The Restless Cloud Nathan Pemberton Johann Schleier-Smith Joseph E
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Effi Barry Training Institute Application
Notice of Funding Opportunity Government of the District of Columbia Department of Health HIV/AIDS, Hepatitis, STD, and TB Administration H A H S T A The Effi Barry Training Institute Application RFA Number: HAHSTA_EBTI_07.03.20 Application Deadline: Monday, August 3, 2020 at 6:00 PM Late applications cannot be accepted The Department of Health (DC Health) reserves the right to, without prior notice, reduce or cancel one or more programs listed in this Request for Applications (RFA), reject all applications, adjust total funds available, or cancel the RFA in part or whole. Funding levels in the respective program areas and budget amount in the award, if awarded, sub grant agreement is contingent on continued funding, sub grantee performance, and/or reduction, elimination, or reallocation funds by a federal grantor, the Executive Office of the Mayor (EOM) of the Government of the District of Columbia and/or the Department of Health in accordance with applicable sections within the sub grant award and/or agreement. Pre-application Conference: DATE: Wednesday, July 8, 2020 TIME: 2:30 PM – 4:00 PM VIRTUAL ZOOM CALL https://us02web.zoom.us/j/8178711891 Zoom/Conference Meeting ID: 817 8711 8910 (Call Access) - One tap mobile +13017158592-81787118910# Application Deadline: DATE: Monday, August 3, 2020 TIME: by 6:00 pm WHERE: Application submission must be done electronically through the Enterprise Grants Management System (See pages 7-9) Applications submitted after 6:00 PM cannot be accepted. You may download this application from: www.dchealth.dc.gov/ebtifunding http://opgs.dc.gov/page/opgs-district-grants- clearinghouse Effi Barry Training Institute Grant 2020 Table of Contents Notice of Funding Availability ........................................ -

GOOGLE LLC V. ORACLE AMERICA, INC
(Slip Opinion) OCTOBER TERM, 2020 1 Syllabus NOTE: Where it is feasible, a syllabus (headnote) will be released, as is being done in connection with this case, at the time the opinion is issued. The syllabus constitutes no part of the opinion of the Court but has been prepared by the Reporter of Decisions for the convenience of the reader. See United States v. Detroit Timber & Lumber Co., 200 U. S. 321, 337. SUPREME COURT OF THE UNITED STATES Syllabus GOOGLE LLC v. ORACLE AMERICA, INC. CERTIORARI TO THE UNITED STATES COURT OF APPEALS FOR THE FEDERAL CIRCUIT No. 18–956. Argued October 7, 2020—Decided April 5, 2021 Oracle America, Inc., owns a copyright in Java SE, a computer platform that uses the popular Java computer programming language. In 2005, Google acquired Android and sought to build a new software platform for mobile devices. To allow the millions of programmers familiar with the Java programming language to work with its new Android plat- form, Google copied roughly 11,500 lines of code from the Java SE pro- gram. The copied lines are part of a tool called an Application Pro- gramming Interface (API). An API allows programmers to call upon prewritten computing tasks for use in their own programs. Over the course of protracted litigation, the lower courts have considered (1) whether Java SE’s owner could copyright the copied lines from the API, and (2) if so, whether Google’s copying constituted a permissible “fair use” of that material freeing Google from copyright liability. In the proceedings below, the Federal Circuit held that the copied lines are copyrightable. -

SIGOPS Annual Report 2012
SIGOPS Annual Report 2012 Fiscal Year July 2012-June 2013 Submitted by Jeanna Matthews, SIGOPS Chair Overview SIGOPS is a vibrant community of people with interests in “operatinG systems” in the broadest sense, includinG topics such as distributed computing, storaGe systems, security, concurrency, middleware, mobility, virtualization, networkinG, cloud computinG, datacenter software, and Internet services. We sponsor a number of top conferences, provide travel Grants to students, present yearly awards, disseminate information to members electronically, and collaborate with other SIGs on important programs for computing professionals. Officers It was the second year for officers: Jeanna Matthews (Clarkson University) as Chair, GeorGe Candea (EPFL) as Vice Chair, Dilma da Silva (Qualcomm) as Treasurer and Muli Ben-Yehuda (Technion) as Information Director. As has been typical, elected officers agreed to continue for a second and final two- year term beginning July 2013. Shan Lu (University of Wisconsin) will replace Muli Ben-Yehuda as Information Director as of AuGust 2013. Awards We have an excitinG new award to announce – the SIGOPS Dennis M. Ritchie Doctoral Dissertation Award. SIGOPS has lonG been lackinG a doctoral dissertation award, such as those offered by SIGCOMM, Eurosys, SIGPLAN, and SIGMOD. This new award fills this Gap and also honors the contributions to computer science that Dennis Ritchie made durinG his life. With this award, ACM SIGOPS will encouraGe the creativity that Ritchie embodied and provide a reminder of Ritchie's leGacy and what a difference a person can make in the field of software systems research. The award is funded by AT&T Research and Alcatel-Lucent Bell Labs, companies that both have a strong connection to AT&T Bell Laboratories where Dennis Ritchie did his seminal work. -

Shanlu › About › Cv › CV Shanlu.Pdf Shan Lu
Shan Lu University of Chicago, Dept. of Computer Science Phone: +1-773-702-3184 5730 S. Ellis Ave., Rm 343 E-mail: [email protected] Chicago, IL 60637 USA Homepage: http://people.cs.uchicago.edu/~shanlu RESEARCH INTERESTS Tool support for improving the correctness and efficiency of large scale software systems EMPLOYMENT 2019 – present Professor, Dept. of Computer Science, University of Chicago 2014 – 2019 Associate Professor, Dept. of Computer Sciences, University of Chicago 2009 – 2014 Assistant Professor, Dept. of Computer Sciences, University of Wisconsin – Madison EDUCATION 2008 University of Illinois at Urbana-Champaign, Urbana, IL Ph.D. in Computer Science Thesis: Understanding, Detecting, and Exposing Concurrency Bugs (Advisor: Prof. Yuanyuan Zhou) 2003 University of Science & Technology of China, Hefei, China B.S. in Computer Science HONORS AND AWARDS 2019 ACM Distinguished Member Among 62 members world-wide recognized for outstanding contributions to the computing field 2015 Google Faculty Research Award 2014 Alfred P. Sloan Research Fellow Among 126 “early-career scholars (who) represent the most promising scientific researchers working today” 2013 Distinguished Alumni Educator Award Among 3 awardees selected by Department of Computer Science, University of Illinois 2010 NSF Career Award 2021 Honorable Mention Award @ CHI for paper [C71] (CHI 2021) 2019 Best Paper Award @ SOSP for paper [C62] (SOSP 2019) 2019 ACM SIGSOFT Distinguished Paper Award @ ICSE for paper [C58] (ICSE 2019) 2017 Google Scholar Classic Paper Award for -

Pivot Tracing: Dynamic Causal Monitoring for Distributed Systems Pdfauthor=Jonathan Mace, Ryan Roelke, Rodrigo Fonseca
PivoT Tracing:Dynamic Causal MoniToring for DisTribuTed SysTems JonaThan Mace Ryan Roelke Rodrigo Fonseca Brown UniversiTy AbsTracT MoniToring and TroubleshooTing disTribuTed sysTems is noToriously diõcult; poTenTial prob- lems are complex, varied, and unpredicTable. _e moniToring and diagnosis Tools commonly used Today – logs, counTers, and meTrics – have Two imporTanT limiTaTions: whaT gets recorded is deûned a priori, and The informaTion is recorded in a componenT- or machine-cenTric way, making iT exTremely hard To correlaTe events ThaT cross These boundaries. _is paper presents PivoT Tracing, a moniToring framework for disTribuTed sysTems ThaT addresses boTh limiTaTions by combining dynamic insTrumenTaTion wiTh a novel relaTional operaTor: The happened-before join. PivoT Tracing gives users, aT runTime, The abiliTy To deûne arbiTrary meTrics aT one poinT of The sysTem, while being able To selecT, ûlTer, and group by events mean- ingful aT oTher parts of The sysTem, even when crossing componenT or machine boundaries. We have implemenTed a proToType of PivoT Tracing for Java-based sysTems and evaluaTe iT on a heTerogeneous Hadoop clusTer comprising HDFS, HBase, MapReduce, and YARN. We show ThaT PivoT Tracing can eòecTively idenTify a diverse range of rooT causes such as soware bugs, misconûguraTion, and limping hardware. We show ThaT PivoT Tracing is dynamic, exTensible, and enables cross-Tier analysis beTween inTer-operaTing applicaTions, wiTh low execuTion overhead. Ë. InTroducTion MoniToring and TroubleshooTing disTribuTed sysTems -
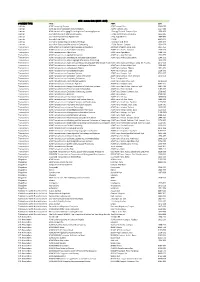
A ACM Transactions on Trans. 1553 TITLE ABBR ISSN ACM Computing Surveys ACM Comput. Surv. 0360‐0300 ACM Journal
ACM - zoznam titulov (2016 - 2019) CONTENT TYPE TITLE ABBR ISSN Journals ACM Computing Surveys ACM Comput. Surv. 0360‐0300 Journals ACM Journal of Computer Documentation ACM J. Comput. Doc. 1527‐6805 Journals ACM Journal on Emerging Technologies in Computing Systems J. Emerg. Technol. Comput. Syst. 1550‐4832 Journals Journal of Data and Information Quality J. Data and Information Quality 1936‐1955 Journals Journal of Experimental Algorithmics J. Exp. Algorithmics 1084‐6654 Journals Journal of the ACM J. ACM 0004‐5411 Journals Journal on Computing and Cultural Heritage J. Comput. Cult. Herit. 1556‐4673 Journals Journal on Educational Resources in Computing J. Educ. Resour. Comput. 1531‐4278 Transactions ACM Letters on Programming Languages and Systems ACM Lett. Program. Lang. Syst. 1057‐4514 Transactions ACM Transactions on Accessible Computing ACM Trans. Access. Comput. 1936‐7228 Transactions ACM Transactions on Algorithms ACM Trans. Algorithms 1549‐6325 Transactions ACM Transactions on Applied Perception ACM Trans. Appl. Percept. 1544‐3558 Transactions ACM Transactions on Architecture and Code Optimization ACM Trans. Archit. Code Optim. 1544‐3566 Transactions ACM Transactions on Asian Language Information Processing 1530‐0226 Transactions ACM Transactions on Asian and Low‐Resource Language Information Proce ACM Trans. Asian Low‐Resour. Lang. Inf. Process. 2375‐4699 Transactions ACM Transactions on Autonomous and Adaptive Systems ACM Trans. Auton. Adapt. Syst. 1556‐4665 Transactions ACM Transactions on Computation Theory ACM Trans. Comput. Theory 1942‐3454 Transactions ACM Transactions on Computational Logic ACM Trans. Comput. Logic 1529‐3785 Transactions ACM Transactions on Computer Systems ACM Trans. Comput. Syst. 0734‐2071 Transactions ACM Transactions on Computer‐Human Interaction ACM Trans. -

An Oral History of Computer Science Cornell University
An Oral History of Computer Science at Cornell University https://ecommons.cornell.edu/handle/1813/40569 Gates Hall, Cornell University Twelve senior faculty members share their personal journeys and their recollections of the early days of computer science at Cornell University and the leadership role in bringing a new field of study into existence. Birman, Ken Hopcroft, John E Cardie, Claire Kozen, Dexter Constable, Robert Nerode, Anil Conway, Richard W. Schneider, Fred B Gries, David Teitelbaum, Tim Hartmanis, Juris Van Loan, Charlie (Click on a name above to scroll to an abstract and a live link to the associated streaming video.) version: 16Jun16 1. KEN BIRMAN Ken Birman, who joined CS in 1981, exemplifies the successful synergy of research and entrepreneurial activities. His research in distributed systems led to his founding ISIS Distributed Systems, Inc., in 1988, which developed software used by the New York Stock Exchange (NYSE) and Swiss Exchange, the French Air Traffic Control sys- tem, the AEGIS warship, and others. He started two other companies, Reliable Network Solutions and Web Sci- ences LLC. This entrepreneurship has in turn generated new research ideas and has also led to Ken’s advising various organi- zations on distributed systems and cloud computing, including the French Civil Aviation Organization, the north- eastern electric power grid, NATO, the US Treasury, and the US Air Force. Ken has received several awards for his research, among them the IEEE Tsutomu Kanai Award for his work on trustworthy computing, the Cisco “Technology Visionary” award, and the ACM SIGOPS Hall of Fame Award. He also has written two successful texts. -
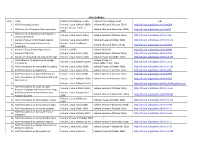
ACM JOURNALS S.No. TITLE PUBLICATION RANGE :STARTS PUBLICATION RANGE: LATEST URL 1. ACM Computing Surveys Volume 1 Issue 1
ACM JOURNALS S.No. TITLE PUBLICATION RANGE :STARTS PUBLICATION RANGE: LATEST URL 1. ACM Computing Surveys Volume 1 Issue 1 (March 1969) Volume 49 Issue 3 (October 2016) http://dl.acm.org/citation.cfm?id=J204 Volume 24 Issue 1 (Feb. 1, 2. ACM Journal of Computer Documentation Volume 26 Issue 4 (November 2002) http://dl.acm.org/citation.cfm?id=J24 2000) ACM Journal on Emerging Technologies in 3. Volume 1 Issue 1 (April 2005) Volume 13 Issue 2 (October 2016) http://dl.acm.org/citation.cfm?id=J967 Computing Systems 4. Journal of Data and Information Quality Volume 1 Issue 1 (June 2009) Volume 8 Issue 1 (October 2016) http://dl.acm.org/citation.cfm?id=J1191 Journal on Educational Resources in Volume 1 Issue 1es (March 5. Volume 16 Issue 2 (March 2016) http://dl.acm.org/citation.cfm?id=J814 Computing 2001) 6. Journal of Experimental Algorithmics Volume 1 (1996) Volume 21 (2016) http://dl.acm.org/citation.cfm?id=J430 7. Journal of the ACM Volume 1 Issue 1 (Jan. 1954) Volume 63 Issue 4 (October 2016) http://dl.acm.org/citation.cfm?id=J401 8. Journal on Computing and Cultural Heritage Volume 1 Issue 1 (June 2008) Volume 9 Issue 3 (October 2016) http://dl.acm.org/citation.cfm?id=J1157 ACM Letters on Programming Languages Volume 2 Issue 1-4 9. Volume 1 Issue 1 (March 1992) http://dl.acm.org/citation.cfm?id=J513 and Systems (March–Dec. 1993) 10. ACM Transactions on Accessible Computing Volume 1 Issue 1 (May 2008) Volume 9 Issue 1 (October 2016) http://dl.acm.org/citation.cfm?id=J1156 11. -

Semperos: a Distributed Capability System
SemperOS: A Distributed Capability System Matthias Hille† Nils Asmussen† ∗ Pramod Bhatotia‡ Hermann Härtig† ∗ †Technische Universität Dresden ‡The University of Edinburgh ∗ Barkhausen Institut Abstract systems have received renewed attention recently to provide Capabilities provide an efficient and secure mechanism for an efficient and secure mechanism for resource management fine-grained resource management and protection. However, in modern hardware architectures [5, 24, 30, 36, 44, 64, 67]. as the modern hardware architectures continue to evolve Today the main improvements in compute capacity with large numbers of non-coherent and heterogeneous cores, are achieved by either adding more cores or integrating we focus on the following research question: can capability accelerators into the system. However, the increasing core systems scale to modern hardware architectures? counts exacerbate the hardware complexity required for global In this work, we present a scalable capability system to drive cache coherence. While on-chip cache coherence is likely to future systems with many non-coherent heterogeneous cores. remain a feature of future hardware architectures [45], we see More specifically, we have designed a distributed capability characteristics of distributed systems added to the hardware system based on a HW/SW co-designed capability system. by giving up on global cache coherence across a whole We analyzed the pitfalls of distributed capability operations machine [6, 28]. Additionally, various kinds of accelerators running concurrently and built the protocols in accordance are added like the Xeon Phi Processor, the Matrix-2000 accel- with the insights. We have incorporated these distributed erator, GPUs, FPGAs, or ASICs, which are used in numerous capability management protocols in a new microkernel-based application fields [4,21,32,34,43,60]. -

Programming Mac OS X: a GUIDE for UNIX DEVELOPERS
Programming Mac OS X: A GUIDE FOR UNIX DEVELOPERS KEVIN O’MALLEY MANNING Programming Mac OS X Programming Mac OS X A GUIDE FOR UNIX DEVELOPERS KEVIN O’MALLEY MANNING Greenwich (74° w. long.) For electronic information and ordering of this and other Manning books, go to www.manning.com. The publisher offers discounts on this book when ordered in quantity. For more information, please contact: Special Sales Department Manning Publications Co. 209 Bruce Park Avenue Fax: (203) 661-9018 Greenwich, CT 06830 email: [email protected] ©2003 by Manning Publications Co. All rights reserved. No part of this publication may be reproduced, stored in a retrieval system, or transmitted, in any form or by means electronic, mechanical, photocopying, or otherwise, without prior written permission of the publisher. Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in the book, and Manning Publications was aware of a trademark claim, the designations have been printed in initial caps or all caps. Recognizing the importance of preserving what has been written, it is Manning’s policy to have the books they publish printed on acid-free paper, and we exert our best efforts to that end. Manning Publications Co. Copyeditor: Tiffany Taylor 209 Bruce Park Avenue Typesetter: Denis Dalinnik Greenwich, CT 06830 Cover designer: Leslie Haimes ISBN 1-930110-85-5 Printed in the United States of America 12345678910–VHG–05 040302 brief contents PART 1OVERVIEW ............................................................................. 1 1 ■ Welcome to Mac OS X 3 2 ■ Navigating and using Mac OS X 27 PART 2TOOLS .................................................................................. -

Mac OS 8 Revealed
•••••••••••••••••••••••••••••••••••••••••••• Mac OS 8 Revealed Tony Francis Addison-Wesley Developers Press Reading, Massachusetts • Menlo Park, California • New York Don Mills, Ontario • Harlow, England • Amsterdam Bonn • Sydney • Singapore • Tokyo • Madrid • San Juan Seoul • Milan • Mexico City • Taipei Apple, AppleScript, AppleTalk, Color LaserWriter, ColorSync, FireWire, LocalTalk, Macintosh, Mac, MacTCP, OpenDoc, Performa, PowerBook, PowerTalk, QuickTime, TrueType, and World- Script are trademarks of Apple Computer, Inc., registered in the United States and other countries. Apple Press, the Apple Press Signature, AOCE, Balloon Help, Cyberdog, Finder, Power Mac, and QuickDraw are trademarks of Apple Computer, Inc. Adobe™, Acrobat™, and PostScript™ are trademarks of Adobe Systems Incorporated or its sub- sidiaries and may be registered in certain jurisdictions. AIX® is a registered trademark of IBM Corp. and is being used under license. NuBus™ is a trademark of Texas Instruments. PowerPC™ is a trademark of International Business Machines Corporation, used under license therefrom. SOM, SOMobjects, and System Object Model are licensed trademarks of IBM Corporation. UNIX® is a registered trademark of Novell, Inc. in the United States and other countries, licensed exclusively through X/Open Company, Ltd. Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and Addison-Wesley was aware of a trademark claim, the designations have been printed in initial capital letters or all capital letters. The author and publisher have taken care in the preparation of this book, but make no express or implied warranty of any kind and assume no responsibility for errors or omissions. No liability is assumed for incidental or consequential damages in connection with or arising out of the use of the information or programs contained herein. -

Owlcpp: a C++ Library for Working with OWL Ontologies Mikhail K
Levin and Cowell Journal of Biomedical Semantics (2015) 6:35 DOI 10.1186/s13326-015-0035-z JOURNAL OF BIOMEDICAL SEMANTICS SOFTWARE Open Access owlcpp: a C++ library for working with OWL ontologies Mikhail K. Levin and Lindsay G. Cowell* Abstract Background: The increasing use of ontologies highlights the need for a library for working with ontologies that is efficient, accessible from various programming languages, and compatible with common computational platforms. Results: We developed owlcpp, a library for storing and searching RDF triples, parsing RDF/XML documents, converting triples into OWL axioms, and reasoning. The library is written in ISO-compliant C++ to facilitate efficiency, portability, and accessibility from other programming languages. Internally, owlcpp uses the Raptor RDF Syntax library for parsing RDF/XML and the FaCT++ library for reasoning. The current version of owlcpp is supported under Linux, OSX, and Windows platforms and provides an API for Python. Conclusions: The results of our evaluation show that, comparedtoothercommonlyusedlibraries,owlcpp is significantly more efficient in terms of memory usage and searching RDF triple stores. owlcpp performs strict parsing and detects errors ignored by other libraries, thus reducing the possibility of incorrect semantic interpretation of ontologies. owlcpp is available at http://owl-cpp.sf.net/ under the Boost Software License, Version 1.0. Background fail to fully meet the needs of software developers build- Ontologies are being increasingly recognized as import- ing software for working with OWL ontologies. First, ant information resources that capture descriptive infor- existing libraries do not scale well enough to support mation in a standardized, structured, and computable ontologies of over a few million triples [6, 7].