, CO – July 3rd East Carolina Motor Speedway – July 3rd Big Country Speedway, WY – July 4th Hythe Motor Speedway, AB – July 4th Atlanta Motor Speedway, GA – July 9th Chemung Speedway, NY – July 10th Flat Rock Speedway, MI – July 18th Elko Speedway, MN – July 18th Stateline Speedway, ID – July 25th Auto Clearing Motor Speedway, SK – July 25th Meridian Speedway, ID – July 30th Meridian Speedway, ID – August 1st Bethel Motor Speedway, NY – August 1st Rocky Mountain Raceway, UT – August 8th Rocky Mountain Raceway, UT – August 9th Scotia Speedworld, NS – August 14th Peterbourough Speedway, ON – August 15th Evans Mills, NY – August 15th Sportsdrome Speedway, IN – August 15th Southern National Speedway, NC – August 15th Anderson Speedway, SC – August 21st New Hampshire Motor Speedway, NH – August 22nd Shenandoah Speedway, VA – August 22nd Anderson Speedway, IN – August 22nd Highway 92, NE – August 28th Riverhead Raceway, NY – August 29th Dells Raceway Park, WI – August 29th South Sound Speedway, -

2015 Performance Partners
PERFORMANCE 20120155 PARTNERS MANUFACTURERS CONTINGENCY PROGRAM Welcome to the Automobile Racing Club of America Founded in 1953 as a Midwest-based stock car racing series, ARCA has grown to represent the most diverse nationally touring stock car series anywhere. ARCA is the second-longest running championship racing series in the country, and remains consistently dedicated to fans, competitors, and sponsors at the highest levels of the sport. ARCA founder John Marcum’s association with NASCAR founder Bill France Sr. predates the sanctioning body itself, and the two remain joined on companion weekends at the same high-profile racing venues that host NASCAR’s most elite series. Our history is a celebration of integrity, stability, tradition, respect, and success. Table of Contents Program Introduction ..........................................................................................pg. 1 The ARCA Racing Series presented by Menards .............................................pg. 2-8 Sponsor Broadcast Exposure & Decal Compliance ...........................................pg. 9 Media Metrics ....................................................................................................pg. 10 Scope of Competition ........................................................................................pg. 11 ARCA CRA Super Series / ARCA Midwest Tour ............................................pg. 12-15 ARCA, CRA and Midwest Tour Cars ..................................................................pg. 16 Contact Information ..........................................................................................pg. -

ISC-45 05 Annual FINAL.Qxd
ISC-45 COVER_comp_1.qxd 2/10/06 12:44 PM Page 1 THE FACE OF AMERICAN MOTORSPORTS International Speedway Corporation International Speedway Corporation 49th Annual Report 2005 Post Office Box 2801 Daytona Beach, Florida 32120-2801 386-254-2700 www.iscmotorsports.com For tickets, merchandise and information 888-4RACTIX (888-472-2849) www.racetickets.com ISC-45 COVER_1.qxd 2/9/06 10:44 AM Page 2 Board of Directors William C. France James C. France Chairman of the Board Chief Executive Officer International Speedway Corporation International Speedway Corporation Lesa France Kennedy Larry Aiello, Jr.1 President President and Chief Executive Officer International Speedway Corporation Corning Cable Systems J. Hyatt Brown1 John R. Cooper2 Chairman and Chief Executive Officer Retired as Vice President Brown & Brown, Inc. International Speedway Corporation Brian Z. France William P. Graves1 Chairman and Chief Executive Officer President and Chief Executive Officer NASCAR, Inc. American Trucking Associations Christy F. Harris Raymond K. Mason, Jr.1 Attorney in private practice of Chairman and President business and commercial law Centerbank of Jacksonville, N.A. TABLE OF CONTENTS Gregory W. Penske1 Edward H. Rensi1 President Retired as President and 3 Letter to Shareholders . Report of Management on Internal Control Penske Automotive Group, Inc. Chief Executive Officer Over Financial Reporting . 70 McDonald’s USA Selected Financial Data . 29 Chairman and Chief Executive Officer Market Price of and Dividends on Registrant’s Common Equity Team Rensi Motorsports Management’s Discussion and Analysis of Financial Condition and and Related Stockholder Matters. 71 Results of Operations. 30 Other Corporate Officers . 72 Consolidated Financial Statements . -

Hamlin Headlines Weekend with Bristol Win
Hamlin Headlines Weekend with Bristol Win August 19, 2019 PLANO, Texas. (August 19, 2019) – Denny Hamlin’s win at Bristol Motor Speedway on Saturday highlighted the racing action for Toyota over the weekend. NASCAR Hamlin captured his fourth win of the season on Saturday night in the Monster Energy NASCAR Cup Series (MENCS) race at Bristol. Hamlin led 79 laps (of 500), passing Camry driver, Matt DiBenedetto, for the lead with 11 laps to go. DiBenedetto tallied a career-best second-place finish after leading a race-high 93 laps at the Tennessee short track. “I’m so sorry to Matt DiBenedetto, (crew chief) Mike Wheeler,” said Hamlin, following the win. “I know a win would mean a lot to that team, but I have to give it 110% for FedEx and my whole team. Proud of this whole FedEx team for giving me a great car, pit crew, crew chief, everybody doing an amazing job. The whole team is just doing an amazing job right now.” Kyle Busch (fourth) also finished in the top five after coming from a lap down to lead 30 laps, as Toyota drivers led a combined 277 laps throughout Saturday night’s MENCS race. Timmy Hill was the top-finishing Supra driver in Friday night’s NASCAR Xfinity Series race at Bristol, matching a career-best seventh-place finish. “Bristol has always been a great track for me and I’m glad we could put on a great finish here,” said Hill, following the race. “MBM (Motorsports) and HRE (Hattori Racing Enterprises) came in collaboration for this race. -

2019 National Qualifier Dates
2019 National Qualifier Dates Asphalt Legend Qualifier Dates: Speedway (State) Date Tucson Speedway, AZ – March 9th East Carolina Motor Speedway, NC – March 23rd Texas Motor Speedway, TX – March 30th The Bullring at Las Vegas Motor Speedway, NV – April 20th Willow Springs Speedway, CA – May 4th Concord Speedway, NC – May 17th Hi-Way 92 Raceway, NE – May 24th Intermountain Speedway, WY – May 25th Star Speedway, NH – May 25th Evergreen Speedway, WA – May 25th Evergreen Speedway, WA – May 26th Colorado National Speedway, CO – May 26th Meridian Speedway, ID – May 27th Sportsdrome Speedway, IN – June 1st Hawkeye Downs Speedway, IA – June 7th Southeast Legends Tour (Tri-County Motor Speedway) – June 15th Wiscasset Speedway, ME – June 15th Elko Speedway, MN – June 22nd Seekonk Speedway, MA – June 28th Evergreen Speedway, WA – June 29th Kern County Raceway, CA – June 29th Peterborough Speedway, CAN Central – June 29th Sunny South Raceway, AL – July 6th Oyster Bed Speedway, CAN East – July 6th Sydney Speedway, CAN East – July 6th Sydney Speedway, CAN East – July 7th Eastbound International Speedway, CAN East – July 7th Edmonton International Raceway, CAN West – July 13th Irwindale Speedway, CA – July 13th I-25 Speedway, CO – July 13th Riverhead Raceway, NY – July 13th Fairgrounds Speedway Nashville, TN – July 13th Langley Speedway, VA – July 20th Wake County Speedway, NC – July 26th Dells Raceway Park, WI – July 27th Sydney Speedway, CAN East – July 27th Sydney Speedway, CAN East – July 28th Charlotte Motor -

Volume 31 No 02R 2016
THE Volume 31 • No. 2 • 2016 WINNING EDGE YOUR TOTAL MOTORSPORTS MAGAZINE IN DIGITAL FORMAT Since SINCE 1985 2006 Snowmobile Swap Meet Draws Enthusiast Inside: • What’s Hot - Industry News & Product Releases TOM DOBBRASTINE • MMSHoF Inductee Profiles WITH WAGON IN TOW HAULS HIS NEW FIND TO THE PARKING LOT. • Bud Bennett Joins MMSHoF • Ultimax Belts • Marion October Swap Meet & More! © WE’vE GOT MORE! LIKE US ON FACEBOOK www.facebook.com/thewinningedgemagazine THE WINNING EDGE MAGAZINE © 2016 Reproduction Prohibited YOUR TOTAL MOTORSPORTS PUBLICATIONS 1 Follow us on facebook and Like our page Join the Conversation! • Get informed, read, comment and share WE’VE the news you like. GOT • Check out our weekly Remember When Features and Photo Flashbacks. MORE! • Get The Winning Edge Magazine in your facebook feed. https://www.facebook.com/thewinningedgemagazine 2 YOUR TOTAL MOTORSPORTS PUBLICATIONS © 2016 Reproduction Prohibited THE WINNING EDGE MAGAZINE THE WINNING EDGE MAGAZINE © 2016 Reproduction Prohibited YOUR TOTAL MOTORSPORTS PUBLICATIONS 3 WHAT’S The Winning Edge Snowmobile Safety: Ride Safe and Have Fun! HASLETT, MI: Now is the excellent adjunct tool for snowmobile safety classes. All of time for snowmobilers to keep the Safe Riders! materials are available free of charge by fill- snowmobile safety a top-of-mind ing out an order form and returning it to the ISMA office. awareness issue. Snowmobile The Safe Riders! campaign highlights key issues of impor- safety is nothing new to orga- tance for snowmobile safety. The position statements are con- nized snowmobiling. Snowmobile cise and easy to understand. They include: Administrators, the Manufactur- 1. Snowmobiling and Alcohol don’t mix - don’t drink and ride ers, snowmobile associations and 2.